################################################################################
# ~ Coordonnées des établissements de santé et données ponctuelles full code ~ #
################################################################################
### Step -----------------------------------------------------------------------
from pathlib import Path
import geopandas as gpd
import matplotlib.colors as mcolors
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import numpy as np
import pandas as pd
import pyreadr
from matplotlib.cm import ScalarMappable
from pyprojroot import here
def read_rds(path):
"""Lire un fichier RDS à objet unique comme objet pandas."""
result = pyreadr.read_r(str(path))
return next(iter(result.values()))
def cli_header(message):
print(f"\n{message}")
def cli_info(message):
print(f"INFO: {message}")
def cli_success(message):
print(f"SUCCESS: {message}")
def cli_warning(message):
print(f"WARNING: {message}")
def cli_danger(message):
print(f"ERROR: {message}")
def anti_join(left, right, on):
"""Retourner les lignes de left sans clé correspondante dans right."""
right_keys = right[on].drop_duplicates()
return (
left.merge(right_keys, on=on, how="left", indicator=True)
.loc[lambda x: x["_merge"] == "left_only"]
.drop(columns="_merge")
)
def finish_map(ax, title=None, subtitle=None):
"""Appliquer le style de carte statique partagé utilisé sur cette page."""
if title and subtitle:
ax.set_title(
f"{title}\n{subtitle}", loc="left", fontsize=14, fontweight="bold"
)
elif title:
ax.set_title(title, loc="left", fontsize=14, fontweight="bold")
ax.set_axis_off()
def save_figure(fig, filename, width, height, dpi=300):
"""Enregistrer une figure matplotlib avec les dimensions correspondant aux exemples R."""
Path(filename).parent.mkdir(parents=True, exist_ok=True)
fig.set_size_inches(width, height)
fig.savefig(filename, dpi=dpi, bbox_inches="tight")
def show_table(df, n=10, caption=None):
"""Rendu d'un tableau HTML compact défilable correspondant au helper R show_table.
Produit un <table class="out-table"> encapsulé dans <div class="out-scroll">
afin que la sortie corresponde exactement au rendu R basé sur kable.
"""
from IPython.display import display, HTML
html = df.head(n).to_html(index=False, border=0, classes="out-table")
if caption:
html = f"<caption>{caption}</caption>" + html
display(HTML(f'<div class="out-scroll">{html}</div>'))
# définir le chemin vers les limites administratives traitées
spat_path = Path(
here(
"01_data/1.1_foundational/"
"1.1a_administrative_boundaries/processed"
)
)
# charger l'objet spatial des chefferies (adm3) traité
gdf = gpd.read_file(spat_path / "sle_spatial_adm3_2021.geojson")
# charger l'objet spatial des districts (adm2) traité
adm2_gdf = gpd.read_file(spat_path / "sle_spatial_adm2_2021.geojson")
# définir le chemin vers les données d'établissements de santé traitées
hf_path = Path(
here(
"01_data/1.1_foundational/"
"1.1b_health_facilities/processed"
)
)
# charger la liste principale des établissements de santé
hf_data = pd.read_excel(hf_path / "mfl_hfs.xlsx")
# inspecter les données chargées
cli_header("Colonnes des limites administratives")
print(list(gdf.columns))
cli_header("Colonnes des données des établissements de santé")
print(list(hf_data.columns))
cli_header("Échantillon des données des établissements de santé")
print(hf_data.head(3))
# cette étape n'est requise que si longitude et latitude sont combinées
# dans une seule colonne. si les colonnes sont séparées, ignorer cette étape.
# remplacer les séparateurs (; ou espace) par une virgule
hf_data["coordinates"] = (
hf_data["coordinates"].str.replace(r"[; ]+", ",", regex=True)
)
# séparer la colonne combinée en deux colonnes
coord_split = hf_data["coordinates"].str.split(",", expand=True)
hf_data = hf_data.assign(
w_lat=pd.to_numeric(coord_split[0], errors="coerce"),
w_long=pd.to_numeric(coord_split[1], errors="coerce"),
)
cli_success("Coordonnées séparées en colonnes distinctes")
cli_header("Échantillon des coordonnées séparées")
print(hf_data[["w_lat", "w_long"]].head(3).to_string(index=False))
# charger la limite nationale (adm0) pour les vérifications spatiales
adm0 = gpd.read_file(
Path(
here(
"01_data/1.1_foundational/"
"1.1a_administrative_boundaries/processed/"
"sle_spatial_adm0_2021.geojson"
)
)
)
# assistant : compter les décimales d'une valeur de coordonnée
def count_decimals(value):
if pd.isna(value):
return 0
text = f"{abs(value):.10f}".rstrip("0")
if "." not in text:
return 0
return len(text.split(".")[1])
# définir la longitude (x) et la latitude (y)
hf_data = hf_data.assign(x=hf_data["w_long"], y=hf_data["w_lat"])
# lignes avec coordonnées valides et dans la plage (pour les vérifications spatiales)
valid = (
hf_data["x"].notna() & hf_data["y"].notna()
& hf_data["x"].between(-180, 180)
& hf_data["y"].between(-90, 90)
)
# coordonnées manquantes, hors plage et île zéro (0, 0)
n_missing = (hf_data["x"].isna() | hf_data["y"].isna()).sum()
n_out_range = (
hf_data["x"].notna() & hf_data["y"].notna() & ~valid
).sum()
n_zero = (
(hf_data["x"] == 0) & (hf_data["y"] == 0)
).sum()
# faible précision (moins de 4 décimales)
lon_dp = hf_data["x"].apply(count_decimals)
lat_dp = hf_data["y"].apply(count_decimals)
n_imprecise = int((valid & ((lon_dp < 4) | (lat_dp < 4))).sum())
# établissement + coordonnée en double et emplacements partagés
valid_data = hf_data.loc[valid].copy()
keys = (
valid_data["hf"].astype(str) + "_"
+ valid_data["x"].astype(str) + "_"
+ valid_data["y"].astype(str)
)
n_duplicate = int(keys.duplicated().sum())
coord_key = (
valid_data["x"].astype(str) + "_" + valid_data["y"].astype(str)
)
n_shared = int(
coord_key.isin(coord_key[coord_key.duplicated()]).sum()
)
# construire un GeoDataFrame des points valides pour les vérifications spatiales
if adm0.crs is None:
adm0 = adm0.set_crs("EPSG:4326")
hf_points = gpd.GeoDataFrame(
valid_data,
geometry=gpd.points_from_xy(valid_data["x"], valid_data["y"]),
crs="EPSG:4326",
)
if hf_points.crs != adm0.crs:
hf_points = hf_points.to_crs(adm0.crs)
# points hors de la limite nationale
inside = hf_points.within(adm0.union_all())
n_outside = int((~inside).sum())
# lon/lat probablement inversés : hors limite tel quel, mais dedans une fois inversés
swapped = gpd.GeoDataFrame(
geometry=gpd.points_from_xy(hf_points["y"], hf_points["x"]),
crs="EPSG:4326",
)
inside_swapped = swapped.within(adm0.union_all())
n_flipped = int((~inside & inside_swapped).sum())
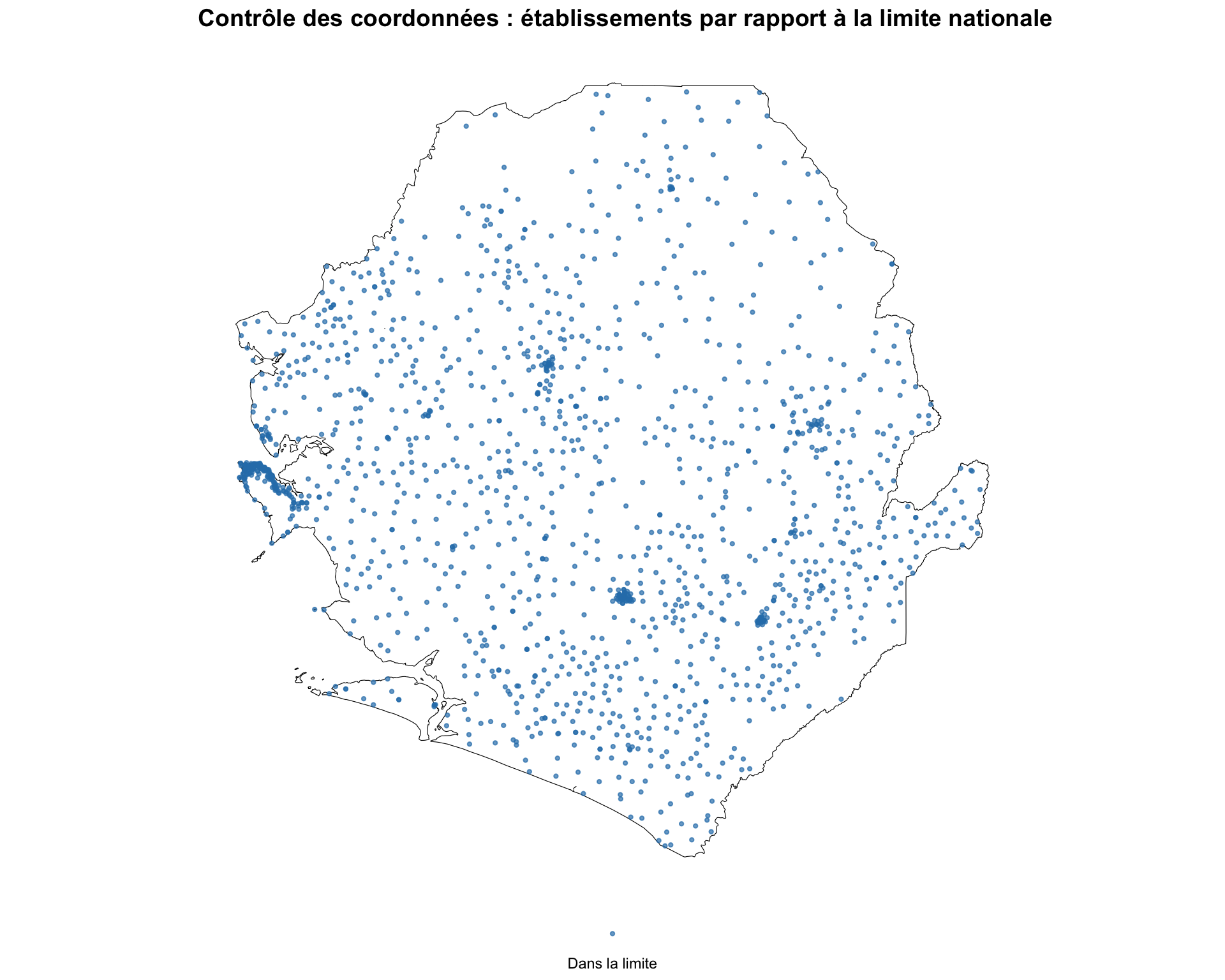
# afficher le bilan des problèmes
cli_header(
f"Bilan de qualité des coordonnées ({len(hf_data)} établissements)"
)
cli_info(f"Coordonnées manquantes : {n_missing}")
cli_info(f"Coordonnées hors plage : {n_out_range}")
cli_info(f"Île zéro (0, 0) : {n_zero}")
cli_info(f"Faible précision (< 4 dp) : {n_imprecise}")
cli_info(f"Établissement et coordonnée en double : {n_duplicate}")
cli_info(f"Enregistrements à emplacements partagés : {n_shared}")
cli_info(f"Hors de la limite nationale : {n_outside}")
cli_info(f"Lon/lat probablement inversés : {n_flipped}")
# marquer chaque point valide selon s'il se trouve à l'intérieur de la limite nationale
hf_points = hf_points.assign(
location=inside.map(
{True: "Dans la limite", False: "Hors limite"}
)
)
# cartographier les points sur la limite nationale
color_map = {"Dans la limite": "#2c7fb8", "Hors limite": "#e31a1c"}
fig, ax = plt.subplots(figsize=(8, 9))
adm0.plot(ax=ax, facecolor="white", edgecolor="black", linewidth=0.8,
aspect="equal")
for label, color in color_map.items():
subset = hf_points.loc[hf_points["location"] == label]
subset.plot(
ax=ax, color=color, markersize=3, alpha=0.7, label=label,
aspect="equal",
)
ax.legend(
loc="lower center", bbox_to_anchor=(0.5, -0.05),
frameon=False, fontsize=9, ncol=2,
)
finish_map(
ax,
title="Contrôle des coordonnées : établissements par rapport à la limite nationale",
)
# définir les coordonnées de longitude (x) et de latitude (y)
hf_data = hf_data.assign(x=hf_data["w_long"], y=hf_data["w_lat"])
# identifier les établissements avec des coordonnées invalides pour suivi
facilities_to_review = hf_data.loc[
hf_data["x"].isna()
| hf_data["y"].isna()
| (hf_data["x"] < -180) | (hf_data["x"] > 180)
| (hf_data["y"] < -90) | (hf_data["y"] > 90)
]
# filtrer pour ne conserver que les coordonnées valides et dans la plage
facilities_clean = hf_data.loc[
hf_data["x"].notna()
& hf_data["y"].notna()
& hf_data["x"].between(-180, 180)
& hf_data["y"].between(-90, 90)
]
# afficher les résultats du nettoyage
cli_header("Résultats du nettoyage des données")
cli_info(f"Établissements de santé initiaux : {len(hf_data)}")
cli_info(f"Établissements de santé nettoyés : {len(facilities_clean)}")
cli_info(
f"Établissements supprimés : {len(hf_data) - len(facilities_clean)}"
)
cli_info(
f"Établissements signalés pour révision : {len(facilities_to_review)}"
)
cli_info(
f"Plage de longitude : {facilities_clean['x'].min()} à "
f"{facilities_clean['x'].max()}"
)
cli_info(
f"Plage de latitude : {facilities_clean['y'].min()} à "
f"{facilities_clean['y'].max()}"
)
# convertir le tableau nettoyé en GeoDataFrame à partir des coordonnées ponctuelles
facilities_sf = gpd.GeoDataFrame(
facilities_clean,
geometry=gpd.points_from_xy(
facilities_clean["w_long"], facilities_clean["w_lat"]
),
crs="EPSG:4326",
)
cli_success("Converti en objet spatial")
cli_header("Résumé de l'objet spatial")
print(facilities_sf.head(3).to_string(index=False))
# conserver uniquement les colonnes admin de limite, renommées pour éviter les conflits
# avec les propres colonnes admin des données d'établissements
boundary_lookup = gdf[["adm2", "adm3", "geometry"]].rename(
columns={"adm2": "adm2_boundary", "adm3": "adm3_boundary"}
)
# assigner un CRS par défaut si absent avant la jointure spatiale
if boundary_lookup.crs is None:
boundary_lookup = boundary_lookup.set_crs("EPSG:4326")
if facilities_sf.crs is None:
facilities_sf = facilities_sf.set_crs("EPSG:4326")
# assigner chaque établissement au polygone de chefferie (adm3) dans lequel il se situe
facilities_admin = gpd.sjoin(
facilities_sf,
boundary_lookup,
how="left",
predicate="within",
)
# établissements qui ne se trouvaient dans aucun polygone
n_unmatched = facilities_admin["adm3_boundary"].isna().sum()
cli_header("Établissements assignés à une unité administrative")
cli_info(f"Établissements joints : {len(facilities_admin)}")
cli_info(f"Non appariés (hors de tous les polygones) : {n_unmatched}")
# comparer la chefferie enregistrée avec le polygone dans lequel le point se situe
print(
facilities_admin[["hf", "adm3", "adm3_boundary"]]
.head(5)
.to_string(index=False)
)
# définir le répertoire de sortie pour les jeux de données traités
out_path = Path(
here(
"01_data/1.1_foundational/"
"1.1b_health_facilities/processed"
)
)
out_path.mkdir(parents=True, exist_ok=True)
# sauvegarder le tableau d'établissements nettoyé en CSV
facilities_clean.to_csv(
out_path / "facilities_clean.csv", index=False
)
# sauvegarder les points d'établissements en GeoPackage
facilities_sf.to_file(
out_path / "facilities_spatial.gpkg",
layer="facilities",
driver="GPKG",
)
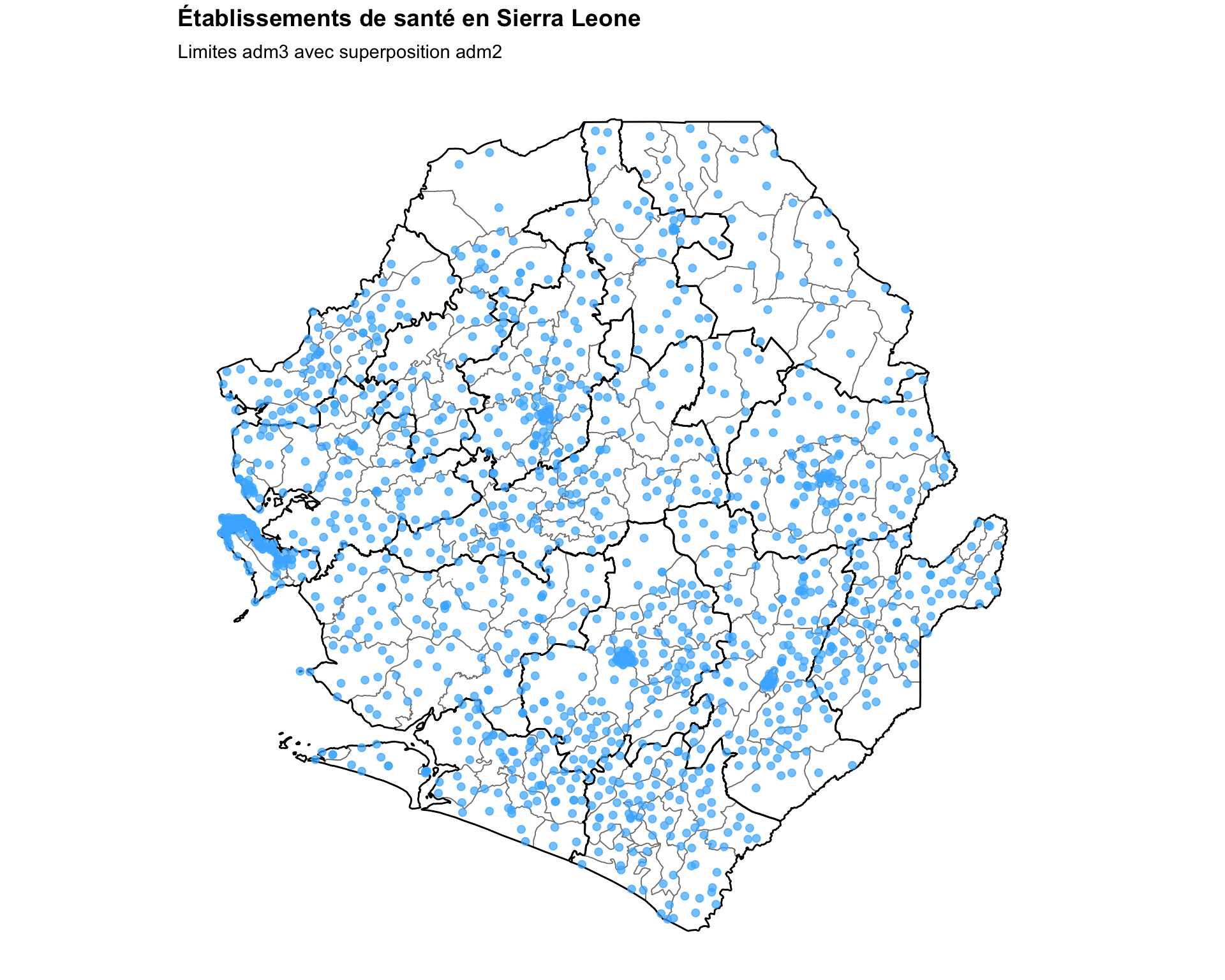
# définir le titre de la carte
title = "Établissements de santé en Sierra Leone"
# créer la carte de base
fig, ax = plt.subplots(figsize=(10, 8))
gdf.plot(ax=ax, facecolor="white", edgecolor="grey", linewidth=0.3,
aspect="equal")
adm2_gdf.plot(ax=ax, facecolor="none", edgecolor="black",
linewidth=0.5, aspect="equal")
ax.scatter(
facilities_clean["x"],
facilities_clean["y"],
color="#47B5FF",
s=15,
alpha=0.7,
zorder=5,
)
finish_map(ax, title=title, subtitle="Limites adm3 avec superposition adm2")
# sauvegarder la carte
save_figure(
fig,
here("03_output/3a_figures/health_facility_locations.png"),
width=10,
height=7,
)
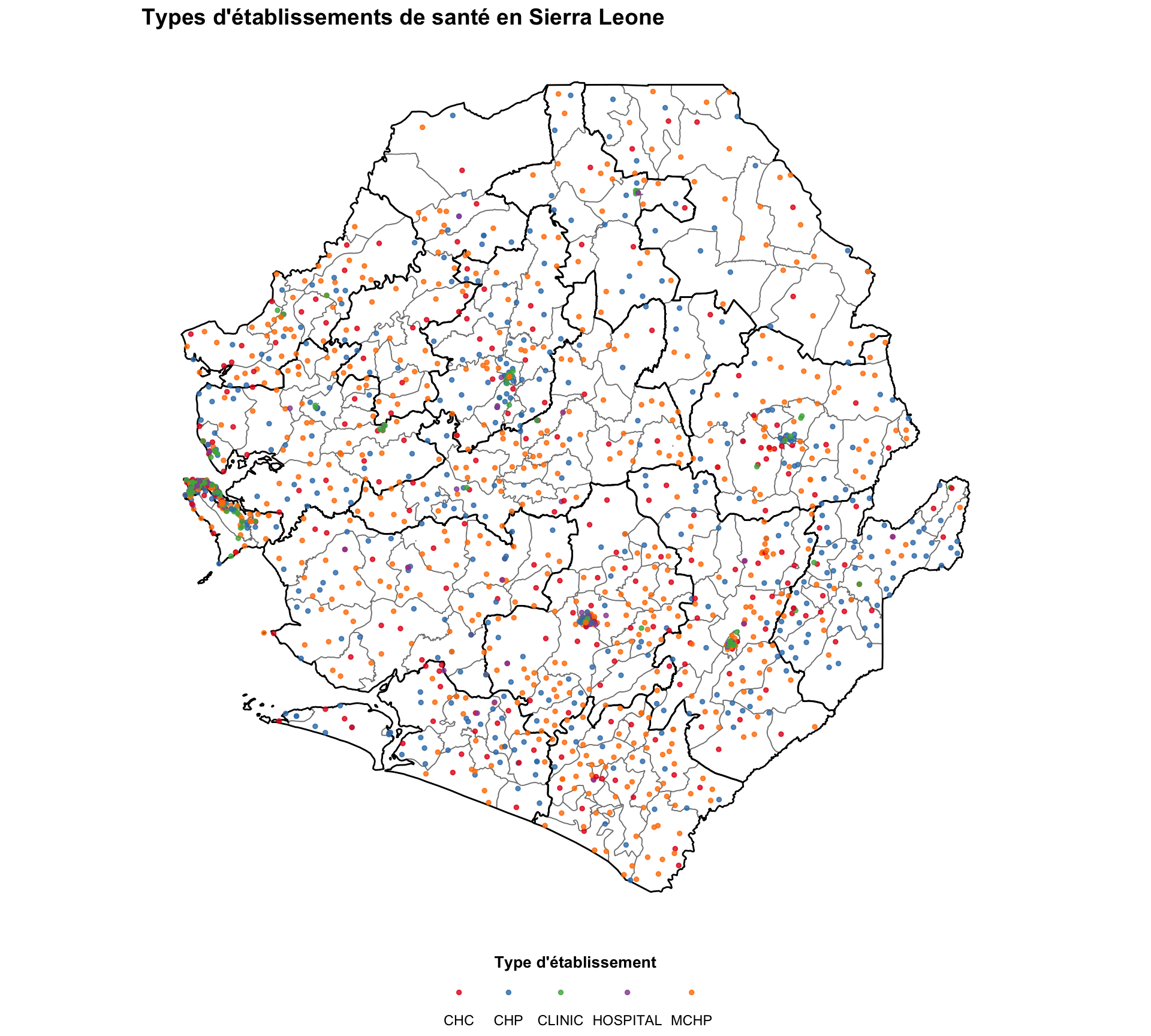
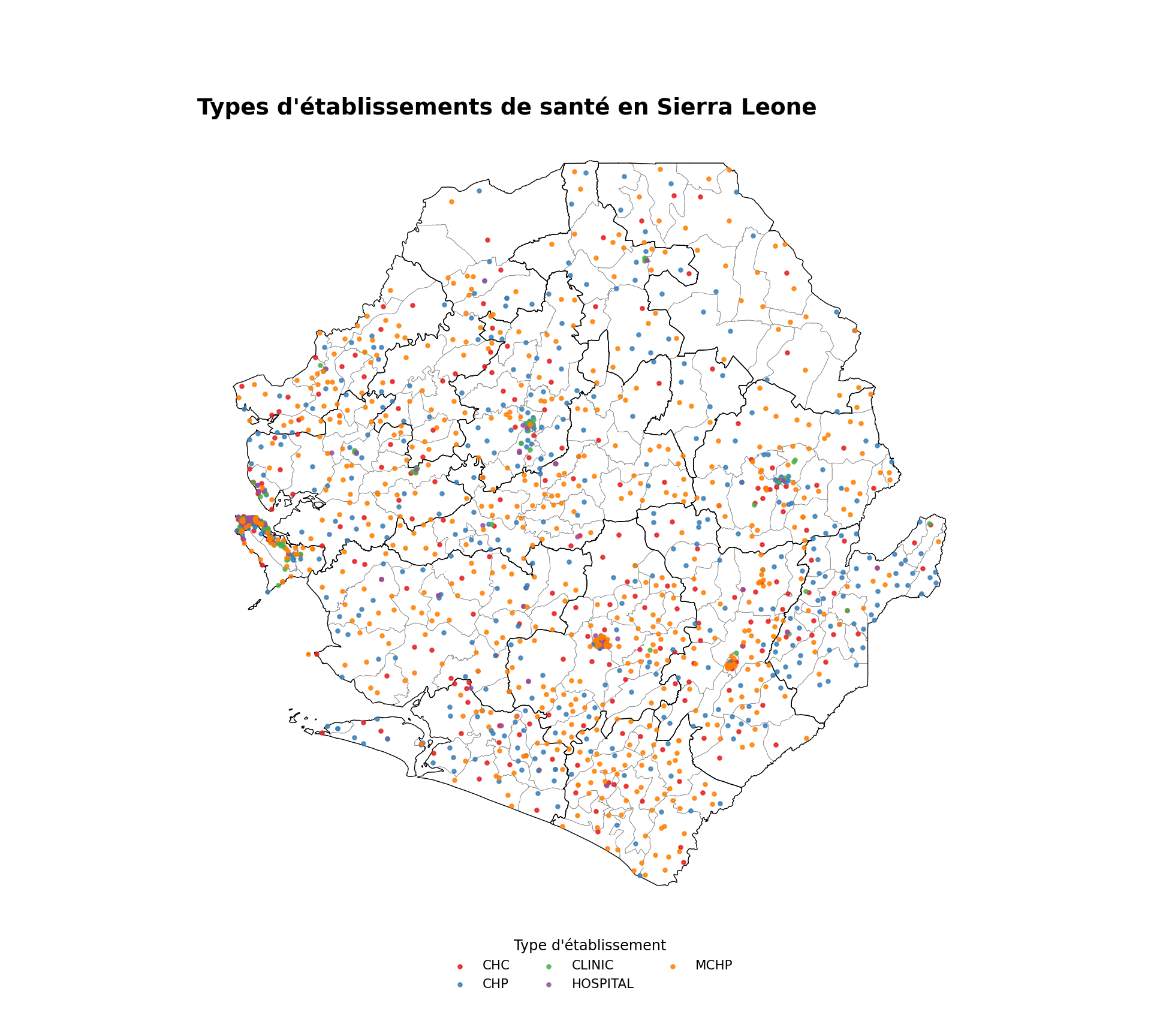
# définir le titre de la carte des types d'établissements
title_type = "Types d'établissements de santé en Sierra Leone"
# obtenir les types d'établissements ordonnés et assigner une couleur Set1 à chacun
facility_types = sorted(facilities_clean["type"].dropna().unique())
set1_colors = plt.get_cmap("Set1").colors
type_palette = {
t: set1_colors[i % len(set1_colors)]
for i, t in enumerate(facility_types)
}
# créer la carte des types d'établissements de santé
fig, ax = plt.subplots(figsize=(10, 9))
gdf.plot(ax=ax, facecolor="white", edgecolor="gray", linewidth=0.3,
aspect="equal")
adm2_gdf.plot(ax=ax, facecolor="none", edgecolor="black",
linewidth=0.5, aspect="equal")
for ftype, color in type_palette.items():
subset = facilities_clean.loc[facilities_clean["type"] == ftype]
ax.scatter(
subset["x"], subset["y"],
color=color, s=5, alpha=0.8, label=ftype, zorder=5,
)
ax.legend(
title="Type d'établissement",
loc="lower center",
bbox_to_anchor=(0.5, -0.10),
ncol=3,
frameon=False,
fontsize=8,
title_fontsize=9,
)
finish_map(ax, title=title_type)
# sauvegarder la carte des types
save_figure(
fig,
here("03_output/3a_figures/health_facility_by_type.png"),
width=10,
height=7,
)
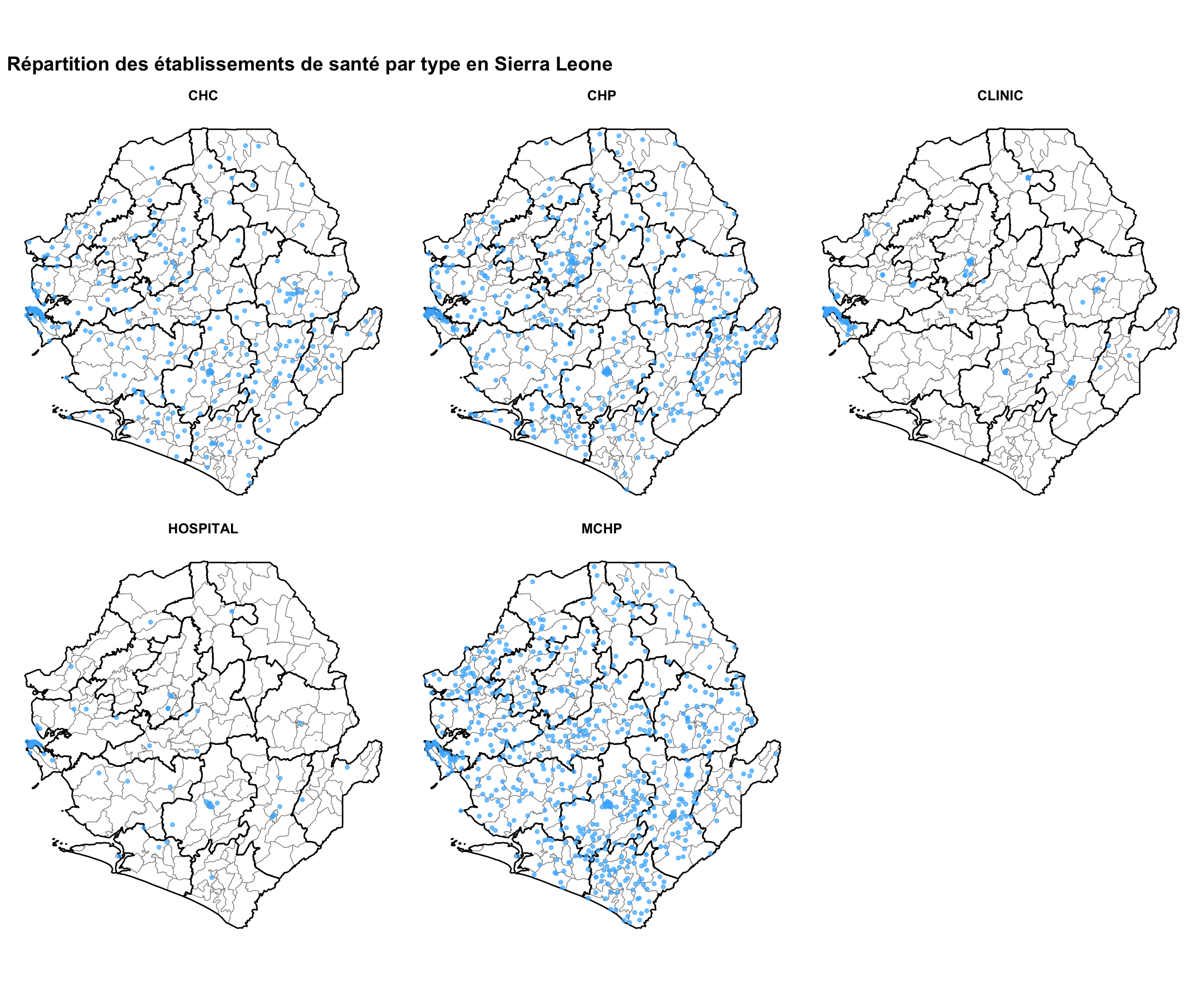
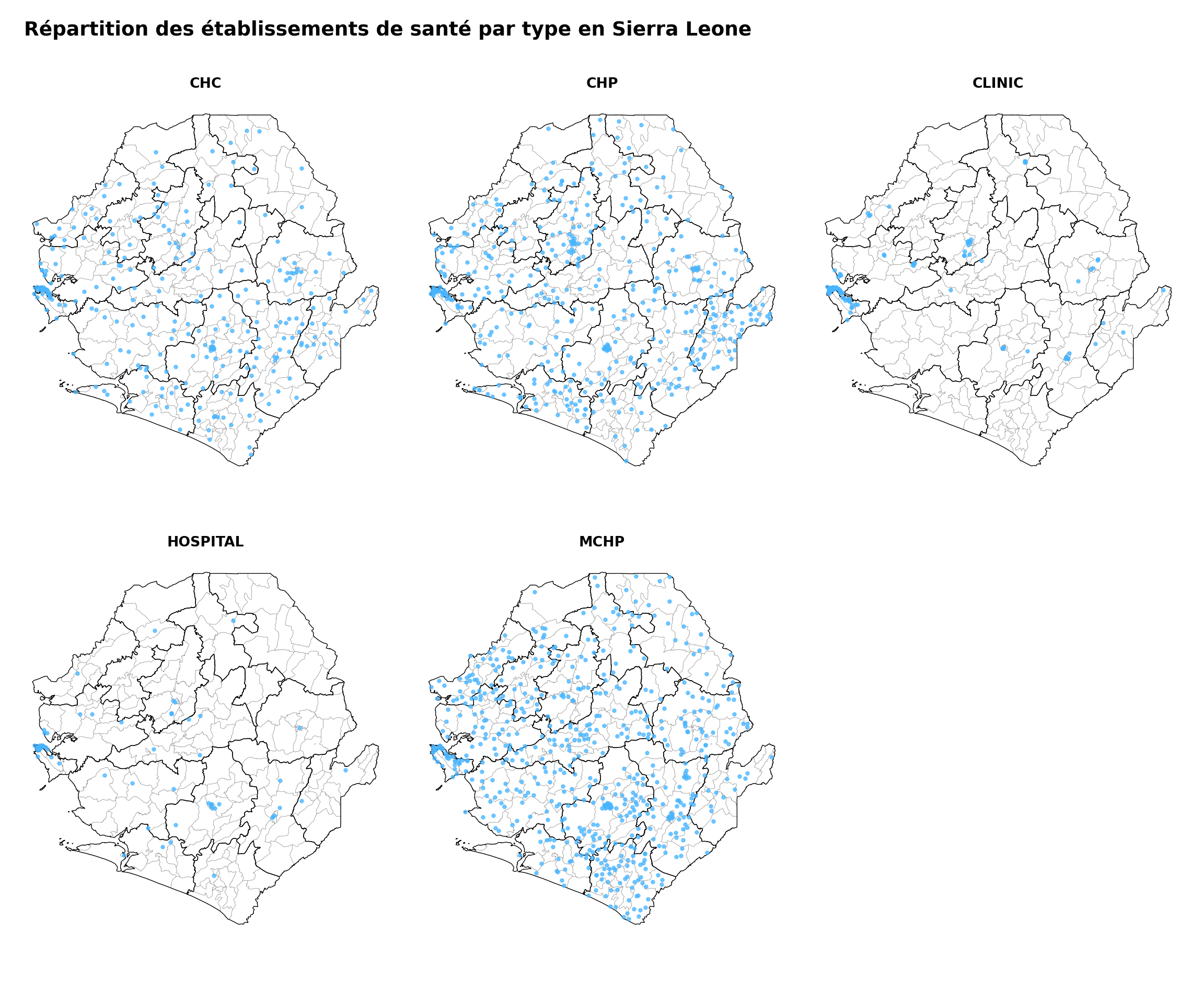
# définir le titre de la carte en panneaux
title_facet = "Répartition des établissements de santé par type en Sierra Leone"
# obtenir les types d'établissements uniques pour les panneaux
facility_types = sorted(facilities_clean["type"].dropna().unique())
n_types = len(facility_types)
ncols = 3
nrows = -(-n_types // ncols) # ceiling division
fig, axes = plt.subplots(nrows, ncols, figsize=(12, 9))
axes_flat = axes.flatten()
for i, ftype in enumerate(facility_types):
ax = axes_flat[i]
gdf.plot(ax=ax, facecolor="white", edgecolor="gray",
linewidth=0.2, aspect="equal")
adm2_gdf.plot(ax=ax, facecolor="none", edgecolor="black",
linewidth=0.5, aspect="equal")
subset = facilities_clean.loc[facilities_clean["type"] == ftype]
ax.scatter(
subset["x"], subset["y"],
color="#47B5FF", s=5, alpha=0.7, zorder=5,
)
ax.set_title(ftype, fontsize=10, fontweight="bold")
ax.set_axis_off()
# masquer les panneaux d'axes inutilisés
for j in range(n_types, len(axes_flat)):
axes_flat[j].set_visible(False)
fig.suptitle(title_facet, fontsize=14, fontweight="bold", x=0.02,
ha="left")
plt.tight_layout()
# sauvegarder la carte en panneaux
save_figure(
fig,
here("03_output/3a_figures/health_facility_faceted_by_type.png"),
width=12,
height=9,
)
# charger le jeu de données DHIS2-MFL fusionné
final_dhis2_mfl_integrated = pd.read_parquet(
Path(
here(
"01_data/1.1_foundational/"
"1.1b_health_facilities/processed/"
"final_dhis2_mfl_integrated.parquet"
)
)
)
# la colonne year peut arriver en chaîne ; la convertir en entier nullable
# afin que le filtre par année se comporte de la même façon qu'en R
# (R : "2023" == 2023 est TRUE ; Python : c'est False)
final_dhis2_mfl_integrated["year"] = pd.to_numeric(
final_dhis2_mfl_integrated["year"], errors="coerce"
).astype("Int64")
# compléter les lat/long manquants depuis la MFL par nom d'établissement ; de nombreuses
# lignes DHIS2 arrivent sans coordonnées car la correspondance floue en amont
# n'a confirmé qu'un sous-ensemble d'identités d'établissements
mfl_coords = (
pd.read_excel(hf_path / "mfl_hfs.xlsx")
[["hf", "w_lat", "w_long"]]
.drop_duplicates("hf")
)
final_dhis2_mfl_integrated = final_dhis2_mfl_integrated.merge(
mfl_coords, on="hf", how="left"
)
final_dhis2_mfl_integrated["lat"] = (
final_dhis2_mfl_integrated["lat"]
.combine_first(final_dhis2_mfl_integrated["w_lat"])
)
final_dhis2_mfl_integrated["long"] = (
final_dhis2_mfl_integrated["long"]
.combine_first(final_dhis2_mfl_integrated["w_long"])
)
# calculer les résumés annuels pour chaque établissement de santé
annual_summary = (
final_dhis2_mfl_integrated
.assign(
total_tests=lambda d: (
d["test_u5"].fillna(0)
+ d["test_5_14"].fillna(0)
+ d["test_ov15"].fillna(0)
),
positive_tests=lambda d: (
d["conf_u5"].fillna(0)
+ d["conf_5_14"].fillna(0)
+ d["conf_ov15"].fillna(0)
),
)
.groupby(["hf_uid", "hf", "year", "lat", "long"], as_index=False)
.agg(
total_tests=("total_tests", "sum"),
positive_tests=("positive_tests", "sum"),
)
.assign(
tpr=lambda d: np.where(
d["total_tests"] > 0,
(d["positive_tests"] / d["total_tests"]) * 100,
np.nan,
)
)
.loc[lambda d: d["total_tests"] > 0]
)
# filtrer pour 2023 et assigner une catégorie de volume de tests
size_levels = ["≤100", "101-500", "501-1,000", "1,001-5,000", "5,000+"]
annual_summary_2023 = (
annual_summary
.loc[lambda d: (
(d["year"] == 2023)
& d["tpr"].notna()
& (d["total_tests"] > 0)
& d["lat"].notna()
& d["long"].notna()
)]
.assign(
size_category=lambda d: pd.Categorical(
np.select(
[
d["total_tests"] <= 100,
d["total_tests"] <= 500,
d["total_tests"] <= 1000,
d["total_tests"] <= 5000,
],
["≤100", "101-500", "501-1,000", "1,001-5,000"],
default="5,000+",
),
categories=size_levels,
ordered=True,
)
)
)
# construire la palette de couleurs correspondant à rev(brewer.pal(7, "RdYlBu")) de R
rdylbu_7_rev = [
"#4575b4", "#91bfdb", "#e0f3f8",
"#ffffbf", "#fee090", "#fc8d59", "#d73027",
]
cmap_tpr = mcolors.LinearSegmentedColormap.from_list(
"rdylbu_rev", rdylbu_7_rev
)
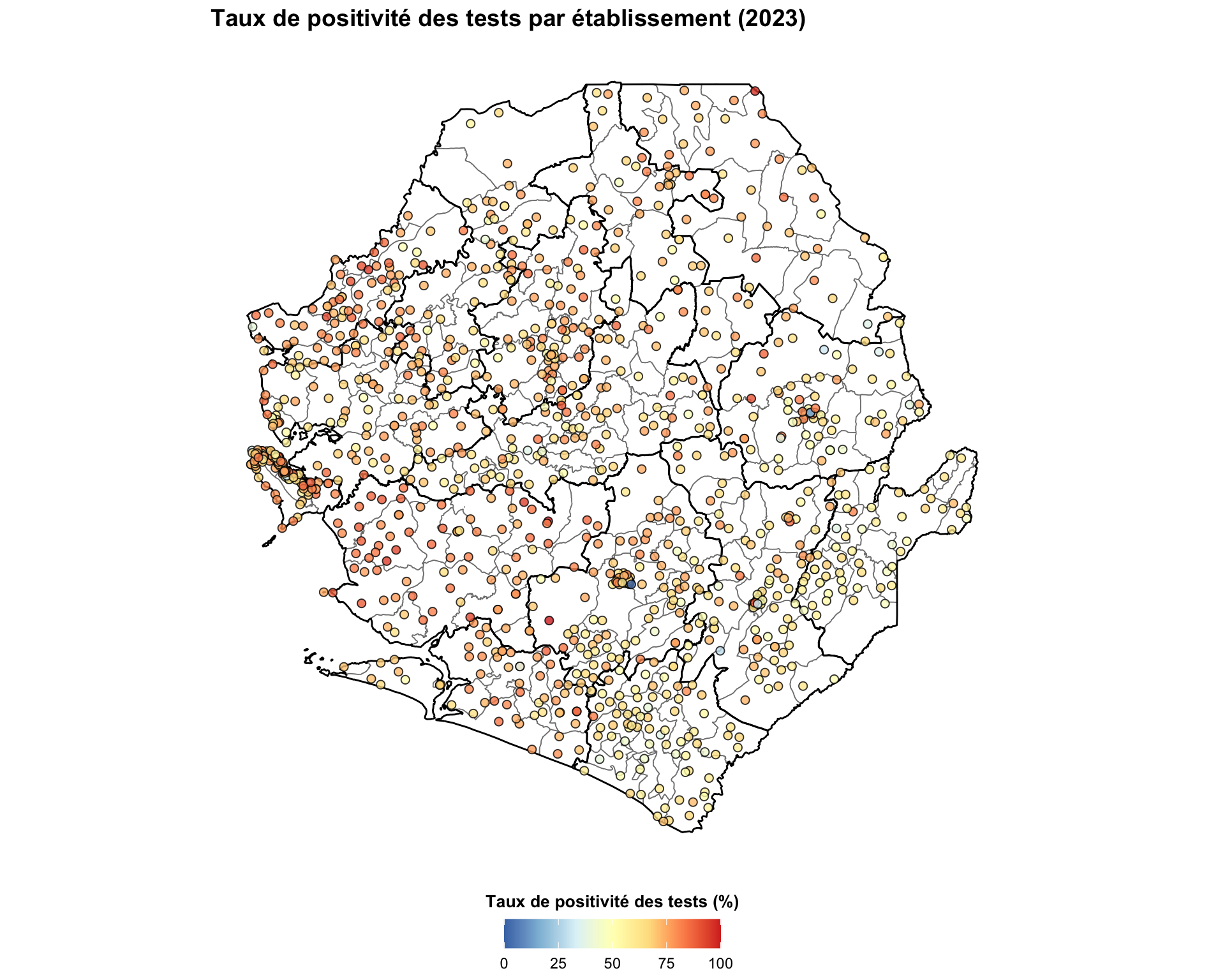
fig, ax = plt.subplots(figsize=(10, 10))
gdf.plot(ax=ax, facecolor="white", edgecolor="gray", linewidth=0.3,
aspect="equal")
adm2_gdf.plot(ax=ax, facecolor="none", edgecolor="black",
linewidth=0.5, aspect="equal")
norm = mcolors.Normalize(vmin=0, vmax=100)
sc = ax.scatter(
annual_summary_2023["long"],
annual_summary_2023["lat"],
c=annual_summary_2023["tpr"],
cmap=cmap_tpr,
norm=norm,
s=15,
alpha=0.8,
edgecolors="black",
linewidths=0.5,
zorder=5,
)
sm = ScalarMappable(cmap=cmap_tpr, norm=norm)
sm.set_array([])
cbar = fig.colorbar(
sm, ax=ax, orientation="horizontal", fraction=0.04, pad=0.04
)
cbar.set_label("Taux de positivité des tests (%)", fontweight="bold")
finish_map(ax, title="Taux de positivité des tests par établissement (2023)")
# sauvegarder la carte
save_figure(
fig,
here("03_output/3a_figures/health_facility_tpr_2023.png"),
width=10,
height=7,
)
# correspondance de taille avec le size_scale de R
size_map = {
"≤100": 20, "101-500": 30, "501-1,000": 50,
"1,001-5,000": 80, "5,000+": 120,
}
# construire la palette de couleurs correspondant à rev(brewer.pal(7, "RdYlBu")) de R
rdylbu_7_rev = [
"#4575b4", "#91bfdb", "#e0f3f8",
"#ffffbf", "#fee090", "#fc8d59", "#d73027",
]
cmap_tpr = mcolors.LinearSegmentedColormap.from_list(
"rdylbu_rev", rdylbu_7_rev
)
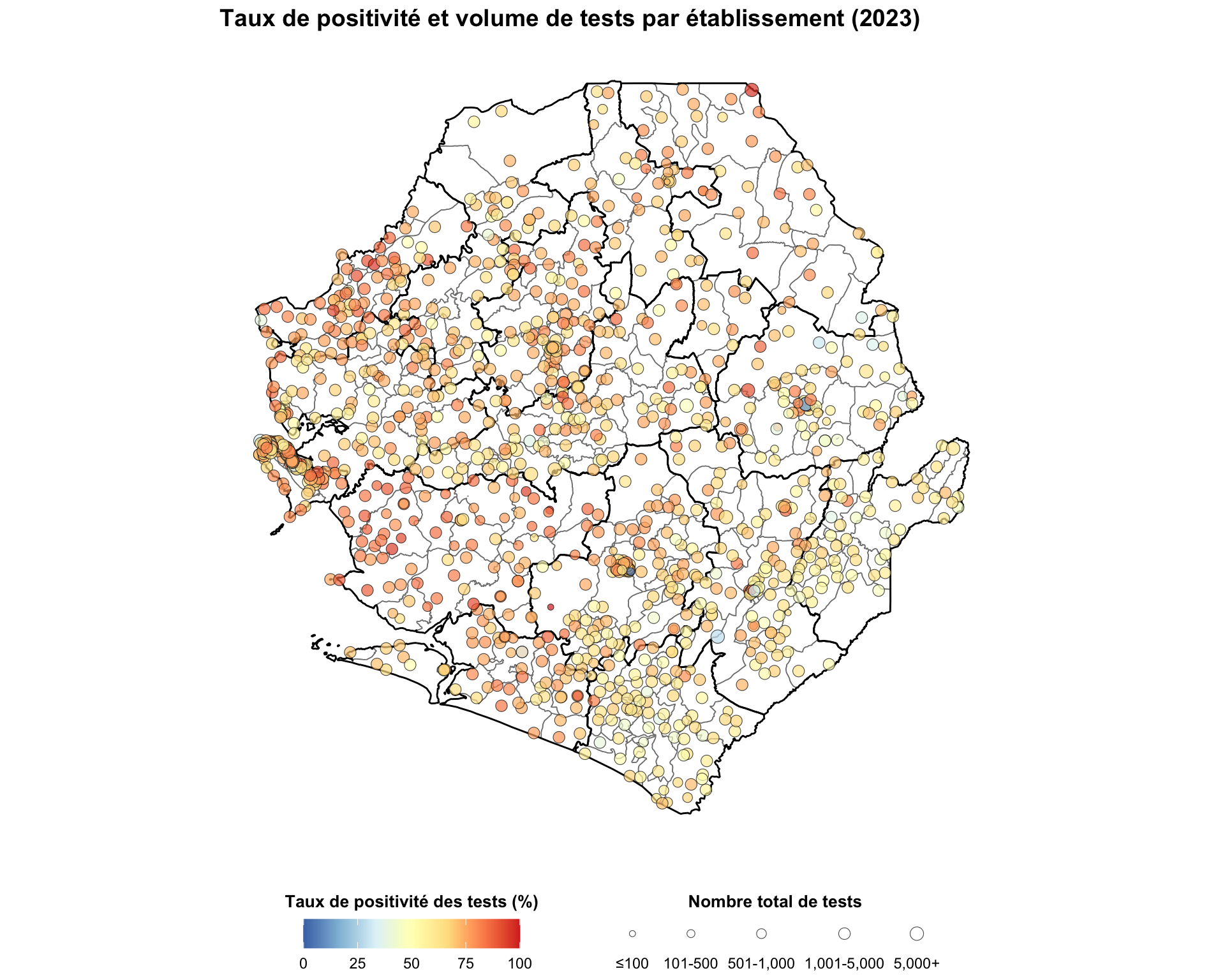
fig, ax = plt.subplots(figsize=(10, 12))
gdf.plot(ax=ax, facecolor="white", edgecolor="gray", linewidth=0.3,
aspect="equal")
adm2_gdf.plot(ax=ax, facecolor="none", edgecolor="black",
linewidth=0.5, aspect="equal")
norm = mcolors.Normalize(vmin=0, vmax=100)
# dériver la taille du marqueur pour chaque ligne depuis la colonne size_category,
# en utilisant la plus petite taille par défaut si la catégorie est manquante
size_levels = ["≤100", "101-500", "501-1,000", "1,001-5,000", "5,000+"]
point_sizes = (
annual_summary_2023["size_category"]
.astype(str)
.map(size_map)
.fillna(size_map["≤100"])
)
# tracer tous les établissements en un seul appel scatter pour que chaque point s'affiche
ax.scatter(
annual_summary_2023["long"],
annual_summary_2023["lat"],
c=annual_summary_2023["tpr"],
cmap=cmap_tpr,
norm=norm,
s=point_sizes,
alpha=0.7,
edgecolors="black",
linewidths=0.3,
zorder=5,
)
# barre de couleurs pour le TPR
sm = ScalarMappable(cmap=cmap_tpr, norm=norm)
sm.set_array([])
cbar = fig.colorbar(
sm, ax=ax, orientation="horizontal", fraction=0.04, pad=0.04
)
cbar.set_label("Taux de positivité des tests (%)", fontweight="bold")
# construire des proxys pour la légende de taille afin qu'elle s'affiche toujours,
# même si une catégorie de taille n'a pas d'établissements
size_handles = [
plt.scatter(
[], [], s=size_map[cat], color="lightgray",
edgecolors="black", linewidths=0.3, alpha=0.7,
)
for cat in size_levels
]
ax.legend(
size_handles, size_levels,
title="Nombre total de tests",
loc="upper center",
bbox_to_anchor=(0.5, -0.18),
ncol=5,
frameon=False,
fontsize=8,
title_fontsize=9,
)
finish_map(
ax,
title=(
"Taux de positivité et volume de tests par établissement (2023)"
),
)
# sauvegarder la carte
save_figure(
fig,
here("03_output/3a_figures/health_facility_tpr_test_2023.png"),
width=10,
height=7,
)