flowchart TD
Start[Établissements de santé DHIS2] --> Step3[Étape 3 : Diagnostic initial<br/>de correspondance]
Step3 --> Step4[Étape 4 : Correspondance géographique<br/>stratifiée interactive]
Step3 --> Step5[Étape 5 : Traiter et préparer<br/>les données non appariées]:::altPath
Step4 --> Decision1{Apparié ?}
Decision1 -->|Oui | Matched1[Enregistrements appariés<br/>à haute confiance]
Decision1 -->|Non | Step5
Step5 --> Step6[Étape 6 : Correspondance floue<br/>sur les non-appariés restants]
Step6 --> Step7[Étape 7 : Évaluer la qualité<br/>des correspondances floues]
Step7 --> Step8[Étape 8 : Finaliser la sélection<br/>des correspondances floues]
Step8 --> Decision2{Apparié ?}
Decision2 -->|Oui| Matched2[Enregistrements appariés<br/>par correspondance floue]
Decision2 -->|Non| Unmatched[Non-appariés finaux<br/>pour révision manuelle]
Matched1 --> Step9[Étape 9 : Combiner tous<br/>les résultats de correspondance]
Matched2 --> Step9
Unmatched --> Step9
Step9 --> Step10[Étape 10 : Vérifications<br/>finales]
Step10 --> Step11[Étape 11 : Sauvegarder<br/>les jeux de données finaux]
classDef altPath fill:#d1c4e9,stroke:#673ab7,stroke-width:2px;
style Start fill:#e1f5fe
style Step3 fill:#e8f5e9
style Step4 fill:#fff3e0
style Step5 fill:#f3e5f5
style Step6 fill:#f3e5f5
style Step7 fill:#fff9c4
style Step8 fill:#f3e5f5
style Step9 fill:#e8f5e9
style Step10 fill:#fff9c4
style Step11 fill:#c8e6c9
style Matched1 fill:#a5d6a7
style Matched2 fill:#ffcc80
style Unmatched fill:#ffab91
Correspondance approximative des noms entre jeux de données
Intermédiaire
Aperçu
Sur cette page, nous montrons comment appliquer la correspondance approximative entre DHIS2 et la liste principale des établissements de santé (MFL) de manière structurée et vérifiable. Bien que l’exemple travaillé utilise DHIS2 et la MFL, nous pouvons appliquer la même approche de correspondance approximative à tout jeu de données contenant des noms d’établissements, ou tout champ de chaîne de caractères utilisé comme clé de jointure entre plusieurs jeux de données. Par exemple, si l’objectif est de joindre un shapefile à des données tabulaires et que les noms adm2 ne se joignent pas correctement, envisagez d’appliquer la correspondance approximative sur les noms adm2 entre les deux jeux de données.
La MFL est la liste nationale de référence des établissements de santé. Maintenue par le ministère de la Santé ou le bureau national des statistiques, elle fournit des noms standardisés, des identifiants uniques d’établissements, des coordonnées, le type, les unités administratives et peut également fournir d’autres informations telles que le statut opérationnel et la disponibilité de services particuliers. La MFL est souvent le seul jeu de données d’établissements de santé qui inclut leur géolocalisation.
La jointure d’autres jeux de données, tels que la surveillance de routine, avec la MFL rend ainsi possible de nombreux types d’analyses infranationales. Si des identifiants uniques d’établissements de santé ne sont pas disponibles dans la MFL et le jeu de données à joindre, ou si les identifiants uniques ne sont pas fiables, la jointure reposera sur la correspondance des noms d’établissements de santé. Cependant, les variations dans l’orthographe, les abréviations, l’ordre des mots ou le formatage des noms d’établissements de santé peuvent rendre ce processus difficile.
Une solution possible, raisonnablement extensible et automatisable, est la correspondance approximative des noms, une technique qui utilise des algorithmes de similarité de chaînes de caractères pour identifier des correspondances proches entre des champs de texte même lorsqu’ils diffèrent légèrement. Bien que non parfaite, cette approche peut améliorer le taux de correspondance entre des jeux de données où les noms d’établissements diffèrent en raison d’un formatage, d’une orthographe ou d’abréviations incohérents, laissant moins d’établissements non appariés à résoudre manuellement et en consultation avec l’équipe SNT. Les correspondances approximatives doivent tout de même être examinées, en particulier dans les applications importantes.
NoteObjectifs
- Effectuer des diagnostics pour vérifier les correspondances exactes, l’alignement administratif et les doublons
- Utiliser la correspondance géographique stratifiée avec validation humaine pour les correspondances à haute confiance
- Standardiser les noms et les abréviations pour préparer les données non appariées
- Appliquer la correspondance approximative sur les établissements restants à l’aide de grilles de candidats et de scores de similarité
- Évaluer la qualité des correspondances approximatives avec des diagnostics, des visualisations et des seuils
- Sélectionner une stratégie de correspondance (simple, composite, pondérée ou de repli) en fonction des besoins en données
- Fusionner les correspondances stratifiées et approximatives en un seul jeu de données
- Sauvegarder la sortie finale appariée pour l’analyse et l’intégration
Comprendre la correspondance approximative
La correspondance approximative nous aide à réconcilier des champs de texte qui ne s’alignent pas exactement mais qui se réfèrent très probablement à la même entité, ce qui peut se produire lorsque l’on travaille avec des noms d’établissements de santé dans des données réelles. Dans cette section, nous expliquons ce qu’est la correspondance approximative, pourquoi elle est nécessaire, comment elle fonctionne et ce que nous devons prendre en compte lors de son application dans le contexte du SNT.
Pourquoi la correspondance exacte n’est pas suffisante
En théorie, si le même établissement apparaît dans deux jeux de données, nous devrions pouvoir les joindre directement par nom. En pratique, les noms d’établissements peuvent parfois être orthographiés différemment, utiliser des abréviations incohérentes ou contenir des différences de formatage qui empêchent une jointure propre.
Par exemple, un établissement pourrait apparaître dans DHIS2 sous le nom « Makeni Gov. Hosp » et dans la MFL sous le nom « Makeni Government Hospital ». Une correspondance directe ne fonctionnera pas, même si les deux se réfèrent clairement au même lieu. De petites différences d’orthographe, de ponctuation ou d’ordre des mots nécessitent une approche de correspondance plus flexible.
Qu’est-ce que la correspondance approximative de chaînes de caractères ?
La correspondance approximative de chaînes de caractères est une méthode permettant de trouver des correspondances approximatives entre des chaînes de texte (une chaîne de texte est le format de données que les langages de programmation utilisent pour traiter le texte). Au lieu d’exiger une correspondance exacte, la correspondance approximative calcule la similarité entre deux chaînes, généralement avec un score compris entre 0 et 100. Un score plus élevé signifie que les chaînes sont plus similaires.
Cela est utile lorsque l’on travaille avec des noms d’établissements réels. La correspondance approximative nous permet de dire : « ces deux noms sont suffisamment proches pour être considérés comme une correspondance probable », et nous permet de décider où tracer la limite entre correspondance automatique, révision manuelle ou absence de correspondance.
Dans le processus SNT, les données sur les établissements de santé peuvent provenir de plusieurs sources avec des conventions de dénomination variées. Par exemple, la MFL peut servir de source faisant autorité, tandis que DHIS2 peut contenir des variations opérationnelles du même nom d’établissement. La correspondance approximative aide à réconcilier ces différences de manière systématique.
ImportantConsultez l’équipe SNT
Avant d’effectuer la correspondance approximative, examinez les considérations relatives aux données avec l’équipe SNT. Ces considérations peuvent inclure :
- L’exhaustivité des noms d’établissements (aucune valeur manquante dans les colonnes clés)
- Les conventions de dénomination locales et les abréviations courantes, afin que la correspondance approximative puisse être configurée pour en tenir compte
- Le protocole pour les correspondances douteuses
Voici un exemple de sortie de la correspondance approximative. L’algorithme compare les noms d’établissements de DHIS2 aux entrées de la MFL, attribuant un score de similarité à chaque correspondance. Des scores plus élevés (proches de 100) indiquent une similarité plus forte ; des scores plus faibles peuvent nécessiter une révision manuelle pour déterminer leur acceptabilité ou leur exclusion.
| Facility Name (DHIS2) | Best Match in MFL | Score | Decision |
|---|---|---|---|
| Makeni Govt. Hospital | Makeni Government Hospital | 96 | High confidence |
| Makeni Goverment Hospital | Makeni Government Hospital | 93 | High confidence |
| Police CHC | Police Community Health Center | 90 | High confidence |
| Loreto Clinic | Clinic Loreto | 88 | High confidence |
| Centre Medical | Centre Médical | 85 | High confidence |
| An-Nour Hospital | An-Noor Hospital | 82 | Accept with caution |
| Rahma Clinic | Rahmah Clinic | 87 | High confidence |
| Bo MCHP | Bo Maternal Child Health Post | 84 | Accept with caution |
| Clinic A | Kenema Government Hospital | 41 | Needs manual review |
| ABC Health Post | Makeni Government Hospital | 29 | Needs manual review |
Le tableau ci-dessus illustre des scénarios de correspondance approximative susceptibles de se présenter. Voici quelques exemples des types de variations que nous traitons :
- Abréviations :
Bo MCHP → Bo Maternal Child Health Post - Incohérences orthographiques ou fautes de frappe :
Makeni Goverment Hospital → Makeni Government Hospital - Différences de formatage :
Police CHC → Police Community Health Center - Variations dans l’ordre des mots :
Loreto Clinic → Clinic Loreto - Accents incohérents :
Centre Medical → Centre Médical - Translittérations incohérentes :
Rahma Clinic → Rahmah Clinic
Choisir une stratégie de correspondance
La correspondance approximative des noms implique de définir ce qui compte comme « similaire » et de décider quels types de différences (comme l’orthographe, l’ordre ou les abréviations) sont acceptables. Nous discutons ici de la manière d’évaluer la qualité des correspondances et du moment d’utiliser différents types d’algorithmes de similarité de chaînes de caractères. Comprendre ces concepts permet de s’assurer que les méthodes que nous appliquons sont adaptées aux types de non-correspondances que nous attendons dans les données.
Choisir parmi les algorithmes de correspondance de chaînes
Différents algorithmes sont mieux adaptés à différents types de non-correspondance, tels que les fautes de frappe, les abréviations ou l’ordre des mots. Le choix du bon algorithme dépend des incohérences spécifiques dans les données. Il peut être utile d’essayer plusieurs algorithmes pour couvrir différents types d’incohérences. Nous présentons ci-dessous les principaux algorithmes, leurs points forts et leurs limites.
Distance de Levenshtein (distance d’édition)
Compte le nombre d’éditions de caractères uniques (insertions, suppressions, substitutions) nécessaires pour transformer une chaîne en une autre.
- Idéal pour : Les fautes de frappe et les erreurs d’orthographe
- Exemple :
Makeni Goverment Hospital → Makeni Government Hospital - Limites : Ne gère pas les transpositions de mots ou les différences phonétiques
Similarité de Jaro-Winkler
Mesure le chevauchement de caractères et les transpositions, avec un poids supplémentaire pour les préfixes communs.
- Idéal pour : L’alignement de préfixes et les petits réarrangements
- Exemples :
Loreto Clinic → Clinic Loreto, ouMakeni Govt Hospital → Makeni Government Hospital - Limites : Faible avec les mots manquants ou les abréviations
Distance Q-gram
Compare des séquences qui se chevauchent (par exemple, des fragments de 2 ou 3 caractères) entre des chaînes.
- Idéal pour : Le chevauchement de sous-chaînes et la détection approximative de sous-chaînes
- Exemple :
Kenema Town MCHP → Kenema MCH Post - Limites : Peut sur-pénaliser les noms courts ou les problèmes d’espacement
Plus longue sous-séquence commune (LCS)
Trouve la plus longue séquence de caractères apparaissant de gauche à droite dans les deux chaînes (pas nécessairement de manière contiguë).
- Idéal pour : Les correspondances partielles avec des insertions
- Exemple :
St Mary Hosp → Saint Mary Hospital - Limites : Ignore les changements d’espacement et d’ordre au-delà de l’alignement de séquences
Soundex et autres algorithmes phonétiques
Convertissent les mots en codes phonétiques basés sur leur prononciation.
- Idéal pour : Les noms avec des orthographes différentes mais une prononciation similaire
- Exemples :
Rahma Clinic → Rahmah Clinic, ouAn-Nour Hospital → An-Noor Hospital - Limites : Échoue avec les non-correspondances structurelles ou basées sur des abréviations
Bonnes pratiques pour un flux de travail de correspondance approximative efficace
La correspondance approximative n’est aussi efficace que la préparation et les règles de décision qui la soutiennent. Cette section décrit les étapes clés et les bonnes pratiques qui améliorent la précision, la transparence et l’efficacité du flux de travail de correspondance. Voici quelques conseils pour améliorer la correspondance approximative :
Conseil 1 : Travailler à partir d’une copie nettoyée de la colonne de noms originale
Toujours conserver la colonne de noms d’établissements originale et effectuer toutes les étapes de nettoyage sur une nouvelle copie. Cela garantit :
- Que nous pouvons toujours nous référer aux noms originaux non modifiés
- Que toutes les jointures et correspondances approximatives s’effectuent sur la version nettoyée et standardisée
- Que nous conservons la possibilité d’inspecter et de résoudre manuellement les enregistrements à faible confiance ou non appariés en utilisant les noms originaux non formatés
Cette séparation est particulièrement utile pour les flux de travail de correspondance manuelle, où le jugement humain repose sur la lecture des noms tels qu’ils apparaissaient à l’origine.
Conseil 2 : Prétraiter le texte pour réduire le bruit
Avant d’exécuter tout algorithme de correspondance, nettoyer et normaliser le texte. La liste ci-dessous fournit plusieurs suggestions ; vérifier si chacune est pertinente dans le contexte du projet :
- Supprimer les espaces supplémentaires pour éviter les fausses non-correspondances
- Supprimer les espaces en début et fin : Supprimer les espaces supplémentaires au début ou à la fin du texte
- Réduire les espaces multiples : Remplacer les espaces répétés par un seul espace
- Standardiser les caractères de texte pour assurer la cohérence
- Convertir tout le texte en minuscules : Assurer la cohérence quelle que soit la casse originale
- Normaliser les caractères accentués : Convertir des caractères comme « é » en « e »
- Standardiser les caractères non textuels
- Standardiser la ponctuation : Remplacer ou supprimer la ponctuation pour réduire la variation non pertinente
- Convertir les chiffres romains en nombres : par exemple, « Koinadugu II CHC » → « Koinadugu 2 CHC »
- Standardiser l’utilisation des mots, le cas échéant
- Trier les mots alphabétiquement dans chaque nom : Gérer les différences d’ordre des mots en divisant les noms en mots, en les triant et en les réassemblant. Par exemple, « Port Loko CHC » et « CHC Port Loko » deviennent tous deux « CHC Loko Port », les rendant directement comparables malgré les différences de convention de dénomination.
Cette étape réduit la variation non pertinente et allège la charge de travail des algorithmes.
Conseil 3 : Gérer les abréviations et les termes spécifiques au domaine
Les abréviations et les termes locaux dans les noms d’établissements peuvent entraîner des non-correspondances si elles ne sont pas standardisées. Selon le contexte, nous pouvons soit développer les abréviations (par exemple, CHC → Community Health Center) soit contracter les formes longues en formes abrégées standard. Chaque approche peut donner des résultats de correspondance différents. L’important est d’appliquer la transformation de manière cohérente aux deux jeux de données.
Exemples de variations :
CHCvsCommunity Health CenterPHUvsPeripheral Health UnitMCHPvsMaternal and Child Health Post
Pratiques recommandées :
- Construire un dictionnaire d’abréviations simple pour le contexte du projet
- Appliquer des règles de substitution (par exemple, remplacer tous les
CHCparCommunity Health Center) avant d’exécuter les algorithmes de correspondance - Utiliser des expansions ou contractions spécifiques au domaine lorsque cela est approprié
TipConseil : identifier les abréviations probables
Nous pouvons analyser les champs de noms d’établissements pour détecter les abréviations potentielles en recherchant des tokens courts en majuscules qui apparaissent dans des chaînes plus longues. Une heuristique courante est :
Rechercher des séquences de 2 à 5 lettres en majuscules qui apparaissent de manière autonome parmi des mots en minuscules ou en casse mixte.
Cela trouve souvent des abréviations comme CHC, PHU ou MCHP intégrées dans des noms tels que Bo MCHP ou Kailahun PHU. Cette vérification peut être faite à l’œil nu ou avec du code.
Conseil 4 : Limiter la portée de la correspondance à l’aide d’informations géographiques
La correspondance approximative est plus précise et efficace lorsqu’elle est restreinte à une portée géographique plausible. Au lieu de comparer chaque nom d’établissement DHIS2 avec chaque nom MFL dans tout le pays, limiter les comparaisons à la même unité administrative, comme adm1 (région) ou adm3 (chefferie), selon la qualité des données disponibles.
- Par exemple, ne comparer que les noms où
adm1etadm3sont identiques pour les deux établissements - Cela accélère le traitement et garantit que les établissements de même nom dans des zones géographiques différentes ne sont pas mistakenly mis en correspondance
Cette approche suppose que :
- Les champs administratifs (
adm1,adm2,adm3) sont déjà nettoyés et harmonisés entre les jeux de données DHIS2 et MFL - Les établissements sont correctement assignés à leurs unités administratives, sans erreurs d’affectation majeures ni affectations manquantes
- Les établissements restants non appariés sont bien des non-correspondances de noms, et non des non-correspondances géographiques nécessitant une correction spatiale
Les approches de correspondance approximative décrites sur cette page peuvent être utilisées pour nettoyer et faire correspondre les noms des unités administratives.
En ancrant la correspondance approximative dans une logique géographique, cette étape améliore à la fois la pertinence et la fiabilité des résultats de correspondance.
Conseil 5 : Appliquer plusieurs algorithmes de similarité
Plutôt que de s’appuyer sur un seul algorithme, sélectionner la meilleure correspondance en fonction du score le plus élevé parmi plusieurs algorithmes de correspondance, tout en tenant compte des vérifications de qualité complémentaires. Cette approche « correspondance d’abord » assure de la flexibilité et évite de verrouiller les décisions sur une seule métrique.
C’est important car chaque algorithme de correspondance approximative capture un aspect différent de la similarité. Par exemple :
- Levenshtein : Adapté aux fautes de frappe et aux suppressions
- Jaro-Winkler : Sensible aux transpositions de caractères et à la concordance de préfixes
- Qgram / LCS : Détecte les chevauchements de mots réordonnés ou partiels
- Ensemble de rangs : Priorise l’accord entre les méthodes en comparant les positions de rang
- Scores composites : Intègre plusieurs métriques pour un meilleur consensus
En comparant et en combinant les sorties de ces méthodes, nous pouvons mieux gérer les diverses incohérences trouvées dans les jeux de données réels.
Conseil 6 : Réviser et valider avec l’équipe SNT
La correspondance automatisée peut produire de bons résultats, mais la révision humaine est requise. Toujours vérifier :
- Les correspondances à haute confiance (85+) : Très probablement une vraie correspondance et peuvent être rapidement vérifiées à l’œil nu
- Les correspondances à confiance moyenne (70–84) : Peuvent nécessiter une correction
- Les scores faibles (en dessous de 70) : Probablement des fausses correspondances
- Les noms d’apparence similaire dans des districts différents : Peuvent indiquer une sur-correspondance
- Les établissements non appariés : Peuvent nécessiter une révision manuelle ou des mises à jour de la base de données
ImportantValider avec l’équipe SNT
Toujours procéder à une révision structurée des résultats finaux de correspondance avec l’équipe SNT. La validation garantit que l’équipe SNT applique ses connaissances locales et prévient les erreurs de classification, en particulier lorsque les correspondances orientent la planification, la cartographie des établissements ou l’analyse de couverture.
Aperçu du flux de travail de correspondance
Cet aperçu explique la réconciliation de bout en bout utilisée en Sierra Leone pour faire correspondre les noms d’établissements DHIS2 à la MFL nationale. Le flux de travail est auditable, donne la priorité aux correspondances à haute confiance en premier et produit une seule table prête pour révision avec la correspondance sélectionnée, les diagnostics de similarité, les indicateurs de décision (accepter/réviser) et des identifiants stables pour une utilisation en aval.
Approche en deux phases
- Phase 1 : Correspondance géographique stratifiée (
adm2/adm3) : Ancrer les comparaisons dans les limites administratives pour capturer la plupart des correspondances avec une haute confiance et détecter précocement les administrations mal assignées - Phase 2 : Correspondance approximative des noms sur les établissements restants : Standardiser les noms, générer des candidats sans contraintes géographiques, noter avec plusieurs algorithmes et utiliser les diagnostics pour sélectionner les correspondances à réviser ou à accepter
Résumé du processus en 11 étapes
Suivre ces 11 étapes ; le code détaillé et exécutable apparaît dans la section suivante.
- Installer et charger les bibliothèques requises pour la manipulation des données, la correspondance approximative de chaînes et la gestion des fichiers.
- Charger les données des sources DHIS2 et de la liste principale des établissements avec un nettoyage initial.
- Effectuer des diagnostics de correspondance initiaux pour évaluer les taux de correspondances exactes, l’alignement administratif et les modèles de noms en double.
- Appliquer la correspondance géographique stratifiée interactive pour résoudre les correspondances à haute confiance à l’aide de contraintes géographiques et de validation humaine.
- Traiter et préparer les données non appariées en standardisant les noms et en gérant les abréviations pour réduire les variations.
- Effectuer la correspondance approximative sur les établissements non appariés restants en construisant des grilles de candidats, en calculant des scores de similarité, en créant des scores composites et en extrayant les meilleures correspondances.
- Évaluer la qualité des correspondances approximatives à l’aide de diagnostics, de visualisations et d’un seuillage pondéré basé sur la qualité structurelle.
- Finaliser la sélection des correspondances approximatives à l’aide de l’une des quatre stratégies : méthode unique, score composite, composite pondéré ou boucle de repli progressive.
- Combiner tous les résultats appariés des approches de correspondance stratifiée et approximative en un jeu de données complet.
- Effectuer des vérifications finales pour valider les résultats de correspondance et identifier les problèmes restants.
- Sauvegarder les jeux de données finaux comprenant les résultats appariés, les établissements non appariés et les statistiques récapitulatives pour l’analyse en aval.
Ensemble, les deux phases minimisent la réconciliation manuelle tout en maintenant les cas ambigus transparents pour la révision de l’équipe SNT.
Diagramme du flux de travail
Le diagramme ci-dessous résume le processus en phases, du diagnostic à la sortie finale.
NoteQuand suivre chaque chemin
- Pour une correspondance approximative directe sans stratification géographique, suivre le chemin violet de l’Étape 3 → Étape 5 (en contournant l’Étape 4).
- Pour le flux de travail de correspondance complet avec stratification géographique, suivre toutes les étapes séquentiellement de l’Étape 3 à l’Étape 11.
Cela offre de la flexibilité : ignorer la stratification si seule la correspondance basée sur les noms est nécessaire, ou l’inclure lorsque le contexte de localisation est important.
Après la correspondance géographique stratifiée, un plus petit ensemble d’établissements reste non résolu. Ceux-ci sont généralement dus à des unités administratives mal assignées, des établissements nouvellement ouverts ou fermés, ou des variations de noms trop importantes pour que la correspondance géographique puisse les résoudre. Ces enregistrements non appariés passent ensuite à l’Étape 5, où la standardisation et la correspondance approximative offrent une autre opportunité de récupérer des correspondances valides.
Étape par étape
Suivre le flux de travail en 11 étapes décrit dans l’Aperçu du flux de travail de correspondance. Les sections ci-dessous fournissent du code exécutable spécifique à la Sierra Leone pour chaque étape et des notes sur la manière de l’adapter au contexte du projet.
Pour passer l’explication étape par étape, aller directement au code complet en bas de cette page.
Étape 1 : Installer et charger les bibliothèques requises
Installer et charger les paquets nécessaires pour la manipulation des données, la correspondance approximative de chaînes et la gestion des fichiers.
# vérifier si 'pacman' est installé ; l'installer s'il est absent
if (!requireNamespace("pacman", quietly = TRUE)) {
install.packages("pacman")
}
# charger tous les paquets requis avec pacman
pacman::p_load(
readxl, # pour lire les fichiers Excel
dplyr, # pour la manipulation des données
stringdist, # pour calculer les distances de chaînes (correspondance approximative)
tibble, # pour travailler avec des data frames modernes
knitr, # pour créer des tables formatées
openxlsx, # pour écrire des fichiers Excel
httr, # pour les requêtes HTTP afin de télécharger des fichiers (optionnel)
here # pour les chemins de fichiers multiplateforme
)
WarningTerminal installation required
Install packages in your terminal, if not already installed. If you need help installing packages, please refer to the Getting Started page.
from pathlib import Path
import re
import unicodedata
import numpy as np
import pandas as pd
import pyreadr
import matplotlib.pyplot as plt
from pyprojroot import here
from rapidfuzz.distance import Levenshtein, JaroWinkler
from rapidfuzz import fuzz
def read_rds(path):
"""Read a single-object RDS file as a pandas DataFrame."""
result = pyreadr.read_r(str(path))
return next(iter(result.values()))
def cli_header(message):
print(f"\n{message}")
def cli_info(message):
print(f"INFO: {message}")
def cli_success(message):
print(f"SUCCESS: {message}")
def cli_warning(message):
print(f"WARNING: {message}")
def cli_danger(message):
print(f"ERROR: {message}")
def anti_join(left, right, on):
"""Return rows in left with no matching key in right."""
right_keys = right[on].drop_duplicates()
return (
left.merge(right_keys, on=on, how="left", indicator=True)
.loc[lambda x: x["_merge"] == "left_only"]
.drop(columns="_merge")
)
def show_table(df, n=10, caption=None):
"""Render a compact scrollable HTML table with the .out-table style.
Chunks calling this must set #| results: asis."""
from IPython.display import display, HTML
rows = df.head(n)
cap_html = f"<caption>{caption}</caption>" if caption else ""
table_html = rows.to_html(
index=False,
classes="out-table",
border=0,
na_rep="",
)
# inject caption before the table header
if cap_html:
table_html = table_html.replace(
"<thead>", cap_html + "<thead>", 1
)
display(HTML(f'<div class="out-scroll">{table_html}</div>'))Pour adapter le code :
- Conserver ces imports et ces fonctions auxiliaires en haut du flux de travail Python. Les blocs Python suivants les utilisent pour la correspondance approximative, le chargement des données et la sortie de diagnostics.
Étape 2 : Charger les données
Cette étape importe les jeux de données des établissements de santé DHIS2 et MFL. Elle crée ensuite dhis2_hf_df, qui contient les unités administratives uniques et les noms d’établissements pour la correspondance approximative. Enfin, elle affiche des échantillons de chaque jeu de données pour examiner les colonnes et prévisualiser les premières lignes, afin de s’assurer que les sorties sont conformes aux attentes.
Afficher le code
# configurer le chemin vers les données hf dhis2
dhis2_path <- here::here(
"01_data",
"1.2_epidemiology",
"1.2a_routine_surveillance",
"processed"
)
hf_path <- here::here(
"01_data",
"1.1_foundational",
"1.1c_health_facilities",
"processed"
)
# lire les données des établissements de santé DHIS2
dhis2_df <- readRDS(
here::here(dhis2_path, "sle_dhis2_with_clean_adm3.rds")
) |>
# renommer les colonnes de noms d'établissements pour la clarté et la cohérence
dplyr::rename(hf_dhis2_raw = hf)
# obtenir les colonnes admin et hf distinctes
dhis2_hf_df <- dhis2_df |>
dplyr::distinct(adm0, adm1, adm2, adm3, hf_dhis2_raw)
# lire les données des établissements de santé de la MFL
master_hf_df <- read.csv(
here::here(hf_path, "hf_final_clean_data.csv")
) |>
dplyr::distinct(
adm0, adm1, adm2, adm3, hf, lat, long, .keep_all = TRUE
) |>
# renommer les colonnes de noms d'établissements pour la clarté et la cohérence
dplyr::mutate(hf_mfl_raw = hf)
# attacher un identifiant stable d'établissement DHIS2 pour un comptage cohérent
# entre les étapes
# distinct par géographie + nom pour éviter les collisions entre admins
dhis2_map <- dhis2_df |>
dplyr::distinct(adm0, adm1, adm2, adm3, hf) |>
dplyr::mutate(
hf_uid_new = paste0(
"hf_uid_new::",
as.integer(as.factor(paste(
tolower(stringr::str_squish(adm0)),
tolower(stringr::str_squish(adm1)),
tolower(stringr::str_squish(adm2)),
tolower(stringr::str_squish(adm3)),
tolower(stringr::str_squish(hf)),
sep = "|"
)))
)
)
# afficher les premières lignes des données
cli::cli_h3("Sample of DHIS2 data:")
head(dhis2_hf_df)
cli::cli_h3("Sample of MFL data:")
head(master_hf_df)Pour adapter le code :
- Lignes 2–7 : Mettre à jour les chemins du fichier dhis2 pour correspondre à l’emplacement des fichiers de données.
- Lignes 9–14 : Mettre à jour les chemins du fichier MFL pour correspondre à l’emplacement des fichiers de données.
- Lignes 18, 29 : Modifier les noms de fichiers pour correspondre aux fichiers de données spécifiques.
- Lignes 21, 35 : Mettre à jour
hfet les colonnes renommées (hf_mfl_raw,hf_dhis2_raw) pour correspondre aux colonnes réelles de noms d’établissements dans les jeux de données.
Afficher le code
# configurer le chemin vers les données hf dhis2
dhis2_path = Path(here("01_data/1.2_epidemiology/1.2a_routine_surveillance/processed"))
hf_path = Path(here("01_data/1.1_foundational/1.1c_health_facilities/processed"))
# lire les données des établissements de santé DHIS2
dhis2_df = read_rds(dhis2_path / "sle_dhis2_with_clean_adm3.rds")
dhis2_df = dhis2_df.assign(hf_dhis2_raw=dhis2_df["hf"])
# obtenir les colonnes admin et hf distinctes
dhis2_hf_df = dhis2_df[
["adm0", "adm1", "adm2", "adm3", "hf", "hf_dhis2_raw"]
].drop_duplicates()
# lire les données des établissements de santé de la MFL
master_hf_df = pd.read_csv(hf_path / "hf_final_clean_data.csv")
master_hf_df = (
master_hf_df
.drop_duplicates(subset=["adm0", "adm1", "adm2", "adm3", "hf", "lat", "long"])
.assign(hf_mfl_raw=lambda d: d["hf"])
)
# attacher un identifiant stable d'établissement DHIS2
dhis2_map = (
dhis2_df[["adm0", "adm1", "adm2", "adm3", "hf"]]
.drop_duplicates()
.assign(
hf_uid_new=lambda d: "hf_uid_new::" + (
d["adm0"].str.lower().str.strip() + "|" +
d["adm1"].str.lower().str.strip() + "|" +
d["adm2"].str.lower().str.strip() + "|" +
d["adm3"].str.lower().str.strip() + "|" +
d["hf"].str.lower().str.strip()
).astype("category").cat.codes.astype(str)
)
)
# afficher les premières lignes des données
cli_header("Sample of DHIS2 data:")
dhis2_hf_df.head()
cli_header("Sample of MFL data:")
master_hf_df.head()Pour adapter le code :
- Lignes 2–3 : Mettre à jour les chemins des fichiers dhis2 et MFL pour correspondre à l’emplacement des fichiers de données.
- Lignes 6, 14 : Modifier les noms de fichiers pour correspondre aux fichiers de données spécifiques.
- Lignes 8, 19 : Mettre à jour
hfet les colonnes renommées (hf_mfl_raw,hf_dhis2_raw) pour correspondre aux colonnes réelles de noms d’établissements dans les jeux de données.
Étape 3 : Diagnostics de correspondance initiaux
Avant toute tentative de correspondance, nous évaluons les données de manière systématique pour comprendre le défi de la correspondance. Nous décomposons cela en trois vérifications ciblées : les correspondances exactes globales, les modèles de correspondance au niveau administratif et les problèmes de noms en double.
Étape 3.1 : Vérification globale des correspondances exactes
Ensuite, nous vérifions les correspondances exactes globales sans contraintes administratives et calculons le potentiel de correspondance total.
Afficher le code
# vérifier les correspondances exactes sur les noms bruts (sans contrainte admin)
exact_matches_all <- dhis2_hf_df |>
dplyr::inner_join(
master_hf_df,
by = c("hf_dhis2_raw" = "hf_mfl_raw"),
relationship = "many-to-many"
)
# calculer le potentiel de correspondance
total_dhis2 <- nrow(dhis2_hf_df)
total_mfl <- nrow(master_hf_df)
unmatched_dhis2 <- total_dhis2 - nrow(exact_matches_all)
cli::cli_h3("Résumé global des correspondances")
cli::cli_alert_info("Total des établissements DHIS2 : {total_dhis2}")
cli::cli_alert_info("Total des établissements MFL : {total_mfl}")
cli::cli_alert_success(
paste0(
"Correspondances exactes trouvées : {nrow(exact_matches_all)} (",
"{round(nrow(exact_matches_all)/total_dhis2*100, 1)}%)
)
)
cli::cli_alert_warning("Restant à faire correspondre : {unmatched_dhis2}")Pour adapter le code :
- Ligne 5 : Mettre à jour les colonnes de jointure pour correspondre aux champs de noms d’établissements.
Afficher le code
# vérifier les correspondances exactes sur les noms bruts (sans contrainte admin)
exact_matches_all = dhis2_hf_df.merge(
master_hf_df[["hf_mfl_raw"]],
left_on="hf_dhis2_raw",
right_on="hf_mfl_raw",
how="inner",
)
# calculer le potentiel de correspondance
total_dhis2 = len(dhis2_hf_df)
total_mfl = len(master_hf_df)
unmatched_dhis2 = total_dhis2 - len(exact_matches_all)
cli_header("Résumé global des correspondances")
cli_info(f"Total des établissements DHIS2 : {total_dhis2}")
cli_info(f"Total des établissements MFL : {total_mfl}")
cli_success(
f"Correspondances exactes trouvées : {len(exact_matches_all)} "
f"({round(len(exact_matches_all) / total_dhis2 * 100, 1)}%)"
)
cli_warning(f"Restant à faire correspondre : {unmatched_dhis2}")Pour adapter le code :
- Ligne 5 : Mettre à jour les colonnes de jointure pour correspondre aux champs de noms d’établissements.
La majorité des établissements correspondent exactement par nom, comme le montre la sortie ci-dessus. Cette base de référence met en évidence la portée avant d’appliquer des approches de correspondance géographique ou approximative.
Étape 3.2 : Vérification des correspondances au niveau administratif
Nous examinons d’abord comment les établissements correspondent lorsque nous prenons en compte les limites administratives, en vérifiant les correspondances aux niveaux adm2 (district) et adm3 (chefferie).
Afficher le code
# vérifier les correspondances au niveau adm2 (district)
dhis2_by_adm2 <- dhis2_hf_df |>
dplyr::group_by(adm2) |>
dplyr::summarise(total_dhis2 = dplyr::n())
matches_by_adm2 <- dhis2_hf_df |>
dplyr::inner_join(
master_hf_df,
by = c("hf_dhis2_raw" = "hf_mfl_raw", "adm2")
) |>
dplyr::group_by(adm2) |>
dplyr::summarise(exact_matches = dplyr::n()) |>
dplyr::left_join(dhis2_by_adm2, by = "adm2") |>
dplyr::mutate(
match_rate = round(exact_matches / total_dhis2 * 100, 1)
) |>
dplyr::select(adm2, exact_matches, total_dhis2, match_rate) |>
dplyr::arrange(dplyr::desc(match_rate))
cli::cli_h3("Correspondances exactes par district (adm2))
matches_by_adm2
# vérifier les correspondances au niveau adm3 (chefferie/sous-district)
dhis2_by_adm3 <- dhis2_hf_df |>
dplyr::group_by(adm2, adm3) |>
dplyr::summarise(total_dhis2 = dplyr::n(), .groups = "drop")
matches_by_adm3 <- dhis2_hf_df |>
dplyr::inner_join(
master_hf_df,
by = c("hf_dhis2_raw" = "hf_mfl_raw", "adm2", "adm3")
) |>
dplyr::group_by(adm2, adm3) |>
dplyr::summarise(exact_matches = dplyr::n(), .groups = "drop") |>
dplyr::left_join(dhis2_by_adm3, by = c("adm2", "adm3")) |>
dplyr::mutate(
match_rate = round(exact_matches / total_dhis2 * 100, 1)
) |>
dplyr::filter(total_dhis2 >= 5) |> # afficher seulement les zones avec 5+ établissements
dplyr::arrange(dplyr::desc(match_rate)) |>
dplyr::slice_head(n = 10) # afficher les 10 meilleures zones adm3
cli::cli_h3("Meilleures correspondances exactes par chefferie (adm3))
matches_by_adm3Pour adapter le code :
- Ligne 9 : Mettre à jour les colonnes de jointure pour correspondre aux champs de noms d’établissements.
- Ligne 11 : Modifier la colonne d’unité administrative (
adm2) pour correspondre au niveau district. - Lignes 25, 31 : Mettre à jour les colonnes
adm2etadm3pour correspondre au niveau sous-district.
Afficher le code
# vérifier les correspondances au niveau adm2 (district)
dhis2_by_adm2 = (
dhis2_hf_df.groupby("adm2", as_index=False)
.agg(total_dhis2=("hf_dhis2_raw", "count"))
)
matches_by_adm2 = (
dhis2_hf_df
.merge(
master_hf_df[["hf_mfl_raw", "adm2"]],
left_on=["hf_dhis2_raw", "adm2"],
right_on=["hf_mfl_raw", "adm2"],
how="inner",
)
.groupby("adm2", as_index=False)
.agg(exact_matches=("hf_dhis2_raw", "count"))
.merge(dhis2_by_adm2, on="adm2", how="left")
.assign(match_rate=lambda d: (d["exact_matches"] / d["total_dhis2"] * 100).round(1))
[["adm2", "exact_matches", "total_dhis2", "match_rate"]]
.sort_values("match_rate", ascending=False)
)
cli_header("Correspondances exactes par district (adm2)")
matches_by_adm2
# vérifier les correspondances au niveau adm3 (chefferie/sous-district)
dhis2_by_adm3 = (
dhis2_hf_df.groupby(["adm2", "adm3"], as_index=False)
.agg(total_dhis2=("hf_dhis2_raw", "count"))
)
matches_by_adm3 = (
dhis2_hf_df
.merge(
master_hf_df[["hf_mfl_raw", "adm2", "adm3"]],
left_on=["hf_dhis2_raw", "adm2", "adm3"],
right_on=["hf_mfl_raw", "adm2", "adm3"],
how="inner",
)
.groupby(["adm2", "adm3"], as_index=False)
.agg(exact_matches=("hf_dhis2_raw", "count"))
.merge(dhis2_by_adm3, on=["adm2", "adm3"], how="left")
.assign(match_rate=lambda d: (d["exact_matches"] / d["total_dhis2"] * 100).round(1))
.loc[lambda d: d["total_dhis2"] >= 5]
.sort_values("match_rate", ascending=False)
.head(10)
)
cli_header("Meilleures correspondances exactes par chefferie (adm3)")
matches_by_adm3Pour adapter le code :
- Ligne 9 : Mettre à jour les colonnes de jointure pour correspondre aux champs de noms d’établissements.
- Ligne 11 : Modifier la colonne d’unité administrative (
adm2) pour correspondre au niveau district. - Lignes 31, 39 : Mettre à jour les colonnes
adm2etadm3pour correspondre au niveau sous-district.
Les taux de correspondance par district varient considérablement, de 86 % (Karene) à 39 % (Western Urban). Certaines chefferies atteignent 100 % de correspondances tandis que d’autres sont en difficulté. Cela montre quelles zones ont des noms propres et standardisés par rapport à celles qui nécessitent un travail de correspondance intensif.
Étape 3.3 : Vérification des noms en double
Enfin, nous vérifions les noms d’établissements en double pour comprendre les complications potentielles de la correspondance.
Afficher le code
# vérifier les doublons dans le même adm2 (problématique)
dhis2_dups_adm2 <- dhis2_hf_df |>
dplyr::group_by(adm2, hf_dhis2_raw) |>
dplyr::filter(dplyr::n() > 1) |>
dplyr::arrange(adm2, hf_dhis2_raw)
mfl_dups_adm2 <- master_hf_df |>
dplyr::group_by(adm2, hf_mfl_raw) |>
dplyr::filter(dplyr::n() > 1) |>
dplyr::arrange(adm2, hf_mfl_raw)
cli::cli_h3("Doublons dans le même district (adm2)")
cli::cli_alert_warning(
paste0(
"Doublons DHIS2 dans les districts : ",
"{length(unique(dhis2_dups_adm2$hf_dhis2_raw))}"
)
)
cli::cli_alert_warning(
paste0(
"Doublons MFL dans les districts : ",
"{length(unique(mfl_dups_adm2$hf_mfl_raw))}"
)
)
# vérifier les doublons dans le même adm3 (très problématique)
dhis2_dups_adm3 <- dhis2_hf_df |>
dplyr::group_by(adm2, adm3, hf_dhis2_raw) |>
dplyr::filter(dplyr::n() > 1) |>
dplyr::arrange(adm2, adm3, hf_dhis2_raw)
mfl_dups_adm3 <- master_hf_df |>
dplyr::group_by(adm2, adm3, hf_mfl_raw) |>
dplyr::filter(dplyr::n() > 1) |>
dplyr::arrange(adm2, adm3, hf_mfl_raw)
cli::cli_h3("Doublons dans la même chefferie (adm3)")
cli::cli_alert_danger(
paste0(
"Doublons DHIS2 dans les chefferies : ",
"{length(unique(dhis2_dups_adm3$hf_dhis2_raw))}"
)
)
cli::cli_alert_danger(
paste0(
"Doublons MFL dans les chefferies : ",
"{length(unique(mfl_dups_adm3$hf_mfl_raw))}"
)
)
# vérifier les doublons globaux (gérables avec le contexte géographique)
dhis2_dups_overall <- dhis2_hf_df |>
dplyr::group_by(hf_dhis2_raw) |>
dplyr::filter(dplyr::n() > 1) |>
dplyr::arrange(hf_dhis2_raw)
mfl_dups_overall <- master_hf_df |>
dplyr::group_by(hf_mfl_raw) |>
dplyr::filter(dplyr::n() > 1) |>
dplyr::arrange(hf_mfl_raw)
cli::cli_h3("Noms en double globaux (dans toutes les zones)")
cli::cli_alert_info(
"Doublons globaux DHIS2 : {length(
unique(dhis2_dups_overall$hf_dhis2_raw)
)}"
)
cli::cli_alert_info(
"Doublons globaux MFL : {length(
unique(mfl_dups_overall$hf_mfl_raw)
)}"
)Pour adapter le code :
- Lignes 3–4, 8–9 : Mettre à jour les colonnes
adm2et de noms d’établissements. - Lignes 28–29, 33–34 : Mettre à jour les colonnes
adm2,adm3et de noms d’établissements. - Lignes 54, 56, 59, 61 : Mettre à jour les colonnes de noms d’établissements pour les doublons globaux.
Afficher le code
# vérifier les doublons dans le même adm2 (problématique)
dhis2_dups_adm2 = (
dhis2_hf_df
.groupby(["adm2", "hf_dhis2_raw"])
.filter(lambda x: len(x) > 1)
.sort_values(["adm2", "hf_dhis2_raw"])
)
mfl_dups_adm2 = (
master_hf_df
.groupby(["adm2", "hf_mfl_raw"])
.filter(lambda x: len(x) > 1)
.sort_values(["adm2", "hf_mfl_raw"])
)
cli_header("Doublons dans le même district (adm2)")
cli_warning(
f"Doublons DHIS2 dans les districts : {dhis2_dups_adm2['hf_dhis2_raw'].nunique()}"
)
cli_warning(
f"Doublons MFL dans les districts : {mfl_dups_adm2['hf_mfl_raw'].nunique()}"
)
# vérifier les doublons dans le même adm3 (très problématique)
dhis2_dups_adm3 = (
dhis2_hf_df
.groupby(["adm2", "adm3", "hf_dhis2_raw"])
.filter(lambda x: len(x) > 1)
.sort_values(["adm2", "adm3", "hf_dhis2_raw"])
)
mfl_dups_adm3 = (
master_hf_df
.groupby(["adm2", "adm3", "hf_mfl_raw"])
.filter(lambda x: len(x) > 1)
.sort_values(["adm2", "adm3", "hf_mfl_raw"])
)
cli_header("Doublons dans la même chefferie (adm3)")
cli_danger(
f"Doublons DHIS2 dans les chefferies : {dhis2_dups_adm3['hf_dhis2_raw'].nunique()}"
)
cli_danger(
f"Doublons MFL dans les chefferies : {mfl_dups_adm3['hf_mfl_raw'].nunique()}"
)
# vérifier les doublons globaux (gérables avec le contexte géographique)
dhis2_dups_overall = (
dhis2_hf_df
.groupby("hf_dhis2_raw")
.filter(lambda x: len(x) > 1)
.sort_values("hf_dhis2_raw")
)
mfl_dups_overall = (
master_hf_df
.groupby("hf_mfl_raw")
.filter(lambda x: len(x) > 1)
.sort_values("hf_mfl_raw")
)
cli_header("Noms en double globaux (dans toutes les zones)")
cli_info(f"Doublons globaux DHIS2 : {dhis2_dups_overall['hf_dhis2_raw'].nunique()}")
cli_info(f"Doublons globaux MFL : {mfl_dups_overall['hf_mfl_raw'].nunique()}")Pour adapter le code :
- Lignes 3–4, 8–9 : Mettre à jour les colonnes
adm2et de noms d’établissements. - Lignes 26–27, 31–32 : Mettre à jour les colonnes
adm2,adm3et de noms d’établissements. - Lignes 49, 54 : Mettre à jour les colonnes de noms d’établissements pour les doublons globaux.
Les doublons sont peu nombreux au niveau de la chefferie mais plus visibles dans les districts, où DHIS2 en répertorie deux fois plus que la MFL. Au niveau national, la MFL présente beaucoup plus de noms en double (49 vs 19). Ces tendances soulignent la nécessité d’utiliser la géographie et des identifiants uniques en complément des noms pour éviter les erreurs de correspondance.
Étape 4 : Correspondance géographique stratifiée interactive
Avant de standardiser les noms ou d’effectuer une correspondance approximative, la stratification géographique combinée au jugement de l’utilisateur peut être utilisée pour résoudre la plupart des correspondances d’établissements par le biais d’une correspondance interactive. Cette approche combine la précision de la révision humaine avec l’efficacité des suggestions automatisées, en utilisant l’approche décrite dans Fusionner des shapefiles avec des données tabulaires mais appliquée ici au niveau des établissements de santé.
La fonction prep_geonames() (disponible sous sntutils::prep_geonames() en R et sntutils.geo.prep_geonames() en Python) gère l’ensemble de ce processus, y compris la standardisation interne des noms, la stratification géographique et la correspondance interactive ou automatisée selon les besoins de l’utilisateur.
Afficher le code
# jointure interne (conserver uniquement les polygones appariés)
# configurer l'emplacement de sauvegarde du cache
cache_loc <- "01_data/1.1_foundational/1.1f_cache_files/processed"
# correspondance stratifiée interactive avec standardisation automatique
# cette fonction gère la standardisation des noms en interne
dhis2_df_cleaned <-
sntutils::prep_geonames(
target_df = dhis2_hf_df, # jeu de données à nettoyer
lookup_df = master_hf_df, # jeu de données de référence avec les admins corrects
level0 = "adm0",
level1 = "adm1",
level2 = "adm2",
level3 = "adm3",
level4 = "hf",
cache_path = here::here(cache_loc, "geoname_cache.rds"),
unmatched_export_path = here::here(cache_loc, "dhis2_hf_unmatched.rds")
)
# charger les établissements non appariés pour traitement ultérieur (étapes 5–8
# correspondance approximative)
dhis2_hf_to_process <- readRDS(
here::here(cache_loc, "dhis2_hf_unmatched.rds")
) |>
dplyr::select(adm0, adm1, adm2, adm3, hf_dhis2_raw = hf)
# statistiques récapitulatives
n_original <- nrow(dhis2_hf_df)
n_matched <- n_original - nrow(dhis2_hf_to_process)
match_rate <- (n_matched / n_original) * 100
cli::cli_alert_success(
paste0(
"Correspondance stratifiée terminée : ",
"{format(n_matched, big.mark = ',')}/{format(n_original, big.mark = ',')}",
" établissements appariés ({round(match_rate, 1)}%)"
)
)
cli::cli_alert_info(
"Non appariés restants : {nrow(dhis2_hf_to_process)} établissements"
)Pour adapter le code :
- Ligne 3 : Mettre à jour
cache_locpour pointer vers le dossier de sauvegarde du fichier cache et de l’export des établissements non appariés. Cela devrait être un emplacement stable réutilisable dans les étapes suivantes (par exemple,"01_data/1.1_foundational/1.1f_cache_files/processed"). - Lignes 9–10 : Remplacer
dhis2_hf_dfetmaster_hf_dfpar les noms des jeux de données. - Lignes 11–15 : Mettre à jour les noms de colonnes pour correspondre à la hiérarchie géographique (
adm0,adm1,adm2,adm3) et à la colonne de noms d’établissements (hf). - Lignes 16–17 : Mettre à jour les chemins de fichiers pour le cache (
cache_path) et l’export des établissements non appariés (unmatched_export_path), qui sera utilisé comme entrée pour les étapes de correspondance approximative (5–8). - Ligne 23 : Utiliser le même chemin que
unmatched_export_pathpour charger les données des établissements non appariés pour les étapes de nettoyage et de correspondance approximative suivantes.
WarningTerminal installation required
Afficher le code
from sntutils.geo import prep_geonames
# configurer l'emplacement de sauvegarde du cache
cache_loc = "01_data/1.1_foundational/1.1f_cache_files/processed"
# correspondance stratifiée interactive avec standardisation automatique
dhis2_df_cleaned = prep_geonames(
target_df=dhis2_hf_df,
lookup_df=master_hf_df,
level0="adm0",
level1="adm1",
level2="adm2",
level3="adm3",
level4="hf",
cache_path=here(cache_loc, "geoname_cache.csv"),
unmatched_export_path=here(cache_loc, "dhis2_hf_unmatched.csv"),
)
# charger les établissements non appariés pour traitement ultérieur (étapes 5–8)
dhis2_hf_to_process = pd.read_csv(
here(cache_loc, "dhis2_hf_unmatched.csv")
).rename(columns={"hf": "hf_dhis2_raw"})
# statistiques récapitulatives
n_original = len(dhis2_hf_df)
n_matched = n_original - len(dhis2_hf_to_process)
match_rate = n_matched / n_original * 100
cli_success(
f"Correspondance stratifiée terminée : {n_matched:,}/{n_original:,} "
f"établissements appariés ({round(match_rate, 1)}%)"
)
cli_info(f"Non appariés restants : {len(dhis2_hf_to_process)} établissements")Pour adapter le code :
- Ligne 3 : Mettre à jour
cache_locpour pointer vers le dossier de sauvegarde du fichier cache et de l’export des établissements non appariés. - Lignes 8–9 : Remplacer
dhis2_hf_dfetmaster_hf_dfpar les noms des jeux de données. - Lignes 10–14 : Mettre à jour les noms de colonnes pour correspondre à la hiérarchie géographique (
adm0,adm1,adm2,adm3) et à la colonne de noms d’établissements (hf). - Lignes 15–16 : Mettre à jour les chemins de fichiers pour le cache et l’export des établissements non appariés.
- Ligne 21 : Utiliser le même chemin que
unmatched_export_pathpour charger les établissements non appariés.
Avec notre correspondance stratifiée interactive, nous avons apparié 1 203 des 1 771 établissements (67,9 %). Tous les niveaux administratifs ont correspondu parfaitement, mais certains établissements restent non appariés au niveau du nom. Les résultats suggèrent que la combinaison des contraintes géographiques avec la validation humaine est efficace, laissant un sous-ensemble plus restreint d’établissements encore à traiter.
ImportantValider avec l’équipe SNT
Les résultats mis en cache doivent toujours être validés avec l’équipe SNT avant l’intégration. Cette étape de révision aide à :
- Confirmer les correspondances en utilisant les connaissances locales, en particulier pour les noms courants ou similaires
- Résoudre les ambiguïtés lorsque des établissements sont mal assignés ou ont plusieurs candidats
- Assurer la cohérence avec les normes et classifications nationales de dénomination
- Documenter les décisions pour soutenir une harmonisation future et réduire les efforts répétés
Le cache est à la fois un enregistrement de validation et une ressource pour améliorer la qualité des données au fil du temps. Le tableau ci-dessous montre le contenu du cache sauvegardé du processus de correspondance stratifiée (cache_path).
Le cache peut également être réutilisé lors d’exécutions futures pour éviter de répéter la correspondance interactive. Il préserve les décisions passées, assure la cohérence et fournit un point de départ efficace pour la mise à jour des noms d’établissements avec l’équipe SNT.
L’étape suivante consiste à faire passer ces établissements non appariés dans le pipeline de standardisation et de correspondance approximative pour récupérer les correspondances valides restantes. ### Étape 5 : Traiter et préparer les données non appariées pour la correspondance floue
Après la correspondance géographique stratifiée, un sous-ensemble de structures reste non résolu. Ces cas sont généralement dus à des unités administratives mal attribuées, à des structures nouvellement ouvertes ou fermées, ou à des variations de noms trop importantes pour être résolues par la correspondance géographique. Pour traiter ces cas, l’Étape 5 se concentre sur la préparation des données non appariées en standardisant les noms et en gérant les abréviations, afin de réduire la variabilité avant d’appliquer la correspondance floue.
Étape 5.1 : Standardiser les noms des structures sanitaires
Nous appliquons maintenant la standardisation aux structures non appariées. Cette étape aide à résoudre les correspondances qui ont échoué en raison de différences de formatage :
Comme indiqué dans la section Bonnes pratiques pour un flux de correspondance floue efficace, nous commençons par standardiser les colonnes de noms de structures sanitaires. Pour cela, nous appliquons d’abord des opérations courantes de nettoyage du texte : conversion en minuscules, suppression des espaces superflus, retrait de la ponctuation, réduction des espaces multiples, normalisation des caractères accentués et conversion des chiffres romains (par exemple, II, III) en forme numérique standard (par exemple, 2, 3). Chaque nom est ensuite divisé en mots individuels, trié par ordre alphabétique et recombineé, ce qui permet de traiter de manière cohérente les noms composés des mêmes mots dans des ordres différents. Ces étapes de prétraitement réduisent la variabilité non pertinente et améliorent la fiabilité de la correspondance floue en aval.
Dans cet exemple illustratif, nous appliquons toutes les options de standardisation disponibles afin que le code soit disponible pour chacune d’elles. Cependant, certaines de ces étapes peuvent être inutiles ou entraîner des correspondances inattendues pour un projet donné. Il convient d’examiner attentivement les options de standardisation à inclure dans le flux de travail. Créer plusieurs versions avec plus ou moins d’étapes de standardisation peut aider à éclairer la décision finale.
Afficher le code
# créer une fonction pour standardiser les noms des structures sanitaires
standardize_names <- function(name_vec) {
# valider l'entrée
if (!rlang::is_atomic(name_vec)) {
cli::cli_abort("`name_vec` must be an atomic vector.")
}
name_vec |>
# s'assurer du type caractère
as.character() |>
# convertir en minuscules
stringr::str_to_lower() |>
# remplacer la ponctuation par un espace
stringr::str_replace_all("[[:punct:]]", " ") |>
# supprimer les espaces superflus et rogner
stringr::str_squish() |>
# normaliser les accents
stringi::stri_trans_general("Latin-ASCII") |>
# normaliser tous les caractères d'espace
stringi::stri_replace_all_regex("\\p{Zs}+", " ") |>
# convertir les chiffres romains en chiffres arabes
stringr::str_replace_all(
c(
" ix\\b" = " 9",
" viii\\b" = " 8",
" vii\\b" = " 7",
" vi\\b" = " 6",
" v\\b" = " 5",
" iv\\b" = " 4",
" iii\\b" = " 3",
" ii\\b" = " 2",
" i\\b" = " 1"
)
) |>
# trier les tokens : lettres en premier, chiffres en dernier ; tri
# alphabétique au sein de chaque groupe
purrr::map_chr(\(.x) {
# diviser sur un ou plusieurs espaces
tokens <- strsplit(.x, " +")[[1]]
# détecter les tokens purement numériques
is_num <- stringr::str_detect(tokens, "^[0-9]+$")
# ordonner les alphabétiques en premier, puis les numériques ; trier dans chaque groupe
ordered <- c(sort(tokens[!is_num]), sort(tokens[is_num]))
# rejoindre
paste(ordered, collapse = " ")
})
}
# préparer un exemple avec un formatage irrégulier
example_word <- factor("Clínica! Rahmâ IV ( New clinic) East")
# afficher la structure originale
cat("\nExample before standardization:\n")
str(example_word)
# appliquer la standardisation
example_word_st <- standardize_names(example_word)
# afficher l'exemple nettoyé
cat("\nExample after standardization:\n")
str(example_word_st)Pour adapter le code :
- Lignes 1–50 : Pour conserver l’ensemble complet des standardisations, laisser la fonction
standardize_namestelle quelle. Sinon, supprimer les standardisations inutiles.
Afficher le code
import unicodedata
def standardize_names(series):
"""Standardize health facility name strings for fuzzy matching.
Applies lowercase conversion, punctuation removal, accent normalization,
Roman numeral conversion, and alphabetical token sorting.
"""
roman_map = {
r"\bix\b": "9", r"\bviii\b": "8", r"\bvii\b": "7",
r"\bvi\b": "6", r"\bv\b": "5", r"\biv\b": "4",
r"\biii\b": "3", r"\bii\b": "2", r"\bi\b": "1",
}
def _clean(text):
if pd.isna(text):
return text
text = str(text).lower()
# remplacer la ponctuation par un espace
text = re.sub(r"[^\w\s]", " ", text)
# réduire les espaces multiples
text = re.sub(r"\s+", " ", text).strip()
# normaliser les accents
text = unicodedata.normalize("NFD", text)
text = "".join(c for c in text if unicodedata.category(c) != "Mn")
# convertir les chiffres romains
for pattern, replacement in roman_map.items():
text = re.sub(pattern, replacement, text)
# trier les tokens : lettres en premier (alphabétique), chiffres en dernier
tokens = text.split()
alpha = sorted(t for t in tokens if not t.isdigit())
numeric = sorted(t for t in tokens if t.isdigit())
return " ".join(alpha + numeric)
return series.apply(_clean)
# préparer un exemple avec un formatage irrégulier
example_word = "Clínica! Rahmâ IV ( New clinic) East"
# afficher l'original
print(f"\nExample before standardization:\n{example_word}")
# appliquer la standardisation
example_word_st = standardize_names(pd.Series([example_word]))[0]
# afficher l'exemple nettoyé
print(f"\nExample after standardization:\n{example_word_st}")Pour adapter le code :
- Lignes 1–42 : Pour conserver l’ensemble complet des standardisations, laisser la fonction
standardize_namestelle quelle. Sinon, supprimer les standardisations inutiles.
La fonction a fonctionné comme prévu : elle a transformé le facteur original Clínica! Rahmâ IV ( New clinic) East en une chaîne de caractères propre clinic clinica east new rahma 4. Cela confirme que les étapes de standardisation ont fonctionné comme prévu.
- Le nom original contenait des espaces superflus, des accents, de la ponctuation et des chiffres romains.
- Tout le texte a été converti en minuscules.
- La ponctuation a été remplacée par des espaces, et les espaces multiples ont été réduits à un seul.
- Les accents ont été supprimés et les chiffres romains ont été convertis en chiffres arabes.
- Les mots ont été divisés, triés par ordre alphabétique, et les chiffres placés en dernier.
Nous allons maintenant appliquer la fonction de standardisation aux colonnes de noms des structures DHIS2 et MFL afin d’assurer un formatage cohérent. Cela permet de s’assurer que les scores de similarité de chaînes reflètent de véritables différences et non des artefacts d’un formatage de texte incohérent.
Afficher le code
# supprimer les doublons du MFL et formater la colonne des structures
master_hf_df <- master_hf_df |>
dplyr::distinct(hf_mfl_raw, .keep_all = TRUE) |>
dplyr::mutate(hf_mfl = standardize_names(hf_mfl_raw))
# important : conserver le jeu de données complet original avant de traiter
# les non-appariés (c'est notre N de base)
dhis2_hf_df_original <- dhis2_hf_df |>
dplyr::mutate(hf_dhis2 = standardize_names(hf_dhis2_raw))
# construire un identifiant stable géo-contextualisé et l'attacher aux originaux et aux non-appariés
hf_uid_new_map <- dhis2_hf_df |>
dplyr::distinct(adm0, adm1, adm2, adm3, hf_dhis2_raw) |>
dplyr::mutate(
hf_uid_new = paste0(
"hf_uid_new::",
as.integer(as.factor(paste(
tolower(stringr::str_squish(adm0)),
tolower(stringr::str_squish(adm1)),
tolower(stringr::str_squish(adm2)),
tolower(stringr::str_squish(adm3)),
tolower(stringr::str_squish(hf_dhis2_raw)),
sep = "|"
)))
)
)
dhis2_hf_df_original <- dhis2_hf_df_original |>
dplyr::left_join(
hf_uid_new_map,
by = c(
"adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw"
)
)
# traiter uniquement les structures non appariées pour les étapes de correspondance floue
dhis2_hf_unmatched <- dhis2_hf_to_process |>
dplyr::mutate(hf_dhis2 = standardize_names(hf_dhis2_raw)) |>
dplyr::left_join(
hf_uid_new_map |>
dplyr::mutate(hf_dhis2_raw = toupper(hf_dhis2_raw)),
by = c(
"adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw"
)
)
knitr::kable(
# vérifier si cela a fonctionné
dhis2_hf_unmatched |>
dplyr::distinct(hf_dhis2_raw, hf_dhis2) |>
dplyr::slice_head(n = 10)
)Pour adapter le code :
- Lignes 2–4 : Mettre à jour les noms de colonnes pour correspondre aux données (
hf_mfl_raw,hf_dhis2_raw,hf_mfl,hf_dhis2). - Ligne 3 : Modifier la fonction
distinct()pour utiliser différents critères de suppression des doublons si nécessaire. - Lignes 6–9 : Créer
dhis2_hf_df_originalpour conserver toutes les structures originales (c’est notre N de base qui sera utilisé à l’Étape 9.2). - Lignes 37–45 : Créer
dhis2_hf_unmatchedpour les étapes de correspondance floue ; les étapes suivantes doivent utiliser cet objet à la place dedhis2_hf_df.
Afficher le code
# supprimer les doublons du MFL et créer la colonne standardisée
master_hf_df = (
master_hf_df
.drop_duplicates(subset="hf_mfl_raw")
.assign(hf_mfl=lambda d: standardize_names(d["hf_mfl_raw"]))
)
# conserver le jeu de données complet original avant de traiter les non-appariés
dhis2_hf_df_original = dhis2_hf_df.assign(
hf_dhis2=lambda d: standardize_names(d["hf_dhis2_raw"])
)
# construire la table de correspondance des identifiants géo-contextualisés
hf_uid_new_map = (
dhis2_hf_df[["adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw"]]
.drop_duplicates()
.assign(
hf_uid_new=lambda d: "hf_uid_new::" + (
d["adm0"].str.lower().str.strip() + "|" +
d["adm1"].str.lower().str.strip() + "|" +
d["adm2"].str.lower().str.strip() + "|" +
d["adm3"].str.lower().str.strip() + "|" +
d["hf_dhis2_raw"].str.lower().str.strip()
).astype("category").cat.codes.astype(str)
)
)
dhis2_hf_df_original = dhis2_hf_df_original.merge(
hf_uid_new_map,
on=["adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw"],
how="left",
)
# traiter uniquement les structures non appariées pour les étapes de correspondance floue
dhis2_hf_unmatched = (
dhis2_hf_to_process
.assign(hf_dhis2=lambda d: standardize_names(d["hf_dhis2_raw"]))
.merge(
hf_uid_new_map.assign(
hf_dhis2_raw=lambda d: d["hf_dhis2_raw"].str.upper()
),
on=["adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw"],
how="left",
)
)
# vérifier si la standardisation a fonctionné
dhis2_hf_unmatched[["hf_dhis2_raw", "hf_dhis2"]].drop_duplicates().head(10)Pour adapter le code :
- Lignes 2–4 : Mettre à jour les noms de colonnes pour correspondre aux données (
hf_mfl_raw,hf_dhis2_raw,hf_mfl,hf_dhis2). - Ligne 3 : Modifier
drop_duplicates()pour utiliser différents critères de suppression des doublons si nécessaire. - Lignes 7–9 : Créer
dhis2_hf_df_originalpour conserver toutes les structures originales. - Lignes 37–44 : Créer
dhis2_hf_unmatchedpour les étapes de correspondance floue ; les étapes suivantes doivent utiliser cet objet à la place dedhis2_hf_df.
Nous conservons les colonnes originales (hf_mfl_raw, hf_dhis2_raw) inchangées et créons des versions standardisées (hf_mfl, hf_dhis2) pour la mise en correspondance. Cela préserve les noms bruts pour un examen ultérieur ou une correspondance manuelle.
Étape 5.2 : Gérer les abréviations dans les noms de structures sanitaires
Les noms de structures sanitaires dans DHIS2 et dans le MFL peuvent contenir des abréviations telles que CHC, PHU ou MCHP. Si ces abréviations sont utilisées de manière incohérente d’un jeu de données à l’autre ou au sein d’un même jeu, la standardisation peut améliorer la précision de la correspondance.
Pour améliorer la cohérence et la qualité des correspondances, nous commençons par identifier les abréviations fréquemment utilisées dans les deux jeux de données en analysant les motifs de mots. Plutôt que d’étendre ces abréviations en leur forme complète, ce qui peut introduire une verbosité et un bruit inutiles, nous avons choisi d’appliquer un dictionnaire prédéfini pour standardiser les deux jeux de données afin qu’ils utilisent des abréviations. Cette approche simplifie les structures des noms, raccourcit les longueurs de chaînes et réduit l’influence des termes génériques répétitifs sur les scores de similarité.
Nous comptons le nombre d’occurrences de chaque abréviation dans les jeux de données (freq) et définissons une « vraie » abréviation comme celle qui apparaît plus de 2 fois.
Afficher le code
abbrev_dictionary <-
dplyr::bind_rows(
dplyr::select(dhis2_hf_unmatched, hf = hf_dhis2_raw),
dplyr::select( master_hf_df, hf = hf_mfl_raw)) |>
# diviser en mots
tidyr::separate_rows(hf, sep = " ") |>
# supprimer les entrées vides
dplyr::filter(hf != "") |>
# détecter les motifs de 2 à 4 lettres majuscules
dplyr::filter(stringr::str_detect(hf, "^[A-Z]{2,4}$")) |>
# compter les fréquences
dplyr::count(hf, sort = TRUE) |>
# renommer pour plus de clarté
dplyr::rename(word = hf, freq = n) |>
dplyr::filter(freq > 2) |>
as.data.frame()
# vérifier la sortie
abbrev_dictionaryPour adapter le code :
- Ligne 10 : Modifier le motif
{2,4}pour changer la plage de longueur de caractères des abréviations détectées (actuellement 2 à 4 caractères). - Ligne 15 : Modifier le seuil de fréquence (
freq > 2) selon le contexte du projet : l’abaisser pour capturer plus d’abréviations potentielles ou l’augmenter pour se concentrer sur les plus fréquentes. - Gérer les noms en majuscules : Si les noms de structures sont entièrement en majuscules, ce motif de détection peut ne pas fonctionner comme prévu. Envisager un prétraitement pour convertir les noms en casse titre ou d’ajuster le motif de détection.
Afficher le code
# combiner les noms DHIS2 et MFL pour la détection des abréviations
all_names = pd.concat([
dhis2_hf_unmatched[["hf_dhis2_raw"]].rename(columns={"hf_dhis2_raw": "hf"}),
master_hf_df[["hf_mfl_raw"]].rename(columns={"hf_mfl_raw": "hf"}),
])
# diviser en mots et filtrer les tokens de 2 à 4 lettres majuscules
abbrev_dictionary = (
all_names["hf"]
.dropna()
.str.split(expand=True)
.stack()
.reset_index(drop=True)
.rename("word")
.loc[lambda s: s.str.match(r"^[A-Z]{2,4}$")]
.value_counts()
.reset_index()
.rename(columns={"count": "freq"})
.loc[lambda d: d["freq"] > 2]
)
# vérifier la sortie
abbrev_dictionaryPour adapter le code :
- Ligne 15 : Modifier le motif
{2,4}pour changer la plage de longueur de caractères des abréviations détectées. - Ligne 19 : Modifier le seuil de fréquence (
freq > 2) selon le contexte du projet.
Maintenant que nous avons identifié les abréviations courantes (par exemple, MCHP, CHP, CHC), nous utilisons un dictionnaire partagé pour standardiser les noms de structures sanitaires dans les deux jeux de données. Plutôt que d’étendre ces termes, nous nous assurons qu’ils sont utilisés de manière cohérente sous forme d’abréviations dans DHIS2 et dans le MFL. Même au sein du MFL, certains noms peuvent utiliser des abréviations tandis que d’autres utilisent des termes complets. La standardisation aide à aligner ces différences et améliore la précision des correspondances.
WarningLimitation : gestion des fautes d’orthographe et des variantes
Cette approche par dictionnaire d’abréviations présente des limites lorsqu’il s’agit de termes mal orthographiés ou de variantes. Par exemple :
- Si « Community Health Center » est mal orthographié en « Comunity Health Center », la recherche dans le dictionnaire ne trouvera pas de correspondance
- Les variations régionales comme « Health Centre » vs « Health Center » peuvent ne pas être capturées
- Les fautes de frappe dans les abréviations elles-mêmes (par exemple,
CHCvsCHS) ne seront pas standardisées
Stratégies d’atténuation :
- Utiliser des algorithmes de correspondance floue à l’Étape 4 pour gérer les correspondances résiduelles après la standardisation des abréviations
- Envisager d’ajouter les fautes d’orthographe courantes au dictionnaire si elles apparaissent fréquemment
- Mettre en œuvre des étapes supplémentaires de nettoyage du texte (vérification orthographique, standardisation des variantes) avant d’appliquer le dictionnaire d’abréviations
Afficher le code
# définir le dictionnaire d'abréviations (tout en minuscules, car nous utilisons
# la colonne standardisée)
abbrev_dict <- c(
"maternal child health post" = "mchp",
"community health post" = "chp",
"community health center" = "chc",
"urban maternal clinic" = "umi",
"expanded programme on immunization" = "epi"
)
# appliquer les remplacements aux noms MFL
master_hf_df <- master_hf_df |>
dplyr::mutate(
hf_mfl = stringr::str_replace_all(hf_mfl, abbrev_dict)
)
# appliquer les remplacements aux noms DHIS2
dhis2_hf_unmatched <- dhis2_hf_unmatched |>
dplyr::mutate(
hf_dhis2 = stringr::str_replace_all(hf_dhis2, abbrev_dict)
)
# vérifier : démontrer la standardisation des abréviations
dhis2_hf_unmatched |>
dplyr::filter(
stringr::str_detect(
hf_dhis2_raw,
paste0(
"(?i)Community Health Center|Maternal Child Health Post|",
"Community Health Post"
)
) |
stringr::str_detect(hf_dhis2_raw, "CHC|MCHP|CHP")
) |>
dplyr::select(hf_dhis2_raw, hf_dhis2) |>
head()Pour adapter le code :
- Lignes 3–9 : Modifier
abbrev_dictsi les données incluent d’autres abréviations fréquentes. - Lignes 14, 20 : Utiliser les colonnes standardisées en minuscules (
hf_mflethf_dhis2) créées à l’Étape 5.1. N’appliquer cette étape qu’après avoir confirmé les abréviations par des vérifications de fréquence (voir Étape 5.2).
Afficher le code
# définir le dictionnaire d'abréviations (tout en minuscules, en utilisant la colonne standardisée)
abbrev_dict = {
"maternal child health post": "mchp",
"community health post": "chp",
"community health center": "chc",
"urban maternal clinic": "umi",
"expanded programme on immunization": "epi",
}
# appliquer les remplacements aux noms MFL
for long_form, short_form in abbrev_dict.items():
master_hf_df["hf_mfl"] = master_hf_df["hf_mfl"].str.replace(
long_form, short_form, regex=False
)
# appliquer les remplacements aux noms DHIS2
for long_form, short_form in abbrev_dict.items():
dhis2_hf_unmatched["hf_dhis2"] = dhis2_hf_unmatched["hf_dhis2"].str.replace(
long_form, short_form, regex=False
)
# vérifier : démontrer la standardisation des abréviations
dhis2_hf_unmatched.loc[
dhis2_hf_unmatched["hf_dhis2_raw"].str.contains(
r"(?i)Community Health Center|Maternal Child Health Post|Community Health Post|CHC|MCHP|CHP",
regex=True,
na=False,
),
["hf_dhis2_raw", "hf_dhis2"],
].drop_duplicates().head()Pour adapter le code :
- Lignes 3–9 : Modifier
abbrev_dictsi les données incluent d’autres abréviations fréquentes. - Lignes 13, 20 : Utiliser les colonnes standardisées en minuscules (
hf_mflethf_dhis2) créées à l’Étape 5.1.
Étape 6 : Effectuer la correspondance floue sur les structures restantes non appariées
Nous appliquons maintenant des algorithmes de correspondance floue aux structures qui restent non appariées après la correspondance géographique stratifiée de l’Étape 4. Ces cas représentent les plus difficiles, où l’alignement géographique ou la similarité des noms n’a pas permis d’établir une correspondance claire.
NoteTraitement des structures restantes non appariées
Cette étape se concentre sur les structures qui n’ont pas pu être appariées par : - l’Étape 4 : Correspondance géographique stratifiée interactive - l’Étape 5 : Standardisation des noms et correspondance exacte
Ces structures restantes présentent souvent des désalignements géographiques ou des variations de noms importantes qui nécessitent des approches de correspondance plus flexibles.
Dans notre exemple, nous cherchons à trouver une correspondance MFL pour chaque structure DHIS2 restante non appariée. Pour faire la correspondance dans l’autre sens (identifier une correspondance DHIS2 pour chaque structure MFL), ou dans les deux sens, modifier et/ou répéter le code en conséquence.
Étape 6.1 : Identifier les structures appariées et non appariées
Nous identifions d’abord les correspondances exactes entre les noms de structures DHIS2 et MFL, avant et après la standardisation du texte. Ces correspondances exactes sont mises de côté pendant que nous nous concentrons sur les structures non appariées pour la correspondance floue.
Nous utilisons une correspondance plusieurs-à-un, ce qui signifie que plusieurs enregistrements DHIS2 peuvent être liés à la même structure MFL si leurs noms sont suffisamment similaires. Cette approche aide à évaluer la fiabilité des liens et signale les incohérences de nommage potentielles. Il est également possible d’observer des détections plusieurs-à-plusieurs, par exemple lorsque la même structure sanitaire apparaît dans DHIS2 sous différentes orthographes ou formats et correspond à plusieurs structures candidates dans le MFL. Ces cas nécessitent un examen plus attentif pour confirmer le lien correct.
La sortie de cette étape est constituée des noms DHIS2 non appariés qui seront traités par les algorithmes de correspondance floue.
Afficher le code
# indicateur pour l'application de la règle un-à-un
enforce_one_to_one <- FALSE
# correspondances exactes utilisant les noms bruts
matched_dhis2_raw <- dhis2_hf_unmatched |>
dplyr::select(
adm0, adm1, adm2, adm3, hf_dhis2_raw, hf_uid_new
) |>
dplyr::inner_join(
master_hf_df |>
dplyr::select(hf_mfl_raw),
by = c("hf_dhis2_raw" = "hf_mfl_raw")
)
# correspondances exactes utilisant les noms standardisés
matched_dhis2 <- dhis2_hf_unmatched |>
dplyr::select(
adm0, adm1, adm2, adm3, hf_dhis2_raw, hf_dhis2, hf_uid_new
) |>
dplyr::inner_join(
master_hf_df |>
dplyr::select(hf_mfl_raw, hf_mfl),
by = c("hf_dhis2" = "hf_mfl"),
keep = TRUE
) |>
# exclure les structures déjà appariées via les noms bruts
dplyr::anti_join(matched_dhis2_raw, by = c("hf_dhis2_raw")) |>
# étiqueter les correspondances exactes
dplyr::mutate(
final_method = paste0(
"Matched Without Fuzzy Matching (standardization)"
),
score = 100
)
# inclure uniquement les structures réellement appariées via la
# standardisation géographique
# ce sont les structures ayant bénéficié de corrections géographiques
matched_dhis2_prepgeoname <-
dhis2_df_cleaned |>
dplyr::anti_join(
dhis2_hf_unmatched,
by = c("adm0", "adm1", "adm2", "adm3", "hf" = "hf_dhis2_raw")
) |>
dplyr::left_join(
master_hf_df |>
dplyr::mutate(hf = toupper(hf)) |>
dplyr::select(adm0, adm1, adm2, adm3, hf, hf_mfl_raw, hf_mfl),
by = c("adm0", "adm1", "adm2", "adm3", "hf")
) |>
# attacher hf_uid_new depuis dhis2_map (par admin + hf)
dplyr::left_join(
dhis2_map |> dplyr::select(adm0, adm1, adm2, adm3, hf, hf_uid_new),
by = c("adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw" = "hf")
) |>
# étiqueter les correspondances
dplyr::mutate(
final_method = "Interactive Stratified Geographic Matching",
score = 100
)
# calculer les non-appariés après standardisation
unmatched_dhis2 <- dhis2_hf_unmatched |>
dplyr::select(hf_dhis2) |>
dplyr::anti_join(
master_hf_df |>
dplyr::select(hf_mfl),
by = c("hf_dhis2" = "hf_mfl")
) |>
dplyr::distinct(hf_dhis2)
# collecter les MFL déjà appariés pour appliquer la règle un-à-un dans le pool de candidats
used_mfl_stand <- matched_dhis2 |>
dplyr::pull(hf_mfl) |>
unique()
use_mfl_prepgeoname <- matched_dhis2_prepgeoname |>
dplyr::pull(hf_mfl) |>
unique()
used_mfl <- c(used_mfl_stand, use_mfl_prepgeoname)
# construire le pool de candidats MFL pour l'étape de correspondance floue
candidate_mfl_df <- master_hf_df |>
dplyr::select(hf_mfl)
# si la règle un-à-un est appliquée, exclure les MFL déjà utilisés par les correspondances exactes
if (enforce_one_to_one) {
candidate_mfl_df <- candidate_mfl_df |>
dplyr::filter(!hf_mfl %in% used_mfl)
}
# comptages récapitulatifs
total_dhis2_hf <- dplyr::n_distinct(dhis2_hf_unmatched$hf_dhis2_raw)
raw_match_dhis2_hf <- dplyr::n_distinct(matched_dhis2_raw$hf_dhis2_raw)
raw_unmatch_dhis2_hf <- total_dhis2_hf - raw_match_dhis2_hf
standardized_match_dhis2_hf <- dplyr::n_distinct(matched_dhis2$hf_dhis2)
standardized_unmatch_dhis2_hf <- total_dhis2_hf - standardized_match_dhis2_hf
total_mfl_hf <- dplyr::n_distinct(master_hf_df$hf_mfl)
candidate_mfl_count <- dplyr::n_distinct(candidate_mfl_df$hf_mfl)
# afficher le récapitulatif
cli::cli_h2("Récapitulatif du statut de correspondance")
cli::cli_alert_info(
"Total des structures DHIS2 : {format(total_dhis2_hf, big.mark = ',')}"
)
cli::cli_alert_success(
paste0(
"Appariées après standardisation : ",
"{format(standardized_match_dhis2_hf, big.mark = ',')}"
)
)
cli::cli_alert_danger(
paste0(
"Non appariées avec les noms bruts : ",
"{format(raw_unmatch_dhis2_hf, big.mark = ',')}"
)
)
cli::cli_alert_danger(
paste0(
"Non appariées après standardisation : ",
"{format(standardized_unmatch_dhis2_hf, big.mark = ',')}"
)
)
cli::cli_alert_info(
paste0(
"Structures MFL dans le pool de candidats pour la correspondance : ",
"{format(candidate_mfl_count, big.mark = ',')} sur ",
"{format(total_mfl_hf, big.mark = ',')}"
)
)Pour adapter le code :
- Ligne 2 : Définir
enforce_one_to_oneàTRUEpour empêcher la réutilisation d’un hf_mfl déjà apparié exactement. Définir àFALSEpour autoriser les correspondances un-à-plusieurs. - Lignes 15, 18 : Remplacer les noms de colonnes :
hf_dhis2ethf_mflpar les champs de noms standardisés ;hf_dhis2_rawethf_mfl_rawpar les champs de noms bruts. - Lignes 14, 17 : Remplacer les noms de jeux de données :
dhis2_hf_unmatchedpar le jeu de données DHIS2 non apparié ;master_hf_dfpar le jeu de données MFL. - Lignes 61–68 :
unmatched_dhis2contient les structures DHIS2 non appariées au MFL et sera transmis à l’étape de correspondance floue. - Lignes 88–91 : Filtre un-à-plusieurs. Conserver tel quel pour exclure les hf_mfl déjà appariés lorsque
enforce_one_to_one == FALSE. Supprimer ces lignes pour toujours autoriser la réutilisation.
Afficher le code
# indicateur pour l'application de la règle un-à-un
enforce_one_to_one = False
# correspondances exactes utilisant les noms bruts
matched_dhis2_raw = (
dhis2_hf_unmatched[["adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw", "hf_uid_new"]]
.merge(
master_hf_df[["hf_mfl_raw"]],
left_on="hf_dhis2_raw",
right_on="hf_mfl_raw",
how="inner",
)
)
# correspondances exactes utilisant les noms standardisés
matched_dhis2 = (
dhis2_hf_unmatched[
["adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw", "hf_dhis2", "hf_uid_new"]
]
.merge(
master_hf_df[["hf_mfl_raw", "hf_mfl"]],
left_on="hf_dhis2",
right_on="hf_mfl",
how="inner",
)
)
# exclure les structures déjà appariées via les noms bruts
matched_dhis2 = anti_join(matched_dhis2, matched_dhis2_raw, on=["hf_dhis2_raw"])
matched_dhis2 = matched_dhis2.assign(
final_method="Matched Without Fuzzy Matching (standardization)",
score=100,
)
# calculer les non-appariés après standardisation
# anti-jointure à noms croisés : dhis2_hf_unmatched.hf_dhis2 vs master_hf_df.hf_mfl
unmatched_dhis2 = (
dhis2_hf_unmatched.loc[
~dhis2_hf_unmatched["hf_dhis2"].isin(master_hf_df["hf_mfl"]),
["hf_dhis2"],
]
.drop_duplicates(subset="hf_dhis2")
)
used_mfl = list(matched_dhis2["hf_mfl"].unique())
# construire le pool de candidats MFL pour l'étape de correspondance floue
candidate_mfl_df = master_hf_df[["hf_mfl"]].copy()
if enforce_one_to_one:
candidate_mfl_df = candidate_mfl_df.loc[~candidate_mfl_df["hf_mfl"].isin(used_mfl)]
# comptages récapitulatifs
total_dhis2_hf = dhis2_hf_unmatched["hf_dhis2_raw"].nunique()
raw_match_dhis2_hf = matched_dhis2_raw["hf_dhis2_raw"].nunique()
raw_unmatch_dhis2_hf = total_dhis2_hf - raw_match_dhis2_hf
standardized_match_dhis2_hf = matched_dhis2["hf_dhis2"].nunique()
standardized_unmatch_dhis2_hf = total_dhis2_hf - standardized_match_dhis2_hf
total_mfl_hf = master_hf_df["hf_mfl"].nunique()
candidate_mfl_count = candidate_mfl_df["hf_mfl"].nunique()
cli_header("Récapitulatif du statut de correspondance")
cli_info(f"Total des structures DHIS2 : {total_dhis2_hf:,}")
cli_success(f"Appariées après standardisation : {standardized_match_dhis2_hf:,}")
cli_danger(f"Non appariées avec les noms bruts : {raw_unmatch_dhis2_hf:,}")
cli_danger(f"Non appariées après standardisation : {standardized_unmatch_dhis2_hf:,}")
cli_info(
f"Structures MFL dans le pool de candidats pour la correspondance : "
f"{candidate_mfl_count:,} sur {total_mfl_hf:,}"
)Pour adapter le code :
- Ligne 2 : Définir
enforce_one_to_oneàTruepour empêcher la réutilisation d’un hf_mfl déjà apparié exactement. Définir àFalsepour autoriser les correspondances un-à-plusieurs. - Lignes 15, 18 : Remplacer les noms de colonnes :
hf_dhis2ethf_mflpar les champs de noms standardisés ;hf_dhis2_rawethf_mfl_rawpar les champs de noms bruts. - Lignes 14, 17 : Remplacer les noms de jeux de données :
dhis2_hf_unmatchedpar le jeu de données DHIS2 non apparié ;master_hf_dfpar le jeu de données MFL. - Lignes 37–39 :
unmatched_dhis2contient les structures DHIS2 non appariées au MFL et sera transmis à l’étape de correspondance floue.
Notre processus de standardisation a résolu certaines des structures DHIS2 initialement non appariées, comme le montre la sortie ci-dessus. Cela illustre la valeur du nettoyage du texte avant d’appliquer la correspondance floue. Les structures DHIS2 restantes non appariées sont l’objet de nos efforts de correspondance floue dans les étapes suivantes.
La sortie ci-dessus montre le nombre total de structures DHIS2 non appariées au stade des noms bruts, ainsi que les structures MFL qui restent dans le pool de candidats pour la correspondance floue après application de l’alignement un-à-plusieurs avec les correspondances DHIS2.
Nous utiliserons unmatched_dhis2 comme entrée pour la correspondance floue. Ces noms de structures DHIS2 standardisés n’ont pas pu être appariés par comparaison exacte de chaînes. Le jeu de données matched_dhis2 contient les noms de structures correspondant exactement après standardisation. Une fois la correspondance floue terminée, nous ajouterons ces correspondances exactes aux résultats finaux pour produire un jeu de données complet et joint.
Étape 6.1 : Créer la grille de correspondance
Une fois que nous identifions les noms unmatched_dhis2, l’étape suivante consiste à créer une grille de correspondance. Cette étape définit l’ensemble complet des paires de noms possibles que nous évaluerons ensuite par comparaison floue de chaînes. L’objectif de cette grille est de définir l’ensemble des paires candidates que nous souhaitons comparer à l’étape suivante, plutôt que de vérifier chaque nom contre tous les autres noms dans le jeu de données complet, ce qui serait coûteux en calcul et pourrait introduire de fausses correspondances.
Afficher le code
# créer une grille de correspondance complète pour la correspondance floue en
# associant chaque structure DHIS2 non appariée à toutes les structures MFL disponibles.
# créer le pool de candidats simple
candidate_match_pool <- tidyr::crossing(
unmatched_dhis2,
candidate_mfl_df
)
# créer la grille de correspondance avec les noms DHIS2 et MFL
match_grid <- candidate_match_pool
# aperçu de l'échantillon - 10 premières correspondances
match_grid |>
dplyr::slice_head(n = 10)Pour adapter le code :
- Lignes 7–8 : Remplacer
unmatched_dhis2etcandidate_mfl_dfpar les noms de jeux de données si différents.
Afficher le code
# créer une grille de correspondance complète pour la correspondance floue en
# associant chaque structure DHIS2 non appariée à toutes les structures MFL disponibles
candidate_match_pool = unmatched_dhis2.merge(candidate_mfl_df, how="cross")
# créer la grille de correspondance avec les noms DHIS2 et MFL
match_grid = candidate_match_pool.copy()
# aperçu de l'échantillon - 10 premières correspondances
match_grid.head(10)Pour adapter le code :
- Lignes 2–3 : Remplacer
unmatched_dhis2etcandidate_mfl_dfpar les noms de jeux de données si différents.
match_grid est une liste plate de paires de noms candidates. Chaque ligne lie un nom DHIS2 non apparié à une correspondance MFL possible. Il ne s’agit pas d’un résultat de correspondance floue, mais de l’ensemble complet des appariements qui seront évalués à l’Étape 6.3 à l’aide des algorithmes de distance de chaîne.
À ce stade, la grille ne contient que les noms de structures (hf_dhis2 et hf_mfl) pour rester légère. Les identifiants, coordonnées et autres métadonnées sont exclus pour l’instant et seront réattachés après la notation. Si des noms identiques apparaissent dans plusieurs emplacements, la grille peut être étendue avec des champs supplémentaires pour la désambiguïsation. L’aperçu montre un échantillon aléatoire de paires candidates. Il peut ne pas inclure de correspondances évidentes, mais aide à confirmer que la logique d’appariement et les filtres géographiques fonctionnent correctement. Cette grille est l’entrée de la correspondance floue, où chaque ligne sera notée et classée pour identifier les correspondances probables.
Étape 6.2 : Calculer les scores de similarité
Nous calculons la similarité des noms entre chaque structure DHIS2 non appariée et tous les candidats dans la liste maîtresse à l’aide de plusieurs algorithmes : Jaro-Winkler, Levenshtein, Qgram et LCS. Chaque algorithme capture différents types de variation, tels que les fautes de frappe, la troncature ou la réorganisation des mots, qui peuvent être présents dans les jeux de données réels.
Cette étape produit des scores de similarité individuels pour chaque méthode, nous permettant d’explorer, de comparer ou de prioriser des algorithmes spécifiques selon les objectifs de correspondance.
Afficher le code
# calculer les scores de correspondance floue
match_grid <- match_grid |>
dplyr::mutate(
len_max = pmax(nchar(hf_dhis2), nchar(hf_mfl)),
score_jw = 1 - stringdist::stringdist(hf_dhis2, hf_mfl, method = "jw"),
score_lv = 1 -
stringdist::stringdist(hf_dhis2, hf_mfl, method = "lv") / len_max,
score_qg = 1 -
stringdist::stringdist(hf_dhis2, hf_mfl, method = "qgram") / len_max,
score_lcs = 1 -
stringdist::stringdist(hf_dhis2, hf_mfl, method = "lcs") / len_max
) |>
dplyr::mutate(
dplyr::across(
.cols = dplyr::starts_with("score_"),
.fns = ~ ifelse(is.nan(.x) | .x < 0, 0, .x)
),
dplyr::across(
.cols = dplyr::contains("score_"),
.fns = ~ .x * 100
)
)Pour adapter le code :
- Lignes 4–10 : Ajouter ou retirer des algorithmes de similarité selon les besoins de correspondance. Consulter le manuel
stringdist, p.23 pour les méthodes disponibles.
Afficher le code
from rapidfuzz.distance import Levenshtein, JaroWinkler
from rapidfuzz import fuzz
def _score_lv(a, b):
"""Normalized Levenshtein similarity (0–100)."""
len_max = max(len(a), len(b))
if len_max == 0:
return 100.0
return max(0.0, (1 - Levenshtein.distance(a, b) / len_max) * 100)
def _score_jw(a, b):
"""Jaro-Winkler similarity (0–100)."""
return JaroWinkler.similarity(a, b) * 100
def _score_qg(a, b):
"""Q-gram similarity (0–100) using token sort ratio."""
return float(fuzz.token_sort_ratio(a, b))
def _score_lcs(a, b):
"""LCS-based similarity (0–100) using partial ratio."""
return float(fuzz.partial_ratio(a, b))
# calculer les scores de correspondance floue
score_cols = ["score_jw", "score_lv", "score_qg", "score_lcs"]
match_grid = match_grid.assign(
score_jw=lambda d: d.apply(
lambda r: _score_jw(str(r["hf_dhis2"]), str(r["hf_mfl"])), axis=1
),
score_lv=lambda d: d.apply(
lambda r: _score_lv(str(r["hf_dhis2"]), str(r["hf_mfl"])), axis=1
),
score_qg=lambda d: d.apply(
lambda r: _score_qg(str(r["hf_dhis2"]), str(r["hf_mfl"])), axis=1
),
score_lcs=lambda d: d.apply(
lambda r: _score_lcs(str(r["hf_dhis2"]), str(r["hf_mfl"])), axis=1
),
)
# écrêter les valeurs négatives et NaN à zéro
for col in score_cols:
match_grid[col] = match_grid[col].clip(lower=0).fillna(0)Pour adapter le code :
- Lignes 14–32 : Ajouter ou retirer des fonctions de similarité selon les besoins de correspondance.
rapidfuzzfournit Levenshtein, Jaro-Winkler, token sort ratio et partial ratio prêts à l’emploi.
Ci-dessus figure un échantillon de dix paires de noms DHIS2–MFL extraites de la grille de correspondance. Les cinq premières sont des correspondances fortes avec des scores quasi parfaits sur tous les algorithmes, reflétant des chaînes presque identiques. Les cinq dernières sont des correspondances faibles avec une similarité faible ou nulle, souvent dues à des noms sans rapport ou à des types de structures différents. Les cas intermédiaires comme kpetema mchp vs clinic gbonkorlenken présentent un chevauchement partiel mais restent bien en dessous des seuils de correspondance. Ces résultats confirment que la notation fonctionne comme prévu et posent les bases pour la construction de scores de similarité composites à l’étape suivante, ce qui aide à réduire la dépendance à une seule métrique.
Étape 6.3 : Créer des scores composites
Pour améliorer la fiabilité de la correspondance floue, nous générons des métriques de similarité composites qui combinent plusieurs algorithmes de distance de chaîne. Cela aide à minimiser la dépendance excessive à une seule métrique et soutient une décision de correspondance plus fiable. Cependant, si nous avons une métrique unique préférée issue de l’étape précédente, nous pouvons ignorer la génération d’un score composite et passer directement à l’Étape 4.5.
Nous générons des métriques composites de deux manières :
Score de similarité composite (
composite_score) : Nous calculons une simple moyenne sur les six algorithmes de similarité de l’étape précédente (Jaro-Winkler, Levenshtein, Qgram et LCS) pour créer uncomposite_score. Cette valeur reflète la similarité globale des chaînes entre les noms DHIS2 et MFL.Score de rang composite (
rank_avg) : Pour chaque structure DHIS2, nous classons la qualité de correspondance de chaque nom MFL candidat, avec un classement effectué pour chacun des six algorithmes de similarité. Nous calculons ensuite la moyenne de ces rangs pour obtenir unrank_avg. Unrank_avgfaible (par exemple, 1) indique que le même nom MFL obtient systématiquement d’excellents résultats sur toutes les méthodes, signalant un consensus fort et une haute confiance dans la correspondance. Ce classement par ensemble aide à équilibrer les forces des différents algorithmes.
Afficher le code
# définir les colonnes de scores de similarité
score_cols <- c("score_jw", "score_lv", "score_qg", "score_lcs")
# calculer composite_score dynamiquement en utilisant score_cols
match_grid <- match_grid |>
dplyr::mutate(
composite_score = rowMeans(
dplyr::across(dplyr::all_of(score_cols))
)
)
# calculer le rang moyen sur toutes les méthodes de similarité
ranked_grid <- match_grid |>
dplyr::group_by(hf_dhis2) |>
dplyr::mutate(
dplyr::across(
dplyr::all_of(score_cols),
~ dplyr::min_rank(dplyr::desc(.)),
.names = "rank_{.col}"
)
) |>
dplyr::ungroup() |>
dplyr::mutate(
rank_avg = rowSums(dplyr::across(
dplyr::all_of(paste0("rank_", score_cols))
)),
rank_avg = round(rank_avg / length(score_cols))
)
# aperçu des résultats classés pour montrer plusieurs candidats par structure DHIS2
# sélectionner quelques structures et afficher leurs 3 meilleurs candidats
sample_facilities <- c(
"charity clinic kamba of",
"arab clinic shad",
"al arab clinic sheefa"
)
ranked_grid |>
dplyr::filter(hf_dhis2 %in% sample_facilities) |>
dplyr::group_by(hf_dhis2) |>
dplyr::slice_min(rank_avg, n = 4, with_ties = FALSE) |>
dplyr::ungroup() |>
dplyr::select(
hf_dhis2,
hf_mfl,
dplyr::all_of(score_cols),
composite_score,
rank_avg
) |>
dplyr::arrange(hf_dhis2, rank_avg)Pour adapter le code :
- Ligne 2 : Si les algorithmes de similarité changent (par exemple, ajout ou suppression de métriques), mettre à jour le vecteur
score_colspour refléter le nouvel ensemble.
Afficher le code
# définir les colonnes de scores de similarité
score_cols = ["score_jw", "score_lv", "score_qg", "score_lcs"]
# calculer composite_score (simple moyenne)
match_grid["composite_score"] = match_grid[score_cols].mean(axis=1)
# calculer le rang moyen sur toutes les méthodes de similarité
for col in score_cols:
match_grid[f"rank_{col}"] = (
match_grid.groupby("hf_dhis2")[col]
.rank(method="min", ascending=False)
)
rank_cols = [f"rank_{c}" for c in score_cols]
match_grid["rank_avg"] = (
match_grid[rank_cols].sum(axis=1) / len(score_cols)
).round()
ranked_grid = match_grid.copy()
# aperçu des résultats classés pour quelques structures échantillons
sample_facilities = [
"charity clinic kamba of",
"arab clinic shad",
"al arab clinic sheefa",
]
ranked_grid.loc[ranked_grid["hf_dhis2"].isin(sample_facilities)].groupby(
"hf_dhis2"
).apply(lambda g: g.nsmallest(4, "rank_avg")).reset_index(drop=True)[
["hf_dhis2", "hf_mfl"] + score_cols + ["composite_score", "rank_avg"]
].sort_values(["hf_dhis2", "rank_avg"])Pour adapter le code :
- Ligne 2 : Si les algorithmes de similarité changent, mettre à jour
score_colspour refléter le nouvel ensemble.
Étape 6.4 : Extraire la meilleure correspondance
Pour finaliser la mise en correspondance, nous sélectionnons le meilleur candidat pour chaque structure DHIS2. Cela peut être basé sur un seul algorithme de similarité ou utiliser une approche combinée telle qu’un score composite ou un rang moyen sur toutes les méthodes.
La sortie inclut une meilleure correspondance par nom DHIS2 pour chaque méthode, permettant une comparaison côte à côte pour évaluer les performances.
Afficher le code
# pour chaque méthode de correspondance floue, sélectionner le nom MFL
# le mieux classé par structure DHIS2.
best_jw <- match_grid |>
dplyr::group_by(hf_dhis2) |>
dplyr::slice_max(score_jw, with_ties = FALSE) |>
dplyr::ungroup() |>
dplyr::mutate(method = "Jaro-Winkler") |>
dplyr::select(
hf_dhis2, hf_mfl, score = score_jw, method
)
best_lv <- match_grid |>
dplyr::group_by(hf_dhis2) |>
dplyr::slice_max(score_lv, with_ties = FALSE) |>
dplyr::ungroup() |>
dplyr::mutate(method = "Levenshtein") |>
dplyr::select(
hf_dhis2, hf_mfl, score = score_lv, method
)
best_qg <- match_grid |>
dplyr::group_by(hf_dhis2) |>
dplyr::slice_max(score_qg, with_ties = FALSE) |>
dplyr::ungroup() |>
dplyr::mutate(method = "Qgram") |>
dplyr::select(
hf_dhis2, hf_mfl, score = score_qg, method
)
best_lcs <- match_grid |>
dplyr::group_by(hf_dhis2) |>
dplyr::slice_max(score_lcs, with_ties = FALSE) |>
dplyr::ungroup() |>
dplyr::mutate(method = "LCS") |>
dplyr::select(
hf_dhis2, hf_mfl, score = score_lcs, method
)
best_comp<- match_grid |>
dplyr::group_by(hf_dhis2) |>
dplyr::slice_max(composite_score, with_ties = FALSE) |>
dplyr::ungroup() |>
dplyr::mutate(method = "Composite-Score") |>
dplyr::select(
hf_dhis2, hf_mfl, score = composite_score, method
)
best_ranked_match <- ranked_grid |>
dplyr::group_by(hf_dhis2) |>
dplyr::slice_min(rank_avg, with_ties = FALSE) |>
dplyr::ungroup() |>
dplyr::mutate(method = "Rank-Ensemble") |>
dplyr::select(
hf_dhis2, hf_mfl, score = rank_avg, method
)
# combiner les meilleures correspondances de toutes les méthodes pour comparaison
all_best <- dplyr::bind_rows(
best_jw, best_lv, best_qg, best_lcs,
best_comp, best_ranked_match)
# aperçu des meilleures correspondances pour afficher les résultats d'extraction
all_best |>
dplyr::slice_head(n = 10) |>
dplyr::select(hf_dhis2, hf_mfl, score, method)Pour adapter le code :
- Lignes 3–56 : Pour chaque bloc de méthode, modifier la colonne de score et l’étiquette
methodpour correspondre à l’algorithme utilisé. - Lignes 3–56 : Supprimer les blocs des méthodes qui n’ont pas été calculées.
- Lignes 58–60 : N’inclure que les objets
best_*conservés dansbind_rows().
Afficher le code
# pour chaque méthode de correspondance floue, sélectionner le nom MFL le mieux classé par structure DHIS2
best_jw = (
match_grid.sort_values("score_jw", ascending=False)
.groupby("hf_dhis2", as_index=False).first()
[["hf_dhis2", "hf_mfl", "score_jw"]]
.rename(columns={"score_jw": "score"})
.assign(method="Jaro-Winkler")
)
best_lv = (
match_grid.sort_values("score_lv", ascending=False)
.groupby("hf_dhis2", as_index=False).first()
[["hf_dhis2", "hf_mfl", "score_lv"]]
.rename(columns={"score_lv": "score"})
.assign(method="Levenshtein")
)
best_qg = (
match_grid.sort_values("score_qg", ascending=False)
.groupby("hf_dhis2", as_index=False).first()
[["hf_dhis2", "hf_mfl", "score_qg"]]
.rename(columns={"score_qg": "score"})
.assign(method="Qgram")
)
best_lcs = (
match_grid.sort_values("score_lcs", ascending=False)
.groupby("hf_dhis2", as_index=False).first()
[["hf_dhis2", "hf_mfl", "score_lcs"]]
.rename(columns={"score_lcs": "score"})
.assign(method="LCS")
)
best_comp = (
match_grid.sort_values("composite_score", ascending=False)
.groupby("hf_dhis2", as_index=False).first()
[["hf_dhis2", "hf_mfl", "composite_score"]]
.rename(columns={"composite_score": "score"})
.assign(method="Composite-Score")
)
best_ranked_match = (
ranked_grid.sort_values("rank_avg")
.groupby("hf_dhis2", as_index=False).first()
[["hf_dhis2", "hf_mfl", "rank_avg"]]
.rename(columns={"rank_avg": "score"})
.assign(method="Rank-Ensemble")
)
# combiner les meilleures correspondances de toutes les méthodes pour comparaison
all_best = pd.concat(
[best_jw, best_lv, best_qg, best_lcs, best_comp, best_ranked_match],
ignore_index=True,
)
# aperçu des meilleures correspondances
all_best.head(10)[["hf_dhis2", "hf_mfl", "score", "method"]]Pour adapter le code :
- Lignes 3–47 : Pour chaque bloc de méthode, modifier la colonne de score et l’étiquette
methodpour correspondre à l’algorithme utilisé. - Lignes 3–47 : Supprimer les blocs des méthodes qui n’ont pas été calculées.
- Lignes 50–55 : N’inclure que les objets
best_*danspd.concat().
Étape 7 : Évaluer la qualité des correspondances floues
Des scores de similarité élevés peuvent parfois masquer des correspondances de mauvaise qualité, notamment lorsque les noms d’établissements diffèrent en structure. Pour s’assurer de ne pas être induits en erreur par de bons scores numériques seuls, nous combinons des métriques de similarité avec des contrôles diagnostiques qui examinent l’alignement des noms au niveau des tokens.
Étape 7.1 : Visualiser la distribution des scores selon les méthodes
Avant d’entrer dans les évaluations structurelles, il est utile d’examiner comment la distribution des scores de correspondance varie selon les algorithmes. Cela permet d’évaluer si certaines méthodes attribuent systématiquement des scores plus élevés et si leurs correspondances tendent à se regrouper ou sont plus dispersées.
C’est particulièrement important lors de l’application de seuils de score, ou lorsqu’on souhaite comprendre dans quelle mesure une méthode est souple ou stricte dans l’attribution de scores de haute confiance.
Afficher le code
# tracer la distribution des scores selon les méthodes
score_dist_plot <- all_best |>
dplyr::filter(method != "Rank-Ensemble") |>
ggplot2::ggplot(ggplot2::aes(x = score)) +
ggplot2::geom_density(fill = "steelblue", alpha = 0.6) +
ggplot2::facet_wrap(~method) +
ggplot2::geom_density(color = "steelblue", linewidth = 1) +
ggplot2::labs(
title = "Distribution of Fuzzy Matching Scores",
x = "\nMatch Score (%)",
y = "Density\n"
) +
ggplot2::theme_minimal(base_size = 14)
# sauvegarder le graphique
ggplot2::ggsave(
plot = score_dist_plot,
filename = here::here("03_output/3a_figures/u5mr_sle_adm2.png"),
width = 12,
height = 9,
dpi = 300
)
NoteSortie
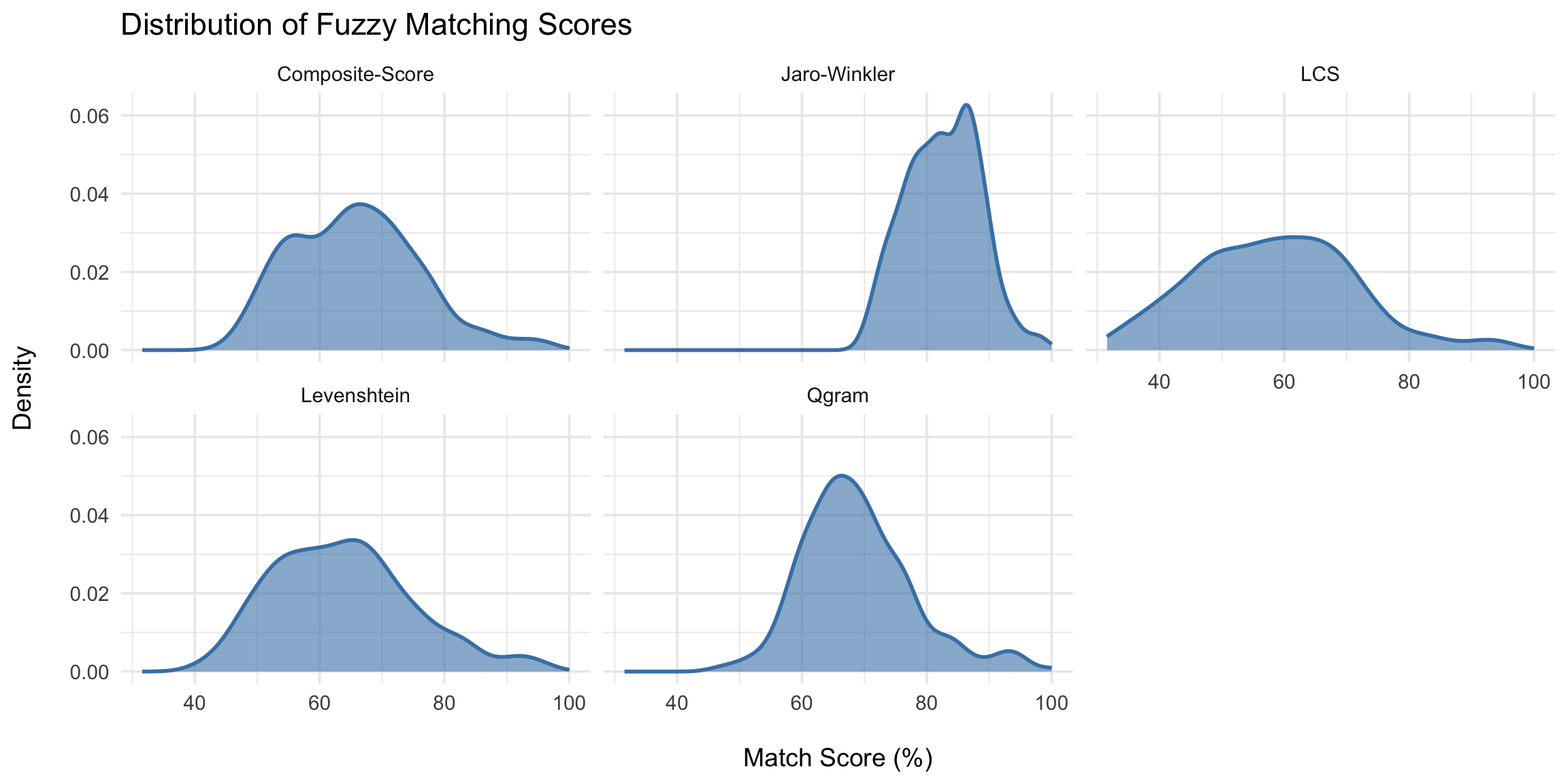
Pour adapter le code :
- Ne rien modifier dans cette section.
Afficher le code
import matplotlib.pyplot as plt
# tracer la distribution des scores selon les méthodes (exclure la méthode par rang)
methods_for_plot = all_best.loc[all_best["method"] != "Rank-Ensemble"]
method_names = sorted(methods_for_plot["method"].unique())
fig, axes = plt.subplots(1, len(method_names), figsize=(12, 6), sharey=True)
for ax, name in zip(axes, method_names):
grp = methods_for_plot.loc[methods_for_plot["method"] == name, "score"].dropna()
grp.plot.kde(ax=ax, color="steelblue", linewidth=1)
ax.fill_between(
ax.lines[0].get_xdata(),
ax.lines[0].get_ydata(),
alpha=0.6,
color="steelblue",
)
ax.set_title(name, fontsize=11)
ax.set_xlabel("\nMatch Score (%)")
if ax == axes[0]:
ax.set_ylabel("Density\n")
fig.suptitle("Distribution of Fuzzy Matching Scores", fontsize=14)
plt.tight_layout()
# sauvegarder le graphique
output_dir = Path(here("03_output/3a_figures"))
output_dir.mkdir(parents=True, exist_ok=True)
fig.savefig(output_dir / "fuzzy_score_distributions.png", dpi=300, bbox_inches="tight")
NoteSortie
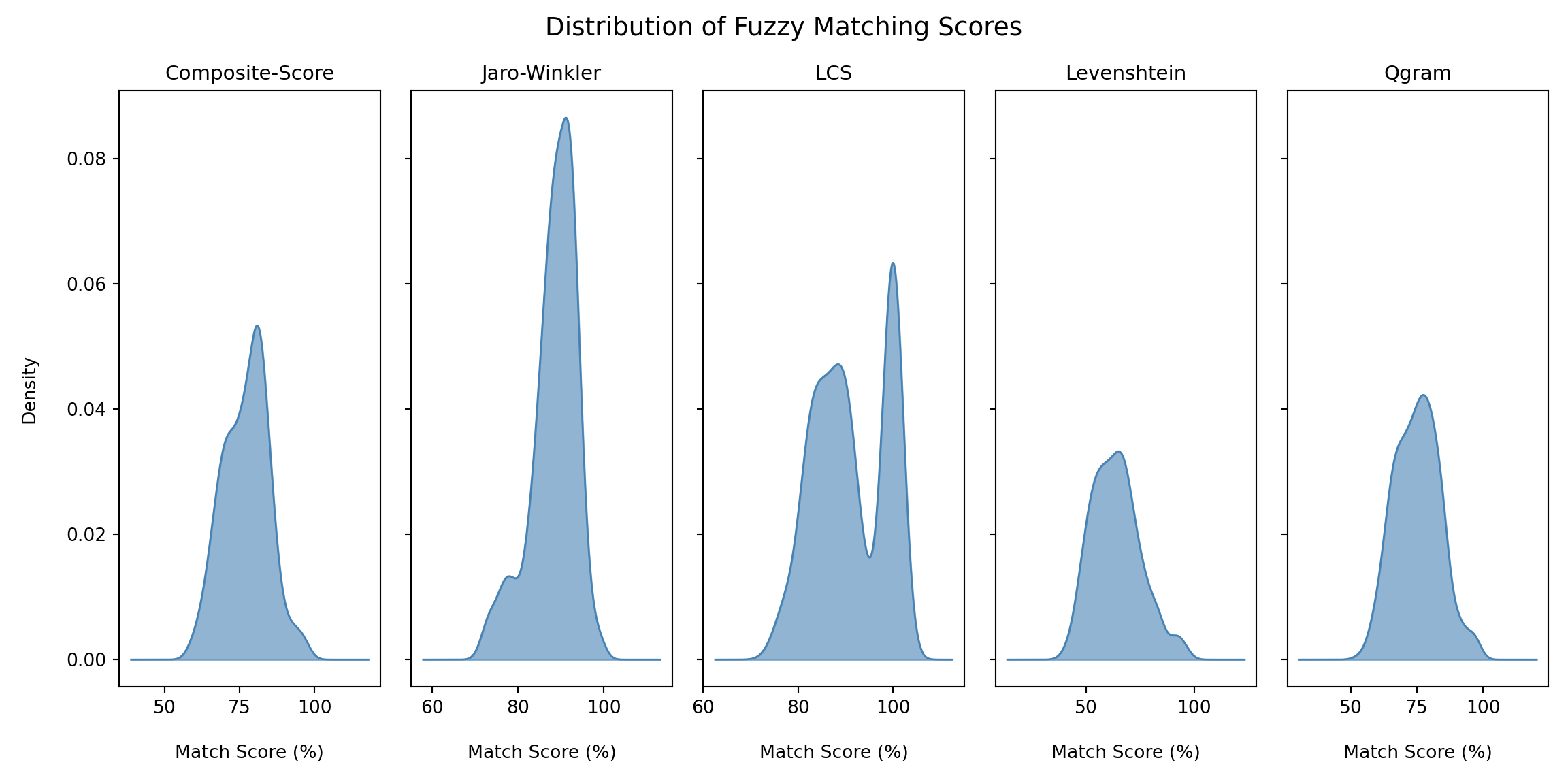
Pour adapter le code :
- Ne rien modifier dans cette section.
En examinant les graphiques, un pic étroit et élevé près de 100 indique qu’une méthode produit de nombreuses correspondances solides ; une distribution plus large ou plus plate peut signaler davantage d’incertitude, et des motifs bimodaux peuvent suggérer un mélange de correspondances clairement bonnes et ambiguës. Ces tendances aident à guider notre stratégie de correspondance : pour notre sélection finale à l’Étape 6, nous utiliserons un seuil de 85 % comme point de départ et construirons un système de repli qui s’appuie en priorité sur les méthodes les plus fiables.
Étape 7.2 : Définir la fonction de diagnostic de qualité des correspondances
Pour évaluer la qualité structurelle d’une correspondance, nous définissons une fonction de diagnostic simple qui compare deux noms au niveau des tokens. Elle divise chaque nom en mots individuels (que nous appellerons tokens, car tout dans le nom n’est pas nécessairement un mot), puis effectue quatre opérations :
- vérifie si les premiers mots s’alignent (correspondance de préfixe)
- vérifie si les derniers mots s’alignent (correspondance de suffixe)
- calcule la différence du nombre de mots (différence de tokens)
- calcule la différence de longueur en caractères (différence de caractères) Ces heuristiques simples peuvent détecter des non-correspondances qui obtiennent un score élevé mais sont structurellement décalées.
assess_match_quality <- function(name1, name2) {
purrr::map2_dfr(name1, name2, function(a, b) {
tokens1 <- strsplit(a, "\\s+")[[1]]
tokens2 <- strsplit(b, "\\s+")[[1]]
tibble::tibble(
prefix_match = tolower(tokens1[1]) == tolower(tokens2[1]),
suffix_match = tolower(tail(tokens1, 1)) == tolower(tail(tokens2, 1)),
token_diff = abs(length(tokens1) - length(tokens2)),
char_diff = abs(nchar(a) - nchar(b))
)
})
}
assess_match_quality("Makeni Govt Hospital", "Makeni Government Hospital")Pour adapter le code :
- Ne rien modifier dans cette section.
def assess_match_quality(names1, names2):
"""Compute structural quality diagnostics for name pairs.
Returns a DataFrame with prefix_match, suffix_match,
token_diff, and char_diff for each name pair.
"""
rows = []
for a, b in zip(names1, names2):
tokens1 = str(a).split()
tokens2 = str(b).split()
rows.append({
"prefix_match": tokens1[0].lower() == tokens2[0].lower()
if tokens1 and tokens2 else False,
"suffix_match": tokens1[-1].lower() == tokens2[-1].lower()
if tokens1 and tokens2 else False,
"token_diff": abs(len(tokens1) - len(tokens2)),
"char_diff": abs(len(str(a)) - len(str(b))),
})
return pd.DataFrame(rows)
assess_match_quality(["Makeni Govt Hospital"], ["Makeni Government Hospital"])Pour adapter le code :
- Ne rien modifier dans cette section.
Dans cet exemple, en utilisant notre fonction assess_match_quality, le premier et le dernier mot correspondent, donc prefix_match et suffix_match sont tous deux TRUE. Il n’y a pas de différence dans le nombre de tokens (token_diff = 0), mais le second nom est six caractères plus long (char_diff = 6) en raison de « Govt » vs « Government ».
Ces diagnostics aident à signaler les cas où un score flou peut être élevé mais où des éléments importants du nom diffèrent, comme CHC vs MCHP, Clinic vs Hospital, ou Primary vs Secondary, ce qui peut indiquer une non-correspondance méritant vérification.
Étape 7.3 : Évaluer la qualité des meilleures correspondances floues
Nous appliquons maintenant ce diagnostic à nos meilleures correspondances. L’objectif est de mettre en évidence les cas où, malgré des scores de similarité élevés, les noms peuvent différer significativement en format ou en structure : par exemple, des préfixes ou suffixes non concordants. Cette étape facilite la révision manuelle ou ajoute une couche de filtrage pour améliorer la précision finale des correspondances.
Nous combinons également les diagnostics en un structure_score (0–100), attribuant 30 % de poids à la différence de tokens, 20 % à la différence de caractères et 25 % chacun aux correspondances de préfixe et de suffixe. Cela fournit un résumé rapide de l’alignement structurel global.
Afficher le code
# évaluer la qualité structurelle des correspondances
diagnostics_df <- dplyr::bind_cols(
all_best,
assess_match_quality(all_best$hf_dhis2, all_best$hf_mfl)
)
# comparer les diagnostics par méthode
summary_stats <- diagnostics_df |>
dplyr::group_by(method) |>
dplyr::summarise(
score = mean(score),
avg_token_diff = mean(token_diff) |> round(2),
avg_char_diff = mean(char_diff) |> round(2),
pct_prefix_match = (mean(prefix_match) * 100) |> round(2),
pct_suffix_match = (mean(suffix_match) * 100) |> round(2),
total = dplyr::n(),
.groups = "drop"
)
# créer un score global final
summary_stats <- summary_stats |>
dplyr::mutate(
# redimensionner le négatif de la différence moyenne de tokens (plus petit = meilleur)
token_score = scales::rescale(-avg_token_diff, to = c(0, 100)),
# redimensionner le négatif de la différence moyenne de caractères (plus petit = meilleur)
char_score = scales::rescale(-avg_char_diff, to = c(0, 100)),
# redimensionner le pourcentage de correspondance de préfixe (plus élevé = meilleur)
prefix_score = scales::rescale(pct_prefix_match, to = c(0, 100)),
# redimensionner le pourcentage de correspondance de suffixe (plus élevé = meilleur)
suffix_score = scales::rescale(pct_suffix_match, to = c(0, 100)),
# combiner les quatre métriques en un score de qualité structurelle pondéré
structure_score = round(
0.3 * token_score + # accentuer les faibles différences de tokens
0.2 * char_score + # poids modéré sur la similarité de caractères
0.25 * prefix_score + # pondérer les mots initiaux correspondants
0.25 * suffix_score, # pondérer également les mots finaux correspondants
1
)
) |>
dplyr::arrange(desc(structure_score)) |>
# attribuer un rang basé sur le score structurel décroissant
dplyr::mutate(rank = dplyr::row_number()) |>
dplyr::select(
method, avg_token_diff, avg_char_diff,
pct_prefix_match, pct_suffix_match,
total, structure_score, rank
)
# vérifier les résultats
summary_stats |>
dplyr::select(
Method = method,
`Avg. Token Difference` = avg_token_diff,
`Avg. Character Difference` = avg_char_diff,
`% Prefix Match` = pct_prefix_match,
`% Suffix Match` = pct_suffix_match,
`Structural Score` = structure_score,
Rank = rank
) |> as.data.frame()Pour adapter le code :
- Lignes 34–37 : Ajuster les poids utilisés pour calculer le
structure_scoresi le contexte de correspondance valorise davantage certaines composantes (par exemple, les correspondances de préfixe ou la longueur des tokens).
Afficher le code
def _rescale(series, new_min, new_max):
"""Rescale a numeric series to [new_min, new_max]."""
s_min, s_max = series.min(), series.max()
if s_max == s_min:
return pd.Series([new_min] * len(series), index=series.index)
return new_min + (series - s_min) / (s_max - s_min) * (new_max - new_min)
# évaluer la qualité structurelle des correspondances
diagnostics_df = pd.concat(
[all_best.reset_index(drop=True),
assess_match_quality(all_best["hf_dhis2"], all_best["hf_mfl"])],
axis=1,
)
# comparer les diagnostics par méthode
summary_stats = (
diagnostics_df
.groupby("method")
.agg(
avg_token_diff=("token_diff", "mean"),
avg_char_diff=("char_diff", "mean"),
pct_prefix_match=("prefix_match", "mean"),
pct_suffix_match=("suffix_match", "mean"),
total=("hf_dhis2", "count"),
)
.reset_index()
.assign(
avg_token_diff=lambda d: d["avg_token_diff"].round(2),
avg_char_diff=lambda d: d["avg_char_diff"].round(2),
pct_prefix_match=lambda d: (d["pct_prefix_match"] * 100).round(2),
pct_suffix_match=lambda d: (d["pct_suffix_match"] * 100).round(2),
)
)
# créer un score global final
summary_stats = summary_stats.assign(
# redimensionner le négatif de la différence moyenne de tokens (plus petit = meilleur)
token_score=lambda d: _rescale(-d["avg_token_diff"], 0, 100),
# redimensionner le négatif de la différence moyenne de caractères (plus petit = meilleur)
char_score=lambda d: _rescale(-d["avg_char_diff"], 0, 100),
# redimensionner le pourcentage de correspondance de préfixe (plus élevé = meilleur)
prefix_score=lambda d: _rescale(d["pct_prefix_match"], 0, 100),
# redimensionner le pourcentage de correspondance de suffixe (plus élevé = meilleur)
suffix_score=lambda d: _rescale(d["pct_suffix_match"], 0, 100),
).assign(
# combiner les quatre métriques en un score de qualité structurelle pondéré
structure_score=lambda d: (
0.3 * d["token_score"] + # accentuer les faibles différences de tokens
0.2 * d["char_score"] + # poids modéré sur la similarité de caractères
0.25 * d["prefix_score"] + # pondérer les mots initiaux correspondants
0.25 * d["suffix_score"] # pondérer également les mots finaux correspondants
).round(1)
).sort_values("structure_score", ascending=False)
summary_stats["rank"] = range(1, len(summary_stats) + 1)
summary_stats.rename(columns={
"method": "Method",
"avg_token_diff": "Avg. Token Difference",
"avg_char_diff": "Avg. Character Difference",
"pct_prefix_match": "% Prefix Match",
"pct_suffix_match": "% Suffix Match",
"structure_score": "Structural Score",
"rank": "Rank",
})[["Method", "Avg. Token Difference", "Avg. Character Difference",
"% Prefix Match", "% Suffix Match", "Structural Score", "Rank"]]Pour adapter le code :
- Lignes 47–50 : Ajuster les poids utilisés pour calculer le
structure_scoresi le contexte de correspondance valorise davantage certaines composantes (par exemple, les correspondances de préfixe ou la longueur des tokens).
Ces diagnostics montrent dans quelle mesure chaque méthode préserve la structure des noms mis en correspondance dans notre exercice de correspondance de noms d’établissements de santé. Cela aide à déterminer quelle méthode privilégier et comment construire des règles de repli lorsque plusieurs méthodes sont combinées. Un contexte de projet différent peut donner lieu à la préférence d’un autre algorithme de correspondance floue.
Résumés de performance des méthodes
Levenshtein : Différences de tokens et de caractères les plus faibles, avec un bon alignement des préfixes et suffixes. Score structurel le plus élevé (84,1, Rang 1) : meilleure performance globale.
Rank-Ensemble : Équilibré sur toutes les métriques, particulièrement fort sur l’alignement des préfixes. Score 71,0 (Rang 2) : option de repli fiable.
Composite-Score : Régulier sur toutes les métriques avec un bon alignement des suffixes. Score 68,5 (Rang 3) : option polyvalente et généraliste.
Jaro-Winkler : Alignement des préfixes le plus fort mais plus faible sur les suffixes. Score 67,1 (Rang 4) : utile lorsque les débuts des noms s’alignent étroitement.
Qgram : Bonne similarité de sous-chaînes, mais structurellement plus faible dans l’ensemble. Score 50,0 (Rang 5) : plus adapté aux chevauchements partiels.
LCS Écarts de tokens et de caractères plus importants malgré des correspondances de suffixes raisonnables. Score le plus bas (43,9, Rang 6) : pénalisé pour les différences structurelles.
Levenshtein était la méthode la plus performante, affichant de faibles différences structurelles et un bon alignement des préfixes et suffixes. Rank-Ensemble et Jaro-Winkler ont suivi comme options fiables, avec des forces différentes sur les préfixes. Composite-Score était stable mais légèrement plus faible. Qgram et LCS étaient moins efficaces dans l’ensemble, pénalisés pour des écarts structurels plus importants malgré des forces occasionnelles sur les suffixes.
Étape 7.4 : Seuillage pondéré basé sur la qualité structurelle et le risque de faux positifs
Maintenant que le score structurel est en place, il peut être utilisé pour calculer des métriques supplémentaires qui renforcent l’approche de correspondance. Ces métriques peuvent alimenter un processus de seuillage pondéré, où les scores sont ajustés par la qualité de la méthode et les seuils sont adaptés au risque de faux positifs de chaque méthode. Cela fait passer la définition des seuils d’une coupure arbitraire unique à un processus fondé sur des données qui reflète les forces et faiblesses de chaque algorithme, améliorant la précision sans sacrifier la qualité des correspondances.
Les résultats de cette étape servent à des fins différentes selon la stratégie de correspondance choisie à l’Étape 8. Lors de l’utilisation d’une méthode unique ou d’une approche composite simple (Options 1-2), seuls les classements des scores structurels de l’Étape 7.3 sont nécessaires pour identifier la méthode la plus performante. Lors de l’utilisation du scoring composite pondéré ou de l’approche en boucle de repli (Options 3-4), les poids de méthode et les seuils calculés à cette étape sont tous deux requis.
Cette étape calcule deux métriques clés pour chaque méthode de correspondance floue :
1. Poids des méthodes : Proportionnels aux scores structurels de l’Étape 7.3, redimensionnés de sorte que tous les poids somment à 1. Les méthodes de meilleure qualité structurelle ont une influence plus élevée lors de la combinaison de plusieurs méthodes dans les Options 3-4.
2. Seuils spécifiques à la méthode : Utilisent une mise à l’échelle inverse basée sur la qualité structurelle. Un seuil détermine le score de similarité minimal requis pour une correspondance (par exemple, un seuil de 85 signifie que seuls les candidats obtenant ≥85 sont acceptés). Les méthodes performantes obtiennent des seuils plus bas (correspondance plus facile) car elles sont fiables, tandis que les méthodes peu performantes obtiennent des seuils plus élevés (correspondance plus stricte) pour éviter les faux positifs. Par exemple, Levenshtein pourrait obtenir le seuil 75 (méthode fiable), tandis que LCS obtient 95 (exige une haute confiance).
Note Dans le code ci-dessous, les seuils sont créés en redimensionnant le structure_score de chaque méthode (0–100) dans une nouvelle plage définie par les 70e et 95e percentiles de all_best$score. La fonction rev() inverse ce mappage de sorte que les scores plus élevés sont poussés vers le bas de la plage et les scores plus faibles vers le haut. Cela signifie que les méthodes plus solides reçoivent des seuils plus stricts, tandis que les méthodes plus faibles se voient attribuer des seuils plus souples.
# calculer les poids et seuils spécifiques à chaque méthode
method_threshold <- summary_stats |>
dplyr::mutate(
score = structure_score / 100,
weight = score / sum(score),
threshold = scales::rescale(
structure_score,
to = rev(unname(
stats::quantile(all_best$score, c(0.70, 0.95), na.rm = TRUE)
))
) |>
round()
) |>
dplyr::select(method, weight, threshold)
# afficher les résultats
method_thresholdPour adapter le code :
- Ligne 2 : Conserver
summary_statsde l’Étape 7.3 avec la colonnestructure_score. - Lignes 6–11 : Ajuster la plage des quantiles (par défaut : 0,70 à 0,95) pour contrôler l’étendue des seuils.
- Ligne 14 : Modifier la sélection des colonnes si des métriques supplémentaires sont nécessaires dans la sortie.
# calculer les poids et seuils spécifiques à chaque méthode
q70 = all_best["score"].quantile(0.70)
q95 = all_best["score"].quantile(0.95)
method_threshold = summary_stats[["method", "structure_score"]].copy()
method_threshold["score_frac"] = method_threshold["structure_score"] / 100
method_threshold["weight"] = (
method_threshold["score_frac"] / method_threshold["score_frac"].sum()
)
# mise à l'échelle inverse : structure_score élevé → seuil plus bas (correspondance plus facile)
method_threshold["threshold"] = (
_rescale(method_threshold["structure_score"], q95, q70)
).round()
method_threshold = method_threshold[["method", "weight", "threshold"]]
# afficher les résultats
method_thresholdPour adapter le code :
- Ligne 2 : Conserver
summary_statsde l’Étape 7.3 avec la colonnestructure_score. - Lignes 4–5 : Ajuster la plage des quantiles (par défaut : 0,70 à 0,95) pour contrôler l’étendue des seuils.
- Ligne 14 : Modifier la sélection des colonnes si des métriques supplémentaires sont nécessaires dans la sortie.
Ce tableau présente le poids relatif de chaque méthode, mis à l’échelle de sorte que tous les poids somment à un, ainsi que son seuil de score spécifique dérivé de la performance observée. La relation entre la qualité structurelle, les poids et les seuils suit ce schéma :
| Method | Weight | Threshold | Interpretation |
|---|---|---|---|
| Levenshtein | 0.219 | 75 | Highest-performing method: gets most influence in composite scoring and lowest threshold for matching |
| Composite-Score | 0.185 | 80 | Strong performer: high influence and low threshold |
| Rank-Ensemble | 0.178 | 81 | Good performer: moderate-high influence and low-medium threshold |
| Jaro-Winkler | 0.174 | 82 | Balanced method: moderate influence and medium threshold |
| Qgram | 0.130 | 88 | Lower performer: reduced influence and higher threshold to prevent false positives |
| LCS | 0.114 | 92 | Lowest performer: minimal influence and strictest threshold required |
Observation clé : Les méthodes présentant un meilleur alignement structurel sont récompensées par des poids plus élevés (plus d’influence) et des seuils plus bas (correspondance plus facile), tandis que les méthodes peu fiables sont contraintes par des poids plus faibles et des seuils plus stricts.
Étape 8 : Finaliser la sélection des correspondances floues
Cette étape attribue une correspondance finale à chaque établissement DHIS2 en choisissant le candidat le plus approprié parmi les résultats de l’appariement flou. À ce stade, chaque établissement non apparié des étapes précédentes devrait disposer d’un ou plusieurs candidats avec des scores de similarité et des diagnostics d’appui (par exemple, correspondances de préfixes/suffixes, différences de tokens). L’objectif est de sélectionner une correspondance par établissement en équilibrant précision, efficacité et couverture.
Le choix de la stratégie de sélection finale dépend de :
- La confiance dans les méthodes d’appariement : si les algorithmes et les seuils sont déjà bien calibrés sur les données, une approche plus simple peut suffire.
- La tolérance aux faux positifs : dans certains contextes, un taux de correspondance légèrement plus faible est acceptable s’il réduit le risque de correspondances incorrectes.
- Les priorités analytiques et opérationnelles : par exemple, si une méthode rapide et explicable est nécessaire pour un rapport urgent, ou si un processus plus complet et itératif est requis pour la mise à jour d’un ensemble de données maître.
Nous proposons quatre options structurées, chacune ayant ses propres forces, faiblesses et niveau de complexité. En pratique, nous pouvons commencer par une option plus simple et progresser vers des approches plus avancées si trop d’établissements restent non appariés ou si la qualité des correspondances est irrégulière. Ces options sont également compatibles avec une étape de révision par l’équipe SNT, permettant une validation humaine avant que les correspondances ne soient finalisées dans le jeu de données.
Résumé des options de sélection des correspondances
| Option | Description | Use Case | Code Complexity |
|---|---|---|---|
| Option 1: Single Method | Use one preferred method (e.g., Levenshtein) with a threshold | When confident in a single algorithm | Low |
| Option 2: Composite/Rank | Use composite score or rank average to select best match | When using blended match signals | Moderate |
| Option 3: Weighted Composite Score | Use performance-weighted composite score that accounts for method reliability and false-positive rates | When using blended match signals with known method performance differences | Moderate |
| Option 4: Fallback Loop | Stepwise fallback through all methods based on structural quality scores | When coverage is most important | High |
Étape 8.1 : Options de sélection des correspondances
Option 1 : Méthode unique préférée
Cette approche utilise un seul algorithme de similarité, tel que Levenshtein ou Jaro-Winkler, pour sélectionner la correspondance avec le score le plus élevé pour chaque établissement. Nous appliquons un seuil fixe afin que les scores supérieurs à la valeur limite soient acceptés comme correspondances, tandis que les scores inférieurs sont signalés pour révision. Elle est rapide, facile à expliquer et fonctionne bien lorsque la méthode choisie est adaptée aux types de différences de noms présents dans les données.
Afficher le code
# appliquer le seuil par méthode unique et signaler les correspondances
best_lv_final <- best_lv |>
dplyr::mutate(
match_flag = dplyr::if_else(score >= 85, "match", "review"),
final_method = "Levenshtein"
) |>
dplyr::left_join(
dplyr::select(master_hf_df, hf_mfl, hf_mfl_raw),
by = "hf_mfl"
) |>
dplyr::select(hf_dhis2, hf_mfl, hf_mfl_raw, score, final_method, match_flag)
# afficher les 5 meilleures et 5 pires correspondances par score
top_5 <- best_lv_final |>
dplyr::arrange(dplyr::desc(score)) |>
dplyr::slice_head(n = 5)
bottom_5 <- best_lv_final |>
dplyr::arrange(score) |>
dplyr::slice_head(n = 5)
# combiner en un seul tableau
top_bottom <- dplyr::bind_rows(top_5, bottom_5)
cli::cli_h3("5 premières et 5 dernières correspondances par score Levenshtein")
# aperçu des résultats
top_bottomPour adapter le code :
- Ligne 2 : Remplacer
best_lvpar un autre objet de l’étape 4.5 (par exemplebest_jw,best_qg) selon la méthode préférée. - Ligne 4 : Ajuster le seuil de score (valeur par défaut = 85) pour définir ce qui constitue une
match. - Ligne 11 : Conserver les noms de colonnes
hf_dhis2ethf_mfl, ou les remplacer par les noms spécifiques au projet.
Afficher le code
# appliquer le seuil par méthode unique et signaler les correspondances
best_lv_final = (
best_lv
.assign(
match_flag=lambda d: np.where(d["score"] >= 85, "match", "review"),
final_method="Levenshtein",
)
.merge(master_hf_df[["hf_mfl", "hf_mfl_raw"]], on="hf_mfl", how="left")
[["hf_dhis2", "hf_mfl", "hf_mfl_raw", "score", "final_method", "match_flag"]]
)
# afficher les 5 meilleures et 5 pires correspondances par score
top_5 = best_lv_final.sort_values("score", ascending=False).head(5)
bottom_5 = best_lv_final.sort_values("score").head(5)
# combiner en un seul tableau
top_bottom = pd.concat([top_5, bottom_5], ignore_index=True)
cli_header("5 premières et 5 dernières correspondances par score Levenshtein")
# aperçu des résultats
top_bottomPour adapter le code :
- Ligne 2 : Remplacer
best_lvpar un autre objet de l’étape 6.4 (par exemplebest_jw,best_qg) selon la méthode préférée. - Ligne 4 : Ajuster le seuil de score (valeur par défaut = 85) pour définir ce qui constitue une
match. - Ligne 9 : Conserver les noms de colonnes
hf_dhis2ethf_mfl, ou les remplacer par les noms spécifiques au projet.
Dans notre jeu de données exemple, la méthode Levenshtein avec un seuil de 85 % a atteint le taux de correspondance indiqué dans la sortie ci-dessus. Cette approche conservatrice privilégie la précision au détriment du rappel, ce qui la rend adaptée lorsque les faux positifs sont coûteux et que des ressources de révision manuelle sont disponibles.
Option 2 : Correspondance composite ou basée sur les rangs
Cette approche sélectionne la meilleure correspondance en utilisant une mesure combinée issue de plusieurs algorithmes, telle qu’un score composite ou un rang moyen. Elle évite de dépendre d’une seule méthode tout en restant plus simple qu’une boucle de repli complète. Cette approche fonctionne bien lorsque différents algorithmes capturent différents types de variations, et qu’un score combiné unique peut être utilisé avec un seuil pour distinguer les correspondances fiables de celles nécessitant une révision.
Afficher le code
# sélectionner la meilleure correspondance en utilisant le rang moyen
composite_final <- ranked_grid |>
dplyr::group_by(hf_dhis2) |>
dplyr::arrange(rank_avg) |>
dplyr::slice_head(n = 1) |>
dplyr::ungroup() |>
dplyr::mutate(
match_flag = dplyr::if_else(composite_score >= 85, "match", "review")
) |>
dplyr::select(
adm1,
adm2,
hf_dhis2,
hf_mfl,
composite_score,
rank_avg,
match_flag
)
# afficher les 5 meilleures et 5 pires correspondances par score composite
top_5 <- composite_final |>
dplyr::arrange(dplyr::desc(score)) |>
dplyr::slice_head(n = 5)
bottom_5 <- composite_final |>
dplyr::arrange(score) |>
dplyr::slice_head(n = 5)
# combiner en un seul tableau
top_bottom <- dplyr::bind_rows(top_5, bottom_5)
cli::cli_h3("5 premiers et 5 derniers appariements par score composite")
# aperçu des résultats
top_bottomPour adapter le code :
- Ligne 2 : Conserver
ranked_gridde l’étape 6.4, ou le remplacer par le dataframe des résultats combinés. - Ligne 8 : Ajuster le seuil du score composite (valeur par défaut = 85) pour définir ce qui constitue une
match. - Lignes 10–18 : Conserver les colonnes de score (
composite_score,rank_avg) ou les remplacer par les métriques de scoring pertinentes.
Afficher le code
# sélectionner la meilleure correspondance en utilisant le rang moyen
composite_final = (
ranked_grid.sort_values("rank_avg")
.groupby("hf_dhis2", as_index=False)
.first()
.assign(
match_flag=lambda d: np.where(d["composite_score"] >= 85, "match", "review"),
score=lambda d: d["composite_score"],
final_method="Composite-Score",
)
.merge(master_hf_df[["hf_mfl", "hf_mfl_raw"]], on="hf_mfl", how="left")
[["hf_dhis2", "hf_mfl", "hf_mfl_raw", "score", "final_method", "match_flag"]]
)
# afficher les 5 meilleures et 5 pires correspondances par score composite
top_5 = composite_final.sort_values("score", ascending=False).head(5)
bottom_5 = composite_final.sort_values("score").head(5)
# combiner en un seul tableau
top_bottom = pd.concat([top_5, bottom_5], ignore_index=True)
cli_header("5 premiers et 5 derniers appariements par score composite")
# aperçu des résultats
top_bottomPour adapter le code :
- Ligne 2 : Conserver
ranked_gridde l’étape 6.4, ou le remplacer par le dataframe des résultats combinés. - Ligne 6 : Ajuster le seuil du score composite (valeur par défaut = 85) pour définir ce qui constitue une
match. - Lignes 8–13 : Conserver les colonnes de score (
composite_score,rank_avg) ou les remplacer par les métriques de scoring pertinentes.
L’approche par score composite donne le taux de correspondance indiqué dans la sortie ci-dessus. Ce résultat reflète l’effet de moyennage, où des correspondances solides dans une méthode peuvent être diluées par des scores plus faibles dans d’autres. Elle convient particulièrement aux jeux de données présentant des schémas de nommage cohérents entre les méthodes.
Option 3 : Score composite pondéré
Cette approche sélectionne la meilleure correspondance en utilisant un score composite pondéré par les performances, qui tient compte de la fiabilité de chaque méthode et de ses taux de faux positifs. Au lieu de traiter toutes les méthodes de manière égale, elle utilise les poids calculés à l’étape 7.4 pour mettre en avant les méthodes ayant démontré un meilleur alignement structurel. Cela constitue une alternative plus sophistiquée à la simple moyenne, tout en étant moins complexe qu’un système de repli complet.
Le score composite pondéré utilise une moyenne pondérée qui maintient l’échelle 0-100 : les méthodes ayant des scores de qualité structurelle plus élevés ont plus de poids dans le composite final. Par exemple, si Levenshtein a un poids de 0,4 et Qgram un poids de 0,1, le score Levenshtein contribue 4 fois plus au score pondéré final.
Afficher le code
# définir les colonnes de score et extraire les poids
score_cols <- c("score_jw", "score_lv", "score_qg", "score_lcs")
weights <- method_threshold |>
dplyr::filter(
method %in% c("Jaro-Winkler", "Levenshtein", "Qgram", "LCS")
) |>
dplyr::pull(weight)
# calculer le score composite pondéré pour chaque paire établissement-candidat
weighted_final <- ranked_grid |>
dplyr::rowwise() |>
dplyr::mutate(
# la moyenne pondérée maintient l'échelle 0-100
weighted_composite_score = stats::weighted.mean(
c(score_jw, score_lv, score_qg, score_lcs),
weights,
na.rm = TRUE
)
) |>
dplyr::ungroup() |>
dplyr::group_by(hf_dhis2) |>
dplyr::arrange(dplyr::desc(weighted_composite_score)) |>
dplyr::slice_head(n = 1) |>
dplyr::ungroup() |>
dplyr::mutate(
match_flag = dplyr::if_else(
weighted_composite_score >= 85,
"match",
"review"
),
score = weighted_composite_score, # standardize column name for Step 7
final_method = "Weighted-Composite"
) |>
dplyr::left_join(
dplyr::select(master_hf_df, hf_mfl, hf_mfl_raw),
by = "hf_mfl"
) |>
dplyr::select(
hf_dhis2,
hf_mfl,
hf_mfl_raw,
score,
final_method,
match_flag
)
# afficher les 5 meilleures et 5 pires correspondances par score composite pondéré
top_5 <- weighted_final |>
dplyr::arrange(dplyr::desc(score)) |>
dplyr::slice_head(n = 5)
bottom_5 <- weighted_final |>
dplyr::arrange(score) |>
dplyr::slice_head(n = 5)
cli::cli_h3("5 premiers et 5 derniers appariements par score composite pondéré")
# aperçu des résultats
bottom_5Pour adapter le code :
- Ligne 2 : Ajuster
score_colssi le jeu de données utilise des noms de colonnes de score de similarité différents. - Lignes 4–8 : S’assurer que
method_thresholdde l’étape 7.4 contient les poids pour les méthodes utilisées. - Lignes 15–18 : La fonction
weighted.mean()calcule une moyenne pondérée qui maintient l’échelle 0-100. - Lignes 27–31 : Ajuster le seuil du score composite pondéré (valeur par défaut = 85) pour définir ce qui constitue une
match. - Lignes 39–46 : Sélectionner les colonnes à inclure dans la sortie finale.
Afficher le code
# définir les colonnes de score et extraire les poids
score_cols = ["score_jw", "score_lv", "score_qg", "score_lcs"]
weights_df = method_threshold.loc[
method_threshold["method"].isin(["Jaro-Winkler", "Levenshtein", "Qgram", "LCS"])
]
weights = weights_df.set_index("method")["weight"]
# extraire les poids individuels pour chaque méthode
w_jw = float(weights.get("Jaro-Winkler", 0))
w_lv = float(weights.get("Levenshtein", 0))
w_qg = float(weights.get("Qgram", 0))
w_lcs = float(weights.get("LCS", 0))
# calculer le score composite pondéré pour chaque paire établissement-candidat
# la moyenne pondérée maintient l'échelle 0-100
weighted_final = (
ranked_grid.assign(
weighted_composite_score=lambda d: (
d["score_jw"] * w_jw +
d["score_lv"] * w_lv +
d["score_qg"] * w_qg +
d["score_lcs"] * w_lcs
)
)
.sort_values("weighted_composite_score", ascending=False)
.groupby("hf_dhis2", as_index=False)
.first()
.assign(
match_flag=lambda d: np.where(
d["weighted_composite_score"] >= 85, "match", "review"
),
score=lambda d: d["weighted_composite_score"],
final_method="Weighted-Composite",
)
.merge(master_hf_df[["hf_mfl", "hf_mfl_raw"]], on="hf_mfl", how="left")
[["hf_dhis2", "hf_mfl", "hf_mfl_raw", "score", "final_method", "match_flag"]]
)
# afficher les 5 meilleures et 5 pires correspondances par score composite pondéré
top_5 = weighted_final.sort_values("score", ascending=False).head(5)
bottom_5 = weighted_final.sort_values("score").head(5)
cli_header("5 premiers et 5 derniers appariements par score composite pondéré")
# aperçu des résultats
bottom_5Pour adapter le code :
- Ligne 2 : Ajuster
score_colssi le jeu de données utilise des noms de colonnes de score de similarité différents. - Lignes 4–7 : S’assurer que
method_thresholdde l’étape 7.4 contient les poids pour les méthodes utilisées. - Lignes 14–19 : La somme pondérée calcule une moyenne pondérée qui maintient l’échelle 0-100.
- Lignes 25–27 : Ajuster le seuil du score composite pondéré (valeur par défaut = 85) pour définir ce qui constitue une
match. - Ligne 33 : Sélectionner les colonnes à inclure dans la sortie finale.
L’approche par score composite pondéré a atteint le taux de correspondance amélioré indiqué dans la sortie ci-dessus. Cette amélioration par rapport au score composite simple démontre l’intérêt de mettre en avant les méthodes de haute qualité. La pondération équilibre les forces de plusieurs modèles tout en privilégiant les algorithmes les plus fiables.
Option 4 : Boucle de repli entre les méthodes (recommandée pour la couverture)
Cette approche maximise la couverture des correspondances grâce à un système de repli par paliers sophistiqué qui utilise dynamiquement l’ordre des méthodes et les seuils calculés aux étapes 7.3 et 7.4. Les méthodes sont appliquées par ordre décroissant de leurs scores de structure, en s’assurant que les algorithmes à haute précision ont la priorité pour apparier.
Un point fort essentiel est l’utilisation de seuils spécifiques à chaque méthode issus de l’étape 7.4. Chaque méthode utilise son propre seuil calculé en fonction de sa qualité structurelle et de son profil de risque de faux positifs. Cette approche fondée sur les données est plus fiable que des seuils arbitraires.
L’ordre des méthodes et les seuils sont déterminés dynamiquement à partir de l’analyse de la qualité structurelle aux étapes 7.3–7.4. Les méthodes ayant des scores de structure plus élevés sont prioritaires, et chacune utilise son seuil calculé en fonction du risque de faux positifs :
- Méthodes de haute qualité (par exemple Levenshtein) : seuils plus bas en raison de la fiabilité de l’appariement
- Méthodes de qualité moyenne (par exemple Jaro-Winkler) : seuils modérés pour un équilibre entre précision et rappel
- Méthodes de moindre qualité (par exemple Qgram, LCS) : seuils plus élevés pour éviter les faux positifs
Le processus de repli fonctionne comme suit :
- Ordre des méthodes : les méthodes sont classées par leurs scores de structure issus de l’étape 7.3 (du plus élevé au plus bas)
- Départage : au sein de chaque méthode, les candidats sont pré-triés par :
- Score de similarité (décroissant) : les scores les plus élevés en premier
- Rang moyen issu des méthodes d’ensemble (croissant) : les meilleurs rangs comme critère secondaire Cela garantit que lorsque plusieurs candidats dépassent le seuil, la meilleure correspondance est sélectionnée
- Appariement progressif : chaque méthode tente d’apparier les établissements restants en utilisant son seuil calculé à l’étape 7.4
- Relaxation du seuil : si des établissements restent non appariés après un passage complet, les seuils sont réduits de 1 point et le cycle reprend
- Plancher de qualité : le processus s’arrête lorsque tous les établissements sont appariés ou lorsque les seuils descendent en dessous de 50
Cette approche dynamique avec un départage fiable garantit la meilleure correspondance possible pour chaque établissement tout en maintenant des normes de qualité basées sur des métriques de performance empiriques.
Afficher le code
# extraire l'ordre des méthodes et les seuils des résultats de l'étape 7.4
# classer les méthodes par score de structure (du plus élevé au plus bas)
method_stats <- summary_stats |>
dplyr::arrange(dplyr::desc(structure_score)) |>
dplyr::filter(method != "Rank-Ensemble") # exclure la méthode basée sur les rangs
method_order <- method_stats$method
# utiliser les seuils calculés à l'étape 7.4
method_thresholds_df <- method_threshold |>
dplyr::filter(method != "Rank-Ensemble")
# convertir en vecteur nommé pour une recherche rapide
method_thresholds <- setNames(
method_thresholds_df$threshold,
method_thresholds_df$method
)
# construire le tableau combiné des meilleures correspondances des méthodes réelles uniquement
all_best_nonrank <- dplyr::bind_rows(
best_lv,
best_jw,
best_qg,
best_lcs,
best_comp
) |>
# normaliser les étiquettes de méthode
dplyr::mutate(method = trimws(method))
# ajouter le rang une seule fois
rank_key <- ranked_grid |>
dplyr::select(hf_dhis2, hf_mfl, rank_avg)
all_best_ranked <- all_best_nonrank |>
dplyr::left_join(rank_key, by = c("hf_dhis2", "hf_mfl")) |>
dplyr::mutate(
# valeur la plus défavorable pour les rangs manquants
rank_avg = dplyr::if_else(is.na(rank_avg), Inf, rank_avg)
)
# diviser par méthode et pré-trier pour un départage stable
by_method <- split(all_best_ranked, all_best_ranked$method) |>
purrr::map(\(x) {
x |>
dplyr::arrange(dplyr::desc(score), rank_avg)
})
# conserver une copie pour la vérification du taux de passage
initial_thr <- method_thresholds
# initialisation
fallback_chunks <- list()
unmatched <- unique(all_best_ranked$hf_dhis2)
# boucle de repli rapide (sans jointures ni regroupements internes)
repeat {
for (m in method_order) {
if (!m %in% names(by_method)) {
next
}
# seuil courant de l'étape 7.4
thr <- method_thresholds[[m]]
if (is.null(thr)) {
thr <- 85 # repli si la méthode n'est pas trouvée
}
# filtrer par score et encore non apparié
cand <- by_method[[m]] |>
dplyr::filter(score >= thr, hf_dhis2 %in% unmatched)
if (nrow(cand) > 0) {
# sélectionner la première ligne par hf_dhis2 (pré-triée par score desc, rang asc)
best_per_hf <- cand |>
dplyr::distinct(hf_dhis2, .keep_all = TRUE) |>
dplyr::mutate(
final_method = glue::glue("Fuzzy-matched using: {m}")
)
# stocker et mettre à jour les non appariés
fallback_chunks[[length(fallback_chunks) + 1L]] <- best_per_hf
unmatched <- setdiff(unmatched, best_per_hf$hf_dhis2)
}
if (length(unmatched) == 0) break
}
if (length(unmatched) == 0) {
break
}
# relâcher progressivement les seuils
method_thresholds <- method_thresholds - 1
if (any(method_thresholds <= 50)) break # arrêter si trop bas
}
# combiner une seule fois
fallback_matched <- dplyr::bind_rows(fallback_chunks)
# construire une correspondance 1:1 depuis le nom DHIS2 standardisé vers admin + brut +
# hf_uid_new
hf_uid_new_map_by_stand <- dhis2_hf_unmatched |>
dplyr::arrange(adm0, adm1, adm2, adm3, hf_dhis2_raw) |>
dplyr::group_by(hf_dhis2) |>
dplyr::summarise(
adm0 = dplyr::first(adm0),
adm1 = dplyr::first(adm1),
adm2 = dplyr::first(adm2),
adm3 = dplyr::first(adm3),
hf_dhis2_raw = dplyr::first(hf_dhis2_raw),
hf_uid_new = dplyr::first(hf_uid_new),
.groups = "drop"
)
# indicateurs finaux et rattachement des unités administratives + identifiants
fallback_final <- fallback_matched |>
dplyr::mutate(
match_flag = dplyr::if_else(score >= 85, "match", "review")
) |>
dplyr::left_join(
dplyr::select(master_hf_df, hf_mfl, hf_mfl_raw),
by = "hf_mfl"
) |>
dplyr::left_join(hf_uid_new_map_by_stand, by = "hf_dhis2") |>
dplyr::select(
adm0, adm1, adm2, adm3,
hf_uid_new,
hf_dhis2_raw,
hf_dhis2,
hf_mfl_raw,
hf_mfl,
score,
final_method,
match_flag
)
top_5 <- fallback_final |>
dplyr::arrange(dplyr::desc(score)) |>
dplyr::slice_head(n = 5)
bottom_5 <- fallback_final |>
dplyr::arrange(score) |>
dplyr::slice_head(n = 5)
cli::cli_h3("5 premiers et 5 derniers appariements par repli")
bottom_5 <- dplyr::bind_rows(top_5, bottom_5)
# aperçu des résultats
bottom_5Pour adapter le code :
- Lignes 2–8 : L’ordre des méthodes est automatiquement déterminé à partir des scores de structure de
summary_stats. - Lignes 10–18 : Les seuils sont extraits du dataframe
method_thresholdde l’étape 7.4. - Ligne 66 : Le seuil de repli (valeur par défaut = 85) est utilisé uniquement si une méthode ne dispose pas d’un seuil calculé.
- Ligne 95 : Le seuil minimum (valeur par défaut = 50) empêche d’accepter des correspondances de très mauvaise qualité.
- Lignes 33, 36, partout : Remplacer
hf_dhis2ethf_mflpar les noms de colonnes du jeu de données s’ils diffèrent.
Afficher le code
# extraire l'ordre des méthodes et les seuils des résultats de l'étape 7.4
# classer les méthodes par score de structure (du plus élevé au plus bas)
method_stats = summary_stats.loc[
summary_stats["method"] != "Rank-Ensemble"
].sort_values("structure_score", ascending=False)
method_order = list(method_stats["method"])
# utiliser les seuils calculés à l'étape 7.4
method_thresholds_df = method_threshold.loc[method_threshold["method"] != "Rank-Ensemble"]
method_thresholds = dict(zip(method_thresholds_df["method"], method_thresholds_df["threshold"]))
# construire le tableau combiné des meilleures correspondances des méthodes réelles uniquement
all_best_nonrank = pd.concat(
[best_lv, best_jw, best_qg, best_lcs, best_comp], ignore_index=True
)
all_best_nonrank["method"] = all_best_nonrank["method"].str.strip()
# ajouter le rang une seule fois
rank_key = ranked_grid[["hf_dhis2", "hf_mfl", "rank_avg"]].copy()
all_best_ranked = (
all_best_nonrank
.merge(rank_key, on=["hf_dhis2", "hf_mfl"], how="left")
.assign(rank_avg=lambda d: d["rank_avg"].fillna(float("inf")))
)
# diviser par méthode et pré-trier pour un départage stable
by_method = {
m: grp.sort_values(["score", "rank_avg"], ascending=[False, True])
for m, grp in all_best_ranked.groupby("method")
}
fallback_chunks = []
unmatched_set = set(all_best_ranked["hf_dhis2"].unique())
current_thresholds = dict(method_thresholds)
# boucle de repli rapide
while True:
for m in method_order:
if m not in by_method:
continue
thr = current_thresholds.get(m, 85) # repli si la méthode n'est pas trouvée
cand = by_method[m].loc[
(by_method[m]["score"] >= thr) &
(by_method[m]["hf_dhis2"].isin(unmatched_set))
]
if len(cand) > 0:
best_per_hf = (
cand.drop_duplicates(subset="hf_dhis2", keep="first")
.assign(final_method=f"Fuzzy-matched using: {m}")
)
fallback_chunks.append(best_per_hf)
unmatched_set -= set(best_per_hf["hf_dhis2"])
if not unmatched_set:
break
if not unmatched_set:
break
# relâcher progressivement les seuils
current_thresholds = {k: v - 1 for k, v in current_thresholds.items()}
if any(v <= 50 for v in current_thresholds.values()): # arrêter si trop bas
break
# combiner une seule fois
fallback_matched = (
pd.concat(fallback_chunks, ignore_index=True)
if fallback_chunks else pd.DataFrame()
)
# construire une correspondance 1:1 depuis le nom DHIS2 standardisé vers admin + brut + hf_uid_new
hf_uid_new_map_by_stand = (
dhis2_hf_unmatched
.sort_values(["adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw"])
.groupby("hf_dhis2", as_index=False)
.first()[["hf_dhis2", "adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw", "hf_uid_new"]]
)
# indicateurs finaux et rattachement des unités administratives + identifiants
fallback_final = (
fallback_matched
.assign(match_flag=lambda d: np.where(d["score"] >= 85, "match", "review"))
.merge(master_hf_df[["hf_mfl", "hf_mfl_raw"]], on="hf_mfl", how="left")
.merge(hf_uid_new_map_by_stand, on="hf_dhis2", how="left")
[["adm0", "adm1", "adm2", "adm3", "hf_uid_new",
"hf_dhis2_raw", "hf_dhis2", "hf_mfl_raw", "hf_mfl",
"score", "final_method", "match_flag"]]
)
top_5 = fallback_final.sort_values("score", ascending=False).head(5)
bottom_5 = fallback_final.sort_values("score").head(5)
cli_header("5 premiers et 5 derniers appariements par repli")
bottom_5 = pd.concat([top_5, bottom_5], ignore_index=True)
# aperçu des résultats
bottom_5Pour adapter le code :
- Lignes 2–7 : L’ordre des méthodes est automatiquement déterminé à partir des scores de structure de
summary_stats. - Lignes 9–12 : Les seuils sont extraits du dataframe
method_thresholdde l’étape 7.4. - Ligne 46 : Le seuil de repli (valeur par défaut = 85) est utilisé uniquement si une méthode ne dispose pas d’un seuil calculé.
- Ligne 58 : Le seuil minimum (valeur par défaut = 50) empêche d’accepter des correspondances de très mauvaise qualité.
- Lignes 22, 76, partout : Remplacer
hf_dhis2ethf_mflpar les noms de colonnes du jeu de données s’ils diffèrent.
La boucle de repli a atteint le taux de correspondance le plus élevé, comme indiqué dans la sortie ci-dessus. Cette amélioration substantielle par rapport aux autres méthodes démontre l’efficacité des seuils spécifiques à chaque méthode et du repli progressif. L’approche maximise la couverture tout en maintenant la qualité grâce à des seuils fondés sur les données et un départage intelligent.
C’est l’approche que nous utiliserons par la suite, car elle offre le meilleur équilibre entre couverture et qualité des correspondances, réduit la charge de révision manuelle et adapte dynamiquement les seuils aux forces et faiblesses de chaque méthode.
Étape 8.2 : Sélectionner l’approche d’appariement flou
Après avoir examiné les différentes options d’appariement flou de l’étape 8.1, sélectionnez l’approche à utiliser. Cette étape crée le jeu de données fuzzy_matches qui sera combiné avec les autres méthodes d’appariement à l’étape 9.
NoteChoisir une approche
Sélectionner une approche en fonction de l’évaluation de l’étape 8.1 : - Utiliser un algorithme unique (Levenshtein, Jaro-Winkler ou Q-gram) pour la simplicité et l’interprétabilité - Utiliser des scores composites pour équilibrer plusieurs algorithmes - Utiliser une approche pondérée lorsque l’expertise du domaine suggère que certains algorithmes sont plus fiables pour les données - Utiliser une approche de repli pour l’appariement le plus complet avec un scoring hiérarchique
Afficher le code
# créer fuzzy_matches à partir des résultats de l'étape 8 (utiliser l'option choisie)
# l'étape 8 produit différents jeux de données selon l'option choisie :
# - option 1: best_lv_final, best_jw_final, etc.
# - option 2: composite_final
# - option 3: weighted_final
# - option 4: fallback_final
fuzzy_matches <- if (exists("fallback_final")) {
dplyr::filter(fallback_final, match_flag == "match")
} else if (exists("composite_final")) {
dplyr::filter(composite_final, match_flag == "match")
} else if (exists("weighted_final")) {
dplyr::filter(weighted_final, match_flag == "match")
} else if (exists("best_lv_final")) {
dplyr::filter(best_lv_final, match_flag == "match")
} else if (exists("best_jw_final")) {
dplyr::filter(best_jw_final, match_flag == "match")
} else if (exists("best_qg_final")) {
dplyr::filter(best_qg_final, match_flag == "match")
} else {
# dataframe vide avec la structure attendue si aucun résultat de l'étape 8 n'existe
data.frame(
hf_dhis2_raw = character(0),
hf_dhis2 = character(0),
hf_mfl_raw = character(0),
hf_mfl = character(0),
score = numeric(0),
final_method = character(0),
stringsAsFactors = FALSE
)
} |>
# supprimer les doublons internes (conserver la correspondance avec le score le plus élevé
# par établissement)
dplyr::group_by(hf_dhis2_raw) |>
dplyr::slice_max(score, n = 1, with_ties = FALSE) |>
dplyr::ungroup() |>
# rattacher admin + hf_uid_new depuis les non appariés (réduire à 1:1 par
# hf_dhis2_raw)
{
hf_uid_new_map_unmatched <- dhis2_hf_unmatched |>
dplyr::arrange(adm0, adm1, adm2, adm3, hf_dhis2_raw) |>
dplyr::group_by(hf_dhis2_raw) |>
dplyr::summarise(
adm0 = dplyr::first(adm0),
adm1 = dplyr::first(adm1),
adm2 = dplyr::first(adm2),
adm3 = dplyr::first(adm3),
hf_uid_new = dplyr::first(hf_uid_new),
.groups = "drop"
)
dplyr::left_join(., hf_uid_new_map_unmatched, by = "hf_dhis2_raw")
}
# afficher le récapitulatif de l'approche sélectionnée
cli::cli_h2("Résultats de l'appariement flou sélectionné")
cli::cli_alert_success("Correspondances floues trouvées : {nrow(fuzzy_matches)}")
if (nrow(fuzzy_matches) > 0) {
score_summary <- fuzzy_matches |>
dplyr::summarise(
avg_score = mean(score, na.rm = TRUE),
min_score = min(score, na.rm = TRUE),
max_score = max(score, na.rm = TRUE),
.groups = "drop"
)
cli::cli_alert_info("Plage de scores : {round(score_summary$min_score, 1)} - {round(score_summary$max_score, 1)}")
cli::cli_alert_info("Score moyen : {round(score_summary$avg_score, 1)}")
}Pour adapter le code :
- Lignes 12–24 : La logique conditionnelle vérifie les différents jeux de données de résultats de l’étape 8 par ordre de priorité. Modifier l’ordre si une approche différente doit avoir la priorité.
- Lignes 25–34 : Créer une structure de dataframe vide si aucun résultat de l’étape 8 n’existe. S’assurer que les noms de colonnes correspondent à la structure attendue.
- Lignes 38–40 : La logique de déduplication supprime les doublons internes au sein de l’approche sélectionnée, en conservant la correspondance avec le score le plus élevé par établissement DHIS2. Modifier si des règles de déduplication différentes sont nécessaires.
- Approche alternative : Au lieu de la logique conditionnelle, assigner directement le jeu de données choisi : ````
Afficher le code
# créer fuzzy_matches à partir des résultats de l'étape 8 (utiliser l'option choisie)
# l'étape 8 produit différents jeux de données selon l'option choisie :
# - option 1: best_lv_final, best_jw_final, etc.
# - option 2: composite_final
# - option 3: weighted_final
# - option 4: fallback_final
if "fallback_final" in dir():
fuzzy_matches_raw = fallback_final.loc[fallback_final["match_flag"] == "match"]
elif "composite_final" in dir():
fuzzy_matches_raw = composite_final.loc[composite_final["match_flag"] == "match"]
elif "weighted_final" in dir():
fuzzy_matches_raw = weighted_final.loc[weighted_final["match_flag"] == "match"]
elif "best_lv_final" in dir():
fuzzy_matches_raw = best_lv_final.loc[best_lv_final["match_flag"] == "match"]
elif "best_jw_final" in dir():
fuzzy_matches_raw = best_jw_final.loc[best_jw_final["match_flag"] == "match"]
elif "best_qg_final" in dir():
fuzzy_matches_raw = best_qg_final.loc[best_qg_final["match_flag"] == "match"]
else:
# dataframe vide avec la structure attendue si aucun résultat de l'étape 8 n'existe
fuzzy_matches_raw = pd.DataFrame(columns=[
"hf_dhis2_raw", "hf_dhis2", "hf_mfl_raw", "hf_mfl",
"score", "final_method",
])
# dédupliquer : conserver la correspondance avec le score le plus élevé par établissement DHIS2
fuzzy_matches = (
fuzzy_matches_raw
.sort_values("score", ascending=False)
.drop_duplicates(subset="hf_dhis2_raw", keep="first")
.merge(
dhis2_hf_unmatched[["adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw", "hf_uid_new"]]
.sort_values(["adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw"])
.drop_duplicates(subset="hf_dhis2_raw", keep="first"),
on="hf_dhis2_raw",
how="left",
)
)
# afficher le récapitulatif de l'approche sélectionnée
cli_header("Résultats de l'appariement flou sélectionné")
cli_success(f"Correspondances floues trouvées : {len(fuzzy_matches)}")
if len(fuzzy_matches) > 0:
cli_info(
f"Plage de scores : {fuzzy_matches['score'].min():.1f} - "
f"{fuzzy_matches['score'].max():.1f}"
)
cli_info(f"Score moyen : {fuzzy_matches['score'].mean():.1f}")Pour adapter le code :
- Lignes 12–24 : La logique conditionnelle vérifie les différents jeux de données de résultats de l’étape 8 par ordre de priorité. Modifier l’ordre si une approche différente doit avoir la priorité.
- Lignes 25–28 : Créer une structure de dataframe vide si aucun résultat de l’étape 8 n’existe. S’assurer que les noms de colonnes correspondent à la structure attendue.
- Lignes 31–41 : La logique de déduplication supprime les doublons internes, en conservant la correspondance avec le score le plus élevé par établissement DHIS2. Modifier si des règles de déduplication différentes sont nécessaires.
Étape 8.3 : Révision manuelle des correspondances signalées
Avant de finaliser les correspondances et de les fusionner avec les jeux de données principaux, tous les enregistrements signalés comme review doivent être validés ou rejetés manuellement par l’équipe SNT ou les réviseurs désignés. Cette étape garantit la qualité des données et empêche les faux positifs d’entrer dans l’analyse.
ImportantConsulter l’équipe SNT
La révision manuelle est requise pour toutes les correspondances review avant de passer à l’étape 9. L’équipe SNT doit confirmer ou rejeter les correspondances incertaines et documenter les schémas de faux positifs ou de correspondances manquées afin d’affiner les futurs workflows d’appariement.
Préparation des données pour la révision manuelle
Ci-dessous, nous exportons les correspondances review vers un fichier structuré pour une vérification systématique :
Afficher le code
# préparer le jeu de données de révision (en utilisant les résultats de repli comme exemple)
review_matches <- fallback_final |>
dplyr::filter(match_flag == "review") |>
dplyr::arrange(dplyr::desc(score)) |>
dplyr::mutate(
reviewer_decision = NA_character_, # accept/reject/uncertain
reviewer_notes = NA_character_,
review_date = NA_character_,
reviewer_name = NA_character_
) |>
dplyr::select(
adm0, adm1, adm2, adm3, hf_uid_new,
hf_dhis2_raw,
hf_dhis2,
hf_mfl_raw,
hf_mfl,
score,
final_method,
reviewer_decision,
reviewer_notes,
review_date,
reviewer_name
)
# exporter pour révision
readr::write_csv(
review_matches,
here::here("03_outputs", "tables", "facility_matches_for_review.csv")
)
# afficher le récapitulatif
cli::cli_h2("Révision manuelle requise")
cli::cli_alert_info(
"Exporté {nrow(review_matches)} correspondances signalées pour révision"
)
cli::cli_alert_info(
"Emplacement du fichier : outputs/facility_matches_for_review.csv"
)Pour adapter le code :
- Lignes 6–9 : Ajouter des colonnes supplémentaires pour le processus de révision (par exemple facility_type, district).
- Lignes 26–29 : Ajuster le chemin et le nom du fichier de sortie selon les besoins.
Afficher le code
# préparer le jeu de données de révision (en utilisant les résultats de repli comme exemple)
review_matches = (
fallback_final
.loc[fallback_final["match_flag"] == "review"]
.sort_values("score", ascending=False)
.assign(
reviewer_decision=pd.NA, # accept/reject/uncertain
reviewer_notes=pd.NA,
review_date=pd.NA,
reviewer_name=pd.NA,
)
[["adm0", "adm1", "adm2", "adm3", "hf_uid_new",
"hf_dhis2_raw", "hf_dhis2", "hf_mfl_raw", "hf_mfl",
"score", "final_method",
"reviewer_decision", "reviewer_notes", "review_date", "reviewer_name"]]
)
# exporter pour révision
output_dir = Path(here("03_outputs/tables"))
output_dir.mkdir(parents=True, exist_ok=True)
review_matches.to_csv(output_dir / "facility_matches_for_review.csv", index=False)
# afficher le récapitulatif
cli_header("Révision manuelle requise")
cli_info(f"Exporté {len(review_matches)} correspondances signalées pour révision")
cli_info("Emplacement du fichier : outputs/tables/facility_matches_for_review.csv")Pour adapter le code :
- Lignes 6–9 : Ajouter des colonnes supplémentaires pour le processus de révision (par exemple facility_type, district).
- Lignes 24–25 : Ajuster le chemin et le nom du fichier de sortie selon les besoins.
Lignes directrices pour le processus de révision
L’étape de révision manuelle va au-delà d’une simple décision oui/non. C’est une occasion de renforcer le workflow d’appariement en confirmant les liens exacts, en rejetant les faux positifs et en documentant les problèmes de qualité des données récurrents. Les réviseurs jouent un rôle clé pour garantir l’intégrité du jeu de données final et pour améliorer le processus lors des prochaines exécutions.
Pour les réviseurs :
- Accepter : confirmer que les deux noms font référence au même établissement. Rechercher des preuves solides d’équivalence, telles que :
- Variations orthographiques mineures :
"Makeni Gov Hospital"↔︎"Makeni Government Hospital" - Abréviations courantes ou cohérentes :
Bo CHC↔︎Bo Community Health Center - Petites différences de formatage qui n’altèrent pas le sens
- Variations orthographiques mineures :
- Rejeter : signaler les cas où les établissements diffèrent ou où la correspondance est trop incertaine. Exemples courants :
- Types d’établissements différents dans la même zone :
"Makeni Hospital"↔︎"Makeni Clinic" - Noms génériques sans qualificatif géographique :
Community Health Postsans localisation - Plusieurs correspondances possibles dans le même voisinage sans identifiants clairs
- Types d’établissements différents dans la même zone :
- Documenter les schémas : utiliser la révision pour capturer les problèmes récurrents. Ces informations aident à affiner les seuils, les poids et les règles d’appariement. Exemples :
- Incompatibilités d’abréviations fréquentes (par exemple
CHCvsCH Centre) - Conventions de nommage régionales ou spécifiques à une langue
- Données d’unités administratives manquantes ou incohérentes dans les systèmes source
- Incompatibilités d’abréviations fréquentes (par exemple
Une approche systématique de la révision garantit que les correspondances acceptées sont fiables, que les correspondances rejetées sont bien justifiées et que les enseignements tirés alimentent directement l’amélioration du prochain cycle d’appariement.
Décisions de révision simulées
À des fins de démonstration, nous simulons les décisions des réviseurs sur les correspondances signalées. En pratique, cela serait effectué par des experts du domaine examinant le fichier CSV exporté.
Après la révision manuelle, nous importons les données contenant toutes les décisions.
Afficher le code
# simuler les décisions des réviseurs (remplacer par les données réellement révisées)
# relire les correspondances révisées
reviewed_matches <- readr::read_csv(
here::here("03_outputs", "tables", "facility_matches_reviewed.csv"),
col_types = readr::cols(
reviewer_decision = readr::col_character(),
reviewer_notes = readr::col_character(),
review_date = readr::col_character(),
reviewer_name = readr::col_character()
)
)Pour adapter le code :
- Ligne 4 : Mettre à jour le chemin du fichier vers le répertoire de sortie du projet.
- Lignes 6–9 : Ajouter des types de colonnes supplémentaires si le fichier de révision inclut des champs supplémentaires.
Afficher le code
# simuler les décisions des réviseurs (remplacer par les données réellement révisées)
# relire les correspondances révisées
reviewed_matches = pd.read_csv(
here("03_outputs/tables/facility_matches_reviewed.csv"),
dtype={
"reviewer_decision": "object",
"reviewer_notes": "object",
"review_date": "object",
"reviewer_name": "object",
}
)Pour adapter le code :
- Ligne 4 : Mettre à jour le chemin du fichier vers le répertoire de sortie du projet.
- Lignes 5–9 : Ajouter des spécifications de type de données supplémentaires si le fichier de révision inclut des champs supplémentaires.
Intégration des résultats de la révision
Nous intégrons maintenant les décisions des réviseurs dans le workflow d’appariement :
Afficher le code
final_incorp <- reviewed_matches |>
dplyr::mutate(
final_match_flag = dplyr::case_when(
reviewer_decision == "accept" ~ "match",
reviewer_decision == "reject" ~ "no_match",
is.na(reviewer_decision) ~ "pending_review",
TRUE ~ "no_match"
)
)
# obtenir les correspondances finalement acceptées
final_matches <- final_incorp |>
dplyr::filter(final_match_flag == "match") |>
dplyr::select(-reviewer_decision)
# récapitulatif de tous les résultats (y compris rejetés/en attente)
all_results_summary <- final_incorp |>
dplyr::count(final_match_flag, name = "n") |>
dplyr::mutate(percentage = round(100 * n / sum(n), 1))
# récapitulatif des correspondances finalement acceptées uniquement
final_summary <- final_matches |>
dplyr::count(final_match_flag, name = "n")
cli::cli_h2("Résultats finaux de l'appariement après révision manuelle")
cli::cli_alert_success(
"Correspondances acceptées : {format(sum(final_summary$n), big.mark = ',')}"
)
# ventilation par type de décision
rejected_count <- all_results_summary |>
dplyr::filter(final_match_flag == "no_match") |>
dplyr::pull(n)
if (length(rejected_count) == 0) {
rejected_count <- 0
}
pending_count <- all_results_summary |>
dplyr::filter(final_match_flag == "pending_review") |>
dplyr::pull(n)
if (length(pending_count) == 0) {
pending_count <- 0
}
if (rejected_count > 0) {
cli::cli_alert_danger(
"Correspondances rejetées : {format(rejected_count, big.mark = ',')} (auront des valeurs NA dans les colonnes MFL du jeu de données final)"
)
}
if (pending_count > 0) {
cli::cli_alert_warning(
"En attente de révision : {format(pending_count, big.mark = ',')} (nécessitent une révision supplémentaire)"
)
}
# afficher le tableau de ventilation
all_results_summaryPour adapter le code :
- [Code supprimé] : Mettre à jour le chemin du fichier de
"03_outputs"vers le répertoire de sortie du projet (aucun chemin de fichier dans ce bloc ; voir le bloc de simulation des décisions des réviseurs ci-dessus). - [Code supprimé] : Ajouter des types de colonnes supplémentaires si le fichier de révision inclut des champs supplémentaires (aucun type de colonne dans ce bloc ; voir le bloc de simulation des décisions des réviseurs ci-dessus).
- Lignes 3–9 : Ajuster la logique de traitement des différentes catégories de décisions des réviseurs selon le workflow du projet.
Afficher le code
final_incorp = reviewed_matches.assign(
final_match_flag=lambda d: np.select(
[
d["reviewer_decision"] == "accept",
d["reviewer_decision"] == "reject",
d["reviewer_decision"].isna(),
],
["match", "no_match", "pending_review"],
default="no_match",
)
)
# obtenir les correspondances finalement acceptées
final_matches = (
final_incorp
.loc[final_incorp["final_match_flag"] == "match"]
.drop(columns="reviewer_decision", errors="ignore")
)
# récapitulatif de tous les résultats (y compris rejetés/en attente)
all_results_summary = (
final_incorp.groupby("final_match_flag", as_index=False)
.size()
.rename(columns={"size": "n"})
.assign(percentage=lambda d: (d["n"] / d["n"].sum() * 100).round(1))
)
cli_header("Résultats finaux de l'appariement après révision manuelle")
cli_success(f"Correspondances acceptées : {len(final_matches):,}")
# ventilation par type de décision
rejected_count = int(
all_results_summary.loc[all_results_summary["final_match_flag"] == "no_match", "n"].sum()
)
pending_count = int(
all_results_summary.loc[
all_results_summary["final_match_flag"] == "pending_review", "n"
].sum()
)
if rejected_count > 0:
cli_danger(
f"Correspondances rejetées : {rejected_count:,} "
"(auront des valeurs NA dans les colonnes MFL du jeu de données final)"
)
if pending_count > 0:
cli_warning(f"En attente de révision : {pending_count:,} (nécessitent une révision supplémentaire)")
# afficher le tableau de ventilation
all_results_summaryPour adapter le code :
- Lignes 3–9 : Ajuster la logique de traitement des différentes catégories de décisions des réviseurs selon le workflow du projet.
Sur les 159 correspondances proposées, aucune n’a été acceptée, toutes semblant désigner des établissements différents. Cela peut suggérer des problèmes de qualité des données sous-jacents ou la présence de nouveaux noms d’établissements de santé.
Les établissements DHIS2 dont les correspondances ont été rejetées apparaîtront dans le jeu de données final (étape 9) avec des valeurs NA pour les colonnes MFL, ce qui préserve l’enregistrement de l’établissement tout en indiquant clairement qu’aucune correspondance fiable n’a été trouvée. Les établissements en attente de révision doivent être traités avant de passer à une utilisation en production. ### Étape 9 : Combiner tous les résultats de correspondance
Dans cette étape, nous combinons les résultats de toutes les approches de correspondance et finalisons le jeu de données en effectuant une jointure avec la liste originale des établissements de santé DHIS2. Cela crée un jeu de données complet qui inclut :
- Les correspondances à haute confiance de l’Étape 4 (Correspondance géographique stratifiée interactive)
- Les correspondances floues des Étapes 6 à 8 (Diverses stratégies de correspondance floue sur les établissements restants sans correspondance)
- Les établissements sans correspondance (Conservés avec des valeurs NA pour les colonnes MFL)
Étape 9.1 : Combiner les résultats de toutes les approches de correspondance
Lorsque l’on utilise le flux de travail amélioré avec une correspondance stratifiée, on combine les résultats de toutes les étapes :
Afficher le code
# créer manual_matches à partir des résultats de la révision manuelle
# (correspondances acceptées et rejetées)
manual_matches <- final_incorp |>
dplyr::mutate(
# pour les établissements sans correspondance, définir des valeurs appropriées
hf_mfl = dplyr::if_else(
reviewer_decision == "accept",
hf_mfl,
NA_character_
),
hf_mfl_raw = dplyr::if_else(
reviewer_decision == "accept",
hf_mfl_raw,
NA_character_
),
final_method = dplyr::if_else(
reviewer_decision == "accept",
"Manual Review - Accepted",
"Manual Review - Rejected"
),
score = dplyr::if_else(
reviewer_decision == "accept",
100,
0
)
) |>
# les résultats révisés manuellement portent déjà adm0-3 + hf_uid_new
# depuis fallback_final → export révision → réimportation
dplyr::select(
adm0,
adm1,
adm2,
adm3,
hf_uid_new,
hf_dhis2_raw,
hf_dhis2,
hf_mfl_raw,
hf_mfl,
score,
final_method
)
# combiner les résultats de toutes les approches de correspondance
# ce jeu de données contient TOUS les établissements : avec correspondance,
# sans correspondance et rejetés
final_facilities_all <- dplyr::bind_rows(
# étape 4 : correspondances géographiques stratifiées (si effectuées)
matched_dhis2_prepgeoname,
# étape 5 : correspondances exactes après standardisation
matched_dhis2,
# étapes 6-8 : correspondances complètes issues de la correspondance floue
fuzzy_matches,
# correspondance manuelle (si effectuée)
manual_matches
)
# sauvegarder pour le chargement par l'état de rendu python (parité règle 6.4)
write.csv(
final_facilities_all,
here::here("01_data/1.1_foundational/1.1c_health_facilities/processed/final_facilities_all.csv"),
row.names = FALSE
)
# réduire à un enregistrement par établissement DHIS2 pour l'intégration aval
final_facilities_one_per_hf <- final_facilities_all |>
dplyr::select(-match_flag, -hf)
cli::cli_alert_info(
"Tous les établissements traités (lignes) : {nrow(final_facilities_all)}"
)
cli::cli_alert_success(
"Tous les établissements traités (DHIS2 distincts par adm0/1/2/3+hf) : {dplyr::n_distinct(final_facilities_all$hf_uid_new)}"
)
# générer un résumé par méthode de correspondance
matching_summary <- final_facilities_one_per_hf |>
dplyr::group_by(final_method) |>
dplyr::summarise(
n_matched = n(),
avg_score = mean(score, na.rm = TRUE),
min_score = min(score, na.rm = TRUE),
max_score = max(score, na.rm = TRUE),
.groups = "drop"
)
# afficher le résumé
cli::cli_h2("Résultats de correspondance par méthode")
matching_summaryPour adapter le code :
- [Code supprimé] : La logique
fuzzy_matchesdétecte automatiquement l’approche de l’Étape 8 utilisée. Modifiez l’ordre ou ajoutez des variables de résultat supplémentaires de l’Étape 8 si nécessaire (cette logique se trouve dans le chunk de sélection de l’approche floue, Étape 8.2). - Lignes 3–41 : La logique
manual_matchestraite les établissements avec et sans correspondance issus definal_incorp. Remplacezfinal_incorppar le nom du jeu de données des résultats de révision manuelle. - Lignes 16–25 : Les établissements rejetés lors de la révision manuelle reçoivent
final_method = "Manual Review - Rejected"etscore = 0. Ajustez ces étiquettes si nécessaire. - Lignes 46–55 : Le
bind_rowscombine toutes les approches de correspondance. Ajoutez ou supprimez des lignes selon les étapes utilisées dans le flux de travail. - [Code supprimé] : La logique de déduplication supprime les doublons en conservant la correspondance avec le score le plus élevé pour chaque établissement DHIS2 (groupé par
hf_dhis2_rawuniquement). Modifiez si des règles de déduplication différentes sont nécessaires (la déduplication se trouve dans le chunk de sélection de l’approche floue, Étape 8.2). - [Code supprimé] : Les vérifications de validation détectent les doublons internes dans chaque jeu de données et vérifient que le jeu de données combiné final ne contient pas de doublons. Supprimez ou modifiez ces vérifications si nécessaire (non présentes dans ce chunk).
Afficher le code
# créer manual_matches à partir des résultats de la révision manuelle
# (correspondances et non-correspondances)
manual_matches = final_incorp.assign(
# pour les établissements sans correspondance, définir des valeurs appropriées
hf_mfl=lambda d: np.where(d["reviewer_decision"] == "accept", d["hf_mfl"], pd.NA),
hf_mfl_raw=lambda d: np.where(
d["reviewer_decision"] == "accept", d["hf_mfl_raw"], pd.NA
),
final_method=lambda d: np.where(
d["reviewer_decision"] == "accept",
"Manual Review - Accepted",
"Manual Review - Rejected",
),
score=lambda d: np.where(d["reviewer_decision"] == "accept", 100, 0),
)
cols_needed = [
"adm0", "adm1", "adm2", "adm3", "hf_uid_new",
"hf_dhis2_raw", "hf_dhis2", "hf_mfl_raw", "hf_mfl", "score", "final_method",
]
manual_matches = manual_matches[[c for c in cols_needed if c in manual_matches.columns]]
# combiner les résultats de toutes les approches de correspondance
# ce jeu de données contient TOUS les établissements : avec correspondance,
# sans correspondance et rejetés
final_facilities_all = pd.concat(
[
# étape 4 : correspondances géographiques stratifiées (si effectuées)
matched_dhis2_prepgeoname[[c for c in cols_needed if c in matched_dhis2_prepgeoname.columns]],
# étape 5 : correspondances exactes après standardisation
matched_dhis2[[c for c in cols_needed if c in matched_dhis2.columns]],
# étapes 6-8 : correspondances complètes issues de la correspondance floue
fuzzy_matches[[c for c in cols_needed if c in fuzzy_matches.columns]],
# correspondance manuelle (si effectuée)
manual_matches,
],
ignore_index=True,
)
# réduire à un enregistrement par établissement DHIS2 pour l'intégration aval
cols_to_drop = [c for c in ["match_flag", "hf"] if c in final_facilities_all.columns]
final_facilities_one_per_hf = final_facilities_all.drop(columns=cols_to_drop, errors="ignore")
cli_info(f"Tous les établissements traités (lignes) : {len(final_facilities_all)}")
cli_success(
f"Tous les établissements traités (DHIS2 distincts par hf_uid_new) : "
f"{final_facilities_all['hf_uid_new'].nunique()}"
)
# générer un résumé par méthode de correspondance
matching_summary = (
final_facilities_one_per_hf
.groupby("final_method", as_index=False)
.agg(
n_matched=("hf_dhis2_raw", "count"),
avg_score=("score", "mean"),
min_score=("score", "min"),
max_score=("score", "max"),
)
)
# afficher le résumé
cli_header("Résultats de correspondance par méthode")
matching_summaryPour adapter le code :
- Lignes 3–22 : La logique
manual_matchestraite les établissements avec et sans correspondance issus definal_incorp. Remplacezfinal_incorppar le nom du jeu de données des résultats de révision manuelle. - Lignes 12–15 : Les établissements rejetés lors de la révision manuelle reçoivent
final_method = "Manual Review - Rejected"etscore = 0. Ajustez ces étiquettes si nécessaire. - Lignes 28–37 :
pd.concatcombine toutes les approches de correspondance. Ajoutez ou supprimez des dataframes selon les étapes utilisées.
Étape 9.2 : Créer le jeu de données intégré DHIS2-MFL final
Créez le jeu de données analytique final en prenant DHIS2 comme base et en l’enrichissant avec les données MFL là où des correspondances existent. Cela garantit qu’aucun établissement DHIS2 n’est perdu tout en ajoutant de précieux attributs MFL.
Afficher le code
# prendre DHIS2 comme base pour conserver toutes les lignes ;
# rattacher hf_uid_new
dhis2_df_final <- dhis2_df |>
dplyr::left_join(
dhis2_map,
by = c("adm0", "adm1", "adm2", "adm3", "hf")
)
# résultats de correspondance par établissement : utiliser hf_uid_new comme
# clé de jointure
final_match_per_hf <- final_facilities_one_per_hf |>
dplyr::select(hf_uid_new, hf_mfl_raw)
# créer le jeu de données intégré
final_dhis2_mfl_df <- dhis2_df_final |>
dplyr::left_join(final_match_per_hf, by = "hf_uid_new") |>
# joindre les attributs MFL pour les établissements avec correspondance
dplyr::left_join(
dplyr::select(master_hf_df, -hf_mfl, -hf, -adm0, -adm1, -adm2, -adm3),
by = "hf_mfl_raw"
)
# comptages sur les établissements distincts via hf_uid_new (robuste aux
# doublons au niveau des lignes)
total <- dhis2_df_final |> dplyr::distinct(hf_uid_new) |> nrow()
with_mfl <- final_match_per_hf |>
dplyr::filter(!is.na(hf_mfl_raw)) |>
nrow()
without_mfl <- total - with_mfl
# résumé de validation
cli::cli_h2("Intégration DHIS2-MFL terminée")
cli::cli_alert_success(
"Total des établissements DHIS2 conservés : {total}"
)
cli::cli_alert_info(
"Établissements avec données MFL : {with_mfl}"
)
cli::cli_alert_warning(
"Établissements sans correspondance MFL : {without_mfl}"
)
cli::cli_alert_info("Total des lignes (établissement-mois) : {nrow(final_dhis2_mfl_df)}")Pour adapter le code :
- Ligne 5 : Modifiez
hfpour correspondre à la colonne du nom de l’établissement DHIS2. - Ligne 17 : Ajustez les colonnes MFL à exclure (nous supprimons les colonnes géographiques pour éviter les conflits avec la géographie de DHIS2).
- Ligne 18 : Assurez-vous que
hf_mfl_rawcorrespond à la colonne du nom de l’établissement MFL issue des résultats de correspondance.
Afficher le code
# prendre DHIS2 comme base pour conserver toutes les lignes ;
# rattacher hf_uid_new
dhis2_df_final = dhis2_df.merge(
dhis2_map,
on=["adm0", "adm1", "adm2", "adm3", "hf"],
how="left",
)
# résultats de correspondance par établissement : utiliser hf_uid_new comme
# clé de jointure
final_match_per_hf = final_facilities_one_per_hf[["hf_uid_new", "hf_mfl_raw"]].copy()
# créer le jeu de données intégré
final_dhis2_mfl_df = (
dhis2_df_final
.merge(final_match_per_hf, on="hf_uid_new", how="left")
# joindre les attributs MFL pour les établissements avec correspondance
.merge(
master_hf_df.drop(
columns=["hf_mfl", "hf", "adm0", "adm1", "adm2", "adm3"],
errors="ignore",
),
on="hf_mfl_raw",
how="left",
)
)
# comptages sur les établissements distincts via hf_uid_new
total = dhis2_df_final["hf_uid_new"].nunique()
with_mfl = final_match_per_hf.dropna(subset=["hf_mfl_raw"])["hf_uid_new"].nunique()
without_mfl = total - with_mfl
# résumé de validation
cli_header("Intégration DHIS2-MFL terminée")
cli_success(f"Total des établissements DHIS2 conservés : {total}")
cli_info(f"Établissements avec données MFL : {with_mfl}")
cli_warning(f"Établissements sans correspondance MFL : {without_mfl}")
cli_info(f"Total des lignes (établissement-mois) : {len(final_dhis2_mfl_df)}")Pour adapter le code :
- Ligne 5 : Modifiez
hfpour correspondre à la colonne du nom de l’établissement DHIS2. - Lignes 19–22 : Ajustez les colonnes MFL à exclure (nous supprimons les colonnes géographiques pour éviter les conflits avec la géographie de DHIS2).
- Ligne 23 : Assurez-vous que
hf_mfl_rawcorrespond à la colonne du nom de l’établissement MFL issue des résultats de correspondance.
Étape 10 : Vérifications finales
Effectuez des contrôles qualité essentiels avant de finaliser le flux de travail de correspondance. Cette étape identifie les problèmes potentiels de qualité des données qui nécessitent une révision par l’équipe SNT : les correspondances un-à-plusieurs (qui peuvent indiquer des établissements en double ou des noms génériques) et les établissements sans correspondance (qui pourraient représenter de nouveaux établissements, des établissements fermés ou des problèmes de qualité des données). Ces vérifications garantissent la qualité des correspondances et créent des listes de révision exploitables pour l’équipe SNT.
Étape 10.1 : Détecter les correspondances un-à-plusieurs pour révision
Après la finalisation, vérifiez si des établissements MFL sont mis en correspondance avec plusieurs établissements DHIS2, ce qui peut indiquer des problèmes de qualité des données nécessitant une révision :
Afficher le code
# détecter les établissements MFL mis en correspondance avec plusieurs
# établissements DHIS2
one_to_many <- final_facilities_all |>
dplyr::filter(!is.na(hf_mfl_raw)) |> # uniquement les établissements avec correspondance
dplyr::group_by(hf_mfl_raw) |>
dplyr::filter(dplyr::n() > 1) |> # MFL mis en correspondance avec >1 DHIS2
dplyr::ungroup() |>
dplyr::arrange(hf_mfl_raw, hf_dhis2_raw)
if (nrow(one_to_many) > 0) {
cli::cli_alert_warning(
paste0(
"Correspondances un-à-plusieurs détectées : {nrow(one_to_many)} établissements DHIS2 ",
"partagent {dplyr::n_distinct(one_to_many$hf_mfl_raw)} établissements MFL"
)
)
# afficher un échantillon
knitr::kable(
one_to_many |>
dplyr::select(hf_dhis2_raw, hf_mfl_raw, score, final_method) |>
dplyr::slice_head(n = 6),
caption = "Échantillon de correspondances un-à-plusieurs nécessitant une révision"
)
} else {
cli::cli_alert_success("Aucune correspondance un-à-plusieurs détectée")
}Pour adapter le code :
- [Code supprimé] : Modifiez le chemin de sortie du fichier de révision si nécessaire (pas d’export de fichier dans ce chunk).
- Lignes 19–23 : Ajustez les colonnes à inclure dans le fichier de révision.
Afficher le code
# détecter les établissements MFL mis en correspondance avec plusieurs
# établissements DHIS2
one_to_many = (
final_facilities_all
.dropna(subset=["hf_mfl_raw"]) # uniquement les établissements avec correspondance
.groupby("hf_mfl_raw")
.filter(lambda g: len(g) > 1) # MFL mis en correspondance avec >1 DHIS2
.sort_values(["hf_mfl_raw", "hf_dhis2_raw"])
)
if len(one_to_many) > 0:
cli_warning(
f"Correspondances un-à-plusieurs détectées : {len(one_to_many)} établissements DHIS2 "
f"partagent {one_to_many['hf_mfl_raw'].nunique()} établissements MFL"
)
# afficher un échantillon
print(
one_to_many[["hf_dhis2_raw", "hf_mfl_raw", "score", "final_method"]]
.head(6)
.to_string(index=False)
)
else:
cli_success("Aucune correspondance un-à-plusieurs détectée")Pour adapter le code :
- Lignes 15–19 : Ajustez les colonnes à inclure dans la sortie de révision.
Les correspondances un-à-plusieurs signalent souvent des problèmes sous-jacents dans les données. Elles peuvent provenir d’enregistrements d’établissements en double ou quasi-identiques dans DHIS2, ou de noms génériques dans le MFL qui correspondent à plusieurs entrées DHIS2 plus spécifiques. Dans d’autres cas, elles reflètent des conventions de nommage incohérentes qui nécessitent une standardisation supplémentaire avant l’intégration.
Étape 10.2 : Analyse des établissements sans correspondance
Analysez les établissements qui restent sans correspondance afin d’identifier les raisons potentielles et de créer des listes de révision exploitables pour l’équipe SNT. Les établissements sans correspondance pourraient représenter de nouveaux établissements, des établissements fermés ou des établissements présentant des problèmes importants de qualité des données.
Afficher le code
# analyser les établissements sans correspondance par raison
unmatched_analysis <- final_facilities_all |>
dplyr::filter(is.na(hf_mfl_raw)) |>
dplyr::group_by(final_method) |>
dplyr::summarise(
count = n(),
.groups = "drop"
) |>
dplyr::arrange(desc(count))
# afficher l'analyse des établissements sans correspondance
cli::cli_h2("Analyse des établissements sans correspondance")
cli::cli_alert_info(
"Total des établissements sans correspondance : {sum(unmatched_analysis$count)}"
)
# afficher la répartition par raison
purrr::pwalk(
unmatched_analysis,
~ cli::cli_alert_warning("{.x}: {.y} facilities")
)
# créer un export détaillé des établissements sans correspondance
unmatched_detailed <- final_facilities_one_per_hf |>
# les établissements sans correspondance sont ceux sans lien MFL
dplyr::filter(is.na(hf_mfl_raw)) |>
# sélectionner le contexte requis et les champs de score/méthode
dplyr::select(
hf_dhis2_raw,
adm1,
adm2,
adm3,
final_method,
score
) |>
# dériver une raison potentielle claire pour la révision
dplyr::mutate(
potential_reason = dplyr::case_when(
is.na(final_method) ~ "Never matched - possible new facility",
final_method == "Manual Review - Rejected" ~
"Rejected in review - possible different facility",
score > 0 & score < 50 ~ "Low similarity - possible data quality issue",
TRUE ~ "Unmatched - needs investigation"
)
) |>
dplyr::arrange(adm1, adm2, adm3, hf_dhis2_raw)
# exporter pour révision par l'équipe SNT
readr::write_csv(
unmatched_detailed,
here::here("03_outputs", "unmatched_facilities_for_snt_review.csv")
)
cli::cli_alert_success(
"Exporté {nrow(unmatched_detailed)} établissements sans correspondance pour révision par l'équipe SNT"
)
cli::cli_text("File: outputs/unmatched_facilities_for_snt_review.csv")Pour adapter le code :
- Lignes 3–9 : L’analyse regroupe les établissements sans correspondance par raison (final_method). Personnalisez le regroupement selon les besoins.
- Lignes 23–46 : L’export détaillé inclut le contexte géographique et les raisons potentielles. Modifiez les colonnes selon les besoins.
- Lignes 49–52 : Le chemin d’export pour la révision par l’équipe SNT peut être personnalisé.
- Lignes 38–44 : La logique des raisons potentielles peut être ajustée selon les schémas spécifiques du flux de travail.
Afficher le code
# analyser les établissements sans correspondance par raison
unmatched_analysis = (
final_facilities_all
.loc[final_facilities_all["hf_mfl_raw"].isna()]
.groupby("final_method", as_index=False)
.size()
.rename(columns={"size": "count"})
.sort_values("count", ascending=False)
)
# afficher l'analyse des établissements sans correspondance
cli_header("Analyse des établissements sans correspondance")
cli_info(f"Total des établissements sans correspondance : {unmatched_analysis['count'].sum()}")
# afficher la répartition par raison
for _, row in unmatched_analysis.iterrows():
cli_warning(f"{row['final_method']}: {row['count']} facilities")
# créer un export détaillé des établissements sans correspondance
unmatched_detailed = (
final_facilities_one_per_hf
.loc[final_facilities_one_per_hf["hf_mfl_raw"].isna()]
[["hf_dhis2_raw", "adm1", "adm2", "adm3", "final_method", "score"]]
.assign(
potential_reason=lambda d: np.select(
[
d["final_method"].isna(),
d["final_method"] == "Manual Review - Rejected",
(d["score"] > 0) & (d["score"] < 50),
],
[
"Never matched - possible new facility",
"Rejected in review - possible different facility",
"Low similarity - possible data quality issue",
],
default="Unmatched - needs investigation",
)
)
.sort_values(["adm1", "adm2", "adm3", "hf_dhis2_raw"])
)
# exporter pour révision par l'équipe SNT
unmatched_export_dir = Path(here("03_outputs"))
unmatched_export_dir.mkdir(parents=True, exist_ok=True)
unmatched_detailed.to_csv(
unmatched_export_dir / "unmatched_facilities_for_snt_review.csv", index=False
)
cli_success(
f"Exporté {len(unmatched_detailed)} établissements sans correspondance pour révision par l'équipe SNT"
)
cli_info("File: outputs/unmatched_facilities_for_snt_review.csv")Pour adapter le code :
- Lignes 3–9 : L’analyse regroupe les établissements sans correspondance par raison (
final_method). Personnalisez le regroupement selon les besoins. - Lignes 22–37 : L’export détaillé inclut le contexte géographique et les raisons potentielles. Modifiez les colonnes selon les besoins.
- Lignes 41–43 : Le chemin d’export pour la révision par l’équipe SNT peut être personnalisé.
- Lignes 29–35 : La logique des raisons potentielles peut être ajustée selon les schémas spécifiques du flux de travail.
Cette vérification aide l’équipe SNT à concentrer sa révision sur les cas les plus importants. Certains établissements sans correspondance peuvent représenter de nouveaux sites à ajouter au MFL, tandis que d’autres signalent des problèmes de qualité des données où des variations de noms nécessitent une correction. Une partie peut correspondre à des établissements fermés qui doivent être marqués comme inactifs. Les résultats peuvent également mettre en évidence des schémas géographiques, montrant les zones où les établissements sans correspondance sont plus fréquents et peuvent nécessiter une révision ciblée.
Étape 11 : Sauvegarder les jeux de données finaux
Sauvegardez tous les jeux de données finaux pour l’analyse, les rapports et la révision par l’équipe SNT. Cette étape consolide toutes les opérations d’export et crée les sorties nécessaires pour les usages en aval.
Afficher le code
# sauvegarder le jeu de données intégré DHIS2-MFL principal
rio::export(
final_dhis2_mfl_df,
here::here("03_outputs", "final_dhis2_mfl_integrated.xlsx")
)
# sauvegarder le résumé des résultats de correspondance
rio::export(
final_facilities_all,
here::here("03_outputs", "facility_matching_results.xlsx")
)
if (nrow(unmatched_facilities) > 0) {
readr::write_csv(
unmatched_facilities,
here::here("03_outputs", "unmatched_dhis2_facilities.csv")
)
}
if (nrow(one_to_many) > 0) {
readr::write_csv(
one_to_many,
here::here("03_outputs", "one_to_many_matches_for_review.csv")
)
}
# résumé des fichiers sauvegardés
cli::cli_h2("Jeux de données finaux sauvegardés")
cli::cli_alert_success("Jeu de données intégré principal : final_dhis2_mfl_integrated.xlsx")
cli::cli_alert_success("Résultats de correspondance : facility_matching_results.xlsx")
cli::cli_alert_info("Établissements sans correspondance : {nrow(unmatched_facilities)} exportés")
cli::cli_alert_info("Correspondances un-à-plusieurs : {nrow(one_to_many)} exportées")Pour adapter le code :
- Lignes 3–7 : Le chemin du jeu de données intégré principal peut être personnalisé selon la structure du projet.
- Lignes 9–13 : Chemin d’export du résumé des résultats de correspondance.
- Lignes 14–19 : Export des établissements sans correspondance, modifiez le chemin si nécessaire.
- Lignes 21–26 : Export des correspondances un-à-plusieurs, détection et export automatiques.
- Lignes 29–33 : Les messages de résumé peuvent être personnalisés.
Afficher le code
# sauvegarder le jeu de données intégré DHIS2-MFL principal
output_dir = Path(here("03_outputs"))
output_dir.mkdir(parents=True, exist_ok=True)
final_dhis2_mfl_df.to_excel(
output_dir / "final_dhis2_mfl_integrated.xlsx", index=False
)
# sauvegarder le résumé des résultats de correspondance
final_facilities_all.to_excel(
output_dir / "facility_matching_results.xlsx", index=False
)
if len(unmatched_detailed) > 0:
unmatched_detailed.to_csv(
output_dir / "unmatched_dhis2_facilities.csv", index=False
)
if len(one_to_many) > 0:
one_to_many.to_csv(
output_dir / "one_to_many_matches_for_review.csv", index=False
)
# résumé des fichiers sauvegardés
cli_header("Jeux de données finaux sauvegardés")
cli_success("Jeu de données intégré principal : final_dhis2_mfl_integrated.xlsx")
cli_success("Résultats de correspondance : facility_matching_results.xlsx")
cli_info(f"Établissements sans correspondance : {len(unmatched_detailed)} exportés")
cli_info(f"Correspondances un-à-plusieurs : {len(one_to_many)} exportées")Pour adapter le code :
- Lignes 3–6 : Le chemin du jeu de données intégré principal peut être personnalisé selon la structure du projet.
- Lignes 8–10 : Chemin d’export du résumé des résultats de correspondance.
- Lignes 12–14 : Export des établissements sans correspondance, modifiez le chemin si nécessaire.
- Lignes 16–18 : Export des correspondances un-à-plusieurs, détection et export automatiques.
- Lignes 21–24 : Les messages de résumé peuvent être personnalisés.
Résumé
Ce guide présente une approche structurée pour mettre en correspondance les noms d’établissements de santé entre les jeux de données DHIS2 et la Liste principale des établissements (MFL). Il propose un flux de travail en deux étapes conçu pour l’efficacité et la précision. Les utilisateurs peuvent mettre en œuvre le flux de travail complet ou appliquer directement la correspondance floue si seule une similarité de chaînes de base est requise.
Étape 1 : Correspondance géographique stratifiée interactive utilise prep_geonames() (disponible sous sntutils::prep_geonames() en R et sntutils.geo.prep_geonames() en Python) pour combiner la validation humaine avec des contraintes géographiques. Elle résout généralement 60 à 70 % des correspondances avec une haute confiance, expose les établissements mal alignés tôt et offre des opportunités de révision immédiate des correspondances suggérées.
Étape 2 : Correspondance floue complète traite les établissements restants sans correspondance par le nettoyage et la standardisation des noms, en appliquant plusieurs algorithmes de similarité de chaînes (Jaro-Winkler, Levenshtein, Qgram, LCS), et en vérifiant la qualité structurelle. Cela permet de capturer les variations orthographiques, les abréviations et les décalages géographiques qui empêchent la correspondance exacte.
L’approche en deux étapes résout la plupart des correspondances via la correspondance géographique stratifiée, réduisant la révision manuelle et ne laissant que les cas difficiles pour la correspondance floue. Elle détecte les désalignements tôt, améliore la confiance grâce à la validation humaine et reste flexible pour une utilisation interactive et automatisée. En combinant plusieurs stratégies, l’approche atteint une large couverture tout en maintenant la qualité.
Pour les établissements qui nécessitent une correspondance floue, quatre stratégies sont disponibles : la correspondance par méthode unique, le score composite, les composites pondérés et les boucles de repli avec des seuils progressifs. Chacune est adaptée à des contextes de données et des besoins de confiance différents. La transparence et la comparabilité sont intégrées au processus, mais la validation avec l’équipe SNT reste essentielle pour les correspondances à faible confiance et les applications critiques.
Code complet
Retrouvez ci-dessous le script de code complet pour la correspondance floue des noms d’établissements de santé.
Show full code
################################################################################
## ~ Correspondance approximative des noms entre jeux de données full code ~ ###
################################################################################
### Step -----------------------------------------------------------------------
# vérifier si 'pacman' est installé ; l'installer s'il est absent
if (!requireNamespace("pacman", quietly = TRUE)) {
install.packages("pacman")
}
# charger tous les paquets requis avec pacman
pacman::p_load(
readxl, # pour lire les fichiers Excel
dplyr, # pour la manipulation des données
stringdist, # pour calculer les distances de chaînes (correspondance approximative)
tibble, # pour travailler avec des data frames modernes
knitr, # pour créer des tables formatées
openxlsx, # pour écrire des fichiers Excel
httr, # pour les requêtes HTTP afin de télécharger des fichiers (optionnel)
here # pour les chemins de fichiers multiplateforme
)
# configurer le chemin vers les données hf dhis2
dhis2_path <- here::here(
"01_data",
"1.2_epidemiology",
"1.2a_routine_surveillance",
"processed"
)
hf_path <- here::here(
"01_data",
"1.1_foundational",
"1.1c_health_facilities",
"processed"
)
# lire les données des établissements de santé DHIS2
dhis2_df <- readRDS(
here::here(dhis2_path, "sle_dhis2_with_clean_adm3.rds")
) |>
# renommer les colonnes de noms d'établissements pour la clarté et la cohérence
dplyr::rename(hf_dhis2_raw = hf)
# obtenir les colonnes admin et hf distinctes
dhis2_hf_df <- dhis2_df |>
dplyr::distinct(adm0, adm1, adm2, adm3, hf_dhis2_raw)
# lire les données des établissements de santé de la MFL
master_hf_df <- read.csv(
here::here(hf_path, "hf_final_clean_data.csv")
) |>
dplyr::distinct(
adm0, adm1, adm2, adm3, hf, lat, long, .keep_all = TRUE
) |>
# renommer les colonnes de noms d'établissements pour la clarté et la cohérence
dplyr::mutate(hf_mfl_raw = hf)
# attacher un identifiant stable d'établissement DHIS2 pour un comptage cohérent
# entre les étapes
# distinct par géographie + nom pour éviter les collisions entre admins
dhis2_map <- dhis2_df |>
dplyr::distinct(adm0, adm1, adm2, adm3, hf) |>
dplyr::mutate(
hf_uid_new = paste0(
"hf_uid_new::",
as.integer(as.factor(paste(
tolower(stringr::str_squish(adm0)),
tolower(stringr::str_squish(adm1)),
tolower(stringr::str_squish(adm2)),
tolower(stringr::str_squish(adm3)),
tolower(stringr::str_squish(hf)),
sep = "|"
)))
)
)
# afficher les premières lignes des données
cli::cli_h3("Sample of DHIS2 data:")
head(dhis2_hf_df)
cli::cli_h3("Sample of MFL data:")
head(master_hf_df)
# vérifier les correspondances exactes sur les noms bruts (sans contrainte admin)
exact_matches_all <- dhis2_hf_df |>
dplyr::inner_join(
master_hf_df,
by = c("hf_dhis2_raw" = "hf_mfl_raw"),
relationship = "many-to-many"
)
# calculer le potentiel de correspondance
total_dhis2 <- nrow(dhis2_hf_df)
total_mfl <- nrow(master_hf_df)
unmatched_dhis2 <- total_dhis2 - nrow(exact_matches_all)
cli::cli_h3("Résumé global des correspondances")
cli::cli_alert_info("Total des établissements DHIS2 : {total_dhis2}")
cli::cli_alert_info("Total des établissements MFL : {total_mfl}")
cli::cli_alert_success(
paste0(
"Correspondances exactes trouvées : {nrow(exact_matches_all)} (",
"{round(nrow(exact_matches_all)/total_dhis2*100, 1)}%)
)
)
cli::cli_alert_warning("Restant à faire correspondre : {unmatched_dhis2}")
# vérifier les correspondances au niveau adm2 (district)
dhis2_by_adm2 <- dhis2_hf_df |>
dplyr::group_by(adm2) |>
dplyr::summarise(total_dhis2 = dplyr::n())
matches_by_adm2 <- dhis2_hf_df |>
dplyr::inner_join(
master_hf_df,
by = c("hf_dhis2_raw" = "hf_mfl_raw", "adm2")
) |>
dplyr::group_by(adm2) |>
dplyr::summarise(exact_matches = dplyr::n()) |>
dplyr::left_join(dhis2_by_adm2, by = "adm2") |>
dplyr::mutate(
match_rate = round(exact_matches / total_dhis2 * 100, 1)
) |>
dplyr::select(adm2, exact_matches, total_dhis2, match_rate) |>
dplyr::arrange(dplyr::desc(match_rate))
cli::cli_h3("Correspondances exactes par district (adm2))
matches_by_adm2
# vérifier les correspondances au niveau adm3 (chefferie/sous-district)
dhis2_by_adm3 <- dhis2_hf_df |>
dplyr::group_by(adm2, adm3) |>
dplyr::summarise(total_dhis2 = dplyr::n(), .groups = "drop")
matches_by_adm3 <- dhis2_hf_df |>
dplyr::inner_join(
master_hf_df,
by = c("hf_dhis2_raw" = "hf_mfl_raw", "adm2", "adm3")
) |>
dplyr::group_by(adm2, adm3) |>
dplyr::summarise(exact_matches = dplyr::n(), .groups = "drop") |>
dplyr::left_join(dhis2_by_adm3, by = c("adm2", "adm3")) |>
dplyr::mutate(
match_rate = round(exact_matches / total_dhis2 * 100, 1)
) |>
dplyr::filter(total_dhis2 >= 5) |> # afficher seulement les zones avec 5+ établissements
dplyr::arrange(dplyr::desc(match_rate)) |>
dplyr::slice_head(n = 10) # afficher les 10 meilleures zones adm3
cli::cli_h3("Meilleures correspondances exactes par chefferie (adm3))
matches_by_adm3
# vérifier les doublons dans le même adm2 (problématique)
dhis2_dups_adm2 <- dhis2_hf_df |>
dplyr::group_by(adm2, hf_dhis2_raw) |>
dplyr::filter(dplyr::n() > 1) |>
dplyr::arrange(adm2, hf_dhis2_raw)
mfl_dups_adm2 <- master_hf_df |>
dplyr::group_by(adm2, hf_mfl_raw) |>
dplyr::filter(dplyr::n() > 1) |>
dplyr::arrange(adm2, hf_mfl_raw)
cli::cli_h3("Doublons dans le même district (adm2)")
cli::cli_alert_warning(
paste0(
"Doublons DHIS2 dans les districts : ",
"{length(unique(dhis2_dups_adm2$hf_dhis2_raw))}"
)
)
cli::cli_alert_warning(
paste0(
"Doublons MFL dans les districts : ",
"{length(unique(mfl_dups_adm2$hf_mfl_raw))}"
)
)
# vérifier les doublons dans le même adm3 (très problématique)
dhis2_dups_adm3 <- dhis2_hf_df |>
dplyr::group_by(adm2, adm3, hf_dhis2_raw) |>
dplyr::filter(dplyr::n() > 1) |>
dplyr::arrange(adm2, adm3, hf_dhis2_raw)
mfl_dups_adm3 <- master_hf_df |>
dplyr::group_by(adm2, adm3, hf_mfl_raw) |>
dplyr::filter(dplyr::n() > 1) |>
dplyr::arrange(adm2, adm3, hf_mfl_raw)
cli::cli_h3("Doublons dans la même chefferie (adm3)")
cli::cli_alert_danger(
paste0(
"Doublons DHIS2 dans les chefferies : ",
"{length(unique(dhis2_dups_adm3$hf_dhis2_raw))}"
)
)
cli::cli_alert_danger(
paste0(
"Doublons MFL dans les chefferies : ",
"{length(unique(mfl_dups_adm3$hf_mfl_raw))}"
)
)
# vérifier les doublons globaux (gérables avec le contexte géographique)
dhis2_dups_overall <- dhis2_hf_df |>
dplyr::group_by(hf_dhis2_raw) |>
dplyr::filter(dplyr::n() > 1) |>
dplyr::arrange(hf_dhis2_raw)
mfl_dups_overall <- master_hf_df |>
dplyr::group_by(hf_mfl_raw) |>
dplyr::filter(dplyr::n() > 1) |>
dplyr::arrange(hf_mfl_raw)
cli::cli_h3("Noms en double globaux (dans toutes les zones)")
cli::cli_alert_info(
"Doublons globaux DHIS2 : {length(
unique(dhis2_dups_overall$hf_dhis2_raw)
)}"
)
cli::cli_alert_info(
"Doublons globaux MFL : {length(
unique(mfl_dups_overall$hf_mfl_raw)
)}"
)
# jointure interne (conserver uniquement les polygones appariés)
# configurer l'emplacement de sauvegarde du cache
cache_loc <- "01_data/1.1_foundational/1.1f_cache_files/processed"
# correspondance stratifiée interactive avec standardisation automatique
# cette fonction gère la standardisation des noms en interne
dhis2_df_cleaned <-
sntutils::prep_geonames(
target_df = dhis2_hf_df, # jeu de données à nettoyer
lookup_df = master_hf_df, # jeu de données de référence avec les admins corrects
level0 = "adm0",
level1 = "adm1",
level2 = "adm2",
level3 = "adm3",
level4 = "hf",
cache_path = here::here(cache_loc, "geoname_cache.rds"),
unmatched_export_path = here::here(cache_loc, "dhis2_hf_unmatched.rds")
)
# charger les établissements non appariés pour traitement ultérieur (étapes 5–8
# correspondance approximative)
dhis2_hf_to_process <- readRDS(
here::here(cache_loc, "dhis2_hf_unmatched.rds")
) |>
dplyr::select(adm0, adm1, adm2, adm3, hf_dhis2_raw = hf)
# statistiques récapitulatives
n_original <- nrow(dhis2_hf_df)
n_matched <- n_original - nrow(dhis2_hf_to_process)
match_rate <- (n_matched / n_original) * 100
cli::cli_alert_success(
paste0(
"Correspondance stratifiée terminée : ",
"{format(n_matched, big.mark = ',')}/{format(n_original, big.mark = ',')}",
" établissements appariés ({round(match_rate, 1)}%)"
)
)
cli::cli_alert_info(
"Non appariés restants : {nrow(dhis2_hf_to_process)} établissements"
)
# créer une fonction pour standardiser les noms des structures sanitaires
standardize_names <- function(name_vec) {
# valider l'entrée
if (!rlang::is_atomic(name_vec)) {
cli::cli_abort("`name_vec` must be an atomic vector.")
}
name_vec |>
# s'assurer du type caractère
as.character() |>
# convertir en minuscules
stringr::str_to_lower() |>
# remplacer la ponctuation par un espace
stringr::str_replace_all("[[:punct:]]", " ") |>
# supprimer les espaces superflus et rogner
stringr::str_squish() |>
# normaliser les accents
stringi::stri_trans_general("Latin-ASCII") |>
# normaliser tous les caractères d'espace
stringi::stri_replace_all_regex("\\p{Zs}+", " ") |>
# convertir les chiffres romains en chiffres arabes
stringr::str_replace_all(
c(
" ix\\b" = " 9",
" viii\\b" = " 8",
" vii\\b" = " 7",
" vi\\b" = " 6",
" v\\b" = " 5",
" iv\\b" = " 4",
" iii\\b" = " 3",
" ii\\b" = " 2",
" i\\b" = " 1"
)
) |>
# trier les tokens : lettres en premier, chiffres en dernier ; tri
# alphabétique au sein de chaque groupe
purrr::map_chr(\(.x) {
# diviser sur un ou plusieurs espaces
tokens <- strsplit(.x, " +")[[1]]
# détecter les tokens purement numériques
is_num <- stringr::str_detect(tokens, "^[0-9]+$")
# ordonner les alphabétiques en premier, puis les numériques ; trier dans chaque groupe
ordered <- c(sort(tokens[!is_num]), sort(tokens[is_num]))
# rejoindre
paste(ordered, collapse = " ")
})
}
# préparer un exemple avec un formatage irrégulier
example_word <- factor("Clínica! Rahmâ IV ( New clinic) East")
# afficher la structure originale
cat("\nExample before standardization:\n")
str(example_word)
# appliquer la standardisation
example_word_st <- standardize_names(example_word)
# afficher l'exemple nettoyé
cat("\nExample after standardization:\n")
str(example_word_st)
# supprimer les doublons du MFL et formater la colonne des structures
master_hf_df <- master_hf_df |>
dplyr::distinct(hf_mfl_raw, .keep_all = TRUE) |>
dplyr::mutate(hf_mfl = standardize_names(hf_mfl_raw))
# important : conserver le jeu de données complet original avant de traiter
# les non-appariés (c'est notre N de base)
dhis2_hf_df_original <- dhis2_hf_df |>
dplyr::mutate(hf_dhis2 = standardize_names(hf_dhis2_raw))
# construire un identifiant stable géo-contextualisé et l'attacher aux originaux et aux non-appariés
hf_uid_new_map <- dhis2_hf_df |>
dplyr::distinct(adm0, adm1, adm2, adm3, hf_dhis2_raw) |>
dplyr::mutate(
hf_uid_new = paste0(
"hf_uid_new::",
as.integer(as.factor(paste(
tolower(stringr::str_squish(adm0)),
tolower(stringr::str_squish(adm1)),
tolower(stringr::str_squish(adm2)),
tolower(stringr::str_squish(adm3)),
tolower(stringr::str_squish(hf_dhis2_raw)),
sep = "|"
)))
)
)
dhis2_hf_df_original <- dhis2_hf_df_original |>
dplyr::left_join(
hf_uid_new_map,
by = c(
"adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw"
)
)
# traiter uniquement les structures non appariées pour les étapes de correspondance floue
dhis2_hf_unmatched <- dhis2_hf_to_process |>
dplyr::mutate(hf_dhis2 = standardize_names(hf_dhis2_raw)) |>
dplyr::left_join(
hf_uid_new_map |>
dplyr::mutate(hf_dhis2_raw = toupper(hf_dhis2_raw)),
by = c(
"adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw"
)
)
knitr::kable(
# vérifier si cela a fonctionné
dhis2_hf_unmatched |>
dplyr::distinct(hf_dhis2_raw, hf_dhis2) |>
dplyr::slice_head(n = 10)
)
abbrev_dictionary <-
dplyr::bind_rows(
dplyr::select(dhis2_hf_unmatched, hf = hf_dhis2_raw),
dplyr::select( master_hf_df, hf = hf_mfl_raw)) |>
# diviser en mots
tidyr::separate_rows(hf, sep = " ") |>
# supprimer les entrées vides
dplyr::filter(hf != "") |>
# détecter les motifs de 2 à 4 lettres majuscules
dplyr::filter(stringr::str_detect(hf, "^[A-Z]{2,4}$")) |>
# compter les fréquences
dplyr::count(hf, sort = TRUE) |>
# renommer pour plus de clarté
dplyr::rename(word = hf, freq = n) |>
dplyr::filter(freq > 2) |>
as.data.frame()
# vérifier la sortie
abbrev_dictionary
# définir le dictionnaire d'abréviations (tout en minuscules, car nous utilisons
# la colonne standardisée)
abbrev_dict <- c(
"maternal child health post" = "mchp",
"community health post" = "chp",
"community health center" = "chc",
"urban maternal clinic" = "umi",
"expanded programme on immunization" = "epi"
)
# appliquer les remplacements aux noms MFL
master_hf_df <- master_hf_df |>
dplyr::mutate(
hf_mfl = stringr::str_replace_all(hf_mfl, abbrev_dict)
)
# appliquer les remplacements aux noms DHIS2
dhis2_hf_unmatched <- dhis2_hf_unmatched |>
dplyr::mutate(
hf_dhis2 = stringr::str_replace_all(hf_dhis2, abbrev_dict)
)
# vérifier : démontrer la standardisation des abréviations
dhis2_hf_unmatched |>
dplyr::filter(
stringr::str_detect(
hf_dhis2_raw,
paste0(
"(?i)Community Health Center|Maternal Child Health Post|",
"Community Health Post"
)
) |
stringr::str_detect(hf_dhis2_raw, "CHC|MCHP|CHP")
) |>
dplyr::select(hf_dhis2_raw, hf_dhis2) |>
head()
# indicateur pour l'application de la règle un-à-un
enforce_one_to_one <- FALSE
# correspondances exactes utilisant les noms bruts
matched_dhis2_raw <- dhis2_hf_unmatched |>
dplyr::select(
adm0, adm1, adm2, adm3, hf_dhis2_raw, hf_uid_new
) |>
dplyr::inner_join(
master_hf_df |>
dplyr::select(hf_mfl_raw),
by = c("hf_dhis2_raw" = "hf_mfl_raw")
)
# correspondances exactes utilisant les noms standardisés
matched_dhis2 <- dhis2_hf_unmatched |>
dplyr::select(
adm0, adm1, adm2, adm3, hf_dhis2_raw, hf_dhis2, hf_uid_new
) |>
dplyr::inner_join(
master_hf_df |>
dplyr::select(hf_mfl_raw, hf_mfl),
by = c("hf_dhis2" = "hf_mfl"),
keep = TRUE
) |>
# exclure les structures déjà appariées via les noms bruts
dplyr::anti_join(matched_dhis2_raw, by = c("hf_dhis2_raw")) |>
# étiqueter les correspondances exactes
dplyr::mutate(
final_method = paste0(
"Matched Without Fuzzy Matching (standardization)"
),
score = 100
)
# inclure uniquement les structures réellement appariées via la
# standardisation géographique
# ce sont les structures ayant bénéficié de corrections géographiques
matched_dhis2_prepgeoname <-
dhis2_df_cleaned |>
dplyr::anti_join(
dhis2_hf_unmatched,
by = c("adm0", "adm1", "adm2", "adm3", "hf" = "hf_dhis2_raw")
) |>
dplyr::left_join(
master_hf_df |>
dplyr::mutate(hf = toupper(hf)) |>
dplyr::select(adm0, adm1, adm2, adm3, hf, hf_mfl_raw, hf_mfl),
by = c("adm0", "adm1", "adm2", "adm3", "hf")
) |>
# attacher hf_uid_new depuis dhis2_map (par admin + hf)
dplyr::left_join(
dhis2_map |> dplyr::select(adm0, adm1, adm2, adm3, hf, hf_uid_new),
by = c("adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw" = "hf")
) |>
# étiqueter les correspondances
dplyr::mutate(
final_method = "Interactive Stratified Geographic Matching",
score = 100
)
# calculer les non-appariés après standardisation
unmatched_dhis2 <- dhis2_hf_unmatched |>
dplyr::select(hf_dhis2) |>
dplyr::anti_join(
master_hf_df |>
dplyr::select(hf_mfl),
by = c("hf_dhis2" = "hf_mfl")
) |>
dplyr::distinct(hf_dhis2)
# collecter les MFL déjà appariés pour appliquer la règle un-à-un dans le pool de candidats
used_mfl_stand <- matched_dhis2 |>
dplyr::pull(hf_mfl) |>
unique()
use_mfl_prepgeoname <- matched_dhis2_prepgeoname |>
dplyr::pull(hf_mfl) |>
unique()
used_mfl <- c(used_mfl_stand, use_mfl_prepgeoname)
# construire le pool de candidats MFL pour l'étape de correspondance floue
candidate_mfl_df <- master_hf_df |>
dplyr::select(hf_mfl)
# si la règle un-à-un est appliquée, exclure les MFL déjà utilisés par les correspondances exactes
if (enforce_one_to_one) {
candidate_mfl_df <- candidate_mfl_df |>
dplyr::filter(!hf_mfl %in% used_mfl)
}
# comptages récapitulatifs
total_dhis2_hf <- dplyr::n_distinct(dhis2_hf_unmatched$hf_dhis2_raw)
raw_match_dhis2_hf <- dplyr::n_distinct(matched_dhis2_raw$hf_dhis2_raw)
raw_unmatch_dhis2_hf <- total_dhis2_hf - raw_match_dhis2_hf
standardized_match_dhis2_hf <- dplyr::n_distinct(matched_dhis2$hf_dhis2)
standardized_unmatch_dhis2_hf <- total_dhis2_hf - standardized_match_dhis2_hf
total_mfl_hf <- dplyr::n_distinct(master_hf_df$hf_mfl)
candidate_mfl_count <- dplyr::n_distinct(candidate_mfl_df$hf_mfl)
# afficher le récapitulatif
cli::cli_h2("Récapitulatif du statut de correspondance")
cli::cli_alert_info(
"Total des structures DHIS2 : {format(total_dhis2_hf, big.mark = ',')}"
)
cli::cli_alert_success(
paste0(
"Appariées après standardisation : ",
"{format(standardized_match_dhis2_hf, big.mark = ',')}"
)
)
cli::cli_alert_danger(
paste0(
"Non appariées avec les noms bruts : ",
"{format(raw_unmatch_dhis2_hf, big.mark = ',')}"
)
)
cli::cli_alert_danger(
paste0(
"Non appariées après standardisation : ",
"{format(standardized_unmatch_dhis2_hf, big.mark = ',')}"
)
)
cli::cli_alert_info(
paste0(
"Structures MFL dans le pool de candidats pour la correspondance : ",
"{format(candidate_mfl_count, big.mark = ',')} sur ",
"{format(total_mfl_hf, big.mark = ',')}"
)
)
# créer une grille de correspondance complète pour la correspondance floue en
# associant chaque structure DHIS2 non appariée à toutes les structures MFL disponibles.
# créer le pool de candidats simple
candidate_match_pool <- tidyr::crossing(
unmatched_dhis2,
candidate_mfl_df
)
# créer la grille de correspondance avec les noms DHIS2 et MFL
match_grid <- candidate_match_pool
# aperçu de l'échantillon - 10 premières correspondances
match_grid |>
dplyr::slice_head(n = 10)
# calculer les scores de correspondance floue
match_grid <- match_grid |>
dplyr::mutate(
len_max = pmax(nchar(hf_dhis2), nchar(hf_mfl)),
score_jw = 1 - stringdist::stringdist(hf_dhis2, hf_mfl, method = "jw"),
score_lv = 1 -
stringdist::stringdist(hf_dhis2, hf_mfl, method = "lv") / len_max,
score_qg = 1 -
stringdist::stringdist(hf_dhis2, hf_mfl, method = "qgram") / len_max,
score_lcs = 1 -
stringdist::stringdist(hf_dhis2, hf_mfl, method = "lcs") / len_max
) |>
dplyr::mutate(
dplyr::across(
.cols = dplyr::starts_with("score_"),
.fns = ~ ifelse(is.nan(.x) | .x < 0, 0, .x)
),
dplyr::across(
.cols = dplyr::contains("score_"),
.fns = ~ .x * 100
)
)
# définir les colonnes de scores de similarité
score_cols <- c("score_jw", "score_lv", "score_qg", "score_lcs")
# calculer composite_score dynamiquement en utilisant score_cols
match_grid <- match_grid |>
dplyr::mutate(
composite_score = rowMeans(
dplyr::across(dplyr::all_of(score_cols))
)
)
# calculer le rang moyen sur toutes les méthodes de similarité
ranked_grid <- match_grid |>
dplyr::group_by(hf_dhis2) |>
dplyr::mutate(
dplyr::across(
dplyr::all_of(score_cols),
~ dplyr::min_rank(dplyr::desc(.)),
.names = "rank_{.col}"
)
) |>
dplyr::ungroup() |>
dplyr::mutate(
rank_avg = rowSums(dplyr::across(
dplyr::all_of(paste0("rank_", score_cols))
)),
rank_avg = round(rank_avg / length(score_cols))
)
# aperçu des résultats classés pour montrer plusieurs candidats par structure DHIS2
# sélectionner quelques structures et afficher leurs 3 meilleurs candidats
sample_facilities <- c(
"charity clinic kamba of",
"arab clinic shad",
"al arab clinic sheefa"
)
ranked_grid |>
dplyr::filter(hf_dhis2 %in% sample_facilities) |>
dplyr::group_by(hf_dhis2) |>
dplyr::slice_min(rank_avg, n = 4, with_ties = FALSE) |>
dplyr::ungroup() |>
dplyr::select(
hf_dhis2,
hf_mfl,
dplyr::all_of(score_cols),
composite_score,
rank_avg
) |>
dplyr::arrange(hf_dhis2, rank_avg)
# pour chaque méthode de correspondance floue, sélectionner le nom MFL
# le mieux classé par structure DHIS2.
best_jw <- match_grid |>
dplyr::group_by(hf_dhis2) |>
dplyr::slice_max(score_jw, with_ties = FALSE) |>
dplyr::ungroup() |>
dplyr::mutate(method = "Jaro-Winkler") |>
dplyr::select(
hf_dhis2, hf_mfl, score = score_jw, method
)
best_lv <- match_grid |>
dplyr::group_by(hf_dhis2) |>
dplyr::slice_max(score_lv, with_ties = FALSE) |>
dplyr::ungroup() |>
dplyr::mutate(method = "Levenshtein") |>
dplyr::select(
hf_dhis2, hf_mfl, score = score_lv, method
)
best_qg <- match_grid |>
dplyr::group_by(hf_dhis2) |>
dplyr::slice_max(score_qg, with_ties = FALSE) |>
dplyr::ungroup() |>
dplyr::mutate(method = "Qgram") |>
dplyr::select(
hf_dhis2, hf_mfl, score = score_qg, method
)
best_lcs <- match_grid |>
dplyr::group_by(hf_dhis2) |>
dplyr::slice_max(score_lcs, with_ties = FALSE) |>
dplyr::ungroup() |>
dplyr::mutate(method = "LCS") |>
dplyr::select(
hf_dhis2, hf_mfl, score = score_lcs, method
)
best_comp<- match_grid |>
dplyr::group_by(hf_dhis2) |>
dplyr::slice_max(composite_score, with_ties = FALSE) |>
dplyr::ungroup() |>
dplyr::mutate(method = "Composite-Score") |>
dplyr::select(
hf_dhis2, hf_mfl, score = composite_score, method
)
best_ranked_match <- ranked_grid |>
dplyr::group_by(hf_dhis2) |>
dplyr::slice_min(rank_avg, with_ties = FALSE) |>
dplyr::ungroup() |>
dplyr::mutate(method = "Rank-Ensemble") |>
dplyr::select(
hf_dhis2, hf_mfl, score = rank_avg, method
)
# combiner les meilleures correspondances de toutes les méthodes pour comparaison
all_best <- dplyr::bind_rows(
best_jw, best_lv, best_qg, best_lcs,
best_comp, best_ranked_match)
# aperçu des meilleures correspondances pour afficher les résultats d'extraction
all_best |>
dplyr::slice_head(n = 10) |>
dplyr::select(hf_dhis2, hf_mfl, score, method)
# tracer la distribution des scores selon les méthodes
score_dist_plot <- all_best |>
dplyr::filter(method != "Rank-Ensemble") |>
ggplot2::ggplot(ggplot2::aes(x = score)) +
ggplot2::geom_density(fill = "steelblue", alpha = 0.6) +
ggplot2::facet_wrap(~method) +
ggplot2::geom_density(color = "steelblue", linewidth = 1) +
ggplot2::labs(
title = "Distribution of Fuzzy Matching Scores",
x = "\nMatch Score (%)",
y = "Density\n"
) +
ggplot2::theme_minimal(base_size = 14)
# sauvegarder le graphique
ggplot2::ggsave(
plot = score_dist_plot,
filename = here::here("03_output/3a_figures/u5mr_sle_adm2.png"),
width = 12,
height = 9,
dpi = 300
)
assess_match_quality <- function(name1, name2) {
purrr::map2_dfr(name1, name2, function(a, b) {
tokens1 <- strsplit(a, "\\s+")[[1]]
tokens2 <- strsplit(b, "\\s+")[[1]]
tibble::tibble(
prefix_match = tolower(tokens1[1]) == tolower(tokens2[1]),
suffix_match = tolower(tail(tokens1, 1)) == tolower(tail(tokens2, 1)),
token_diff = abs(length(tokens1) - length(tokens2)),
char_diff = abs(nchar(a) - nchar(b))
)
})
}
assess_match_quality("Makeni Govt Hospital", "Makeni Government Hospital")
# évaluer la qualité structurelle des correspondances
diagnostics_df <- dplyr::bind_cols(
all_best,
assess_match_quality(all_best$hf_dhis2, all_best$hf_mfl)
)
# comparer les diagnostics par méthode
summary_stats <- diagnostics_df |>
dplyr::group_by(method) |>
dplyr::summarise(
score = mean(score),
avg_token_diff = mean(token_diff) |> round(2),
avg_char_diff = mean(char_diff) |> round(2),
pct_prefix_match = (mean(prefix_match) * 100) |> round(2),
pct_suffix_match = (mean(suffix_match) * 100) |> round(2),
total = dplyr::n(),
.groups = "drop"
)
# créer un score global final
summary_stats <- summary_stats |>
dplyr::mutate(
# redimensionner le négatif de la différence moyenne de tokens (plus petit = meilleur)
token_score = scales::rescale(-avg_token_diff, to = c(0, 100)),
# redimensionner le négatif de la différence moyenne de caractères (plus petit = meilleur)
char_score = scales::rescale(-avg_char_diff, to = c(0, 100)),
# redimensionner le pourcentage de correspondance de préfixe (plus élevé = meilleur)
prefix_score = scales::rescale(pct_prefix_match, to = c(0, 100)),
# redimensionner le pourcentage de correspondance de suffixe (plus élevé = meilleur)
suffix_score = scales::rescale(pct_suffix_match, to = c(0, 100)),
# combiner les quatre métriques en un score de qualité structurelle pondéré
structure_score = round(
0.3 * token_score + # accentuer les faibles différences de tokens
0.2 * char_score + # poids modéré sur la similarité de caractères
0.25 * prefix_score + # pondérer les mots initiaux correspondants
0.25 * suffix_score, # pondérer également les mots finaux correspondants
1
)
) |>
dplyr::arrange(desc(structure_score)) |>
# attribuer un rang basé sur le score structurel décroissant
dplyr::mutate(rank = dplyr::row_number()) |>
dplyr::select(
method, avg_token_diff, avg_char_diff,
pct_prefix_match, pct_suffix_match,
total, structure_score, rank
)
# vérifier les résultats
summary_stats |>
dplyr::select(
Method = method,
`Avg. Token Difference` = avg_token_diff,
`Avg. Character Difference` = avg_char_diff,
`% Prefix Match` = pct_prefix_match,
`% Suffix Match` = pct_suffix_match,
`Structural Score` = structure_score,
Rank = rank
) |> as.data.frame()
# calculer les poids et seuils spécifiques à chaque méthode
method_threshold <- summary_stats |>
dplyr::mutate(
score = structure_score / 100,
weight = score / sum(score),
threshold = scales::rescale(
structure_score,
to = rev(unname(
stats::quantile(all_best$score, c(0.70, 0.95), na.rm = TRUE)
))
) |>
round()
) |>
dplyr::select(method, weight, threshold)
# afficher les résultats
method_threshold
# appliquer le seuil par méthode unique et signaler les correspondances
best_lv_final <- best_lv |>
dplyr::mutate(
match_flag = dplyr::if_else(score >= 85, "match", "review"),
final_method = "Levenshtein"
) |>
dplyr::left_join(
dplyr::select(master_hf_df, hf_mfl, hf_mfl_raw),
by = "hf_mfl"
) |>
dplyr::select(hf_dhis2, hf_mfl, hf_mfl_raw, score, final_method, match_flag)
# afficher les 5 meilleures et 5 pires correspondances par score
top_5 <- best_lv_final |>
dplyr::arrange(dplyr::desc(score)) |>
dplyr::slice_head(n = 5)
bottom_5 <- best_lv_final |>
dplyr::arrange(score) |>
dplyr::slice_head(n = 5)
# combiner en un seul tableau
top_bottom <- dplyr::bind_rows(top_5, bottom_5)
cli::cli_h3("5 premières et 5 dernières correspondances par score Levenshtein")
# aperçu des résultats
top_bottom
# sélectionner la meilleure correspondance en utilisant le rang moyen
composite_final <- ranked_grid |>
dplyr::group_by(hf_dhis2) |>
dplyr::arrange(rank_avg) |>
dplyr::slice_head(n = 1) |>
dplyr::ungroup() |>
dplyr::mutate(
match_flag = dplyr::if_else(composite_score >= 85, "match", "review")
) |>
dplyr::select(
adm1,
adm2,
hf_dhis2,
hf_mfl,
composite_score,
rank_avg,
match_flag
)
# afficher les 5 meilleures et 5 pires correspondances par score composite
top_5 <- composite_final |>
dplyr::arrange(dplyr::desc(score)) |>
dplyr::slice_head(n = 5)
bottom_5 <- composite_final |>
dplyr::arrange(score) |>
dplyr::slice_head(n = 5)
# combiner en un seul tableau
top_bottom <- dplyr::bind_rows(top_5, bottom_5)
cli::cli_h3("5 premiers et 5 derniers appariements par score composite")
# aperçu des résultats
top_bottom
# définir les colonnes de score et extraire les poids
score_cols <- c("score_jw", "score_lv", "score_qg", "score_lcs")
weights <- method_threshold |>
dplyr::filter(
method %in% c("Jaro-Winkler", "Levenshtein", "Qgram", "LCS")
) |>
dplyr::pull(weight)
# calculer le score composite pondéré pour chaque paire établissement-candidat
weighted_final <- ranked_grid |>
dplyr::rowwise() |>
dplyr::mutate(
# la moyenne pondérée maintient l'échelle 0-100
weighted_composite_score = stats::weighted.mean(
c(score_jw, score_lv, score_qg, score_lcs),
weights,
na.rm = TRUE
)
) |>
dplyr::ungroup() |>
dplyr::group_by(hf_dhis2) |>
dplyr::arrange(dplyr::desc(weighted_composite_score)) |>
dplyr::slice_head(n = 1) |>
dplyr::ungroup() |>
dplyr::mutate(
match_flag = dplyr::if_else(
weighted_composite_score >= 85,
"match",
"review"
),
score = weighted_composite_score, # standardize column name for Step 7
final_method = "Weighted-Composite"
) |>
dplyr::left_join(
dplyr::select(master_hf_df, hf_mfl, hf_mfl_raw),
by = "hf_mfl"
) |>
dplyr::select(
hf_dhis2,
hf_mfl,
hf_mfl_raw,
score,
final_method,
match_flag
)
# afficher les 5 meilleures et 5 pires correspondances par score composite pondéré
top_5 <- weighted_final |>
dplyr::arrange(dplyr::desc(score)) |>
dplyr::slice_head(n = 5)
bottom_5 <- weighted_final |>
dplyr::arrange(score) |>
dplyr::slice_head(n = 5)
cli::cli_h3("5 premiers et 5 derniers appariements par score composite pondéré")
# aperçu des résultats
bottom_5
# extraire l'ordre des méthodes et les seuils des résultats de l'étape 7.4
# classer les méthodes par score de structure (du plus élevé au plus bas)
method_stats <- summary_stats |>
dplyr::arrange(dplyr::desc(structure_score)) |>
dplyr::filter(method != "Rank-Ensemble") # exclure la méthode basée sur les rangs
method_order <- method_stats$method
# utiliser les seuils calculés à l'étape 7.4
method_thresholds_df <- method_threshold |>
dplyr::filter(method != "Rank-Ensemble")
# convertir en vecteur nommé pour une recherche rapide
method_thresholds <- setNames(
method_thresholds_df$threshold,
method_thresholds_df$method
)
# construire le tableau combiné des meilleures correspondances des méthodes réelles uniquement
all_best_nonrank <- dplyr::bind_rows(
best_lv,
best_jw,
best_qg,
best_lcs,
best_comp
) |>
# normaliser les étiquettes de méthode
dplyr::mutate(method = trimws(method))
# ajouter le rang une seule fois
rank_key <- ranked_grid |>
dplyr::select(hf_dhis2, hf_mfl, rank_avg)
all_best_ranked <- all_best_nonrank |>
dplyr::left_join(rank_key, by = c("hf_dhis2", "hf_mfl")) |>
dplyr::mutate(
# valeur la plus défavorable pour les rangs manquants
rank_avg = dplyr::if_else(is.na(rank_avg), Inf, rank_avg)
)
# diviser par méthode et pré-trier pour un départage stable
by_method <- split(all_best_ranked, all_best_ranked$method) |>
purrr::map(\(x) {
x |>
dplyr::arrange(dplyr::desc(score), rank_avg)
})
# conserver une copie pour la vérification du taux de passage
initial_thr <- method_thresholds
# initialisation
fallback_chunks <- list()
unmatched <- unique(all_best_ranked$hf_dhis2)
# boucle de repli rapide (sans jointures ni regroupements internes)
repeat {
for (m in method_order) {
if (!m %in% names(by_method)) {
next
}
# seuil courant de l'étape 7.4
thr <- method_thresholds[[m]]
if (is.null(thr)) {
thr <- 85 # repli si la méthode n'est pas trouvée
}
# filtrer par score et encore non apparié
cand <- by_method[[m]] |>
dplyr::filter(score >= thr, hf_dhis2 %in% unmatched)
if (nrow(cand) > 0) {
# sélectionner la première ligne par hf_dhis2 (pré-triée par score desc, rang asc)
best_per_hf <- cand |>
dplyr::distinct(hf_dhis2, .keep_all = TRUE) |>
dplyr::mutate(
final_method = glue::glue("Fuzzy-matched using: {m}")
)
# stocker et mettre à jour les non appariés
fallback_chunks[[length(fallback_chunks) + 1L]] <- best_per_hf
unmatched <- setdiff(unmatched, best_per_hf$hf_dhis2)
}
if (length(unmatched) == 0) break
}
if (length(unmatched) == 0) {
break
}
# relâcher progressivement les seuils
method_thresholds <- method_thresholds - 1
if (any(method_thresholds <= 50)) break # arrêter si trop bas
}
# combiner une seule fois
fallback_matched <- dplyr::bind_rows(fallback_chunks)
# construire une correspondance 1:1 depuis le nom DHIS2 standardisé vers admin + brut +
# hf_uid_new
hf_uid_new_map_by_stand <- dhis2_hf_unmatched |>
dplyr::arrange(adm0, adm1, adm2, adm3, hf_dhis2_raw) |>
dplyr::group_by(hf_dhis2) |>
dplyr::summarise(
adm0 = dplyr::first(adm0),
adm1 = dplyr::first(adm1),
adm2 = dplyr::first(adm2),
adm3 = dplyr::first(adm3),
hf_dhis2_raw = dplyr::first(hf_dhis2_raw),
hf_uid_new = dplyr::first(hf_uid_new),
.groups = "drop"
)
# indicateurs finaux et rattachement des unités administratives + identifiants
fallback_final <- fallback_matched |>
dplyr::mutate(
match_flag = dplyr::if_else(score >= 85, "match", "review")
) |>
dplyr::left_join(
dplyr::select(master_hf_df, hf_mfl, hf_mfl_raw),
by = "hf_mfl"
) |>
dplyr::left_join(hf_uid_new_map_by_stand, by = "hf_dhis2") |>
dplyr::select(
adm0, adm1, adm2, adm3,
hf_uid_new,
hf_dhis2_raw,
hf_dhis2,
hf_mfl_raw,
hf_mfl,
score,
final_method,
match_flag
)
top_5 <- fallback_final |>
dplyr::arrange(dplyr::desc(score)) |>
dplyr::slice_head(n = 5)
bottom_5 <- fallback_final |>
dplyr::arrange(score) |>
dplyr::slice_head(n = 5)
cli::cli_h3("5 premiers et 5 derniers appariements par repli")
bottom_5 <- dplyr::bind_rows(top_5, bottom_5)
# aperçu des résultats
bottom_5
# créer fuzzy_matches à partir des résultats de l'étape 8 (utiliser l'option choisie)
# l'étape 8 produit différents jeux de données selon l'option choisie :
# - option 1: best_lv_final, best_jw_final, etc.
# - option 2: composite_final
# - option 3: weighted_final
# - option 4: fallback_final
fuzzy_matches <- if (exists("fallback_final")) {
dplyr::filter(fallback_final, match_flag == "match")
} else if (exists("composite_final")) {
dplyr::filter(composite_final, match_flag == "match")
} else if (exists("weighted_final")) {
dplyr::filter(weighted_final, match_flag == "match")
} else if (exists("best_lv_final")) {
dplyr::filter(best_lv_final, match_flag == "match")
} else if (exists("best_jw_final")) {
dplyr::filter(best_jw_final, match_flag == "match")
} else if (exists("best_qg_final")) {
dplyr::filter(best_qg_final, match_flag == "match")
} else {
# dataframe vide avec la structure attendue si aucun résultat de l'étape 8 n'existe
data.frame(
hf_dhis2_raw = character(0),
hf_dhis2 = character(0),
hf_mfl_raw = character(0),
hf_mfl = character(0),
score = numeric(0),
final_method = character(0),
stringsAsFactors = FALSE
)
} |>
# supprimer les doublons internes (conserver la correspondance avec le score le plus élevé
# par établissement)
dplyr::group_by(hf_dhis2_raw) |>
dplyr::slice_max(score, n = 1, with_ties = FALSE) |>
dplyr::ungroup() |>
# rattacher admin + hf_uid_new depuis les non appariés (réduire à 1:1 par
# hf_dhis2_raw)
{
hf_uid_new_map_unmatched <- dhis2_hf_unmatched |>
dplyr::arrange(adm0, adm1, adm2, adm3, hf_dhis2_raw) |>
dplyr::group_by(hf_dhis2_raw) |>
dplyr::summarise(
adm0 = dplyr::first(adm0),
adm1 = dplyr::first(adm1),
adm2 = dplyr::first(adm2),
adm3 = dplyr::first(adm3),
hf_uid_new = dplyr::first(hf_uid_new),
.groups = "drop"
)
dplyr::left_join(., hf_uid_new_map_unmatched, by = "hf_dhis2_raw")
}
# afficher le récapitulatif de l'approche sélectionnée
cli::cli_h2("Résultats de l'appariement flou sélectionné")
cli::cli_alert_success("Correspondances floues trouvées : {nrow(fuzzy_matches)}")
if (nrow(fuzzy_matches) > 0) {
score_summary <- fuzzy_matches |>
dplyr::summarise(
avg_score = mean(score, na.rm = TRUE),
min_score = min(score, na.rm = TRUE),
max_score = max(score, na.rm = TRUE),
.groups = "drop"
)
cli::cli_alert_info("Plage de scores : {round(score_summary$min_score, 1)} - {round(score_summary$max_score, 1)}")
cli::cli_alert_info("Score moyen : {round(score_summary$avg_score, 1)}")
}
# préparer le jeu de données de révision (en utilisant les résultats de repli comme exemple)
review_matches <- fallback_final |>
dplyr::filter(match_flag == "review") |>
dplyr::arrange(dplyr::desc(score)) |>
dplyr::mutate(
reviewer_decision = NA_character_, # accept/reject/uncertain
reviewer_notes = NA_character_,
review_date = NA_character_,
reviewer_name = NA_character_
) |>
dplyr::select(
adm0, adm1, adm2, adm3, hf_uid_new,
hf_dhis2_raw,
hf_dhis2,
hf_mfl_raw,
hf_mfl,
score,
final_method,
reviewer_decision,
reviewer_notes,
review_date,
reviewer_name
)
# exporter pour révision
readr::write_csv(
review_matches,
here::here("03_outputs", "tables", "facility_matches_for_review.csv")
)
# afficher le récapitulatif
cli::cli_h2("Révision manuelle requise")
cli::cli_alert_info(
"Exporté {nrow(review_matches)} correspondances signalées pour révision"
)
cli::cli_alert_info(
"Emplacement du fichier : outputs/facility_matches_for_review.csv"
)
# simuler les décisions des réviseurs (remplacer par les données réellement révisées)
# relire les correspondances révisées
reviewed_matches <- readr::read_csv(
here::here("03_outputs", "tables", "facility_matches_reviewed.csv"),
col_types = readr::cols(
reviewer_decision = readr::col_character(),
reviewer_notes = readr::col_character(),
review_date = readr::col_character(),
reviewer_name = readr::col_character()
)
)
final_incorp <- reviewed_matches |>
dplyr::mutate(
final_match_flag = dplyr::case_when(
reviewer_decision == "accept" ~ "match",
reviewer_decision == "reject" ~ "no_match",
is.na(reviewer_decision) ~ "pending_review",
TRUE ~ "no_match"
)
)
# obtenir les correspondances finalement acceptées
final_matches <- final_incorp |>
dplyr::filter(final_match_flag == "match") |>
dplyr::select(-reviewer_decision)
# récapitulatif de tous les résultats (y compris rejetés/en attente)
all_results_summary <- final_incorp |>
dplyr::count(final_match_flag, name = "n") |>
dplyr::mutate(percentage = round(100 * n / sum(n), 1))
# récapitulatif des correspondances finalement acceptées uniquement
final_summary <- final_matches |>
dplyr::count(final_match_flag, name = "n")
cli::cli_h2("Résultats finaux de l'appariement après révision manuelle")
cli::cli_alert_success(
"Correspondances acceptées : {format(sum(final_summary$n), big.mark = ',')}"
)
# ventilation par type de décision
rejected_count <- all_results_summary |>
dplyr::filter(final_match_flag == "no_match") |>
dplyr::pull(n)
if (length(rejected_count) == 0) {
rejected_count <- 0
}
pending_count <- all_results_summary |>
dplyr::filter(final_match_flag == "pending_review") |>
dplyr::pull(n)
if (length(pending_count) == 0) {
pending_count <- 0
}
if (rejected_count > 0) {
cli::cli_alert_danger(
"Correspondances rejetées : {format(rejected_count, big.mark = ',')} (auront des valeurs NA dans les colonnes MFL du jeu de données final)"
)
}
if (pending_count > 0) {
cli::cli_alert_warning(
"En attente de révision : {format(pending_count, big.mark = ',')} (nécessitent une révision supplémentaire)"
)
}
# afficher le tableau de ventilation
all_results_summary
# créer manual_matches à partir des résultats de la révision manuelle
# (correspondances acceptées et rejetées)
manual_matches <- final_incorp |>
dplyr::mutate(
# pour les établissements sans correspondance, définir des valeurs appropriées
hf_mfl = dplyr::if_else(
reviewer_decision == "accept",
hf_mfl,
NA_character_
),
hf_mfl_raw = dplyr::if_else(
reviewer_decision == "accept",
hf_mfl_raw,
NA_character_
),
final_method = dplyr::if_else(
reviewer_decision == "accept",
"Manual Review - Accepted",
"Manual Review - Rejected"
),
score = dplyr::if_else(
reviewer_decision == "accept",
100,
0
)
) |>
# les résultats révisés manuellement portent déjà adm0-3 + hf_uid_new
# depuis fallback_final → export révision → réimportation
dplyr::select(
adm0,
adm1,
adm2,
adm3,
hf_uid_new,
hf_dhis2_raw,
hf_dhis2,
hf_mfl_raw,
hf_mfl,
score,
final_method
)
# combiner les résultats de toutes les approches de correspondance
# ce jeu de données contient TOUS les établissements : avec correspondance,
# sans correspondance et rejetés
final_facilities_all <- dplyr::bind_rows(
# étape 4 : correspondances géographiques stratifiées (si effectuées)
matched_dhis2_prepgeoname,
# étape 5 : correspondances exactes après standardisation
matched_dhis2,
# étapes 6-8 : correspondances complètes issues de la correspondance floue
fuzzy_matches,
# correspondance manuelle (si effectuée)
manual_matches
)
# sauvegarder pour le chargement par l'état de rendu python (parité règle 6.4)
write.csv(
final_facilities_all,
here::here("01_data/1.1_foundational/1.1c_health_facilities/processed/final_facilities_all.csv"),
row.names = FALSE
)
# réduire à un enregistrement par établissement DHIS2 pour l'intégration aval
final_facilities_one_per_hf <- final_facilities_all |>
dplyr::select(-match_flag, -hf)
cli::cli_alert_info(
"Tous les établissements traités (lignes) : {nrow(final_facilities_all)}"
)
cli::cli_alert_success(
"Tous les établissements traités (DHIS2 distincts par adm0/1/2/3+hf) : {dplyr::n_distinct(final_facilities_all$hf_uid_new)}"
)
# générer un résumé par méthode de correspondance
matching_summary <- final_facilities_one_per_hf |>
dplyr::group_by(final_method) |>
dplyr::summarise(
n_matched = n(),
avg_score = mean(score, na.rm = TRUE),
min_score = min(score, na.rm = TRUE),
max_score = max(score, na.rm = TRUE),
.groups = "drop"
)
# afficher le résumé
cli::cli_h2("Résultats de correspondance par méthode")
matching_summary
# prendre DHIS2 comme base pour conserver toutes les lignes ;
# rattacher hf_uid_new
dhis2_df_final <- dhis2_df |>
dplyr::left_join(
dhis2_map,
by = c("adm0", "adm1", "adm2", "adm3", "hf")
)
# résultats de correspondance par établissement : utiliser hf_uid_new comme
# clé de jointure
final_match_per_hf <- final_facilities_one_per_hf |>
dplyr::select(hf_uid_new, hf_mfl_raw)
# créer le jeu de données intégré
final_dhis2_mfl_df <- dhis2_df_final |>
dplyr::left_join(final_match_per_hf, by = "hf_uid_new") |>
# joindre les attributs MFL pour les établissements avec correspondance
dplyr::left_join(
dplyr::select(master_hf_df, -hf_mfl, -hf, -adm0, -adm1, -adm2, -adm3),
by = "hf_mfl_raw"
)
# comptages sur les établissements distincts via hf_uid_new (robuste aux
# doublons au niveau des lignes)
total <- dhis2_df_final |> dplyr::distinct(hf_uid_new) |> nrow()
with_mfl <- final_match_per_hf |>
dplyr::filter(!is.na(hf_mfl_raw)) |>
nrow()
without_mfl <- total - with_mfl
# résumé de validation
cli::cli_h2("Intégration DHIS2-MFL terminée")
cli::cli_alert_success(
"Total des établissements DHIS2 conservés : {total}"
)
cli::cli_alert_info(
"Établissements avec données MFL : {with_mfl}"
)
cli::cli_alert_warning(
"Établissements sans correspondance MFL : {without_mfl}"
)
cli::cli_alert_info("Total des lignes (établissement-mois) : {nrow(final_dhis2_mfl_df)}")
# détecter les établissements MFL mis en correspondance avec plusieurs
# établissements DHIS2
one_to_many <- final_facilities_all |>
dplyr::filter(!is.na(hf_mfl_raw)) |> # uniquement les établissements avec correspondance
dplyr::group_by(hf_mfl_raw) |>
dplyr::filter(dplyr::n() > 1) |> # MFL mis en correspondance avec >1 DHIS2
dplyr::ungroup() |>
dplyr::arrange(hf_mfl_raw, hf_dhis2_raw)
if (nrow(one_to_many) > 0) {
cli::cli_alert_warning(
paste0(
"Correspondances un-à-plusieurs détectées : {nrow(one_to_many)} établissements DHIS2 ",
"partagent {dplyr::n_distinct(one_to_many$hf_mfl_raw)} établissements MFL"
)
)
# afficher un échantillon
knitr::kable(
one_to_many |>
dplyr::select(hf_dhis2_raw, hf_mfl_raw, score, final_method) |>
dplyr::slice_head(n = 6),
caption = "Échantillon de correspondances un-à-plusieurs nécessitant une révision"
)
} else {
cli::cli_alert_success("Aucune correspondance un-à-plusieurs détectée")
}
# analyser les établissements sans correspondance par raison
unmatched_analysis <- final_facilities_all |>
dplyr::filter(is.na(hf_mfl_raw)) |>
dplyr::group_by(final_method) |>
dplyr::summarise(
count = n(),
.groups = "drop"
) |>
dplyr::arrange(desc(count))
# afficher l'analyse des établissements sans correspondance
cli::cli_h2("Analyse des établissements sans correspondance")
cli::cli_alert_info(
"Total des établissements sans correspondance : {sum(unmatched_analysis$count)}"
)
# afficher la répartition par raison
purrr::pwalk(
unmatched_analysis,
~ cli::cli_alert_warning("{.x}: {.y} facilities")
)
# créer un export détaillé des établissements sans correspondance
unmatched_detailed <- final_facilities_one_per_hf |>
# les établissements sans correspondance sont ceux sans lien MFL
dplyr::filter(is.na(hf_mfl_raw)) |>
# sélectionner le contexte requis et les champs de score/méthode
dplyr::select(
hf_dhis2_raw,
adm1,
adm2,
adm3,
final_method,
score
) |>
# dériver une raison potentielle claire pour la révision
dplyr::mutate(
potential_reason = dplyr::case_when(
is.na(final_method) ~ "Never matched - possible new facility",
final_method == "Manual Review - Rejected" ~
"Rejected in review - possible different facility",
score > 0 & score < 50 ~ "Low similarity - possible data quality issue",
TRUE ~ "Unmatched - needs investigation"
)
) |>
dplyr::arrange(adm1, adm2, adm3, hf_dhis2_raw)
# exporter pour révision par l'équipe SNT
readr::write_csv(
unmatched_detailed,
here::here("03_outputs", "unmatched_facilities_for_snt_review.csv")
)
cli::cli_alert_success(
"Exporté {nrow(unmatched_detailed)} établissements sans correspondance pour révision par l'équipe SNT"
)
cli::cli_text("File: outputs/unmatched_facilities_for_snt_review.csv")
# sauvegarder le jeu de données intégré DHIS2-MFL principal
rio::export(
final_dhis2_mfl_df,
here::here("03_outputs", "final_dhis2_mfl_integrated.xlsx")
)
# sauvegarder le résumé des résultats de correspondance
rio::export(
final_facilities_all,
here::here("03_outputs", "facility_matching_results.xlsx")
)
if (nrow(unmatched_facilities) > 0) {
readr::write_csv(
unmatched_facilities,
here::here("03_outputs", "unmatched_dhis2_facilities.csv")
)
}
if (nrow(one_to_many) > 0) {
readr::write_csv(
one_to_many,
here::here("03_outputs", "one_to_many_matches_for_review.csv")
)
}
# résumé des fichiers sauvegardés
cli::cli_h2("Jeux de données finaux sauvegardés")
cli::cli_alert_success("Jeu de données intégré principal : final_dhis2_mfl_integrated.xlsx")
cli::cli_alert_success("Résultats de correspondance : facility_matching_results.xlsx")
cli::cli_alert_info("Établissements sans correspondance : {nrow(unmatched_facilities)} exportés")
cli::cli_alert_info("Correspondances un-à-plusieurs : {nrow(one_to_many)} exportées")Show full code
################################################################################
## ~ Correspondance approximative des noms entre jeux de données full code ~ ###
################################################################################
### Step -----------------------------------------------------------------------
from pathlib import Path
import re
import unicodedata
import numpy as np
import pandas as pd
import pyreadr
import matplotlib.pyplot as plt
from pyprojroot import here
from rapidfuzz.distance import Levenshtein, JaroWinkler
from rapidfuzz import fuzz
def read_rds(path):
"""Read a single-object RDS file as a pandas DataFrame."""
result = pyreadr.read_r(str(path))
return next(iter(result.values()))
def cli_header(message):
print(f"\n{message}")
def cli_info(message):
print(f"INFO: {message}")
def cli_success(message):
print(f"SUCCESS: {message}")
def cli_warning(message):
print(f"WARNING: {message}")
def cli_danger(message):
print(f"ERROR: {message}")
def anti_join(left, right, on):
"""Return rows in left with no matching key in right."""
right_keys = right[on].drop_duplicates()
return (
left.merge(right_keys, on=on, how="left", indicator=True)
.loc[lambda x: x["_merge"] == "left_only"]
.drop(columns="_merge")
)
def show_table(df, n=10, caption=None):
"""Render a compact scrollable HTML table with the .out-table style.
Chunks calling this must set #| results: asis."""
from IPython.display import display, HTML
rows = df.head(n)
cap_html = f"<caption>{caption}</caption>" if caption else ""
table_html = rows.to_html(
index=False,
classes="out-table",
border=0,
na_rep="",
)
# inject caption before the table header
if cap_html:
table_html = table_html.replace(
"<thead>", cap_html + "<thead>", 1
)
display(HTML(f'<div class="out-scroll">{table_html}</div>'))
# configurer le chemin vers les données hf dhis2
dhis2_path = Path(here("01_data/1.2_epidemiology/1.2a_routine_surveillance/processed"))
hf_path = Path(here("01_data/1.1_foundational/1.1c_health_facilities/processed"))
# lire les données des établissements de santé DHIS2
dhis2_df = read_rds(dhis2_path / "sle_dhis2_with_clean_adm3.rds")
dhis2_df = dhis2_df.assign(hf_dhis2_raw=dhis2_df["hf"])
# obtenir les colonnes admin et hf distinctes
dhis2_hf_df = dhis2_df[
["adm0", "adm1", "adm2", "adm3", "hf", "hf_dhis2_raw"]
].drop_duplicates()
# lire les données des établissements de santé de la MFL
master_hf_df = pd.read_csv(hf_path / "hf_final_clean_data.csv")
master_hf_df = (
master_hf_df
.drop_duplicates(subset=["adm0", "adm1", "adm2", "adm3", "hf", "lat", "long"])
.assign(hf_mfl_raw=lambda d: d["hf"])
)
# attacher un identifiant stable d'établissement DHIS2
dhis2_map = (
dhis2_df[["adm0", "adm1", "adm2", "adm3", "hf"]]
.drop_duplicates()
.assign(
hf_uid_new=lambda d: "hf_uid_new::" + (
d["adm0"].str.lower().str.strip() + "|" +
d["adm1"].str.lower().str.strip() + "|" +
d["adm2"].str.lower().str.strip() + "|" +
d["adm3"].str.lower().str.strip() + "|" +
d["hf"].str.lower().str.strip()
).astype("category").cat.codes.astype(str)
)
)
# afficher les premières lignes des données
cli_header("Sample of DHIS2 data:")
dhis2_hf_df.head()
cli_header("Sample of MFL data:")
master_hf_df.head()
# vérifier les correspondances exactes sur les noms bruts (sans contrainte admin)
exact_matches_all = dhis2_hf_df.merge(
master_hf_df[["hf_mfl_raw"]],
left_on="hf_dhis2_raw",
right_on="hf_mfl_raw",
how="inner",
)
# calculer le potentiel de correspondance
total_dhis2 = len(dhis2_hf_df)
total_mfl = len(master_hf_df)
unmatched_dhis2 = total_dhis2 - len(exact_matches_all)
cli_header("Résumé global des correspondances")
cli_info(f"Total des établissements DHIS2 : {total_dhis2}")
cli_info(f"Total des établissements MFL : {total_mfl}")
cli_success(
f"Correspondances exactes trouvées : {len(exact_matches_all)} "
f"({round(len(exact_matches_all) / total_dhis2 * 100, 1)}%)"
)
cli_warning(f"Restant à faire correspondre : {unmatched_dhis2}")
# vérifier les correspondances au niveau adm2 (district)
dhis2_by_adm2 = (
dhis2_hf_df.groupby("adm2", as_index=False)
.agg(total_dhis2=("hf_dhis2_raw", "count"))
)
matches_by_adm2 = (
dhis2_hf_df
.merge(
master_hf_df[["hf_mfl_raw", "adm2"]],
left_on=["hf_dhis2_raw", "adm2"],
right_on=["hf_mfl_raw", "adm2"],
how="inner",
)
.groupby("adm2", as_index=False)
.agg(exact_matches=("hf_dhis2_raw", "count"))
.merge(dhis2_by_adm2, on="adm2", how="left")
.assign(match_rate=lambda d: (d["exact_matches"] / d["total_dhis2"] * 100).round(1))
[["adm2", "exact_matches", "total_dhis2", "match_rate"]]
.sort_values("match_rate", ascending=False)
)
cli_header("Correspondances exactes par district (adm2)")
matches_by_adm2
# vérifier les correspondances au niveau adm3 (chefferie/sous-district)
dhis2_by_adm3 = (
dhis2_hf_df.groupby(["adm2", "adm3"], as_index=False)
.agg(total_dhis2=("hf_dhis2_raw", "count"))
)
matches_by_adm3 = (
dhis2_hf_df
.merge(
master_hf_df[["hf_mfl_raw", "adm2", "adm3"]],
left_on=["hf_dhis2_raw", "adm2", "adm3"],
right_on=["hf_mfl_raw", "adm2", "adm3"],
how="inner",
)
.groupby(["adm2", "adm3"], as_index=False)
.agg(exact_matches=("hf_dhis2_raw", "count"))
.merge(dhis2_by_adm3, on=["adm2", "adm3"], how="left")
.assign(match_rate=lambda d: (d["exact_matches"] / d["total_dhis2"] * 100).round(1))
.loc[lambda d: d["total_dhis2"] >= 5]
.sort_values("match_rate", ascending=False)
.head(10)
)
cli_header("Meilleures correspondances exactes par chefferie (adm3)")
matches_by_adm3
# vérifier les doublons dans le même adm2 (problématique)
dhis2_dups_adm2 = (
dhis2_hf_df
.groupby(["adm2", "hf_dhis2_raw"])
.filter(lambda x: len(x) > 1)
.sort_values(["adm2", "hf_dhis2_raw"])
)
mfl_dups_adm2 = (
master_hf_df
.groupby(["adm2", "hf_mfl_raw"])
.filter(lambda x: len(x) > 1)
.sort_values(["adm2", "hf_mfl_raw"])
)
cli_header("Doublons dans le même district (adm2)")
cli_warning(
f"Doublons DHIS2 dans les districts : {dhis2_dups_adm2['hf_dhis2_raw'].nunique()}"
)
cli_warning(
f"Doublons MFL dans les districts : {mfl_dups_adm2['hf_mfl_raw'].nunique()}"
)
# vérifier les doublons dans le même adm3 (très problématique)
dhis2_dups_adm3 = (
dhis2_hf_df
.groupby(["adm2", "adm3", "hf_dhis2_raw"])
.filter(lambda x: len(x) > 1)
.sort_values(["adm2", "adm3", "hf_dhis2_raw"])
)
mfl_dups_adm3 = (
master_hf_df
.groupby(["adm2", "adm3", "hf_mfl_raw"])
.filter(lambda x: len(x) > 1)
.sort_values(["adm2", "adm3", "hf_mfl_raw"])
)
cli_header("Doublons dans la même chefferie (adm3)")
cli_danger(
f"Doublons DHIS2 dans les chefferies : {dhis2_dups_adm3['hf_dhis2_raw'].nunique()}"
)
cli_danger(
f"Doublons MFL dans les chefferies : {mfl_dups_adm3['hf_mfl_raw'].nunique()}"
)
# vérifier les doublons globaux (gérables avec le contexte géographique)
dhis2_dups_overall = (
dhis2_hf_df
.groupby("hf_dhis2_raw")
.filter(lambda x: len(x) > 1)
.sort_values("hf_dhis2_raw")
)
mfl_dups_overall = (
master_hf_df
.groupby("hf_mfl_raw")
.filter(lambda x: len(x) > 1)
.sort_values("hf_mfl_raw")
)
cli_header("Noms en double globaux (dans toutes les zones)")
cli_info(f"Doublons globaux DHIS2 : {dhis2_dups_overall['hf_dhis2_raw'].nunique()}")
cli_info(f"Doublons globaux MFL : {mfl_dups_overall['hf_mfl_raw'].nunique()}")
from sntutils.geo import prep_geonames
# configurer l'emplacement de sauvegarde du cache
cache_loc = "01_data/1.1_foundational/1.1f_cache_files/processed"
# correspondance stratifiée interactive avec standardisation automatique
dhis2_df_cleaned = prep_geonames(
target_df=dhis2_hf_df,
lookup_df=master_hf_df,
level0="adm0",
level1="adm1",
level2="adm2",
level3="adm3",
level4="hf",
cache_path=here(cache_loc, "geoname_cache.csv"),
unmatched_export_path=here(cache_loc, "dhis2_hf_unmatched.csv"),
)
# charger les établissements non appariés pour traitement ultérieur (étapes 5–8)
dhis2_hf_to_process = pd.read_csv(
here(cache_loc, "dhis2_hf_unmatched.csv")
).rename(columns={"hf": "hf_dhis2_raw"})
# statistiques récapitulatives
n_original = len(dhis2_hf_df)
n_matched = n_original - len(dhis2_hf_to_process)
match_rate = n_matched / n_original * 100
cli_success(
f"Correspondance stratifiée terminée : {n_matched:,}/{n_original:,} "
f"établissements appariés ({round(match_rate, 1)}%)"
)
cli_info(f"Non appariés restants : {len(dhis2_hf_to_process)} établissements")
import unicodedata
def standardize_names(series):
"""Standardize health facility name strings for fuzzy matching.
Applies lowercase conversion, punctuation removal, accent normalization,
Roman numeral conversion, and alphabetical token sorting.
"""
roman_map = {
r"\bix\b": "9", r"\bviii\b": "8", r"\bvii\b": "7",
r"\bvi\b": "6", r"\bv\b": "5", r"\biv\b": "4",
r"\biii\b": "3", r"\bii\b": "2", r"\bi\b": "1",
}
def _clean(text):
if pd.isna(text):
return text
text = str(text).lower()
# remplacer la ponctuation par un espace
text = re.sub(r"[^\w\s]", " ", text)
# réduire les espaces multiples
text = re.sub(r"\s+", " ", text).strip()
# normaliser les accents
text = unicodedata.normalize("NFD", text)
text = "".join(c for c in text if unicodedata.category(c) != "Mn")
# convertir les chiffres romains
for pattern, replacement in roman_map.items():
text = re.sub(pattern, replacement, text)
# trier les tokens : lettres en premier (alphabétique), chiffres en dernier
tokens = text.split()
alpha = sorted(t for t in tokens if not t.isdigit())
numeric = sorted(t for t in tokens if t.isdigit())
return " ".join(alpha + numeric)
return series.apply(_clean)
# préparer un exemple avec un formatage irrégulier
example_word = "Clínica! Rahmâ IV ( New clinic) East"
# afficher l'original
print(f"\nExample before standardization:\n{example_word}")
# appliquer la standardisation
example_word_st = standardize_names(pd.Series([example_word]))[0]
# afficher l'exemple nettoyé
print(f"\nExample after standardization:\n{example_word_st}")
# supprimer les doublons du MFL et créer la colonne standardisée
master_hf_df = (
master_hf_df
.drop_duplicates(subset="hf_mfl_raw")
.assign(hf_mfl=lambda d: standardize_names(d["hf_mfl_raw"]))
)
# conserver le jeu de données complet original avant de traiter les non-appariés
dhis2_hf_df_original = dhis2_hf_df.assign(
hf_dhis2=lambda d: standardize_names(d["hf_dhis2_raw"])
)
# construire la table de correspondance des identifiants géo-contextualisés
hf_uid_new_map = (
dhis2_hf_df[["adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw"]]
.drop_duplicates()
.assign(
hf_uid_new=lambda d: "hf_uid_new::" + (
d["adm0"].str.lower().str.strip() + "|" +
d["adm1"].str.lower().str.strip() + "|" +
d["adm2"].str.lower().str.strip() + "|" +
d["adm3"].str.lower().str.strip() + "|" +
d["hf_dhis2_raw"].str.lower().str.strip()
).astype("category").cat.codes.astype(str)
)
)
dhis2_hf_df_original = dhis2_hf_df_original.merge(
hf_uid_new_map,
on=["adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw"],
how="left",
)
# traiter uniquement les structures non appariées pour les étapes de correspondance floue
dhis2_hf_unmatched = (
dhis2_hf_to_process
.assign(hf_dhis2=lambda d: standardize_names(d["hf_dhis2_raw"]))
.merge(
hf_uid_new_map.assign(
hf_dhis2_raw=lambda d: d["hf_dhis2_raw"].str.upper()
),
on=["adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw"],
how="left",
)
)
# vérifier si la standardisation a fonctionné
dhis2_hf_unmatched[["hf_dhis2_raw", "hf_dhis2"]].drop_duplicates().head(10)
# combiner les noms DHIS2 et MFL pour la détection des abréviations
all_names = pd.concat([
dhis2_hf_unmatched[["hf_dhis2_raw"]].rename(columns={"hf_dhis2_raw": "hf"}),
master_hf_df[["hf_mfl_raw"]].rename(columns={"hf_mfl_raw": "hf"}),
])
# diviser en mots et filtrer les tokens de 2 à 4 lettres majuscules
abbrev_dictionary = (
all_names["hf"]
.dropna()
.str.split(expand=True)
.stack()
.reset_index(drop=True)
.rename("word")
.loc[lambda s: s.str.match(r"^[A-Z]{2,4}$")]
.value_counts()
.reset_index()
.rename(columns={"count": "freq"})
.loc[lambda d: d["freq"] > 2]
)
# vérifier la sortie
abbrev_dictionary
# définir le dictionnaire d'abréviations (tout en minuscules, en utilisant la colonne standardisée)
abbrev_dict = {
"maternal child health post": "mchp",
"community health post": "chp",
"community health center": "chc",
"urban maternal clinic": "umi",
"expanded programme on immunization": "epi",
}
# appliquer les remplacements aux noms MFL
for long_form, short_form in abbrev_dict.items():
master_hf_df["hf_mfl"] = master_hf_df["hf_mfl"].str.replace(
long_form, short_form, regex=False
)
# appliquer les remplacements aux noms DHIS2
for long_form, short_form in abbrev_dict.items():
dhis2_hf_unmatched["hf_dhis2"] = dhis2_hf_unmatched["hf_dhis2"].str.replace(
long_form, short_form, regex=False
)
# vérifier : démontrer la standardisation des abréviations
dhis2_hf_unmatched.loc[
dhis2_hf_unmatched["hf_dhis2_raw"].str.contains(
r"(?i)Community Health Center|Maternal Child Health Post|Community Health Post|CHC|MCHP|CHP",
regex=True,
na=False,
),
["hf_dhis2_raw", "hf_dhis2"],
].drop_duplicates().head()
# indicateur pour l'application de la règle un-à-un
enforce_one_to_one = False
# correspondances exactes utilisant les noms bruts
matched_dhis2_raw = (
dhis2_hf_unmatched[["adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw", "hf_uid_new"]]
.merge(
master_hf_df[["hf_mfl_raw"]],
left_on="hf_dhis2_raw",
right_on="hf_mfl_raw",
how="inner",
)
)
# correspondances exactes utilisant les noms standardisés
matched_dhis2 = (
dhis2_hf_unmatched[
["adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw", "hf_dhis2", "hf_uid_new"]
]
.merge(
master_hf_df[["hf_mfl_raw", "hf_mfl"]],
left_on="hf_dhis2",
right_on="hf_mfl",
how="inner",
)
)
# exclure les structures déjà appariées via les noms bruts
matched_dhis2 = anti_join(matched_dhis2, matched_dhis2_raw, on=["hf_dhis2_raw"])
matched_dhis2 = matched_dhis2.assign(
final_method="Matched Without Fuzzy Matching (standardization)",
score=100,
)
# calculer les non-appariés après standardisation
# anti-jointure à noms croisés : dhis2_hf_unmatched.hf_dhis2 vs master_hf_df.hf_mfl
unmatched_dhis2 = (
dhis2_hf_unmatched.loc[
~dhis2_hf_unmatched["hf_dhis2"].isin(master_hf_df["hf_mfl"]),
["hf_dhis2"],
]
.drop_duplicates(subset="hf_dhis2")
)
used_mfl = list(matched_dhis2["hf_mfl"].unique())
# construire le pool de candidats MFL pour l'étape de correspondance floue
candidate_mfl_df = master_hf_df[["hf_mfl"]].copy()
if enforce_one_to_one:
candidate_mfl_df = candidate_mfl_df.loc[~candidate_mfl_df["hf_mfl"].isin(used_mfl)]
# comptages récapitulatifs
total_dhis2_hf = dhis2_hf_unmatched["hf_dhis2_raw"].nunique()
raw_match_dhis2_hf = matched_dhis2_raw["hf_dhis2_raw"].nunique()
raw_unmatch_dhis2_hf = total_dhis2_hf - raw_match_dhis2_hf
standardized_match_dhis2_hf = matched_dhis2["hf_dhis2"].nunique()
standardized_unmatch_dhis2_hf = total_dhis2_hf - standardized_match_dhis2_hf
total_mfl_hf = master_hf_df["hf_mfl"].nunique()
candidate_mfl_count = candidate_mfl_df["hf_mfl"].nunique()
cli_header("Récapitulatif du statut de correspondance")
cli_info(f"Total des structures DHIS2 : {total_dhis2_hf:,}")
cli_success(f"Appariées après standardisation : {standardized_match_dhis2_hf:,}")
cli_danger(f"Non appariées avec les noms bruts : {raw_unmatch_dhis2_hf:,}")
cli_danger(f"Non appariées après standardisation : {standardized_unmatch_dhis2_hf:,}")
cli_info(
f"Structures MFL dans le pool de candidats pour la correspondance : "
f"{candidate_mfl_count:,} sur {total_mfl_hf:,}"
)
# créer une grille de correspondance complète pour la correspondance floue en
# associant chaque structure DHIS2 non appariée à toutes les structures MFL disponibles
candidate_match_pool = unmatched_dhis2.merge(candidate_mfl_df, how="cross")
# créer la grille de correspondance avec les noms DHIS2 et MFL
match_grid = candidate_match_pool.copy()
# aperçu de l'échantillon - 10 premières correspondances
match_grid.head(10)
from rapidfuzz.distance import Levenshtein, JaroWinkler
from rapidfuzz import fuzz
def _score_lv(a, b):
"""Normalized Levenshtein similarity (0–100)."""
len_max = max(len(a), len(b))
if len_max == 0:
return 100.0
return max(0.0, (1 - Levenshtein.distance(a, b) / len_max) * 100)
def _score_jw(a, b):
"""Jaro-Winkler similarity (0–100)."""
return JaroWinkler.similarity(a, b) * 100
def _score_qg(a, b):
"""Q-gram similarity (0–100) using token sort ratio."""
return float(fuzz.token_sort_ratio(a, b))
def _score_lcs(a, b):
"""LCS-based similarity (0–100) using partial ratio."""
return float(fuzz.partial_ratio(a, b))
# calculer les scores de correspondance floue
score_cols = ["score_jw", "score_lv", "score_qg", "score_lcs"]
match_grid = match_grid.assign(
score_jw=lambda d: d.apply(
lambda r: _score_jw(str(r["hf_dhis2"]), str(r["hf_mfl"])), axis=1
),
score_lv=lambda d: d.apply(
lambda r: _score_lv(str(r["hf_dhis2"]), str(r["hf_mfl"])), axis=1
),
score_qg=lambda d: d.apply(
lambda r: _score_qg(str(r["hf_dhis2"]), str(r["hf_mfl"])), axis=1
),
score_lcs=lambda d: d.apply(
lambda r: _score_lcs(str(r["hf_dhis2"]), str(r["hf_mfl"])), axis=1
),
)
# écrêter les valeurs négatives et NaN à zéro
for col in score_cols:
match_grid[col] = match_grid[col].clip(lower=0).fillna(0)
# définir les colonnes de scores de similarité
score_cols = ["score_jw", "score_lv", "score_qg", "score_lcs"]
# calculer composite_score (simple moyenne)
match_grid["composite_score"] = match_grid[score_cols].mean(axis=1)
# calculer le rang moyen sur toutes les méthodes de similarité
for col in score_cols:
match_grid[f"rank_{col}"] = (
match_grid.groupby("hf_dhis2")[col]
.rank(method="min", ascending=False)
)
rank_cols = [f"rank_{c}" for c in score_cols]
match_grid["rank_avg"] = (
match_grid[rank_cols].sum(axis=1) / len(score_cols)
).round()
ranked_grid = match_grid.copy()
# aperçu des résultats classés pour quelques structures échantillons
sample_facilities = [
"charity clinic kamba of",
"arab clinic shad",
"al arab clinic sheefa",
]
ranked_grid.loc[ranked_grid["hf_dhis2"].isin(sample_facilities)].groupby(
"hf_dhis2"
).apply(lambda g: g.nsmallest(4, "rank_avg")).reset_index(drop=True)[
["hf_dhis2", "hf_mfl"] + score_cols + ["composite_score", "rank_avg"]
].sort_values(["hf_dhis2", "rank_avg"])
# pour chaque méthode de correspondance floue, sélectionner le nom MFL le mieux classé par structure DHIS2
best_jw = (
match_grid.sort_values("score_jw", ascending=False)
.groupby("hf_dhis2", as_index=False).first()
[["hf_dhis2", "hf_mfl", "score_jw"]]
.rename(columns={"score_jw": "score"})
.assign(method="Jaro-Winkler")
)
best_lv = (
match_grid.sort_values("score_lv", ascending=False)
.groupby("hf_dhis2", as_index=False).first()
[["hf_dhis2", "hf_mfl", "score_lv"]]
.rename(columns={"score_lv": "score"})
.assign(method="Levenshtein")
)
best_qg = (
match_grid.sort_values("score_qg", ascending=False)
.groupby("hf_dhis2", as_index=False).first()
[["hf_dhis2", "hf_mfl", "score_qg"]]
.rename(columns={"score_qg": "score"})
.assign(method="Qgram")
)
best_lcs = (
match_grid.sort_values("score_lcs", ascending=False)
.groupby("hf_dhis2", as_index=False).first()
[["hf_dhis2", "hf_mfl", "score_lcs"]]
.rename(columns={"score_lcs": "score"})
.assign(method="LCS")
)
best_comp = (
match_grid.sort_values("composite_score", ascending=False)
.groupby("hf_dhis2", as_index=False).first()
[["hf_dhis2", "hf_mfl", "composite_score"]]
.rename(columns={"composite_score": "score"})
.assign(method="Composite-Score")
)
best_ranked_match = (
ranked_grid.sort_values("rank_avg")
.groupby("hf_dhis2", as_index=False).first()
[["hf_dhis2", "hf_mfl", "rank_avg"]]
.rename(columns={"rank_avg": "score"})
.assign(method="Rank-Ensemble")
)
# combiner les meilleures correspondances de toutes les méthodes pour comparaison
all_best = pd.concat(
[best_jw, best_lv, best_qg, best_lcs, best_comp, best_ranked_match],
ignore_index=True,
)
# aperçu des meilleures correspondances
all_best.head(10)[["hf_dhis2", "hf_mfl", "score", "method"]]
import matplotlib.pyplot as plt
# tracer la distribution des scores selon les méthodes (exclure la méthode par rang)
methods_for_plot = all_best.loc[all_best["method"] != "Rank-Ensemble"]
method_names = sorted(methods_for_plot["method"].unique())
fig, axes = plt.subplots(1, len(method_names), figsize=(12, 6), sharey=True)
for ax, name in zip(axes, method_names):
grp = methods_for_plot.loc[methods_for_plot["method"] == name, "score"].dropna()
grp.plot.kde(ax=ax, color="steelblue", linewidth=1)
ax.fill_between(
ax.lines[0].get_xdata(),
ax.lines[0].get_ydata(),
alpha=0.6,
color="steelblue",
)
ax.set_title(name, fontsize=11)
ax.set_xlabel("\nMatch Score (%)")
if ax == axes[0]:
ax.set_ylabel("Density\n")
fig.suptitle("Distribution of Fuzzy Matching Scores", fontsize=14)
plt.tight_layout()
# sauvegarder le graphique
output_dir = Path(here("03_output/3a_figures"))
output_dir.mkdir(parents=True, exist_ok=True)
fig.savefig(output_dir / "fuzzy_score_distributions.png", dpi=300, bbox_inches="tight")
def assess_match_quality(names1, names2):
"""Compute structural quality diagnostics for name pairs.
Returns a DataFrame with prefix_match, suffix_match,
token_diff, and char_diff for each name pair.
"""
rows = []
for a, b in zip(names1, names2):
tokens1 = str(a).split()
tokens2 = str(b).split()
rows.append({
"prefix_match": tokens1[0].lower() == tokens2[0].lower()
if tokens1 and tokens2 else False,
"suffix_match": tokens1[-1].lower() == tokens2[-1].lower()
if tokens1 and tokens2 else False,
"token_diff": abs(len(tokens1) - len(tokens2)),
"char_diff": abs(len(str(a)) - len(str(b))),
})
return pd.DataFrame(rows)
assess_match_quality(["Makeni Govt Hospital"], ["Makeni Government Hospital"])
def _rescale(series, new_min, new_max):
"""Rescale a numeric series to [new_min, new_max]."""
s_min, s_max = series.min(), series.max()
if s_max == s_min:
return pd.Series([new_min] * len(series), index=series.index)
return new_min + (series - s_min) / (s_max - s_min) * (new_max - new_min)
# évaluer la qualité structurelle des correspondances
diagnostics_df = pd.concat(
[all_best.reset_index(drop=True),
assess_match_quality(all_best["hf_dhis2"], all_best["hf_mfl"])],
axis=1,
)
# comparer les diagnostics par méthode
summary_stats = (
diagnostics_df
.groupby("method")
.agg(
avg_token_diff=("token_diff", "mean"),
avg_char_diff=("char_diff", "mean"),
pct_prefix_match=("prefix_match", "mean"),
pct_suffix_match=("suffix_match", "mean"),
total=("hf_dhis2", "count"),
)
.reset_index()
.assign(
avg_token_diff=lambda d: d["avg_token_diff"].round(2),
avg_char_diff=lambda d: d["avg_char_diff"].round(2),
pct_prefix_match=lambda d: (d["pct_prefix_match"] * 100).round(2),
pct_suffix_match=lambda d: (d["pct_suffix_match"] * 100).round(2),
)
)
# créer un score global final
summary_stats = summary_stats.assign(
# redimensionner le négatif de la différence moyenne de tokens (plus petit = meilleur)
token_score=lambda d: _rescale(-d["avg_token_diff"], 0, 100),
# redimensionner le négatif de la différence moyenne de caractères (plus petit = meilleur)
char_score=lambda d: _rescale(-d["avg_char_diff"], 0, 100),
# redimensionner le pourcentage de correspondance de préfixe (plus élevé = meilleur)
prefix_score=lambda d: _rescale(d["pct_prefix_match"], 0, 100),
# redimensionner le pourcentage de correspondance de suffixe (plus élevé = meilleur)
suffix_score=lambda d: _rescale(d["pct_suffix_match"], 0, 100),
).assign(
# combiner les quatre métriques en un score de qualité structurelle pondéré
structure_score=lambda d: (
0.3 * d["token_score"] + # accentuer les faibles différences de tokens
0.2 * d["char_score"] + # poids modéré sur la similarité de caractères
0.25 * d["prefix_score"] + # pondérer les mots initiaux correspondants
0.25 * d["suffix_score"] # pondérer également les mots finaux correspondants
).round(1)
).sort_values("structure_score", ascending=False)
summary_stats["rank"] = range(1, len(summary_stats) + 1)
summary_stats.rename(columns={
"method": "Method",
"avg_token_diff": "Avg. Token Difference",
"avg_char_diff": "Avg. Character Difference",
"pct_prefix_match": "% Prefix Match",
"pct_suffix_match": "% Suffix Match",
"structure_score": "Structural Score",
"rank": "Rank",
})[["Method", "Avg. Token Difference", "Avg. Character Difference",
"% Prefix Match", "% Suffix Match", "Structural Score", "Rank"]]
# calculer les poids et seuils spécifiques à chaque méthode
q70 = all_best["score"].quantile(0.70)
q95 = all_best["score"].quantile(0.95)
method_threshold = summary_stats[["method", "structure_score"]].copy()
method_threshold["score_frac"] = method_threshold["structure_score"] / 100
method_threshold["weight"] = (
method_threshold["score_frac"] / method_threshold["score_frac"].sum()
)
# mise à l'échelle inverse : structure_score élevé → seuil plus bas (correspondance plus facile)
method_threshold["threshold"] = (
_rescale(method_threshold["structure_score"], q95, q70)
).round()
method_threshold = method_threshold[["method", "weight", "threshold"]]
# afficher les résultats
method_threshold
# appliquer le seuil par méthode unique et signaler les correspondances
best_lv_final = (
best_lv
.assign(
match_flag=lambda d: np.where(d["score"] >= 85, "match", "review"),
final_method="Levenshtein",
)
.merge(master_hf_df[["hf_mfl", "hf_mfl_raw"]], on="hf_mfl", how="left")
[["hf_dhis2", "hf_mfl", "hf_mfl_raw", "score", "final_method", "match_flag"]]
)
# afficher les 5 meilleures et 5 pires correspondances par score
top_5 = best_lv_final.sort_values("score", ascending=False).head(5)
bottom_5 = best_lv_final.sort_values("score").head(5)
# combiner en un seul tableau
top_bottom = pd.concat([top_5, bottom_5], ignore_index=True)
cli_header("5 premières et 5 dernières correspondances par score Levenshtein")
# aperçu des résultats
top_bottom
# sélectionner la meilleure correspondance en utilisant le rang moyen
composite_final = (
ranked_grid.sort_values("rank_avg")
.groupby("hf_dhis2", as_index=False)
.first()
.assign(
match_flag=lambda d: np.where(d["composite_score"] >= 85, "match", "review"),
score=lambda d: d["composite_score"],
final_method="Composite-Score",
)
.merge(master_hf_df[["hf_mfl", "hf_mfl_raw"]], on="hf_mfl", how="left")
[["hf_dhis2", "hf_mfl", "hf_mfl_raw", "score", "final_method", "match_flag"]]
)
# afficher les 5 meilleures et 5 pires correspondances par score composite
top_5 = composite_final.sort_values("score", ascending=False).head(5)
bottom_5 = composite_final.sort_values("score").head(5)
# combiner en un seul tableau
top_bottom = pd.concat([top_5, bottom_5], ignore_index=True)
cli_header("5 premiers et 5 derniers appariements par score composite")
# aperçu des résultats
top_bottom
# définir les colonnes de score et extraire les poids
score_cols = ["score_jw", "score_lv", "score_qg", "score_lcs"]
weights_df = method_threshold.loc[
method_threshold["method"].isin(["Jaro-Winkler", "Levenshtein", "Qgram", "LCS"])
]
weights = weights_df.set_index("method")["weight"]
# extraire les poids individuels pour chaque méthode
w_jw = float(weights.get("Jaro-Winkler", 0))
w_lv = float(weights.get("Levenshtein", 0))
w_qg = float(weights.get("Qgram", 0))
w_lcs = float(weights.get("LCS", 0))
# calculer le score composite pondéré pour chaque paire établissement-candidat
# la moyenne pondérée maintient l'échelle 0-100
weighted_final = (
ranked_grid.assign(
weighted_composite_score=lambda d: (
d["score_jw"] * w_jw +
d["score_lv"] * w_lv +
d["score_qg"] * w_qg +
d["score_lcs"] * w_lcs
)
)
.sort_values("weighted_composite_score", ascending=False)
.groupby("hf_dhis2", as_index=False)
.first()
.assign(
match_flag=lambda d: np.where(
d["weighted_composite_score"] >= 85, "match", "review"
),
score=lambda d: d["weighted_composite_score"],
final_method="Weighted-Composite",
)
.merge(master_hf_df[["hf_mfl", "hf_mfl_raw"]], on="hf_mfl", how="left")
[["hf_dhis2", "hf_mfl", "hf_mfl_raw", "score", "final_method", "match_flag"]]
)
# afficher les 5 meilleures et 5 pires correspondances par score composite pondéré
top_5 = weighted_final.sort_values("score", ascending=False).head(5)
bottom_5 = weighted_final.sort_values("score").head(5)
cli_header("5 premiers et 5 derniers appariements par score composite pondéré")
# aperçu des résultats
bottom_5
# extraire l'ordre des méthodes et les seuils des résultats de l'étape 7.4
# classer les méthodes par score de structure (du plus élevé au plus bas)
method_stats = summary_stats.loc[
summary_stats["method"] != "Rank-Ensemble"
].sort_values("structure_score", ascending=False)
method_order = list(method_stats["method"])
# utiliser les seuils calculés à l'étape 7.4
method_thresholds_df = method_threshold.loc[method_threshold["method"] != "Rank-Ensemble"]
method_thresholds = dict(zip(method_thresholds_df["method"], method_thresholds_df["threshold"]))
# construire le tableau combiné des meilleures correspondances des méthodes réelles uniquement
all_best_nonrank = pd.concat(
[best_lv, best_jw, best_qg, best_lcs, best_comp], ignore_index=True
)
all_best_nonrank["method"] = all_best_nonrank["method"].str.strip()
# ajouter le rang une seule fois
rank_key = ranked_grid[["hf_dhis2", "hf_mfl", "rank_avg"]].copy()
all_best_ranked = (
all_best_nonrank
.merge(rank_key, on=["hf_dhis2", "hf_mfl"], how="left")
.assign(rank_avg=lambda d: d["rank_avg"].fillna(float("inf")))
)
# diviser par méthode et pré-trier pour un départage stable
by_method = {
m: grp.sort_values(["score", "rank_avg"], ascending=[False, True])
for m, grp in all_best_ranked.groupby("method")
}
fallback_chunks = []
unmatched_set = set(all_best_ranked["hf_dhis2"].unique())
current_thresholds = dict(method_thresholds)
# boucle de repli rapide
while True:
for m in method_order:
if m not in by_method:
continue
thr = current_thresholds.get(m, 85) # repli si la méthode n'est pas trouvée
cand = by_method[m].loc[
(by_method[m]["score"] >= thr) &
(by_method[m]["hf_dhis2"].isin(unmatched_set))
]
if len(cand) > 0:
best_per_hf = (
cand.drop_duplicates(subset="hf_dhis2", keep="first")
.assign(final_method=f"Fuzzy-matched using: {m}")
)
fallback_chunks.append(best_per_hf)
unmatched_set -= set(best_per_hf["hf_dhis2"])
if not unmatched_set:
break
if not unmatched_set:
break
# relâcher progressivement les seuils
current_thresholds = {k: v - 1 for k, v in current_thresholds.items()}
if any(v <= 50 for v in current_thresholds.values()): # arrêter si trop bas
break
# combiner une seule fois
fallback_matched = (
pd.concat(fallback_chunks, ignore_index=True)
if fallback_chunks else pd.DataFrame()
)
# construire une correspondance 1:1 depuis le nom DHIS2 standardisé vers admin + brut + hf_uid_new
hf_uid_new_map_by_stand = (
dhis2_hf_unmatched
.sort_values(["adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw"])
.groupby("hf_dhis2", as_index=False)
.first()[["hf_dhis2", "adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw", "hf_uid_new"]]
)
# indicateurs finaux et rattachement des unités administratives + identifiants
fallback_final = (
fallback_matched
.assign(match_flag=lambda d: np.where(d["score"] >= 85, "match", "review"))
.merge(master_hf_df[["hf_mfl", "hf_mfl_raw"]], on="hf_mfl", how="left")
.merge(hf_uid_new_map_by_stand, on="hf_dhis2", how="left")
[["adm0", "adm1", "adm2", "adm3", "hf_uid_new",
"hf_dhis2_raw", "hf_dhis2", "hf_mfl_raw", "hf_mfl",
"score", "final_method", "match_flag"]]
)
top_5 = fallback_final.sort_values("score", ascending=False).head(5)
bottom_5 = fallback_final.sort_values("score").head(5)
cli_header("5 premiers et 5 derniers appariements par repli")
bottom_5 = pd.concat([top_5, bottom_5], ignore_index=True)
# aperçu des résultats
bottom_5
# créer fuzzy_matches à partir des résultats de l'étape 8 (utiliser l'option choisie)
# l'étape 8 produit différents jeux de données selon l'option choisie :
# - option 1: best_lv_final, best_jw_final, etc.
# - option 2: composite_final
# - option 3: weighted_final
# - option 4: fallback_final
if "fallback_final" in dir():
fuzzy_matches_raw = fallback_final.loc[fallback_final["match_flag"] == "match"]
elif "composite_final" in dir():
fuzzy_matches_raw = composite_final.loc[composite_final["match_flag"] == "match"]
elif "weighted_final" in dir():
fuzzy_matches_raw = weighted_final.loc[weighted_final["match_flag"] == "match"]
elif "best_lv_final" in dir():
fuzzy_matches_raw = best_lv_final.loc[best_lv_final["match_flag"] == "match"]
elif "best_jw_final" in dir():
fuzzy_matches_raw = best_jw_final.loc[best_jw_final["match_flag"] == "match"]
elif "best_qg_final" in dir():
fuzzy_matches_raw = best_qg_final.loc[best_qg_final["match_flag"] == "match"]
else:
# dataframe vide avec la structure attendue si aucun résultat de l'étape 8 n'existe
fuzzy_matches_raw = pd.DataFrame(columns=[
"hf_dhis2_raw", "hf_dhis2", "hf_mfl_raw", "hf_mfl",
"score", "final_method",
])
# dédupliquer : conserver la correspondance avec le score le plus élevé par établissement DHIS2
fuzzy_matches = (
fuzzy_matches_raw
.sort_values("score", ascending=False)
.drop_duplicates(subset="hf_dhis2_raw", keep="first")
.merge(
dhis2_hf_unmatched[["adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw", "hf_uid_new"]]
.sort_values(["adm0", "adm1", "adm2", "adm3", "hf_dhis2_raw"])
.drop_duplicates(subset="hf_dhis2_raw", keep="first"),
on="hf_dhis2_raw",
how="left",
)
)
# afficher le récapitulatif de l'approche sélectionnée
cli_header("Résultats de l'appariement flou sélectionné")
cli_success(f"Correspondances floues trouvées : {len(fuzzy_matches)}")
if len(fuzzy_matches) > 0:
cli_info(
f"Plage de scores : {fuzzy_matches['score'].min():.1f} - "
f"{fuzzy_matches['score'].max():.1f}"
)
cli_info(f"Score moyen : {fuzzy_matches['score'].mean():.1f}")
# préparer le jeu de données de révision (en utilisant les résultats de repli comme exemple)
review_matches = (
fallback_final
.loc[fallback_final["match_flag"] == "review"]
.sort_values("score", ascending=False)
.assign(
reviewer_decision=pd.NA, # accept/reject/uncertain
reviewer_notes=pd.NA,
review_date=pd.NA,
reviewer_name=pd.NA,
)
[["adm0", "adm1", "adm2", "adm3", "hf_uid_new",
"hf_dhis2_raw", "hf_dhis2", "hf_mfl_raw", "hf_mfl",
"score", "final_method",
"reviewer_decision", "reviewer_notes", "review_date", "reviewer_name"]]
)
# exporter pour révision
output_dir = Path(here("03_outputs/tables"))
output_dir.mkdir(parents=True, exist_ok=True)
review_matches.to_csv(output_dir / "facility_matches_for_review.csv", index=False)
# afficher le récapitulatif
cli_header("Révision manuelle requise")
cli_info(f"Exporté {len(review_matches)} correspondances signalées pour révision")
cli_info("Emplacement du fichier : outputs/tables/facility_matches_for_review.csv")
# simuler les décisions des réviseurs (remplacer par les données réellement révisées)
# relire les correspondances révisées
reviewed_matches = pd.read_csv(
here("03_outputs/tables/facility_matches_reviewed.csv"),
dtype={
"reviewer_decision": "object",
"reviewer_notes": "object",
"review_date": "object",
"reviewer_name": "object",
}
)
final_incorp = reviewed_matches.assign(
final_match_flag=lambda d: np.select(
[
d["reviewer_decision"] == "accept",
d["reviewer_decision"] == "reject",
d["reviewer_decision"].isna(),
],
["match", "no_match", "pending_review"],
default="no_match",
)
)
# obtenir les correspondances finalement acceptées
final_matches = (
final_incorp
.loc[final_incorp["final_match_flag"] == "match"]
.drop(columns="reviewer_decision", errors="ignore")
)
# récapitulatif de tous les résultats (y compris rejetés/en attente)
all_results_summary = (
final_incorp.groupby("final_match_flag", as_index=False)
.size()
.rename(columns={"size": "n"})
.assign(percentage=lambda d: (d["n"] / d["n"].sum() * 100).round(1))
)
cli_header("Résultats finaux de l'appariement après révision manuelle")
cli_success(f"Correspondances acceptées : {len(final_matches):,}")
# ventilation par type de décision
rejected_count = int(
all_results_summary.loc[all_results_summary["final_match_flag"] == "no_match", "n"].sum()
)
pending_count = int(
all_results_summary.loc[
all_results_summary["final_match_flag"] == "pending_review", "n"
].sum()
)
if rejected_count > 0:
cli_danger(
f"Correspondances rejetées : {rejected_count:,} "
"(auront des valeurs NA dans les colonnes MFL du jeu de données final)"
)
if pending_count > 0:
cli_warning(f"En attente de révision : {pending_count:,} (nécessitent une révision supplémentaire)")
# afficher le tableau de ventilation
all_results_summary
# créer manual_matches à partir des résultats de la révision manuelle
# (correspondances et non-correspondances)
manual_matches = final_incorp.assign(
# pour les établissements sans correspondance, définir des valeurs appropriées
hf_mfl=lambda d: np.where(d["reviewer_decision"] == "accept", d["hf_mfl"], pd.NA),
hf_mfl_raw=lambda d: np.where(
d["reviewer_decision"] == "accept", d["hf_mfl_raw"], pd.NA
),
final_method=lambda d: np.where(
d["reviewer_decision"] == "accept",
"Manual Review - Accepted",
"Manual Review - Rejected",
),
score=lambda d: np.where(d["reviewer_decision"] == "accept", 100, 0),
)
cols_needed = [
"adm0", "adm1", "adm2", "adm3", "hf_uid_new",
"hf_dhis2_raw", "hf_dhis2", "hf_mfl_raw", "hf_mfl", "score", "final_method",
]
manual_matches = manual_matches[[c for c in cols_needed if c in manual_matches.columns]]
# combiner les résultats de toutes les approches de correspondance
# ce jeu de données contient TOUS les établissements : avec correspondance,
# sans correspondance et rejetés
final_facilities_all = pd.concat(
[
# étape 4 : correspondances géographiques stratifiées (si effectuées)
matched_dhis2_prepgeoname[[c for c in cols_needed if c in matched_dhis2_prepgeoname.columns]],
# étape 5 : correspondances exactes après standardisation
matched_dhis2[[c for c in cols_needed if c in matched_dhis2.columns]],
# étapes 6-8 : correspondances complètes issues de la correspondance floue
fuzzy_matches[[c for c in cols_needed if c in fuzzy_matches.columns]],
# correspondance manuelle (si effectuée)
manual_matches,
],
ignore_index=True,
)
# réduire à un enregistrement par établissement DHIS2 pour l'intégration aval
cols_to_drop = [c for c in ["match_flag", "hf"] if c in final_facilities_all.columns]
final_facilities_one_per_hf = final_facilities_all.drop(columns=cols_to_drop, errors="ignore")
cli_info(f"Tous les établissements traités (lignes) : {len(final_facilities_all)}")
cli_success(
f"Tous les établissements traités (DHIS2 distincts par hf_uid_new) : "
f"{final_facilities_all['hf_uid_new'].nunique()}"
)
# générer un résumé par méthode de correspondance
matching_summary = (
final_facilities_one_per_hf
.groupby("final_method", as_index=False)
.agg(
n_matched=("hf_dhis2_raw", "count"),
avg_score=("score", "mean"),
min_score=("score", "min"),
max_score=("score", "max"),
)
)
# afficher le résumé
cli_header("Résultats de correspondance par méthode")
matching_summary
# prendre DHIS2 comme base pour conserver toutes les lignes ;
# rattacher hf_uid_new
dhis2_df_final = dhis2_df.merge(
dhis2_map,
on=["adm0", "adm1", "adm2", "adm3", "hf"],
how="left",
)
# résultats de correspondance par établissement : utiliser hf_uid_new comme
# clé de jointure
final_match_per_hf = final_facilities_one_per_hf[["hf_uid_new", "hf_mfl_raw"]].copy()
# créer le jeu de données intégré
final_dhis2_mfl_df = (
dhis2_df_final
.merge(final_match_per_hf, on="hf_uid_new", how="left")
# joindre les attributs MFL pour les établissements avec correspondance
.merge(
master_hf_df.drop(
columns=["hf_mfl", "hf", "adm0", "adm1", "adm2", "adm3"],
errors="ignore",
),
on="hf_mfl_raw",
how="left",
)
)
# comptages sur les établissements distincts via hf_uid_new
total = dhis2_df_final["hf_uid_new"].nunique()
with_mfl = final_match_per_hf.dropna(subset=["hf_mfl_raw"])["hf_uid_new"].nunique()
without_mfl = total - with_mfl
# résumé de validation
cli_header("Intégration DHIS2-MFL terminée")
cli_success(f"Total des établissements DHIS2 conservés : {total}")
cli_info(f"Établissements avec données MFL : {with_mfl}")
cli_warning(f"Établissements sans correspondance MFL : {without_mfl}")
cli_info(f"Total des lignes (établissement-mois) : {len(final_dhis2_mfl_df)}")
# détecter les établissements MFL mis en correspondance avec plusieurs
# établissements DHIS2
one_to_many = (
final_facilities_all
.dropna(subset=["hf_mfl_raw"]) # uniquement les établissements avec correspondance
.groupby("hf_mfl_raw")
.filter(lambda g: len(g) > 1) # MFL mis en correspondance avec >1 DHIS2
.sort_values(["hf_mfl_raw", "hf_dhis2_raw"])
)
if len(one_to_many) > 0:
cli_warning(
f"Correspondances un-à-plusieurs détectées : {len(one_to_many)} établissements DHIS2 "
f"partagent {one_to_many['hf_mfl_raw'].nunique()} établissements MFL"
)
# afficher un échantillon
print(
one_to_many[["hf_dhis2_raw", "hf_mfl_raw", "score", "final_method"]]
.head(6)
.to_string(index=False)
)
else:
cli_success("Aucune correspondance un-à-plusieurs détectée")
# analyser les établissements sans correspondance par raison
unmatched_analysis = (
final_facilities_all
.loc[final_facilities_all["hf_mfl_raw"].isna()]
.groupby("final_method", as_index=False)
.size()
.rename(columns={"size": "count"})
.sort_values("count", ascending=False)
)
# afficher l'analyse des établissements sans correspondance
cli_header("Analyse des établissements sans correspondance")
cli_info(f"Total des établissements sans correspondance : {unmatched_analysis['count'].sum()}")
# afficher la répartition par raison
for _, row in unmatched_analysis.iterrows():
cli_warning(f"{row['final_method']}: {row['count']} facilities")
# créer un export détaillé des établissements sans correspondance
unmatched_detailed = (
final_facilities_one_per_hf
.loc[final_facilities_one_per_hf["hf_mfl_raw"].isna()]
[["hf_dhis2_raw", "adm1", "adm2", "adm3", "final_method", "score"]]
.assign(
potential_reason=lambda d: np.select(
[
d["final_method"].isna(),
d["final_method"] == "Manual Review - Rejected",
(d["score"] > 0) & (d["score"] < 50),
],
[
"Never matched - possible new facility",
"Rejected in review - possible different facility",
"Low similarity - possible data quality issue",
],
default="Unmatched - needs investigation",
)
)
.sort_values(["adm1", "adm2", "adm3", "hf_dhis2_raw"])
)
# exporter pour révision par l'équipe SNT
unmatched_export_dir = Path(here("03_outputs"))
unmatched_export_dir.mkdir(parents=True, exist_ok=True)
unmatched_detailed.to_csv(
unmatched_export_dir / "unmatched_facilities_for_snt_review.csv", index=False
)
cli_success(
f"Exporté {len(unmatched_detailed)} établissements sans correspondance pour révision par l'équipe SNT"
)
cli_info("File: outputs/unmatched_facilities_for_snt_review.csv")
# sauvegarder le jeu de données intégré DHIS2-MFL principal
output_dir = Path(here("03_outputs"))
output_dir.mkdir(parents=True, exist_ok=True)
final_dhis2_mfl_df.to_excel(
output_dir / "final_dhis2_mfl_integrated.xlsx", index=False
)
# sauvegarder le résumé des résultats de correspondance
final_facilities_all.to_excel(
output_dir / "facility_matching_results.xlsx", index=False
)
if len(unmatched_detailed) > 0:
unmatched_detailed.to_csv(
output_dir / "unmatched_dhis2_facilities.csv", index=False
)
if len(one_to_many) > 0:
one_to_many.to_csv(
output_dir / "one_to_many_matches_for_review.csv", index=False
)
# résumé des fichiers sauvegardés
cli_header("Jeux de données finaux sauvegardés")
cli_success("Jeu de données intégré principal : final_dhis2_mfl_integrated.xlsx")
cli_success("Résultats de correspondance : facility_matching_results.xlsx")
cli_info(f"Établissements sans correspondance : {len(unmatched_detailed)} exportés")
cli_info(f"Correspondances un-à-plusieurs : {len(one_to_many)} exportées")
Comment savoir si une correspondance est « bonne » ?
Les algorithmes de correspondance approximative renvoient des scores de similarité qui estiment la ressemblance entre deux noms. Mais un score de similarité élevé ne garantit pas toujours une correspondance correcte. Par exemple, des établissements ayant des composants communs comme « community health post » peuvent recevoir des scores élevés, même si la correspondance est incorrecte. Cela souligne l’importance de regarder au-delà des scores bruts.
Pour améliorer la confiance dans les correspondances, nous pouvons utiliser des diagnostics supplémentaires qui évaluent la qualité des correspondances sous différents angles. Ceux-ci comprennent :
Ces diagnostics sont destinés à compléter les scores de similarité, et non à les remplacer. Les diagnostics aident à identifier les cas où un score élevé peut être trompeur et guident la manière dont nous filtrons, classons ou combinons les résultats à travers plusieurs algorithmes.
Prenons cet exemple :
Supposons que
Makeni Govt Hospitalcorresponde avecMakeni Government Hospital. Mais dans quelle mesure cette correspondance est-elle bonne ?Nous pouvons évaluer la qualité à l’aide de quelques caractéristiques intuitives :
Le préfixe correspond : les deux commencent par
Makeni. Le suffixe correspond : les deux se terminent parHospital. La différence de tokens est 0, les deux contiennent trois mots. La différence de caractères est petite, seulement 6 caractères d’écart. La différence provient principalement deGovtvsGovernment.Ces caractéristiques suggèrent une correspondance solide, même si le score de similarité de chaîne brute est imparfait.