pacman::p_load(
dplyr, # manipulation des données
tidyr, # mise en forme des données
lubridate, # gestion des dates
ggplot2, # visualisation des données
scales, # formatage des axes
data.table, # rleid() pour le regroupement par longueur de séquence
forcats, # ordre des facteurs pour l'axe y de la carte thermique
patchwork, # disposition des graphiques diagnostiques côte à côte
knitr, # rendu de tableaux html
tibble, # tribble() pour les tableaux littéraux ordonnés
glue, # interpolation de chaînes
cli, # messages informatifs
here # chemins de fichiers reproductibles
)Détermination du statut actif et inactif
Aperçu
Dans le flux de travail SNT, les calculs du taux de déclaration, nécessaires à l’estimation de l’incidence, du recours aux soins et d’autres indicateurs en aval, dépendent du statut d’activité de chaque établissement de santé. Savoir si un établissement était opérationnel un mois donné détermine si son absence dans les données doit être traitée comme un problème de dénominateur (l’établissement n’était pas censé déclarer) ou comme un problème de qualité des données (l’établissement était censé déclarer mais ne l’a pas fait).
Dans la plupart des pays, une Liste des établissements de santé (LES) tenue par le PNM fournit le statut actif/inactif officiel de chaque établissement. Lorsque cette liste est absente, obsolète ou insuffisamment précise au niveau mensuel, nous recourons à l’inférence du statut d’activité à partir des données de déclaration elles-mêmes : un établissement est considéré actif les mois où il a soumis au moins un des indicateurs clés du paludisme.
Cette page présente trois méthodes complémentaires d’inférence : Activation permanente, Premier-au-dernier avec période de grâce, et Longueur de séquence dynamique. Chaque méthode repose sur des hypothèses différentes sur la façon dont les établissements ouvrent, ferment et rouvrent, et le choix a des conséquences directes sur tous les résultats fondés sur le taux de déclaration. Nous terminons par une comparaison diagnostique afin de voir en un coup d’oeil où les trois méthodes concordent et où elles divergent sur le même panel DHIS2.
NoteObjectifs
- Classer chaque paire établissement-mois dans l’une des catégories : Déclarant actif / Actif – Non déclarant / Inactif
- Visualiser l’activité mensuelle de déclaration à l’échelle du pays et au sein des unités administratives
- Comparer les méthodes de classification côte à côte et choisir celle qui convient à l’analyse
- Exporter le dénominateur des établissements actifs (
df_expected) utilisé dans les calculs en aval du taux de déclaration et de l’incidence
Concepts clés
Pour procéder aux calculs du taux de déclaration, nous devons d’abord déterminer si chaque établissement de santé était actif un mois donné, c’est-à-dire s’il était censé déclarer.
La méthode utilisée pour définir le statut d’activité des établissements doit être discutée avec l’équipe SNT, qui orientera le choix selon si le pays dispose d’une méthode établie ou préférée. Dans certains cas, le PNM s’appuie déjà sur une Liste des établissements de santé (LES) pour identifier les établissements actifs. Bien que cela puisse constituer un point de départ utile, cela ne reflète pas toujours la prestation de services en temps réel ni la fonctionnalité de l’établissement, et sa fiabilité doit être soigneusement évaluée.
Si aucune méthode fiable n’existe, ou si une validation supplémentaire est requise, une approche alternative fondée sur les données peut être utilisée. Cette approche infère le statut d’activité directement à partir des données de surveillance de routine, en se basant sur le fait qu’un établissement a déclaré des valeurs valides pour des indicateurs clés du paludisme.
NoteClassification mensuelle de l’activité
Pour chaque établissement de santé (ES) un mois donné :
- Si l’ES a soumis des données valides (non-NA) pour tout indicateur clé → il est classifié comme Déclarant actif
- Si l’ES n’a pas déclaré sur les indicateurs clés :
- S’il a déclaré lors d’un mois précédent → Actif – Non déclarant
- S’il n’a jamais déclaré (ou a été silencieux suffisamment longtemps pour être considéré comme fermé) → Inactif
Ces indicateurs clés (tels que allout, test, susp, pres, conf et treat) reflètent les fonctions essentielles de la prestation de services contre le paludisme, notamment la notification des cas suspects, les tests diagnostiques et le traitement. Si un établissement déclare sur l’un de ces indicateurs au cours d’un mois donné, on peut raisonnablement le considérer comme opérationnel et engagé dans le système de surveillance du paludisme.
TipBonne pratique : utiliser la LES lorsqu’elle est disponible
Dans la mesure du possible, obtenez une copie de la Liste des établissements de santé (LES) qui inclut des colonnes pour le statut actif/inactif des établissements de santé. Il s’agit généralement de la classification la plus précise et la plus à jour du statut actif/inactif des établissements. Utilisez ces informations pour générer des visualisations du statut actif et l’analyse du taux de déclaration. Consultez la page Fusion de shapefiles avec des données tabulaires pour fusionner la LES avec les données DHIS2 et procéder aux étapes de visualisation de cette page.
ImportantConsultez l’équipe SNT
En l’absence d’informations sur le statut actif des établissements de santé dans la LES, le statut actif/inactif peut être déterminé par l’une des trois méthodes ci-dessous en fonction de ce qui est désigné comme indicateur clé.
La sélection des indicateurs clés (et la méthode utilisée pour définir l’activité des établissements) doit être discutée et validée avec l’équipe SNT. Dans certains pays, une Liste des établissements de santé peut être appropriée ; dans d’autres, des définitions basées sur les indicateurs peuvent être plus fiables. L’approche finale doit refléter la façon dont les services contre le paludisme sont délivrés et déclarés dans le système national.
WarningStatut d’activité spécifique à l’indicateur
Dans la plupart des pays, un statut d’activité mensuel distinct peut être nécessaire lors du calcul des taux de déclaration pour les indicateurs IPD ou OPD spécifiques. Par exemple, les indicateurs de soins hospitaliers ne doivent inclure que les établissements disposant d’une capacité d’hospitalisation. Les critères d’inclusion doivent être discutés avec le programme. Bien que le type d’établissement (par exemple, hôpital ou centre de santé avec salles) puisse aider, il n’est pas toujours déterminant.
Méthodes de classification de l’activité
Un établissement de santé est considéré comme « actif » pour un mois donné selon trois méthodes différentes, chacune avec des critères distincts. Voici les trois méthodes.
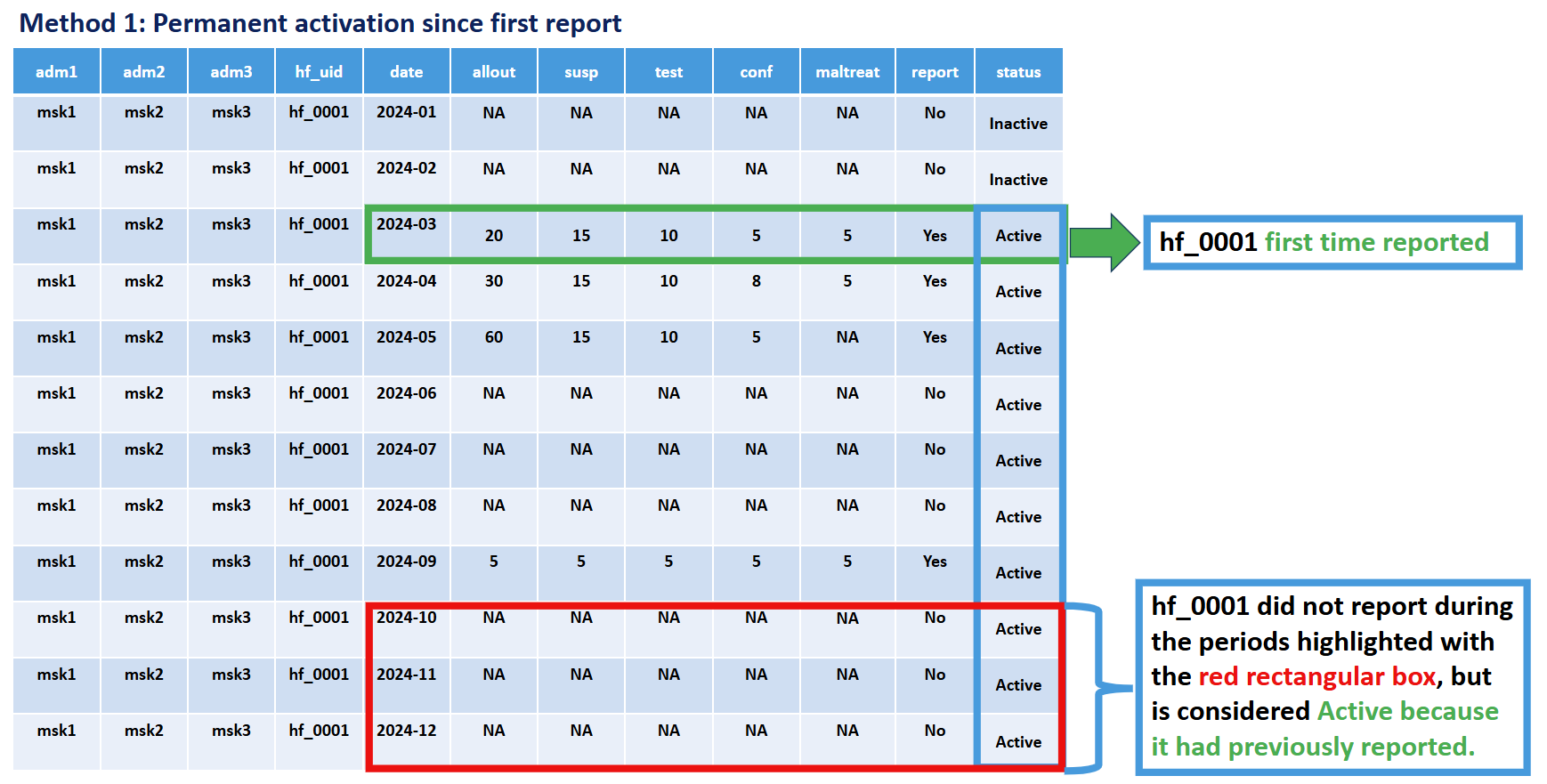
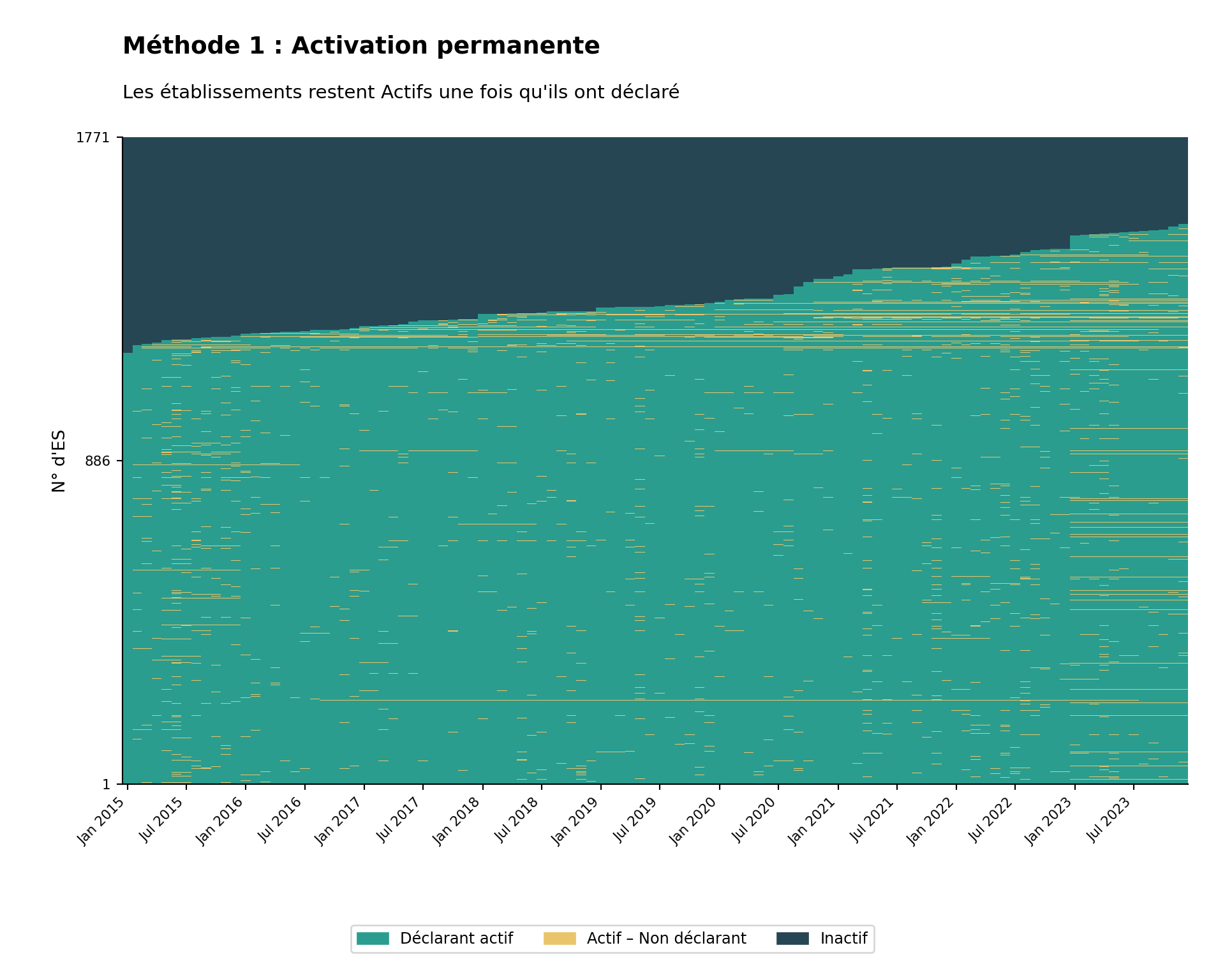
Méthode 1 : Activation permanente
Critères : Un établissement est classé comme actif à partir de son premier mois de déclaration, et inactif avant ce premier rapport.
Principe clé : Un établissement n’est inclus dans le dénominateur (censé déclarer) qu’à partir du mois où il a effectivement déclaré pour la première fois des données sur le paludisme. Avant ce premier mois de déclaration, l’établissement est considéré « inactif » et n’est pas censé déclarer.
Justification : Cette méthode reconnaît que les établissements peuvent ne pas exister, être opérationnels, avoir accès à DHIS2, ou participer à la surveillance du paludisme depuis le début de la période d’analyse. Elle évite de sous-estimer les performances de déclaration en n’évaluant les établissements que pendant les périodes où ils ont démontré la capacité à déclarer.
Illustration :
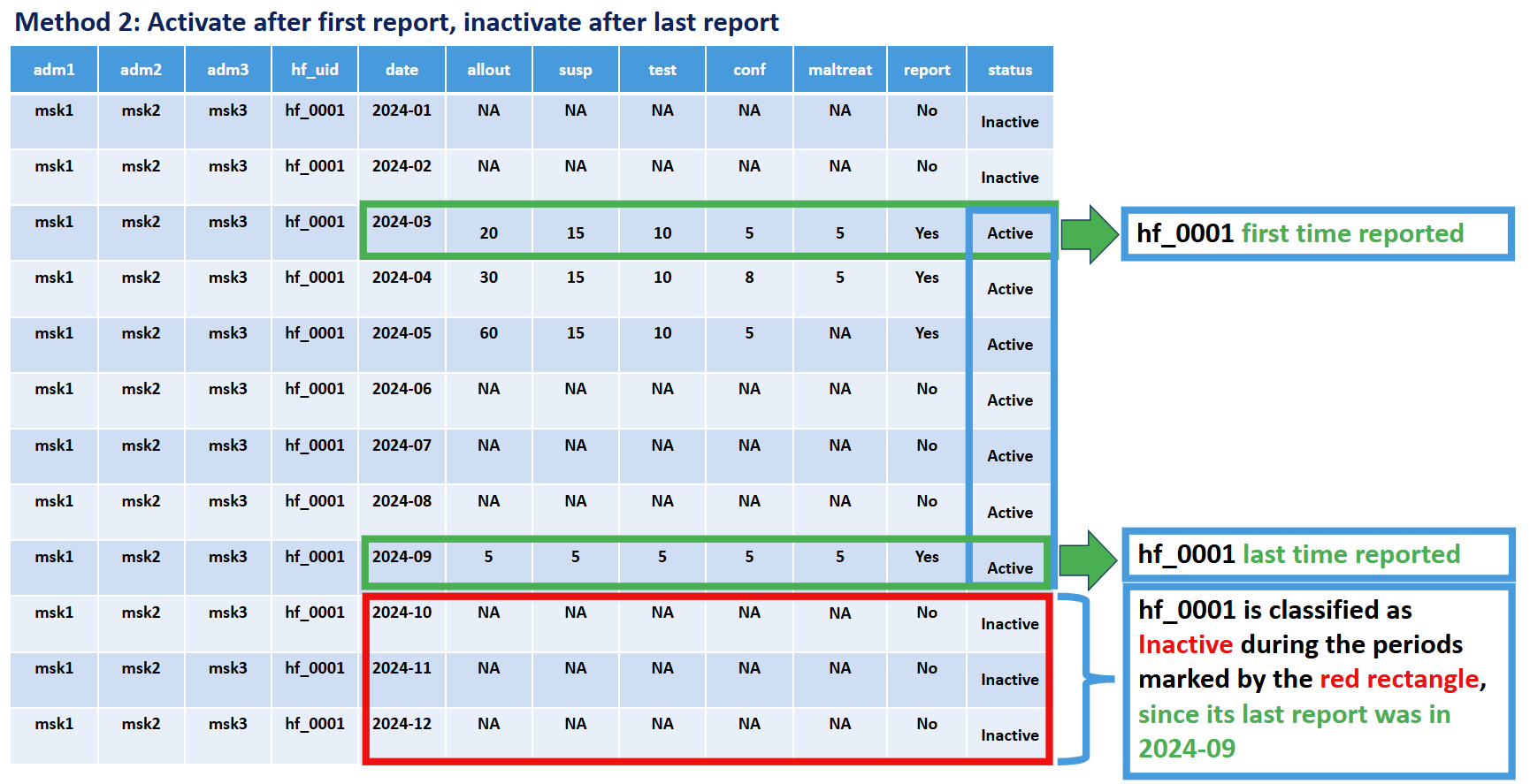
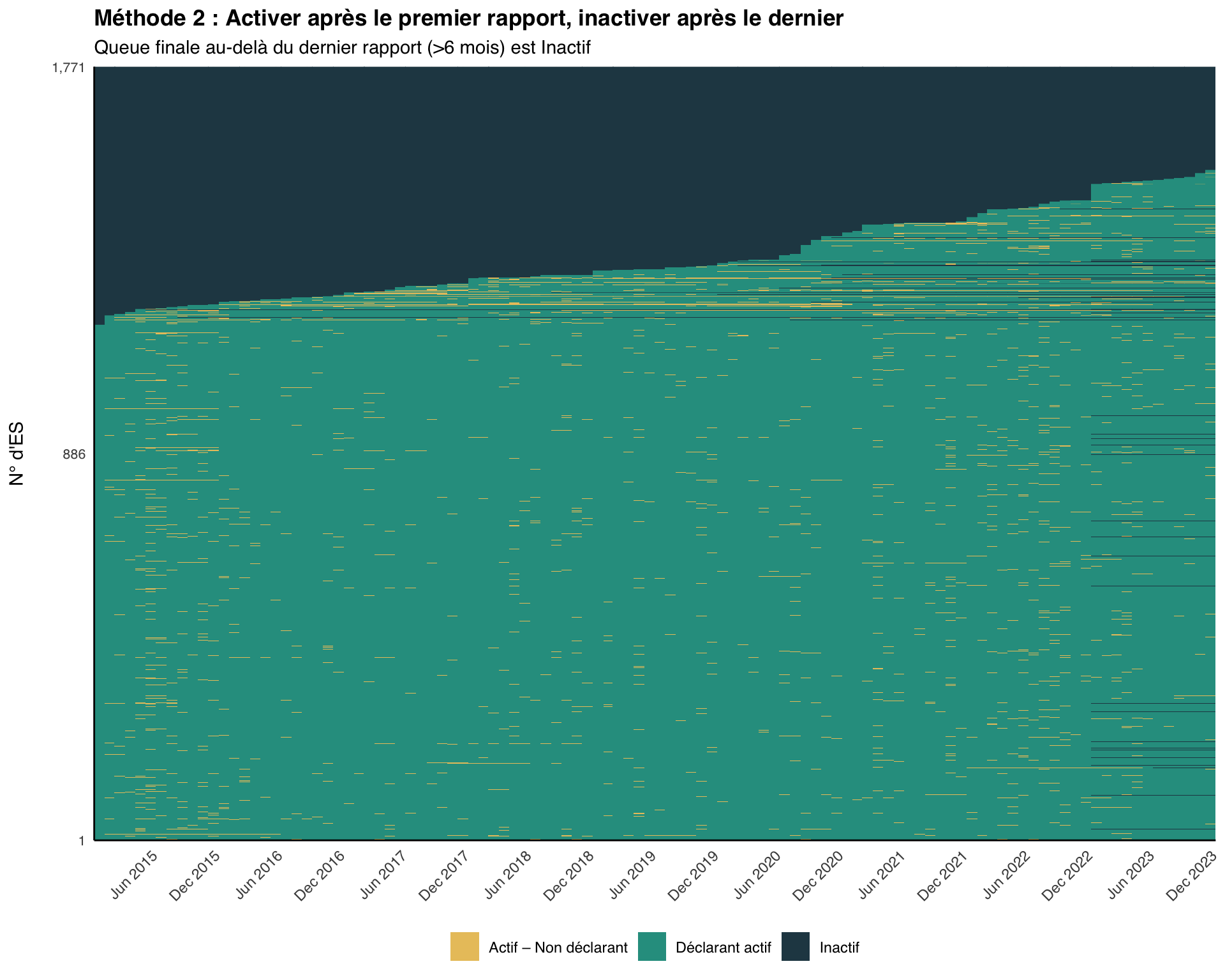
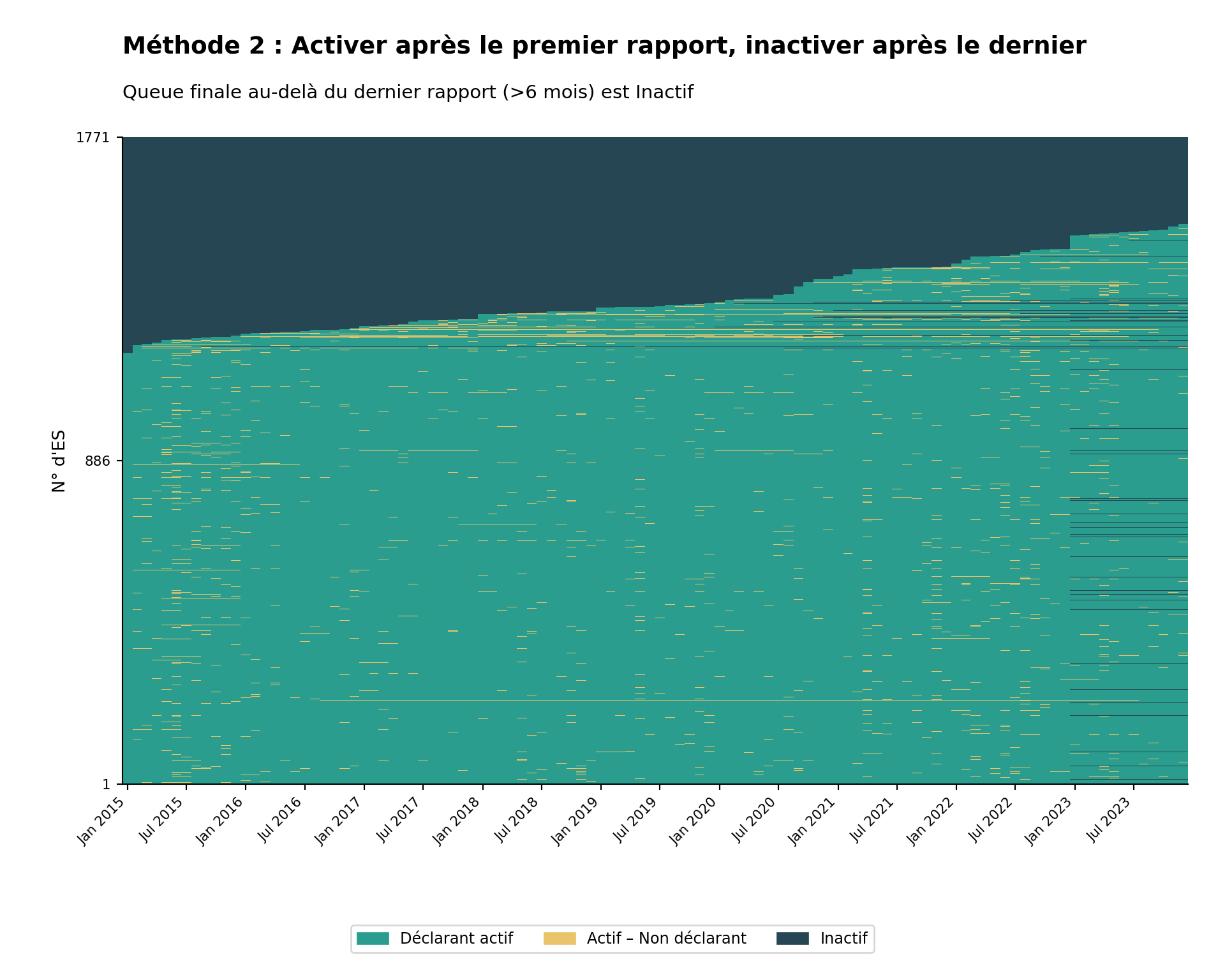
Méthode 2 : Activation premier-au-dernier
Critères : Un établissement est classé comme actif dès qu’il commence à déclarer, et inactif après son dernier rapport. Pour éviter d’attribuer à tort une non-déclaration à une inactivité dans les mois les plus récents du jeu de données, nous exigeons également un nombre minimum de non-déclarations (par défaut : 6 mois) après le dernier rapport avant de le traiter comme Inactif.
Principe clé : Un établissement est inclus dans le dénominateur (censé déclarer) pour un mois donné s’il a déjà déclaré, et exclu seulement après avoir cessé de déclarer et que le panel s’est prolongé au-delà de la période de grâce.
Justification : Cette méthode reconnaît que les établissements peuvent fermer définitivement, par exemple en raison d’une insécurité, d’une diminution de la population locale ou d’une réduction des ressources de prestation de services. Elle évite de sous-estimer les performances de déclaration en n’évaluant les établissements que pendant les périodes où ils ont démontré la capacité à déclarer.
Illustration :
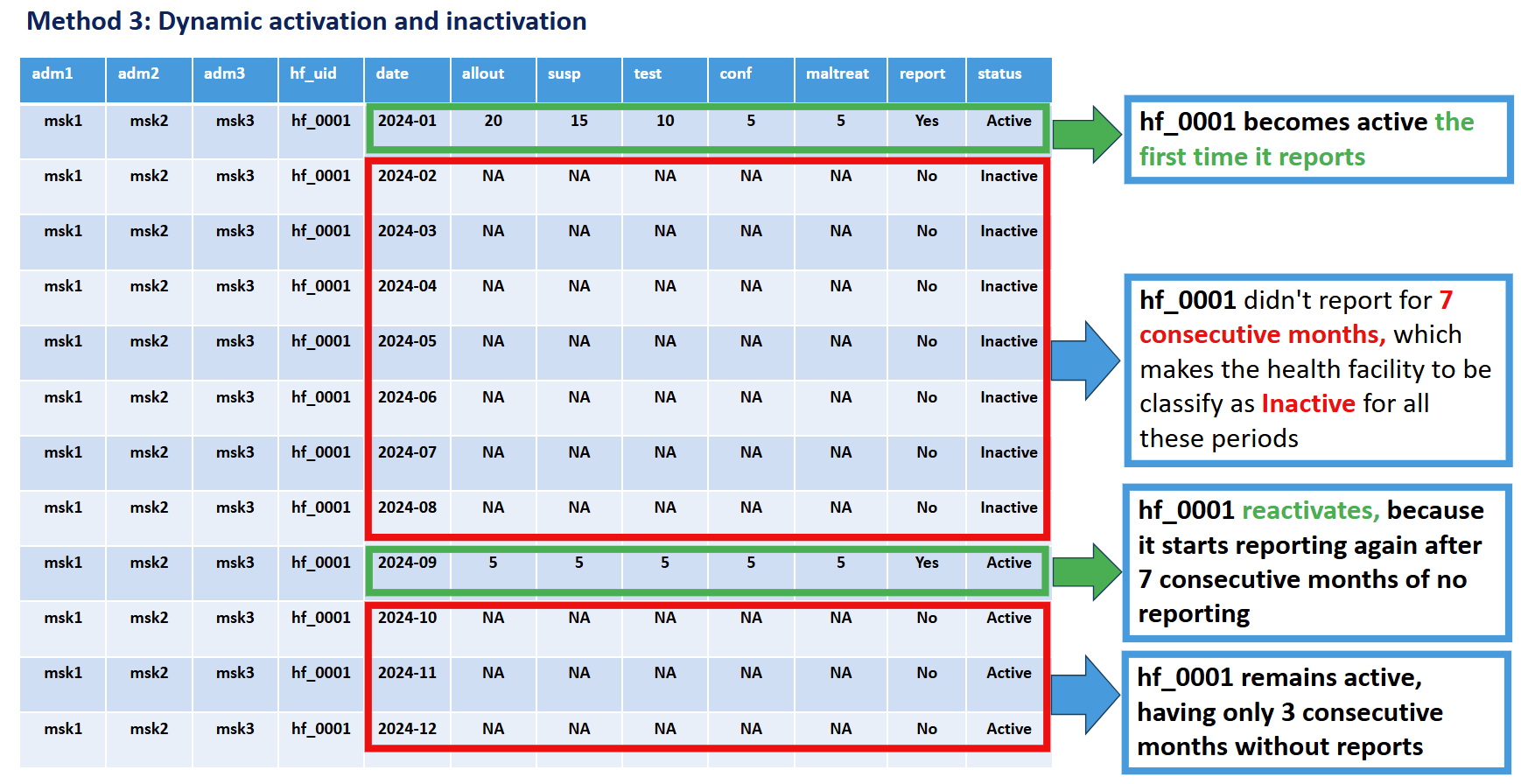
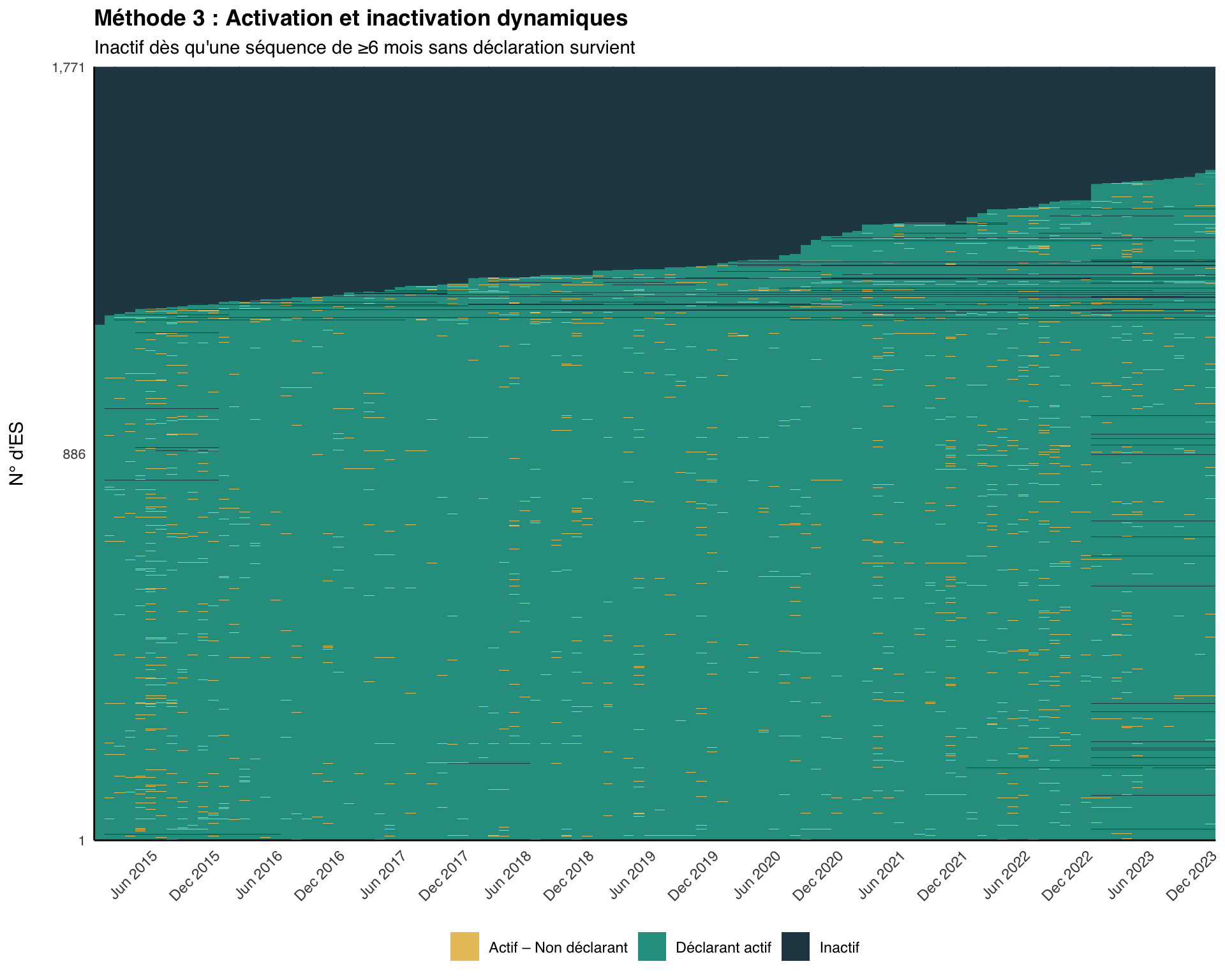
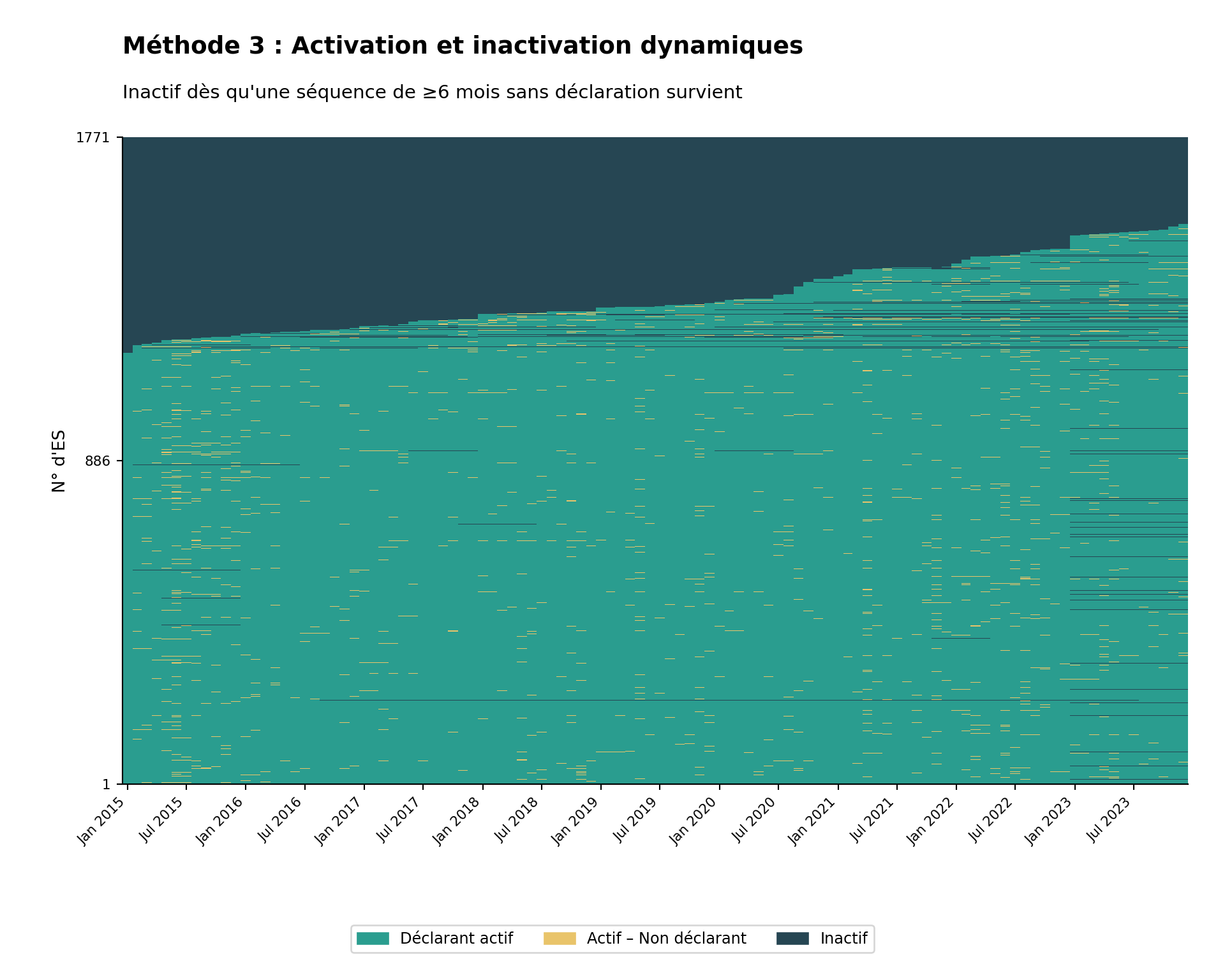
Méthode 3 : Longueur de séquence dynamique
Critères : Un établissement est classé comme actif dès qu’il commence à déclarer, et inactif chaque fois qu’une séquence continue de non-déclaration atteint une longueur minimale configurée (par défaut : 6 mois). Toute la séquence est marquée Inactif, et l’établissement se réactive la prochaine fois qu’il déclare.
Principe clé : Un établissement est exclu du dénominateur (censé déclarer) pour chaque mois appartenant à une séquence de non-déclaration d’au moins N mois. La taille de la fenêtre (N) peut être configurée selon les exigences du programme.
Justification : Cette méthode reconnaît que les établissements peuvent connaître des interruptions temporaires de fonctionnement dues à des facteurs opérationnels tels que des pénuries de personnel, des problèmes d’équipement, une inaccessibilité due à des catastrophes naturelles ou à l’insécurité. L’établissement peut retrouver une activité dans le futur lorsque ces facteurs changent, puis redevenir inactif à nouveau. Elle fournit une évaluation dynamique qui équilibre la réalité opérationnelle avec la responsabilité. Il n’est pas normal qu’un établissement change fréquemment de statut actif à inactif ; si ce schéma apparaît lors de l’utilisation de la Méthode 3, envisagez d’allonger la taille de la fenêtre ou de passer à la Méthode 2.
Illustration :
| Aspect de comparaison | Méthode 1 | Méthode 2 | Méthode 3 |
|---|---|---|---|
| Critères d'activation | Premier rapport reçu | Premier rapport reçu | Premier rapport reçu |
| Critères d'inactivation | Jamais (une fois actif, toujours actif) | Après le dernier rapport + période de grâce (ex. 6 mois) | Dès qu'une séquence de non-déclaration atteint N mois |
| Statut de l'établissement | Binaire : inactif → actif permanent | Binaire : inactif → actif → inactif permanent | Dynamique : peut alterner entre actif/inactif plusieurs fois |
| Gère les fermetures temporaires | Non | Non | Oui |
| Gère les fermetures permanentes | Non | Oui | Oui |
| Exigences en données | Données historiques minimales | Données historiques complètes de préférence | Données de série temporelle complètes |
| Meilleure utilisation quand | Analyse de nouveaux établissements ou phases précoces du programme | Étude de l'attrition/fermetures permanentes des établissements | Surveillance des opérations courantes avec des perturbations temporaires |
| Avantages | Simple à mettre en oeuvre ; dénominateurs stables | Tient compte des sorties permanentes ; évite de pénaliser les établissements fermés | Réaliste pour les contextes opérationnels ; gère les problèmes temporaires |
| Limites | Surestime les établissements actifs au fil du temps | Peut mal classer les établissements temporairement fermés comme définitivement fermés | Plus complexe ; le statut peut fluctuer ; nécessite un réglage des paramètres |
Étape par étape
Dans la suite de cette page, nous construisons chaque méthode étape par étape à l’aide d’un code simplifié, puis nous visualisons le résultat avec une petite fonction de carte thermique réutilisable. Nous utilisons les données DHIS2 nettoyées de Sierra Leone issues de la page de prétraitement DHIS2. Nous terminons par des vues par unité administrative et une comparaison diagnostique des trois méthodes.
Étape 1 : Charger les paquets et les données
Étape 1.1 : Charger les paquets R requis
Pour adapter le code :
- Ne rien modifier dans le code ci-dessus
import pandas as pd # manipulation des données
import numpy as np # opérations numériques
import matplotlib.pyplot as plt # tracé de graphiques
import matplotlib.dates as mdates
import matplotlib.patches as mpatches
from pathlib import Path
from pyprojroot import here # chemins de fichiers reproductibles
# assistants cli — définis une fois, réutilisés à chaque étape
def cli_header(message):
print(f"\n{message}")
def cli_info(message):
print(f"INFO: {message}")
def cli_success(message):
print(f"SUCCESS: {message}")
def cli_warning(message):
print(f"WARNING: {message}")
def cli_danger(message):
print(f"ERROR: {message}")Pour adapter le code :
- Ne rien modifier dans le code ci-dessus
Étape 1.2 : Importer les données
Charger les données de routine sur le paludisme prétraitées exportées par l’étape d’importation (clean_malaria_routine_data_final.parquet) et s’assurer que la colonne date est un objet Date valide.
Pour adapter le code :
- Lignes 2-6 : Ajuster les composantes du chemin si vos données sont stockées ailleurs
import pandas as pd
from pathlib import Path
from pyprojroot import here
# charger les données de routine sur le paludisme prétraitées
df = pd.read_parquet(
Path(here(
"01_data/1.2_epidemiology/1.2a_routine_surveillance/processed/"
"clean_malaria_routine_data_final.parquet"
))
)
# s'assurer que la colonne date est un objet datetime valide
df["date"] = pd.to_datetime(df["date"])Pour adapter le code :
- Ligne 6 : Ajuster le chemin si vos données sont stockées ailleurs
Étape 2 : Construire le panel équilibré
Les extractions DHIS2 du monde réel manquent souvent de lignes pour les établissements qui n’existaient pas (ou n’étaient pas encore dans DHIS2) certains mois. Pour classifier le statut d’activité de façon cohérente, nous commençons par élargir les données en un panel équilibré (chaque établissement associé à chaque mois entre la première et la dernière date du jeu de données) et nous traitons toute paire établissement-mois manquante comme un mois sans déclaration. Ensuite, nous indiquons si chaque paire a déclaré un indicateur clé et enregistrons la première et la dernière date de déclaration de chaque établissement ainsi que la dernière date globale du panel. Les trois méthodes réutilisent ces colonnes.
# indicateurs clés signalant la prestation de services contre le paludisme
key_indicators <- c("allout", "test", "pres", "conf", "maltreat", "maladm")
# fenêtre de grâce / d'inactivation dynamique par défaut (mois)
nonreport_window <- 6L
# (1) construire un panel équilibré (établissement × mois) et remplir les
# métadonnées manquantes
month_seq <- seq(min(df$date), max(df$date), by = "month")
panel <- tidyr::expand_grid(
hf_uid = unique(df$hf_uid),
date = month_seq
)
df <- df |>
dplyr::right_join(panel, by = c("hf_uid", "date")) |>
dplyr::arrange(hf_uid, date) |>
dplyr::group_by(hf_uid) |>
tidyr::fill(adm0, adm1, adm2, adm3, .direction = "downup") |>
dplyr::ungroup()
# (2) indicateur de déclaration au niveau de la ligne : cet établissement-mois
# a-t-il déclaré un indicateur ?
df <- df |>
dplyr::mutate(
reported_any = dplyr::if_any(
dplyr::all_of(key_indicators),
~ !is.na(.x)
)
)
# (3) dates de première / dernière déclaration par établissement et dernière
# date du panel
# (utiliser if/else, pas dplyr::if_else, pour que min/max ne soient pas évalués
# sur les établissements qui n'ont jamais déclaré — évite les avertissements "no
# non-missing arguments to min")
df <- df |>
dplyr::arrange(hf_uid, date) |>
dplyr::group_by(hf_uid) |>
dplyr::mutate(
first_rep = if (any(reported_any)) min(date[reported_any]) else as.Date(NA),
last_rep = if (any(reported_any)) max(date[reported_any]) else as.Date(NA),
last_date = max(date)
) |>
dplyr::ungroup()Pour adapter le code :
- Ligne 2 : Remplacer
key_indicatorspar les colonnes que votre programme considère comme indicateurs de déclaration - Ligne 5 : Ajuster
nonreport_windowpour correspondre à la période de grâce préférée de votre pays (mois) - Ligne 19 : Ajuster les colonnes de métadonnées remplies au sein des groupes d’établissements si vos données utilisent des noms de colonnes administratives différents
import pandas as pd
import numpy as np
# indicateurs clés signalant la prestation de services contre le paludisme
key_indicators = ["allout", "test", "pres", "conf", "maltreat", "maladm"]
# fenêtre de grâce / d'inactivation dynamique par défaut (mois)
nonreport_window = 6
# (1) construire un panel équilibré (établissement × mois) et remplir les
# métadonnées manquantes
month_seq = pd.date_range(df["date"].min(), df["date"].max(), freq="MS")
panel = pd.MultiIndex.from_product(
[df["hf_uid"].unique(), month_seq],
names=["hf_uid", "date"]
).to_frame(index=False)
df = (
panel.merge(df, on=["hf_uid", "date"], how="left")
.sort_values(["hf_uid", "date"])
)
# remplissage avant puis arrière des métadonnées administratives au sein de chaque groupe d'établissements
meta_cols = ["adm0", "adm1", "adm2", "adm3"]
df[meta_cols] = (
df.groupby("hf_uid")[meta_cols]
.transform(lambda s: s.ffill().bfill())
)
# (2) indicateur de déclaration au niveau de la ligne : cet établissement-mois
# a-t-il déclaré un indicateur ?
# ajouter les colonnes d'indicateurs clés manquantes en NaN pour que le prédicat utilise les mêmes
# six colonnes que dplyr::if_any(dplyr::all_of(key_indicators), ~!is.na(.x)) en R
for _col in key_indicators:
if _col not in df.columns:
df[_col] = np.nan
df = df.assign(
reported_any=lambda d: d[key_indicators].notna().any(axis=1)
)
# (3) dates de première / dernière déclaration par établissement et dernière
# date du panel
def facility_dates(g):
mask = g["reported_any"]
g = g.copy()
if mask.any():
g["first_rep"] = g.loc[mask, "date"].min()
g["last_rep"] = g.loc[mask, "date"].max()
else:
g["first_rep"] = pd.NaT
g["last_rep"] = pd.NaT
g["last_date"] = g["date"].max()
return g
df = (
df.sort_values(["hf_uid", "date"])
.groupby("hf_uid", group_keys=False)
.apply(facility_dates)
.reset_index(drop=True)
)Pour adapter le code :
- Ligne 5 : Remplacer
key_indicatorspar les colonnes que votre programme considère comme indicateurs de déclaration - Ligne 8 : Ajuster
nonreport_windowpour correspondre à la période de grâce préférée de votre pays (mois) - Ligne 24 : Ajuster les colonnes de métadonnées remplies au sein des groupes d’établissements si vos données utilisent des noms de colonnes administratives différents
Étape 3 : Fonction de carte thermique
Définir une petite fonction ggplot que nous réutiliserons pour toutes les visualisations des trois méthodes. Elle prend un tableau de données classifié et une colonne de statut, ordonne les établissements par date de première déclaration et produit une carte thermique en tuiles avec la palette forestière à 3 états (vert-teal = Déclarant actif, ambre = Actif – Non déclarant, bleu marine foncé = Inactif).
Afficher le code
plot_activity_heatmap <- function(
data,
status_col,
hf_col = "hf_uid",
date_col = "date",
title = NULL,
subtitle = NULL,
facet_col = NULL,
facet_ncol = 4
) {
# palette forestière à 3 états : vert-teal / ambre / bleu marine foncé
status_colours <- c(
"Déclarant actif" = "#2A9D8F", # vert-teal : opérationnel
"Actif – Non déclarant" = "#E9C46A", # ambre : opérationnel mais silencieux
"Inactif" = "#264653" # bleu marine foncé : non opérationnel
)
# ordonner les établissements par date de première déclaration pour un
# balayage visuel propre
facility_order <- data |>
dplyr::distinct(.data[[hf_col]], first_rep) |>
dplyr::arrange(first_rep) |>
dplyr::pull(.data[[hf_col]])
data <- data |>
dplyr::mutate(
.hf_ordered = forcats::fct_relevel(
as.character(.data[[hf_col]]),
!!!as.character(facility_order)
)
)
# afficher uniquement le premier / milieu / dernier numéro d'établissement
# sur l'axe y
n_hf <- length(facility_order)
if (n_hf >= 3) {
y_breaks <- facility_order[c(1, ceiling(n_hf / 2), n_hf)]
y_labels <- scales::comma(c(1, ceiling(n_hf / 2), n_hf))
} else {
y_breaks <- facility_order
y_labels <- scales::comma(seq_len(n_hf))
}
p <- ggplot2::ggplot(
data,
ggplot2::aes(
x = .data[[date_col]],
y = .hf_ordered,
fill = .data[[status_col]]
)
) +
ggplot2::geom_tile(width = 31, height = 1) +
ggplot2::scale_fill_manual(
values = status_colours,
na.value = "white",
name = NULL
) +
ggplot2::scale_x_date(
expand = c(0, 0),
date_breaks = "6 months",
date_labels = "%b %Y"
) +
ggplot2::scale_y_discrete(
breaks = y_breaks,
labels = y_labels
) +
ggplot2::labs(
x = NULL,
y = "N° d'ES\n",
title = title,
subtitle = subtitle
) +
ggplot2::theme_minimal(base_family = "sans") +
ggplot2::theme(
axis.text.x = ggplot2::element_text(angle = 45, hjust = 1),
axis.text.y = ggplot2::element_text(size = 8),
axis.line = ggplot2::element_line(color = "black", linewidth = 0.5),
legend.position = "bottom",
legend.direction = "horizontal",
plot.title = ggplot2::element_text(face = "bold")
)
if (!is.null(facet_col)) {
p <- p +
ggplot2::facet_wrap(
ggplot2::vars(.data[[facet_col]]),
scales = "free_y",
ncol = facet_ncol
)
}
p
}Pour adapter le code :
- Lignes 13–17 : Modifier
status_colourspour correspondre à la palette de votre projet - Dernier argument lors de l’appel : Passer
facet_col = "adm1"pour diviser la carte thermique par unité administrative
Afficher le code
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import matplotlib.patches as mpatches
from matplotlib.collections import PatchCollection
import numpy as np
def plot_activity_heatmap(
data,
status_col,
hf_col="hf_uid",
date_col="date",
title=None,
subtitle=None,
facet_col=None,
facet_ncol=4
):
# palette forestière à 3 états : vert-teal / ambre / bleu marine foncé
status_colours = {
"Déclarant actif": "#2A9D8F", # vert-teal : opérationnel
"Actif – Non déclarant": "#E9C46A", # ambre : opérationnel mais silencieux
"Inactif": "#264653", # bleu marine foncé : non opérationnel
}
colour_map = dict(status_colours)
def _draw_panel(ax, subset, title_text=None):
subset = subset.copy()
# ordonner les établissements de ce panel par date de première déclaration,
# en reproduisant facet_wrap(scales = "free_y") pour que chaque panel remplisse son propre axe y
order = (
subset[[hf_col, "first_rep"]]
.drop_duplicates()
.sort_values("first_rep")
[hf_col]
.tolist()
)
rank = {hf: i for i, hf in enumerate(order)}
n = len(order)
subset["_y"] = subset[hf_col].map(rank)
subset["_c"] = subset[status_col].map(colour_map).fillna("white")
# dessiner chaque paire établissement-mois comme une tuile remplie, correspondant à geom_tile :
# 31 jours de large, 1 rangée de haut, centré sur la date et le rang de l'établissement
x = mdates.date2num(subset[date_col])
tiles = [
mpatches.Rectangle((xi - 15.5, yi - 0.5), 31, 1)
for xi, yi in zip(x, subset["_y"])
]
ax.add_collection(
PatchCollection(
tiles,
facecolors=subset["_c"].tolist(),
edgecolors="none",
)
)
ax.set_xlim(x.min() - 15.5, x.max() + 15.5)
ax.set_ylim(-0.5, n - 0.5)
# graduations de l'axe y : premier / milieu / dernier établissement de ce panel
if n >= 3:
tick_positions = [0, (n - 1) // 2, n - 1]
tick_labels = [str(1), str((n - 1) // 2 + 1), str(n)]
else:
tick_positions = list(range(n))
tick_labels = [str(i + 1) for i in range(n)]
# axe x : graduations semestrielles
ax.xaxis.set_major_locator(mdates.MonthLocator(bymonth=[1, 7]))
ax.xaxis.set_major_formatter(mdates.DateFormatter("%b %Y"))
plt.setp(ax.get_xticklabels(), rotation=45, ha="right", fontsize=8)
# axe y : étiquettes de rang des établissements
ax.set_yticks(tick_positions)
ax.set_yticklabels(tick_labels, fontsize=8)
ax.set_ylabel("N° d'ES")
ax.spines["top"].set_visible(False)
ax.spines["right"].set_visible(False)
ax.set_xlabel("")
if title_text:
ax.set_title(title_text, fontsize=9, pad=4)
# poignées de légende partagées (une teinte par statut)
legend_handles = [
mpatches.Patch(color=v, label=k)
for k, v in status_colours.items()
]
if facet_col is None:
fig, ax = plt.subplots(figsize=(10, 8))
_draw_panel(ax, data)
# réserver des marges pour que le bloc de titre et la légende ne soient jamais coupés
fig.subplots_adjust(top=0.86, bottom=0.20, left=0.10, right=0.97)
x0 = ax.get_position().x0
# titre en gras avec un sous-titre plus léger en dessous, aligné à gauche (style ggplot)
if title:
fig.text(x0, 0.965, title, ha="left", va="top",
fontsize=14, fontweight="bold")
if subtitle:
fig.text(x0, 0.915, subtitle, ha="left", va="top", fontsize=11)
# la légende se trouve bien au-dessus des étiquettes de graduation de l'axe x
fig.legend(handles=legend_handles, loc="lower center", ncol=3,
fontsize=9, bbox_to_anchor=(0.5, 0.02))
else:
groups = sorted(data[facet_col].dropna().unique())
n_groups = len(groups)
n_cols = facet_ncol
n_rows = int(np.ceil(n_groups / n_cols))
fig, axes = plt.subplots(
n_rows, n_cols,
figsize=(4 * n_cols, 3.2 * n_rows)
)
axes_flat = np.array(axes).reshape(-1)
for idx, grp in enumerate(groups):
_draw_panel(axes_flat[idx], data[data[facet_col] == grp], str(grp))
for ax in axes_flat[n_groups:]:
ax.set_visible(False)
fig.subplots_adjust(top=0.93, bottom=0.14, left=0.08, right=0.97,
hspace=0.75, wspace=0.28)
x0 = axes_flat[0].get_position().x0
if title:
fig.text(x0, 0.985, title, ha="left", va="top",
fontsize=15, fontweight="bold")
if subtitle:
fig.text(x0, 0.965, subtitle, ha="left", va="top", fontsize=12)
# la légende se trouve bien au-dessus des étiquettes de graduation de la dernière rangée
fig.legend(handles=legend_handles, loc="lower center", ncol=3,
fontsize=10, bbox_to_anchor=(0.5, 0.02))
return figPour adapter le code :
- Lignes 18–22 : Modifier
status_colourspour correspondre à la palette de votre projet - Dernier argument lors de l’appel : Passer
facet_col="adm1"pour diviser la carte thermique par unité administrative
Étape 4 : Méthode 1 — Activation permanente
Étape 4.1 : Appliquer la classification de la Méthode 1
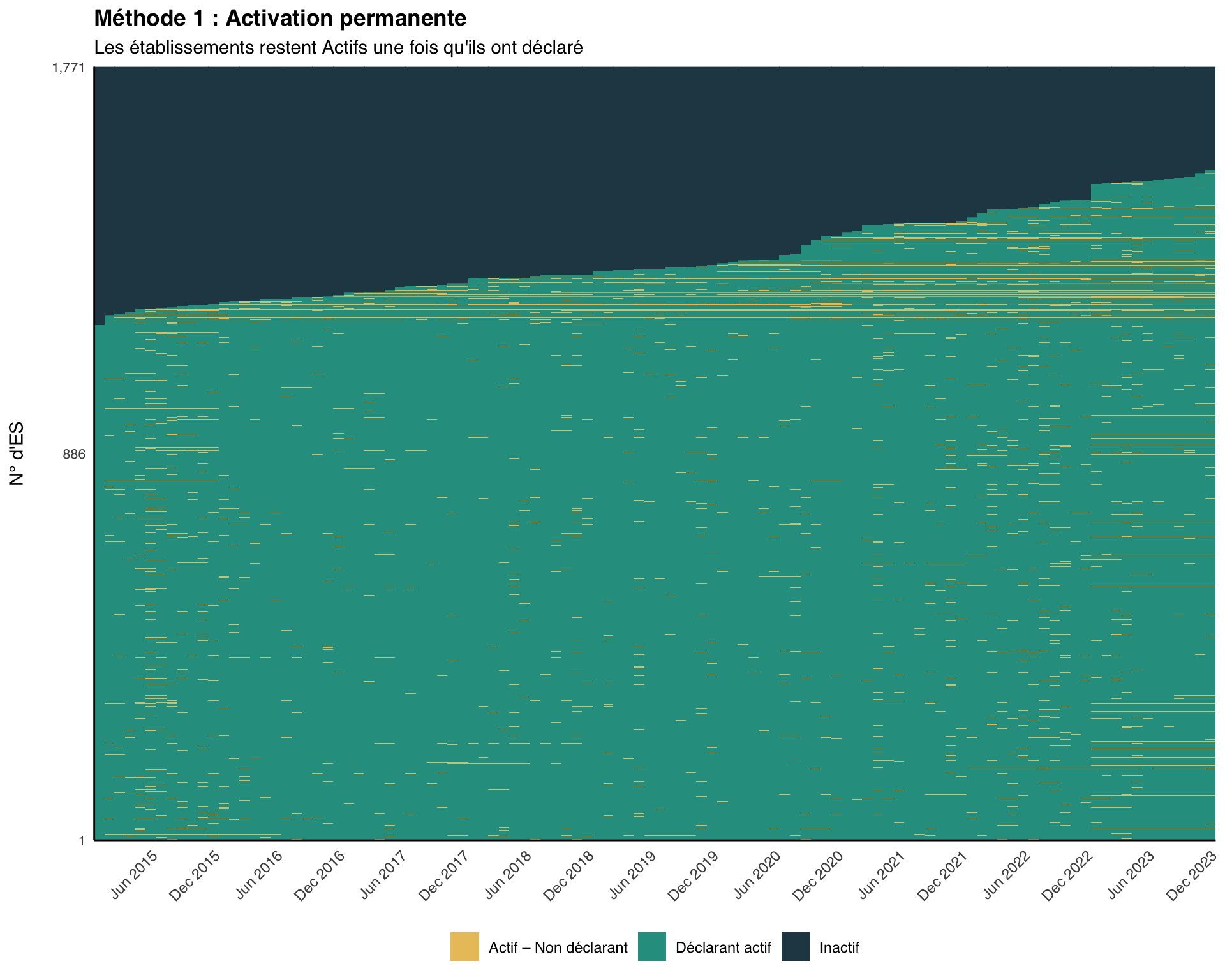
Un établissement devient Actif à partir du mois de son premier rapport et reste Actif pour le reste du panel.
df <- df |>
dplyr::arrange(hf_uid, date) |>
dplyr::group_by(hf_uid) |>
dplyr::mutate(
ever_reported = dplyr::cumany(reported_any),
activity_method1 = dplyr::case_when(
!any(reported_any) ~ "Inactif",
!ever_reported ~ "Inactif",
reported_any ~ "Déclarant actif",
TRUE ~ "Actif – Non déclarant"
)
) |>
dplyr::ungroup()Pour adapter le code :
- Ne rien modifier dans le code ci-dessus
df = df.sort_values(["hf_uid", "date"])
# indicateur cumulatif « a déjà déclaré » au sein de chaque établissement
df["ever_reported"] = (
df.groupby("hf_uid")["reported_any"]
.transform("cummax")
)
# méthode 1 : activation permanente à partir du premier mois de déclaration
df["activity_method1"] = np.select(
[
~df.groupby("hf_uid")["reported_any"].transform("any"),
~df["ever_reported"],
df["reported_any"],
],
[
"Inactif",
"Inactif",
"Déclarant actif",
],
default="Actif – Non déclarant",
)Pour adapter le code :
- Ne rien modifier dans le code ci-dessus
Étape 4.2 : Visualiser la carte thermique de la Méthode 1
NoteSortie
Pour adapter le code :
- Ajouter
facet_col = "adm1"pour diviser la carte thermique par région
Étape 5 : Méthode 2 — Premier-au-dernier
Étape 5.1 : Appliquer la classification de la Méthode 2
Un établissement devient Actif à partir de son premier rapport et reste Actif jusqu’à son dernier rapport. Après le dernier rapport, il reste Actif – Non déclarant jusqu’à ce que le panel se soit prolongé de nonreport_window mois, auquel point il devient Inactif.
df <- df |>
dplyr::arrange(hf_uid, date) |>
dplyr::group_by(hf_uid) |>
dplyr::mutate(
months_since_last = dplyr::if_else(
is.na(last_rep),
Inf,
as.numeric(
lubridate::interval(last_rep, last_date) / lubridate::dmonths(1)
)
),
activity_method2 = dplyr::case_when(
is.na(first_rep) ~ "Inactif",
date < first_rep ~ "Inactif",
reported_any ~ "Déclarant actif",
date <= last_rep ~ "Actif – Non déclarant",
date > last_rep & months_since_last >= nonreport_window ~ "Inactif",
TRUE ~ "Actif – Non déclarant"
)
) |>
dplyr::ungroup()Pour adapter le code :
- Ligne 17 : Modifier la logique de grâce si votre programme préfère une inactivation immédiate après le dernier rapport
df = df.sort_values(["hf_uid", "date"])
# mois entre le dernier rapport d'un établissement et la dernière date du panel
def months_since_last(g):
g = g.copy()
if g["last_rep"].isna().all():
g["months_since_last"] = np.inf
else:
last_rep = g["last_rep"].iloc[0]
last_date = g["last_date"].iloc[0]
# dmonths(1) = 30.4375 jours dans lubridate ; ceci correspond exactement à R
delta_days = (last_date - last_rep).days
g["months_since_last"] = delta_days / 30.4375
return g
df = (
df.groupby("hf_uid", group_keys=False)
.apply(months_since_last)
.reset_index(drop=True)
)
# méthode 2 : premier-au-dernier avec période de grâce
df["activity_method2"] = np.select(
[
df["first_rep"].isna(),
df["date"] < df["first_rep"],
df["reported_any"],
df["date"] <= df["last_rep"],
(df["date"] > df["last_rep"])
& (df["months_since_last"] >= nonreport_window),
],
[
"Inactif",
"Inactif",
"Déclarant actif",
"Actif – Non déclarant",
"Inactif",
],
default="Actif – Non déclarant",
)Pour adapter le code :
- Lignes 29–30 : Modifier la logique de grâce si votre programme préfère une inactivation immédiate après le dernier rapport
Étape 5.2 : Visualiser la carte thermique de la Méthode 2
NoteSortie
Pour adapter le code :
- Ne rien modifier dans le code ci-dessus
NoteSortie
Pour adapter le code :
- Ne rien modifier dans le code ci-dessus
Étape 6 : Méthode 3 — Dynamique
Étape 6.1 : Appliquer la classification de la Méthode 3
L’inactivation est déclenchée chaque fois qu’une séquence continue de non-déclaration atteint nonreport_window mois ; toute la séquence est marquée Inactif, et l’établissement se réactive la prochaine fois qu’il déclare.
df <- df |>
dplyr::arrange(hf_uid, date) |>
dplyr::group_by(hf_uid) |>
dplyr::mutate(
# 1 si ce mois n'a pas déclaré, 0 s'il a déclaré
gap = dplyr::if_else(!reported_any, 1L, 0L),
# un identifiant par séquence consécutive de valeurs gap identiques
gap_run = data.table::rleid(gap),
# longueur de la séquence à laquelle appartient cette ligne (même valeur
# pour toutes les lignes de la séquence)
run_len = stats::ave(gap, gap_run, FUN = length),
activity_method3 = dplyr::case_when(
!any(reported_any) ~ "Inactif",
is.na(first_rep) ~ "Inactif",
date < first_rep ~ "Inactif",
reported_any ~ "Déclarant actif",
gap == 1 & run_len < nonreport_window ~ "Actif – Non déclarant",
gap == 1 & run_len >= nonreport_window ~ "Inactif",
TRUE ~ "Inactif"
)
) |>
dplyr::ungroup()Pour adapter le code :
- Ne rien modifier dans le code ci-dessus
df = df.sort_values(["hf_uid", "date"])
def add_run_length(g):
"""Étiqueter chaque ligne avec la longueur de sa séquence de lacune consécutive."""
g = g.copy()
# 1 si l'établissement n'a pas déclaré ce mois, 0 s'il a déclaré
g["gap"] = (~g["reported_any"]).astype(int)
# identifiant de séquence consécutive (incrémente à chaque changement de gap)
g["gap_run"] = (g["gap"] != g["gap"].shift()).cumsum()
# longueur de chaque séquence (même valeur pour toutes les lignes de la même séquence)
g["run_len"] = g.groupby("gap_run")["gap"].transform("count")
return g
df = (
df.groupby("hf_uid", group_keys=False)
.apply(add_run_length)
.reset_index(drop=True)
)
# méthode 3 : activation dynamique — inactiver toute séquence de ≥ nonreport_window mois
never_reported = ~df.groupby("hf_uid")["reported_any"].transform("any")
df["activity_method3"] = np.select(
[
never_reported,
df["first_rep"].isna(),
df["date"] < df["first_rep"],
df["reported_any"],
(df["gap"] == 1) & (df["run_len"] < nonreport_window),
(df["gap"] == 1) & (df["run_len"] >= nonreport_window),
],
[
"Inactif",
"Inactif",
"Inactif",
"Déclarant actif",
"Actif – Non déclarant",
"Inactif",
],
default="Inactif",
)Pour adapter le code :
- Ne rien modifier dans le code ci-dessus
Étape 6.2 : Visualiser la carte thermique de la Méthode 3
NoteSortie
Pour adapter le code :
- Ne rien modifier dans le code ci-dessus
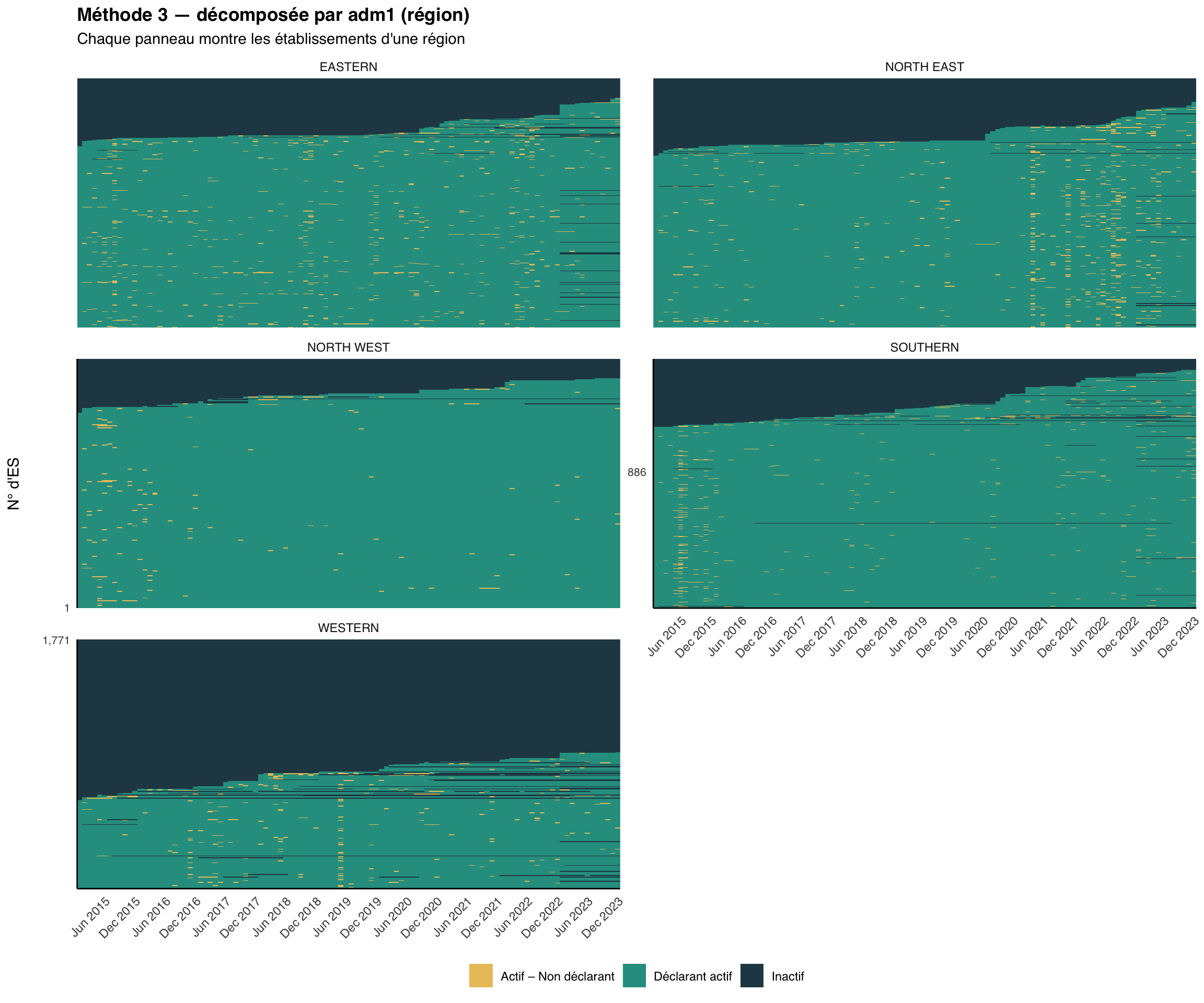
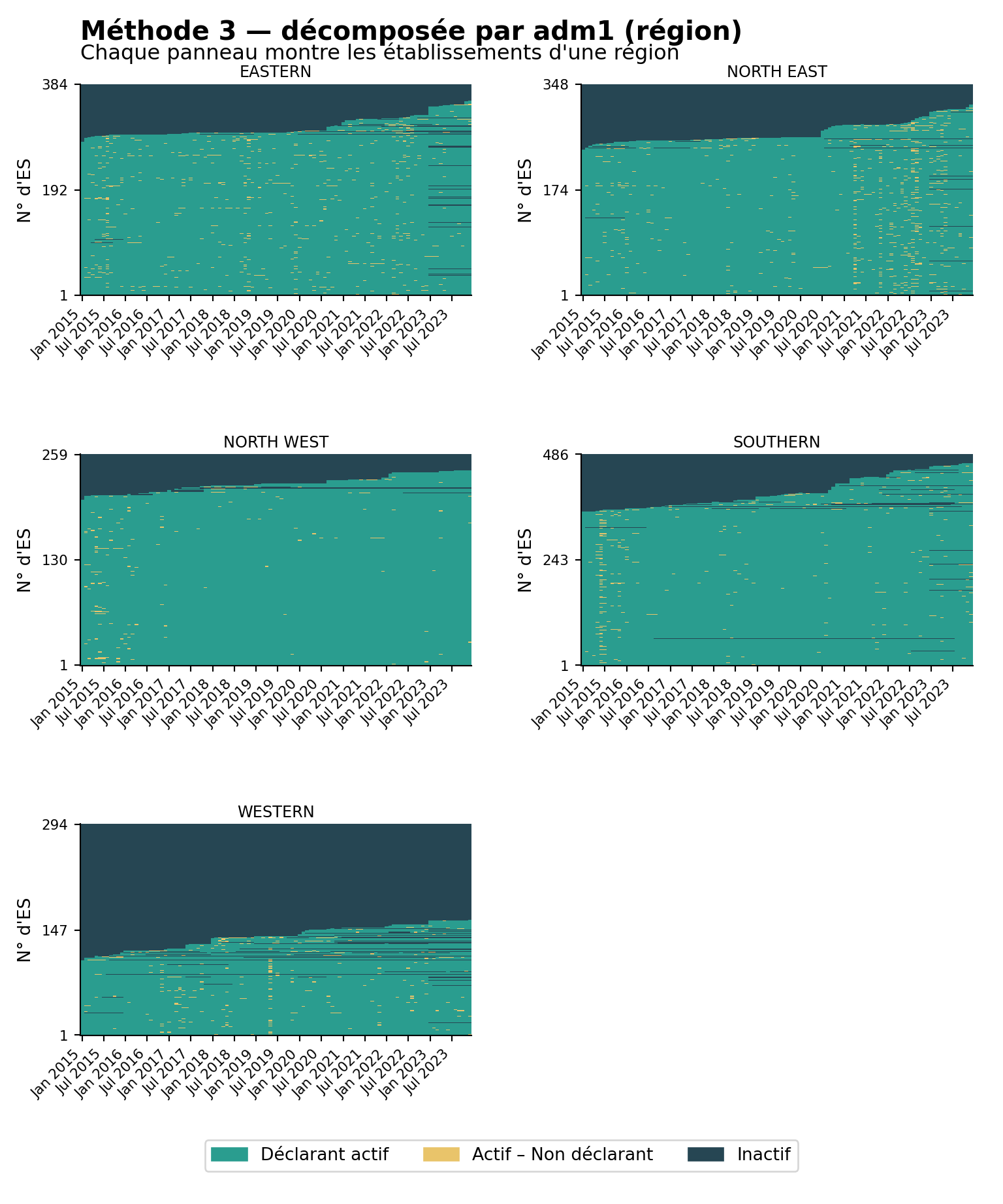
Étape 7 : Cartes thermiques par unité administrative
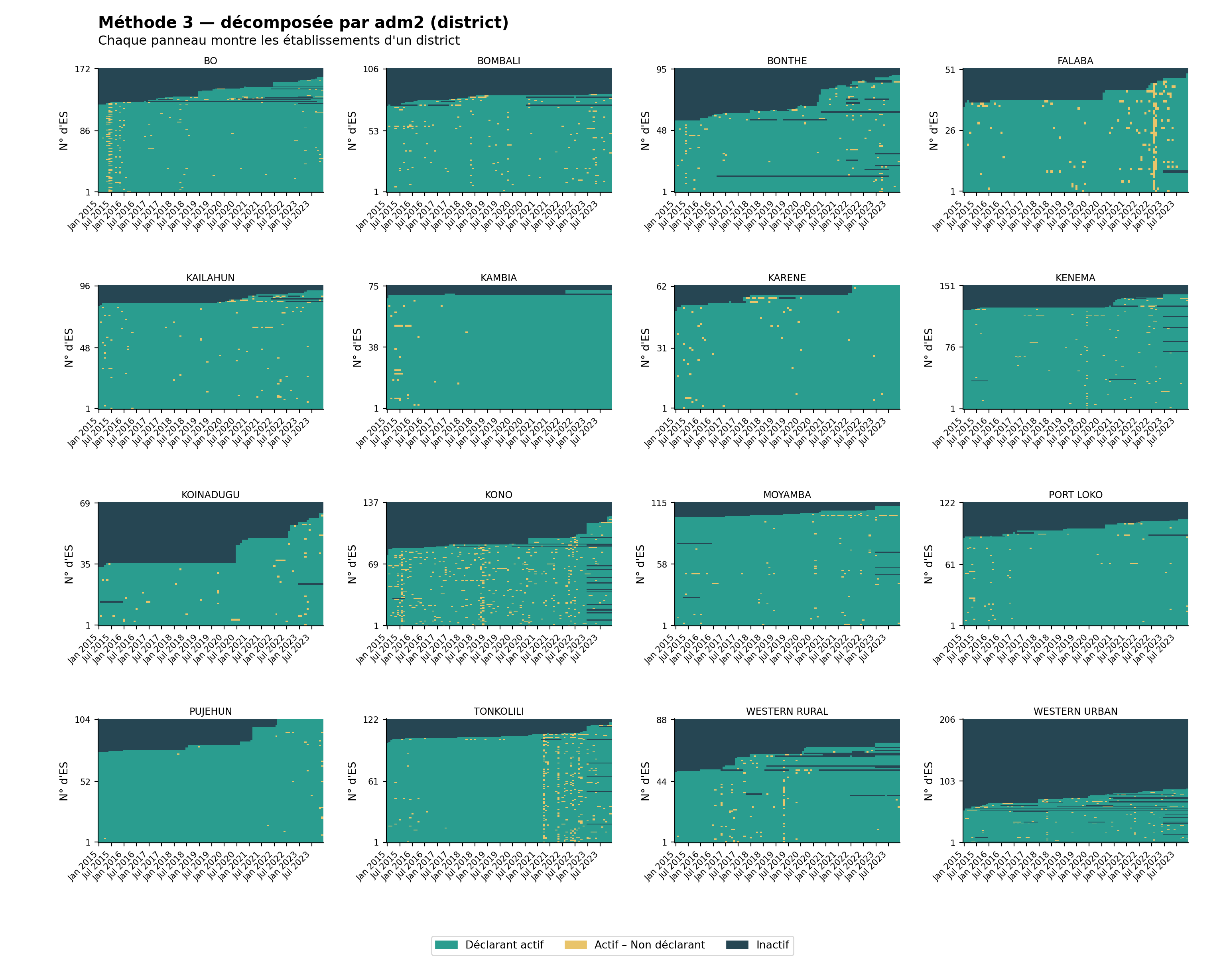
La même fonction prend en charge la décomposition en facettes. Diviser la carte thermique par adm1 (région) puis par adm2 (district) est utile pour repérer si les lacunes de déclaration sont concentrées dans des zones géographiques particulières, un schéma courant lorsque des chocs d’accès ou de sécurité affectent une seule zone. Les visualisations ci-dessous utilisent la classification de la Méthode 3 (la plus stricte des trois), décomposée en facettes à deux niveaux administratifs.
# décomposition par adm1 (région)
plot_activity_heatmap(
data = df,
status_col = "activity_method3",
facet_col = "adm1",
facet_ncol = 2,
title = "Méthode 3 — décomposée par adm1 (région)",
subtitle = "Chaque panneau montre les établissements d'une région"
)
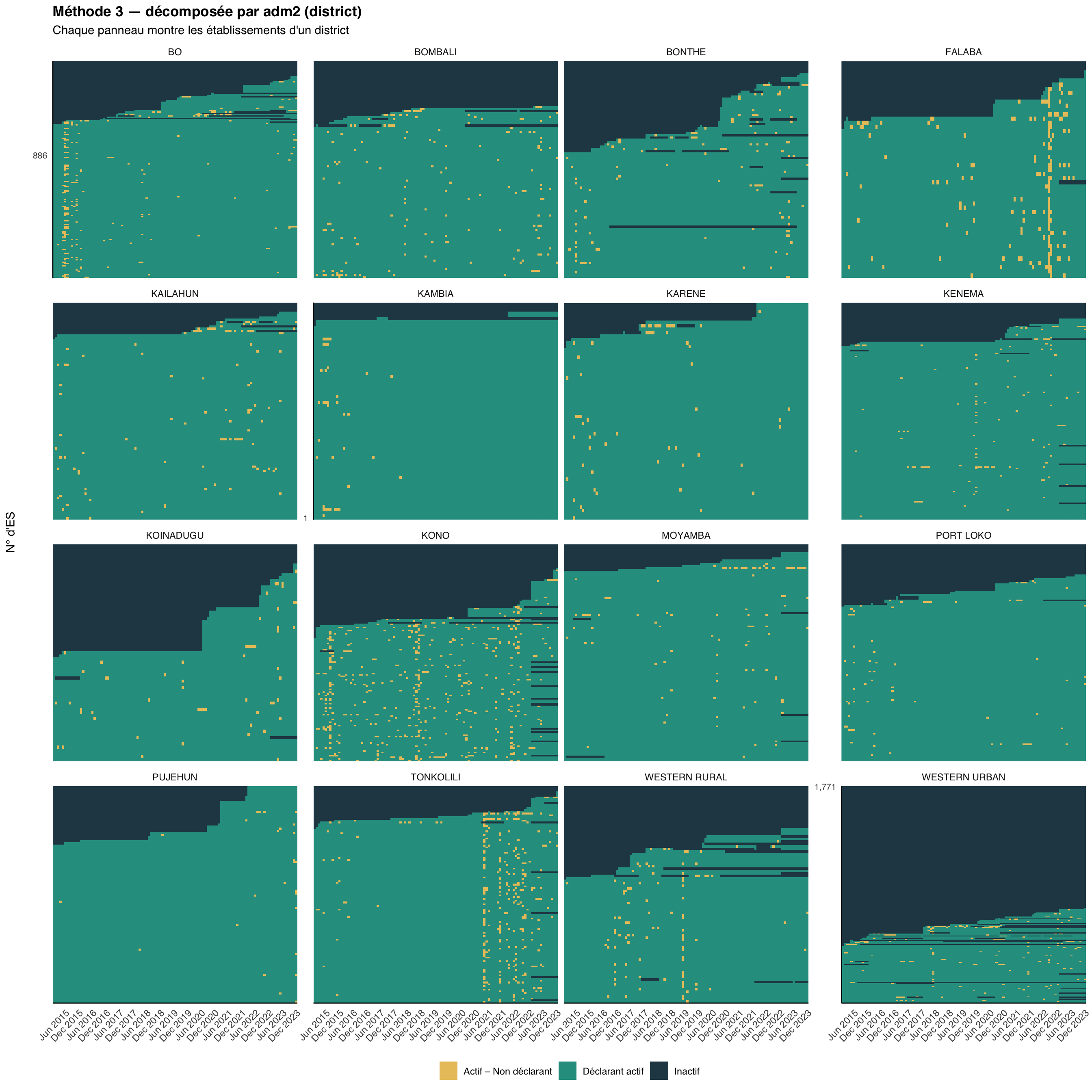
# décomposition par adm2 (district)
plot_activity_heatmap(
data = df,
status_col = "activity_method3",
facet_col = "adm2",
facet_ncol = 4,
title = "Méthode 3 — décomposée par adm2 (district)",
subtitle = "Chaque panneau montre les établissements d'un district"
)
NoteSortie — par adm1
NoteSortie — par adm2
Pour adapter le code :
status_col: Remplacer par"activity_method1"ou"activity_method2"pour décomposer une classification différentefacet_col: Toute colonne dedfpeut être utilisée (ex.,"adm3","hf_type")facet_ncol: Ajuster la disposition de la grille de panneaux
# décomposition par adm1 (région)
plot_activity_heatmap(
data=df,
status_col="activity_method3",
facet_col="adm1",
facet_ncol=2,
title="Méthode 3 — décomposée par adm1 (région)",
subtitle="Chaque panneau montre les établissements d'une région",
)
# décomposition par adm2 (district)
plot_activity_heatmap(
data=df,
status_col="activity_method3",
facet_col="adm2",
facet_ncol=4,
title="Méthode 3 — décomposée par adm2 (district)",
subtitle="Chaque panneau montre les établissements d'un district",
)
NoteSortie — par adm1
NoteSortie — par adm2
Pour adapter le code :
status_col: Remplacer par"activity_method1"ou"activity_method2"pour décomposer une classification différentefacet_col: Toute colonne dedfpeut être utilisée (ex.,"adm3","hf_type")facet_ncol: Ajuster la disposition de la grille de panneaux
La carte thermique nationale montre combien il y a de non-déclarations ; les vues décomposées montrent où elles sont concentrées. Les problèmes de déclaration se regroupent généralement autour de chocs (insécurité, ruptures de stock, accès DHIS2) qui touchent des régions ou des districts spécifiques plutôt que l’ensemble du pays à la fois. Recherchez des bandes ambre verticales (une perturbation à l’échelle du système un mois donné), des districts entiers dominés par le bleu marine foncé (un problème structurel dans cette zone) et des districts qui semblent sains au niveau adm1 mais révèlent des zones fragiles une fois décomposés au niveau adm2 ; inspectez toujours au niveau auquel les décisions seront prises.
Étape 8 : Comparer les méthodes
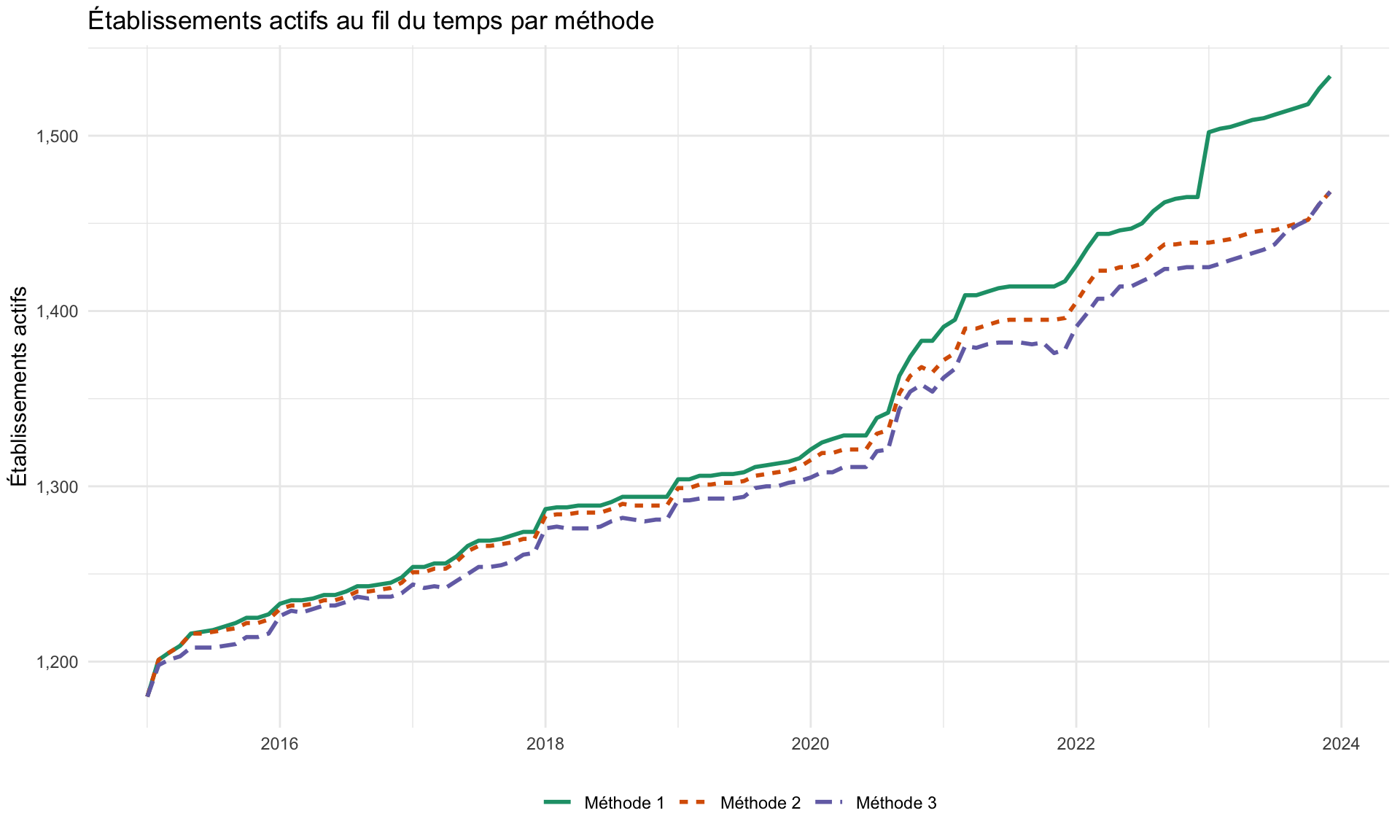
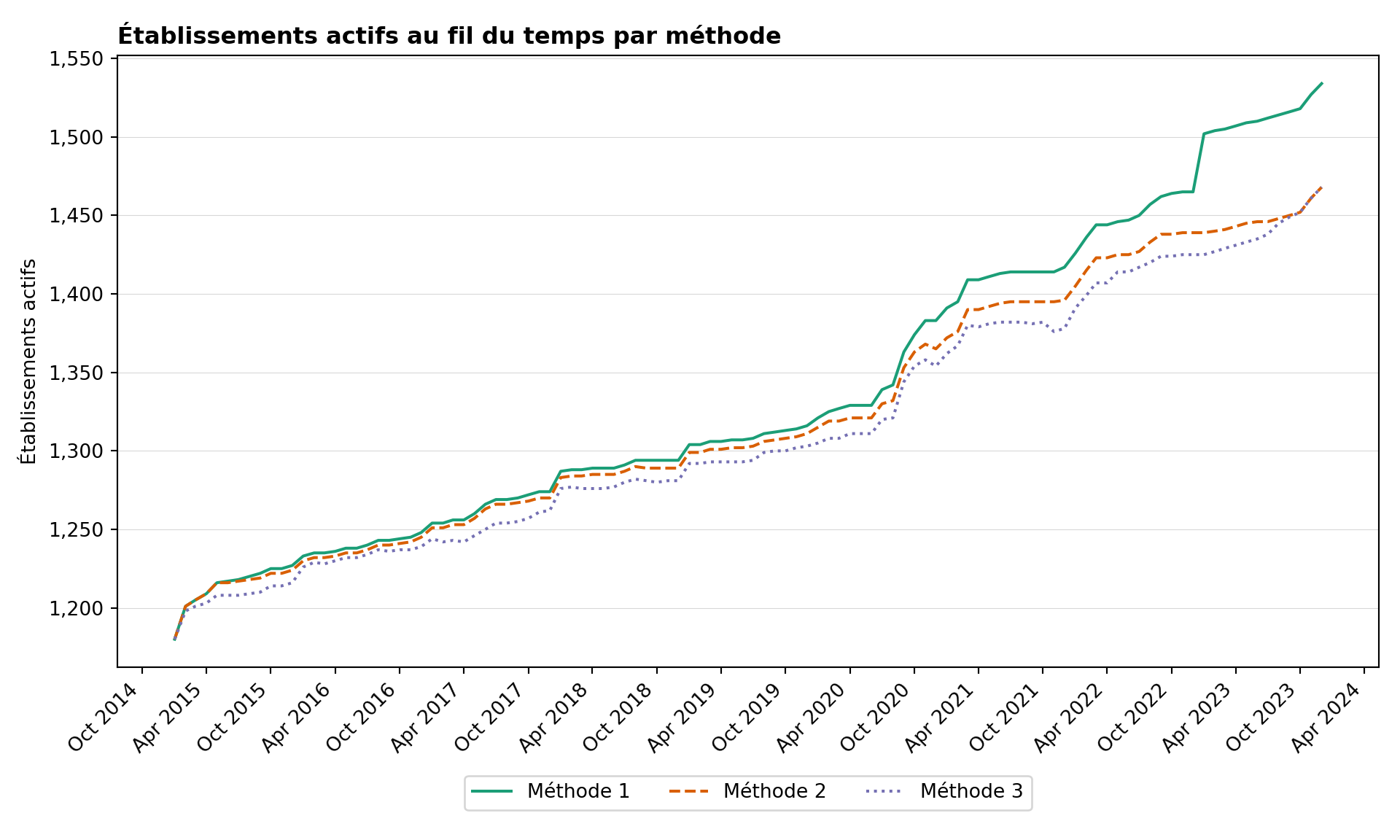
Pour comprendre comment les trois méthodes diffèrent en pratique, nous examinons deux vues complémentaires sur les mêmes données : une série temporelle du nombre d’établissements que chaque méthode compte comme Actifs chaque mois, et un ensemble de nuages de points par paires du taux de déclaration résultant par adm3 et par mois.
Étape 8.1 : Établissements actifs au fil du temps
df_methods_long <- df |>
dplyr::select(
hf_uid, date,
activity_method1, activity_method2, activity_method3
) |>
tidyr::pivot_longer(
cols = dplyr::starts_with("activity_method"),
names_to = "method",
values_to = "status"
) |>
dplyr::mutate(
method = dplyr::recode(
method,
"activity_method1" = "Méthode 1",
"activity_method2" = "Méthode 2",
"activity_method3" = "Méthode 3"
),
is_active = status %in% c("Déclarant actif", "Actif – Non déclarant")
)
df_active_per_month <- df_methods_long |>
dplyr::group_by(date, method) |>
dplyr::summarise(
n_active = sum(is_active, na.rm = TRUE),
.groups = "drop"
)
ggplot2::ggplot(
df_active_per_month,
ggplot2::aes(x = date, y = n_active, colour = method, linetype = method)
) +
ggplot2::geom_line(linewidth = 1) +
ggplot2::scale_y_continuous(labels = scales::comma) +
ggplot2::scale_colour_brewer(palette = "Dark2") +
ggplot2::labs(
x = NULL,
y = "Établissements actifs",
title = "Établissements actifs au fil du temps par méthode",
colour = NULL,
linetype = NULL
) +
ggplot2::theme_minimal() +
ggplot2::theme(legend.position = "bottom")
NoteSortie
Pour adapter le code :
- Ne rien modifier dans le code ci-dessus
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
# reformater en format long : une ligne par établissement × mois × méthode
df_methods_long = (
df[["hf_uid", "date", "activity_method1", "activity_method2", "activity_method3"]]
.melt(
id_vars=["hf_uid", "date"],
value_vars=["activity_method1", "activity_method2", "activity_method3"],
var_name="method",
value_name="status",
)
.assign(
method=lambda d: d["method"].map({
"activity_method1": "Méthode 1",
"activity_method2": "Méthode 2",
"activity_method3": "Méthode 3",
}),
is_active=lambda d: d["status"].isin(
["Déclarant actif", "Actif – Non déclarant"]
),
)
)
df_active_per_month = (
df_methods_long.groupby(["date", "method"], as_index=False)
.agg(n_active=("is_active", "sum"))
)
# palette Dark2 (trois premières couleurs)
method_colours = {
"Méthode 1": "#1B9E77",
"Méthode 2": "#D95F02",
"Méthode 3": "#7570B3",
}
method_linestyles = {
"Méthode 1": "-",
"Méthode 2": "--",
"Méthode 3": ":",
}
fig, ax = plt.subplots(figsize=(10, 6))
for method, grp in df_active_per_month.groupby("method"):
ax.plot(
grp["date"],
grp["n_active"],
label=method,
color=method_colours[method],
linestyle=method_linestyles[method],
linewidth=1.5,
)
ax.xaxis.set_major_locator(mdates.MonthLocator(interval=6))
ax.xaxis.set_major_formatter(mdates.DateFormatter("%b %Y"))
plt.setp(ax.get_xticklabels(), rotation=45, ha="right")
ax.yaxis.set_major_formatter(
plt.FuncFormatter(lambda x, _: f"{int(x):,}")
)
ax.set_xlabel("")
ax.set_ylabel("Établissements actifs")
ax.set_title("Établissements actifs au fil du temps par méthode", fontweight="bold",
loc="left")
ax.legend(loc="lower center", ncol=3, bbox_to_anchor=(0.5, -0.25))
ax.grid(axis="y", linewidth=0.4, alpha=0.5)
fig.tight_layout()
NoteSortie
Pour adapter le code :
- Ne rien modifier dans le code ci-dessus
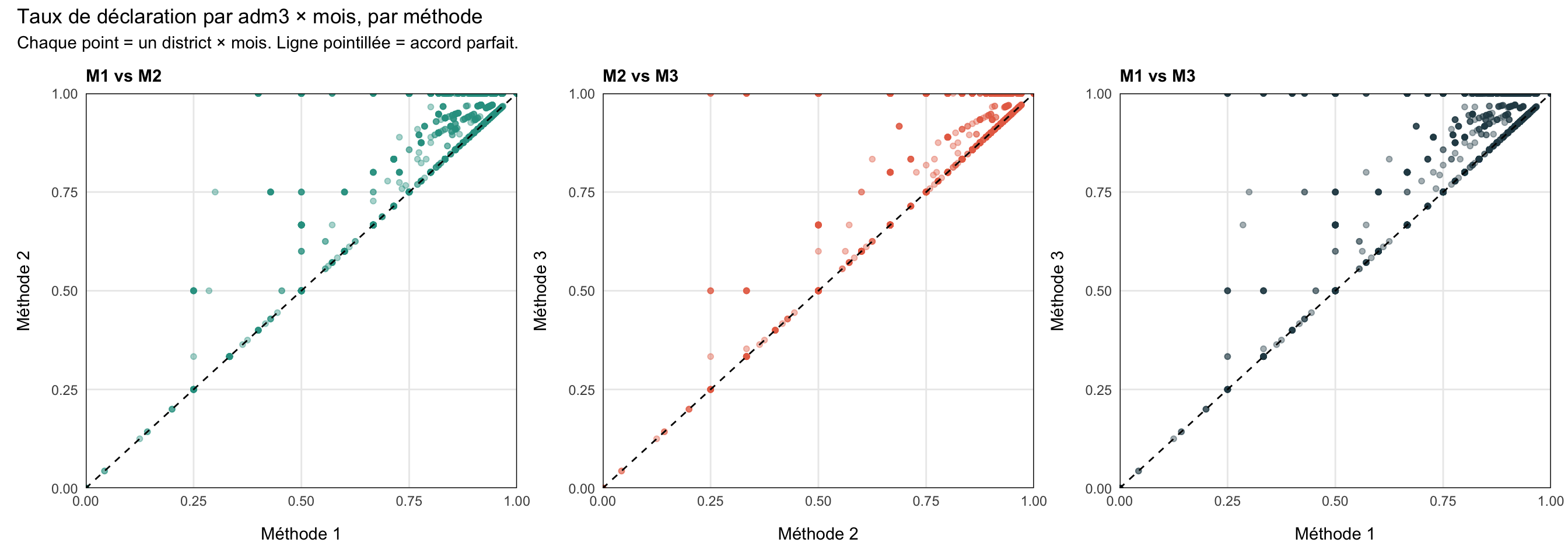
Étape 8.2 : Diagnostic par paires du taux de déclaration
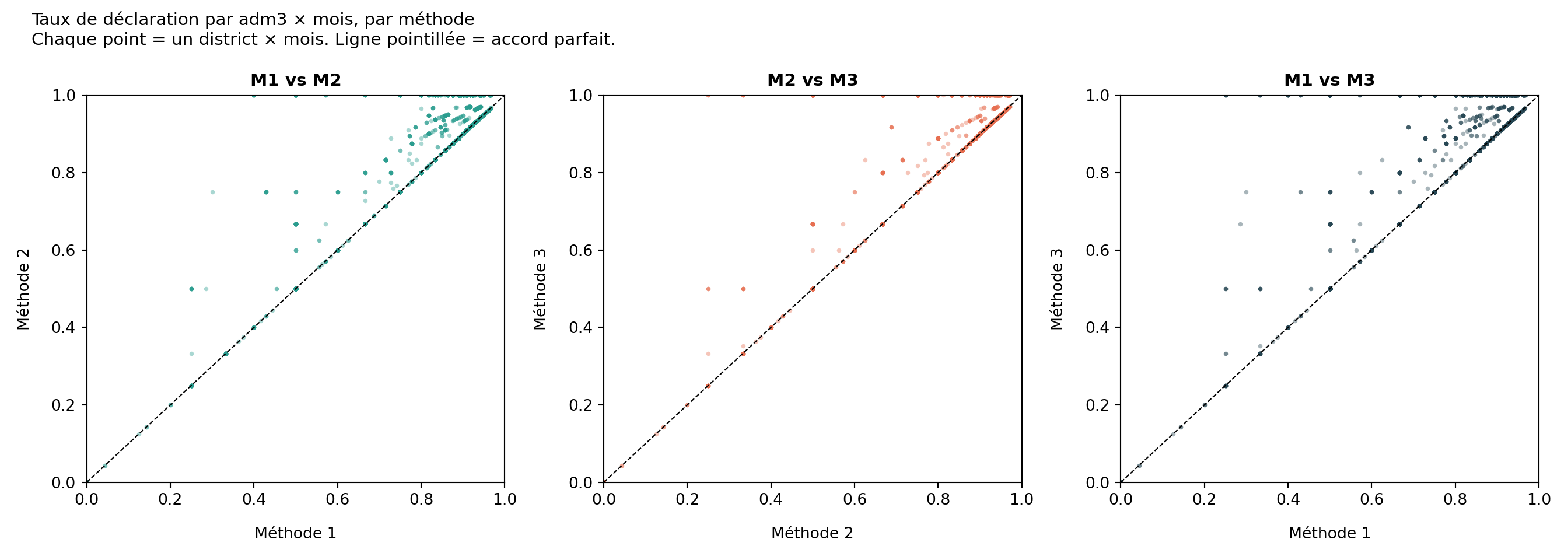
Chaque point représente une combinaison adm3 × mois. Les axes x et y sont le taux de déclaration (n_reported / n_active) sous deux méthodes différentes. Les points sur la ligne pointillée à 45° concordent parfaitement ; les points au-dessus de la ligne signifient que la méthode de l’axe y donne un taux plus élevé (c’est-à-dire qu’elle est plus stricte : elle a retiré plus d’établissements du dénominateur).
Afficher le code
# taux de déclaration par adm3 × mois sous chaque méthode
df_rate <- df |>
dplyr::mutate(
m1_active = activity_method1 %in%
c("Déclarant actif", "Actif – Non déclarant"),
m2_active = activity_method2 %in%
c("Déclarant actif", "Actif – Non déclarant"),
m3_active = activity_method3 %in%
c("Déclarant actif", "Actif – Non déclarant")
) |>
dplyr::group_by(date, adm3) |>
dplyr::summarise(
n_reported = sum(reported_any, na.rm = TRUE),
n_m1_active = sum(m1_active, na.rm = TRUE),
n_m2_active = sum(m2_active, na.rm = TRUE),
n_m3_active = sum(m3_active, na.rm = TRUE),
.groups = "drop"
) |>
dplyr::mutate(
rate_m1 = n_reported / n_m1_active,
rate_m2 = n_reported / n_m2_active,
rate_m3 = n_reported / n_m3_active
) |>
dplyr::filter(
is.finite(rate_m1), is.finite(rate_m2), is.finite(rate_m3)
)
# fonction pour un nuage de points par paire
make_scatter <- function(d, xcol, ycol, xlab, ylab, title, colour) {
ggplot2::ggplot(d, ggplot2::aes(x = .data[[xcol]], y = .data[[ycol]])) +
ggplot2::geom_point(alpha = 0.4, size = 1.4, colour = colour) +
ggplot2::geom_abline(slope = 1, intercept = 0, linetype = "dashed") +
ggplot2::scale_x_continuous(limits = c(0, 1), expand = c(0, 0)) +
ggplot2::scale_y_continuous(limits = c(0, 1), expand = c(0, 0)) +
ggplot2::labs(x = xlab, y = ylab, title = title) +
ggplot2::theme_minimal() +
ggplot2::theme(
plot.title = ggplot2::element_text(face = "bold", size = 11),
panel.border = ggplot2::element_rect(colour = "black", fill = NA),
panel.grid.minor = ggplot2::element_blank(),
axis.title.x = ggplot2::element_text(margin = ggplot2::margin(t = 12)),
axis.title.y = ggplot2::element_text(margin = ggplot2::margin(r = 12))
)
}
p1 <- make_scatter(
df_rate, "rate_m1", "rate_m2",
"Méthode 1", "Méthode 2", "M1 vs M2", "#2A9D8F"
)
p2 <- make_scatter(
df_rate, "rate_m2", "rate_m3",
"Méthode 2", "Méthode 3", "M2 vs M3", "#E76F51"
)
p3 <- make_scatter(
df_rate, "rate_m1", "rate_m3",
"Méthode 1", "Méthode 3", "M1 vs M3", "#264653"
)
patchwork::wrap_plots(p1, p2, p3, nrow = 1) +
patchwork::plot_annotation(
title = "Taux de déclaration par adm3 × mois, par méthode",
subtitle = "Chaque point = un district × mois. Ligne pointillée = accord parfait."
)
NoteSortie
Pour adapter le code :
- Ne rien modifier dans le code ci-dessus
Afficher le code
import matplotlib.pyplot as plt
import numpy as np
# taux de déclaration par adm3 × mois sous chaque méthode
active_labels = ["Déclarant actif", "Actif – Non déclarant"]
df_rate = (
df.assign(
m1_active=lambda d: d["activity_method1"].isin(active_labels),
m2_active=lambda d: d["activity_method2"].isin(active_labels),
m3_active=lambda d: d["activity_method3"].isin(active_labels),
)
.groupby(["date", "adm3"], as_index=False)
.agg(
n_reported=("reported_any", "sum"),
n_m1_active=("m1_active", "sum"),
n_m2_active=("m2_active", "sum"),
n_m3_active=("m3_active", "sum"),
)
.assign(
rate_m1=lambda d: d["n_reported"] / d["n_m1_active"],
rate_m2=lambda d: d["n_reported"] / d["n_m2_active"],
rate_m3=lambda d: d["n_reported"] / d["n_m3_active"],
)
.replace([np.inf, -np.inf], np.nan)
.dropna(subset=["rate_m1", "rate_m2", "rate_m3"])
)
# fonction pour un panneau de nuage de points par paire
def make_scatter(ax, xcol, ycol, xlab, ylab, title, colour):
ax.scatter(
df_rate[xcol], df_rate[ycol],
alpha=0.4, s=8, color=colour, linewidths=0,
)
ax.plot([0, 1], [0, 1], linestyle="dashed", color="black", linewidth=0.8)
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
ax.set_xlabel(xlab, labelpad=12)
ax.set_ylabel(ylab, labelpad=12)
ax.set_title(title, fontweight="bold", fontsize=11)
for spine in ax.spines.values():
spine.set_visible(True)
spine.set_color("black")
ax.grid(False)
ax.minorticks_off()
fig, axes = plt.subplots(1, 3, figsize=(14, 5))
make_scatter(axes[0], "rate_m1", "rate_m2", "Méthode 1", "Méthode 2", "M1 vs M2", "#2A9D8F")
make_scatter(axes[1], "rate_m2", "rate_m3", "Méthode 2", "Méthode 3", "M2 vs M3", "#E76F51")
make_scatter(axes[2], "rate_m1", "rate_m3", "Méthode 1", "Méthode 3", "M1 vs M3", "#264653")
fig.suptitle(
"Taux de déclaration par adm3 × mois, par méthode\n"
"Chaque point = un district × mois. Ligne pointillée = accord parfait.",
fontsize=11,
x=0.02,
ha="left",
)
fig.tight_layout()
NoteSortie
Pour adapter le code :
- Ne rien modifier dans le code ci-dessus
TipComment lire le diagnostic
Les trois méthodes se situent sur un spectre de tolérance : elles concordent toutes sur le moment où un établissement déclare, mais divergent sur ce qu’il faut faire des mois silencieux.
- Méthode 1 (la plus tolérante). Dès qu’un établissement déclare, il est compté comme Actif indéfiniment. Le dénominateur est le plus grand, donc les taux de déclaration sont les plus faibles. Les longues queues silencieuses après la fermeture effective d’un établissement continuent de faire baisser le taux.
- Méthode 2 (intermédiaire). Le silence terminal au-delà de la fenêtre de grâce (
nonreport_window) est retiré du dénominateur, de sorte que les établissements fermés cessent de nuire au taux. Les lacunes intermédiaires sont toujours comptées comme Actif – Non déclarant. - Méthode 3 (la plus stricte). Toute séquence de ≥
nonreport_windownon-déclarations consécutives, qu’elle se situe au milieu ou à la fin de la chronologie d’un établissement, retire ces mois du dénominateur. Les taux de déclaration sont les plus élevés mais la méthode peut masquer une sous-performance réelle lors de longues périodes silencieuses.
Dans le nuage de points M1 vs M3, les points se situent au-dessus de la ligne à 45° : les taux de M3 sont systématiquement plus élevés que ceux de M1, car M3 retire continuellement du dénominateur des établissements inactifs que M1 continue de compter. M2 se situe entre les deux. Utilisez ce diagnostic pour choisir la méthode qui correspond le mieux à la façon dont le PNM pense à l’activité des établissements.
Étape 9 : Exporter le dénominateur
Construire le dénominateur mensuel des établissements actifs par adm3 en utilisant la méthode choisie (Méthode 1 ci-dessous) : celui-ci devient le dénominateur pour les calculs en aval du taux de déclaration et de l’incidence.
df_expected <- df |>
dplyr::mutate(
is_active = activity_method1 %in% c(
"Déclarant actif", "Actif – Non déclarant"
),
YM = format(date, "%Y-%m")
) |>
dplyr::group_by(YM, adm0, adm1, adm2, adm3) |>
dplyr::summarise(
denominator = sum(is_active, na.rm = TRUE),
.groups = "drop"
) |>
dplyr::arrange(YM, adm0, adm1, adm2, adm3)
# décommenter pour sauvegarder
# save_path <- here::here(
# "01_data",
# "1.2_epidemiology",
# "1.2a_routine_surveillance",
# "processed"
# )
# saveRDS(
# df_expected,
# here::here(save_path, "sle_active_facility_denominator.rds")
# )Pour adapter le code :
- Ligne 3 : Remplacer
activity_method1paractivity_method2ouactivity_method3pour utiliser le dénominateur d’une autre méthode
active_labels = ["Déclarant actif", "Actif – Non déclarant"]
df_expected = (
df.assign(
is_active=lambda d: d["activity_method1"].isin(active_labels),
YM=lambda d: d["date"].dt.strftime("%Y-%m"),
)
.groupby(["YM", "adm0", "adm1", "adm2", "adm3"], as_index=False)
.agg(denominator=("is_active", "sum"))
.sort_values(["YM", "adm0", "adm1", "adm2", "adm3"])
.reset_index(drop=True)
)
# décommenter pour sauvegarder
# from pathlib import Path
# from pyprojroot import here
# save_path = Path(
# here("01_data/1.2_epidemiology/1.2a_routine_surveillance/processed")
# )
# df_expected.to_parquet(
# save_path / "sle_active_facility_denominator.parquet",
# index=False,
# )Pour adapter le code :
- Ligne 5 : Remplacer
activity_method1paractivity_method2ouactivity_method3pour utiliser le dénominateur d’une autre méthode
Résumé
Nous avons classé chaque paire établissement-mois dans l’un des trois états d’activité selon trois méthodes différentes (Activation permanente, Premier-au-dernier avec grâce et Dynamique) à l’aide d’une implémentation simplifiée pour chacune. Une fonction de carte thermique réutilisable visualise le résultat à l’échelle nationale et par unité administrative. Le diagnostic par paires de l’Étape 8 rend explicite le compromis de tolérance afin que nous puissions choisir la méthode qui correspond le mieux à la façon dont le PNM pense à l’activité des établissements. Les comptages actifs de la Méthode 1 alimentent les calculs en aval du taux de déclaration et de l’incidence comme dénominateur (df_expected).
Code complet
Retrouvez le script de code complet pour déterminer le statut actif et inactif ci-dessous.
Show full code
################################################################################
############ ~ Détermination du statut actif et inactif full code ~ ############
################################################################################
### Step -----------------------------------------------------------------------
pacman::p_load(
dplyr, # manipulation des données
tidyr, # mise en forme des données
lubridate, # gestion des dates
ggplot2, # visualisation des données
scales, # formatage des axes
data.table, # rleid() pour le regroupement par longueur de séquence
forcats, # ordre des facteurs pour l'axe y de la carte thermique
patchwork, # disposition des graphiques diagnostiques côte à côte
knitr, # rendu de tableaux html
tibble, # tribble() pour les tableaux littéraux ordonnés
glue, # interpolation de chaînes
cli, # messages informatifs
here # chemins de fichiers reproductibles
)
df <- arrow::read_parquet(here::here(
"01_data",
"1.2_epidemiology",
"1.2a_routine_surveillance",
"processed",
"clean_malaria_routine_data_final.parquet"
))
df <- df |>
dplyr::mutate(date = as.Date(date))
# indicateurs clés signalant la prestation de services contre le paludisme
key_indicators <- c("allout", "test", "pres", "conf", "maltreat", "maladm")
# fenêtre de grâce / d'inactivation dynamique par défaut (mois)
nonreport_window <- 6L
# (1) construire un panel équilibré (établissement × mois) et remplir les
# métadonnées manquantes
month_seq <- seq(min(df$date), max(df$date), by = "month")
panel <- tidyr::expand_grid(
hf_uid = unique(df$hf_uid),
date = month_seq
)
df <- df |>
dplyr::right_join(panel, by = c("hf_uid", "date")) |>
dplyr::arrange(hf_uid, date) |>
dplyr::group_by(hf_uid) |>
tidyr::fill(adm0, adm1, adm2, adm3, .direction = "downup") |>
dplyr::ungroup()
# (2) indicateur de déclaration au niveau de la ligne : cet établissement-mois
# a-t-il déclaré un indicateur ?
df <- df |>
dplyr::mutate(
reported_any = dplyr::if_any(
dplyr::all_of(key_indicators),
~ !is.na(.x)
)
)
# (3) dates de première / dernière déclaration par établissement et dernière
# date du panel
# (utiliser if/else, pas dplyr::if_else, pour que min/max ne soient pas évalués
# sur les établissements qui n'ont jamais déclaré — évite les avertissements "no
# non-missing arguments to min")
df <- df |>
dplyr::arrange(hf_uid, date) |>
dplyr::group_by(hf_uid) |>
dplyr::mutate(
first_rep = if (any(reported_any)) min(date[reported_any]) else as.Date(NA),
last_rep = if (any(reported_any)) max(date[reported_any]) else as.Date(NA),
last_date = max(date)
) |>
dplyr::ungroup()
plot_activity_heatmap <- function(
data,
status_col,
hf_col = "hf_uid",
date_col = "date",
title = NULL,
subtitle = NULL,
facet_col = NULL,
facet_ncol = 4
) {
# palette forestière à 3 états : vert-teal / ambre / bleu marine foncé
status_colours <- c(
"Déclarant actif" = "#2A9D8F", # vert-teal : opérationnel
"Actif – Non déclarant" = "#E9C46A", # ambre : opérationnel mais silencieux
"Inactif" = "#264653" # bleu marine foncé : non opérationnel
)
# ordonner les établissements par date de première déclaration pour un
# balayage visuel propre
facility_order <- data |>
dplyr::distinct(.data[[hf_col]], first_rep) |>
dplyr::arrange(first_rep) |>
dplyr::pull(.data[[hf_col]])
data <- data |>
dplyr::mutate(
.hf_ordered = forcats::fct_relevel(
as.character(.data[[hf_col]]),
!!!as.character(facility_order)
)
)
# afficher uniquement le premier / milieu / dernier numéro d'établissement
# sur l'axe y
n_hf <- length(facility_order)
if (n_hf >= 3) {
y_breaks <- facility_order[c(1, ceiling(n_hf / 2), n_hf)]
y_labels <- scales::comma(c(1, ceiling(n_hf / 2), n_hf))
} else {
y_breaks <- facility_order
y_labels <- scales::comma(seq_len(n_hf))
}
p <- ggplot2::ggplot(
data,
ggplot2::aes(
x = .data[[date_col]],
y = .hf_ordered,
fill = .data[[status_col]]
)
) +
ggplot2::geom_tile(width = 31, height = 1) +
ggplot2::scale_fill_manual(
values = status_colours,
na.value = "white",
name = NULL
) +
ggplot2::scale_x_date(
expand = c(0, 0),
date_breaks = "6 months",
date_labels = "%b %Y"
) +
ggplot2::scale_y_discrete(
breaks = y_breaks,
labels = y_labels
) +
ggplot2::labs(
x = NULL,
y = "N° d'ES\n",
title = title,
subtitle = subtitle
) +
ggplot2::theme_minimal(base_family = "sans") +
ggplot2::theme(
axis.text.x = ggplot2::element_text(angle = 45, hjust = 1),
axis.text.y = ggplot2::element_text(size = 8),
axis.line = ggplot2::element_line(color = "black", linewidth = 0.5),
legend.position = "bottom",
legend.direction = "horizontal",
plot.title = ggplot2::element_text(face = "bold")
)
if (!is.null(facet_col)) {
p <- p +
ggplot2::facet_wrap(
ggplot2::vars(.data[[facet_col]]),
scales = "free_y",
ncol = facet_ncol
)
}
p
}
df <- df |>
dplyr::arrange(hf_uid, date) |>
dplyr::group_by(hf_uid) |>
dplyr::mutate(
ever_reported = dplyr::cumany(reported_any),
activity_method1 = dplyr::case_when(
!any(reported_any) ~ "Inactif",
!ever_reported ~ "Inactif",
reported_any ~ "Déclarant actif",
TRUE ~ "Actif – Non déclarant"
)
) |>
dplyr::ungroup()
plot_activity_heatmap(
data = df,
status_col = "activity_method1",
title = "Méthode 1 : Activation permanente",
subtitle = "Les établissements restent Actifs une fois qu'ils ont déclaré"
)
df <- df |>
dplyr::arrange(hf_uid, date) |>
dplyr::group_by(hf_uid) |>
dplyr::mutate(
months_since_last = dplyr::if_else(
is.na(last_rep),
Inf,
as.numeric(
lubridate::interval(last_rep, last_date) / lubridate::dmonths(1)
)
),
activity_method2 = dplyr::case_when(
is.na(first_rep) ~ "Inactif",
date < first_rep ~ "Inactif",
reported_any ~ "Déclarant actif",
date <= last_rep ~ "Actif – Non déclarant",
date > last_rep & months_since_last >= nonreport_window ~ "Inactif",
TRUE ~ "Actif – Non déclarant"
)
) |>
dplyr::ungroup()
plot_activity_heatmap(
data = df,
status_col = "activity_method2",
title = "Méthode 2 : Activer après le premier rapport, inactiver après le dernier",
subtitle = glue::glue(
"Queue finale au-delà du dernier rapport (>{nonreport_window} mois) est Inactif"
)
)
df <- df |>
dplyr::arrange(hf_uid, date) |>
dplyr::group_by(hf_uid) |>
dplyr::mutate(
# 1 si ce mois n'a pas déclaré, 0 s'il a déclaré
gap = dplyr::if_else(!reported_any, 1L, 0L),
# un identifiant par séquence consécutive de valeurs gap identiques
gap_run = data.table::rleid(gap),
# longueur de la séquence à laquelle appartient cette ligne (même valeur
# pour toutes les lignes de la séquence)
run_len = stats::ave(gap, gap_run, FUN = length),
activity_method3 = dplyr::case_when(
!any(reported_any) ~ "Inactif",
is.na(first_rep) ~ "Inactif",
date < first_rep ~ "Inactif",
reported_any ~ "Déclarant actif",
gap == 1 & run_len < nonreport_window ~ "Actif – Non déclarant",
gap == 1 & run_len >= nonreport_window ~ "Inactif",
TRUE ~ "Inactif"
)
) |>
dplyr::ungroup()
plot_activity_heatmap(
data = df,
status_col = "activity_method3",
title = "Méthode 3 : Activation et inactivation dynamiques",
subtitle = glue::glue(
"Inactif dès qu'une séquence de ≥{nonreport_window} mois sans déclaration survient"
)
)
# décomposition par adm1 (région)
plot_activity_heatmap(
data = df,
status_col = "activity_method3",
facet_col = "adm1",
facet_ncol = 2,
title = "Méthode 3 — décomposée par adm1 (région)",
subtitle = "Chaque panneau montre les établissements d'une région"
)
# décomposition par adm2 (district)
plot_activity_heatmap(
data = df,
status_col = "activity_method3",
facet_col = "adm2",
facet_ncol = 4,
title = "Méthode 3 — décomposée par adm2 (district)",
subtitle = "Chaque panneau montre les établissements d'un district"
)
df_methods_long <- df |>
dplyr::select(
hf_uid, date,
activity_method1, activity_method2, activity_method3
) |>
tidyr::pivot_longer(
cols = dplyr::starts_with("activity_method"),
names_to = "method",
values_to = "status"
) |>
dplyr::mutate(
method = dplyr::recode(
method,
"activity_method1" = "Méthode 1",
"activity_method2" = "Méthode 2",
"activity_method3" = "Méthode 3"
),
is_active = status %in% c("Déclarant actif", "Actif – Non déclarant")
)
df_active_per_month <- df_methods_long |>
dplyr::group_by(date, method) |>
dplyr::summarise(
n_active = sum(is_active, na.rm = TRUE),
.groups = "drop"
)
ggplot2::ggplot(
df_active_per_month,
ggplot2::aes(x = date, y = n_active, colour = method, linetype = method)
) +
ggplot2::geom_line(linewidth = 1) +
ggplot2::scale_y_continuous(labels = scales::comma) +
ggplot2::scale_colour_brewer(palette = "Dark2") +
ggplot2::labs(
x = NULL,
y = "Établissements actifs",
title = "Établissements actifs au fil du temps par méthode",
colour = NULL,
linetype = NULL
) +
ggplot2::theme_minimal() +
ggplot2::theme(legend.position = "bottom")
# taux de déclaration par adm3 × mois sous chaque méthode
df_rate <- df |>
dplyr::mutate(
m1_active = activity_method1 %in%
c("Déclarant actif", "Actif – Non déclarant"),
m2_active = activity_method2 %in%
c("Déclarant actif", "Actif – Non déclarant"),
m3_active = activity_method3 %in%
c("Déclarant actif", "Actif – Non déclarant")
) |>
dplyr::group_by(date, adm3) |>
dplyr::summarise(
n_reported = sum(reported_any, na.rm = TRUE),
n_m1_active = sum(m1_active, na.rm = TRUE),
n_m2_active = sum(m2_active, na.rm = TRUE),
n_m3_active = sum(m3_active, na.rm = TRUE),
.groups = "drop"
) |>
dplyr::mutate(
rate_m1 = n_reported / n_m1_active,
rate_m2 = n_reported / n_m2_active,
rate_m3 = n_reported / n_m3_active
) |>
dplyr::filter(
is.finite(rate_m1), is.finite(rate_m2), is.finite(rate_m3)
)
# fonction pour un nuage de points par paire
make_scatter <- function(d, xcol, ycol, xlab, ylab, title, colour) {
ggplot2::ggplot(d, ggplot2::aes(x = .data[[xcol]], y = .data[[ycol]])) +
ggplot2::geom_point(alpha = 0.4, size = 1.4, colour = colour) +
ggplot2::geom_abline(slope = 1, intercept = 0, linetype = "dashed") +
ggplot2::scale_x_continuous(limits = c(0, 1), expand = c(0, 0)) +
ggplot2::scale_y_continuous(limits = c(0, 1), expand = c(0, 0)) +
ggplot2::labs(x = xlab, y = ylab, title = title) +
ggplot2::theme_minimal() +
ggplot2::theme(
plot.title = ggplot2::element_text(face = "bold", size = 11),
panel.border = ggplot2::element_rect(colour = "black", fill = NA),
panel.grid.minor = ggplot2::element_blank(),
axis.title.x = ggplot2::element_text(margin = ggplot2::margin(t = 12)),
axis.title.y = ggplot2::element_text(margin = ggplot2::margin(r = 12))
)
}
p1 <- make_scatter(
df_rate, "rate_m1", "rate_m2",
"Méthode 1", "Méthode 2", "M1 vs M2", "#2A9D8F"
)
p2 <- make_scatter(
df_rate, "rate_m2", "rate_m3",
"Méthode 2", "Méthode 3", "M2 vs M3", "#E76F51"
)
p3 <- make_scatter(
df_rate, "rate_m1", "rate_m3",
"Méthode 1", "Méthode 3", "M1 vs M3", "#264653"
)
patchwork::wrap_plots(p1, p2, p3, nrow = 1) +
patchwork::plot_annotation(
title = "Taux de déclaration par adm3 × mois, par méthode",
subtitle = "Chaque point = un district × mois. Ligne pointillée = accord parfait."
)
df_expected <- df |>
dplyr::mutate(
is_active = activity_method1 %in% c(
"Déclarant actif", "Actif – Non déclarant"
),
YM = format(date, "%Y-%m")
) |>
dplyr::group_by(YM, adm0, adm1, adm2, adm3) |>
dplyr::summarise(
denominator = sum(is_active, na.rm = TRUE),
.groups = "drop"
) |>
dplyr::arrange(YM, adm0, adm1, adm2, adm3)
# décommenter pour sauvegarder
# save_path <- here::here(
# "01_data",
# "1.2_epidemiology",
# "1.2a_routine_surveillance",
# "processed"
# )
# saveRDS(
# df_expected,
# here::here(save_path, "sle_active_facility_denominator.rds")
# )Show full code
################################################################################
############ ~ Détermination du statut actif et inactif full code ~ ############
################################################################################
### Step -----------------------------------------------------------------------
import pandas as pd # manipulation des données
import numpy as np # opérations numériques
import matplotlib.pyplot as plt # tracé de graphiques
import matplotlib.dates as mdates
import matplotlib.patches as mpatches
from pathlib import Path
from pyprojroot import here # chemins de fichiers reproductibles
# assistants cli — définis une fois, réutilisés à chaque étape
def cli_header(message):
print(f"\n{message}")
def cli_info(message):
print(f"INFO: {message}")
def cli_success(message):
print(f"SUCCESS: {message}")
def cli_warning(message):
print(f"WARNING: {message}")
def cli_danger(message):
print(f"ERROR: {message}")
import pandas as pd
from pathlib import Path
from pyprojroot import here
# charger les données de routine sur le paludisme prétraitées
df = pd.read_parquet(
Path(here(
"01_data/1.2_epidemiology/1.2a_routine_surveillance/processed/"
"clean_malaria_routine_data_final.parquet"
))
)
# s'assurer que la colonne date est un objet datetime valide
df["date"] = pd.to_datetime(df["date"])
import pandas as pd
import numpy as np
# indicateurs clés signalant la prestation de services contre le paludisme
key_indicators = ["allout", "test", "pres", "conf", "maltreat", "maladm"]
# fenêtre de grâce / d'inactivation dynamique par défaut (mois)
nonreport_window = 6
# (1) construire un panel équilibré (établissement × mois) et remplir les
# métadonnées manquantes
month_seq = pd.date_range(df["date"].min(), df["date"].max(), freq="MS")
panel = pd.MultiIndex.from_product(
[df["hf_uid"].unique(), month_seq],
names=["hf_uid", "date"]
).to_frame(index=False)
df = (
panel.merge(df, on=["hf_uid", "date"], how="left")
.sort_values(["hf_uid", "date"])
)
# remplissage avant puis arrière des métadonnées administratives au sein de chaque groupe d'établissements
meta_cols = ["adm0", "adm1", "adm2", "adm3"]
df[meta_cols] = (
df.groupby("hf_uid")[meta_cols]
.transform(lambda s: s.ffill().bfill())
)
# (2) indicateur de déclaration au niveau de la ligne : cet établissement-mois
# a-t-il déclaré un indicateur ?
# ajouter les colonnes d'indicateurs clés manquantes en NaN pour que le prédicat utilise les mêmes
# six colonnes que dplyr::if_any(dplyr::all_of(key_indicators), ~!is.na(.x)) en R
for _col in key_indicators:
if _col not in df.columns:
df[_col] = np.nan
df = df.assign(
reported_any=lambda d: d[key_indicators].notna().any(axis=1)
)
# (3) dates de première / dernière déclaration par établissement et dernière
# date du panel
def facility_dates(g):
mask = g["reported_any"]
g = g.copy()
if mask.any():
g["first_rep"] = g.loc[mask, "date"].min()
g["last_rep"] = g.loc[mask, "date"].max()
else:
g["first_rep"] = pd.NaT
g["last_rep"] = pd.NaT
g["last_date"] = g["date"].max()
return g
df = (
df.sort_values(["hf_uid", "date"])
.groupby("hf_uid", group_keys=False)
.apply(facility_dates)
.reset_index(drop=True)
)
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import matplotlib.patches as mpatches
from matplotlib.collections import PatchCollection
import numpy as np
def plot_activity_heatmap(
data,
status_col,
hf_col="hf_uid",
date_col="date",
title=None,
subtitle=None,
facet_col=None,
facet_ncol=4
):
# palette forestière à 3 états : vert-teal / ambre / bleu marine foncé
status_colours = {
"Déclarant actif": "#2A9D8F", # vert-teal : opérationnel
"Actif – Non déclarant": "#E9C46A", # ambre : opérationnel mais silencieux
"Inactif": "#264653", # bleu marine foncé : non opérationnel
}
colour_map = dict(status_colours)
def _draw_panel(ax, subset, title_text=None):
subset = subset.copy()
# ordonner les établissements de ce panel par date de première déclaration,
# en reproduisant facet_wrap(scales = "free_y") pour que chaque panel remplisse son propre axe y
order = (
subset[[hf_col, "first_rep"]]
.drop_duplicates()
.sort_values("first_rep")
[hf_col]
.tolist()
)
rank = {hf: i for i, hf in enumerate(order)}
n = len(order)
subset["_y"] = subset[hf_col].map(rank)
subset["_c"] = subset[status_col].map(colour_map).fillna("white")
# dessiner chaque paire établissement-mois comme une tuile remplie, correspondant à geom_tile :
# 31 jours de large, 1 rangée de haut, centré sur la date et le rang de l'établissement
x = mdates.date2num(subset[date_col])
tiles = [
mpatches.Rectangle((xi - 15.5, yi - 0.5), 31, 1)
for xi, yi in zip(x, subset["_y"])
]
ax.add_collection(
PatchCollection(
tiles,
facecolors=subset["_c"].tolist(),
edgecolors="none",
)
)
ax.set_xlim(x.min() - 15.5, x.max() + 15.5)
ax.set_ylim(-0.5, n - 0.5)
# graduations de l'axe y : premier / milieu / dernier établissement de ce panel
if n >= 3:
tick_positions = [0, (n - 1) // 2, n - 1]
tick_labels = [str(1), str((n - 1) // 2 + 1), str(n)]
else:
tick_positions = list(range(n))
tick_labels = [str(i + 1) for i in range(n)]
# axe x : graduations semestrielles
ax.xaxis.set_major_locator(mdates.MonthLocator(bymonth=[1, 7]))
ax.xaxis.set_major_formatter(mdates.DateFormatter("%b %Y"))
plt.setp(ax.get_xticklabels(), rotation=45, ha="right", fontsize=8)
# axe y : étiquettes de rang des établissements
ax.set_yticks(tick_positions)
ax.set_yticklabels(tick_labels, fontsize=8)
ax.set_ylabel("N° d'ES")
ax.spines["top"].set_visible(False)
ax.spines["right"].set_visible(False)
ax.set_xlabel("")
if title_text:
ax.set_title(title_text, fontsize=9, pad=4)
# poignées de légende partagées (une teinte par statut)
legend_handles = [
mpatches.Patch(color=v, label=k)
for k, v in status_colours.items()
]
if facet_col is None:
fig, ax = plt.subplots(figsize=(10, 8))
_draw_panel(ax, data)
# réserver des marges pour que le bloc de titre et la légende ne soient jamais coupés
fig.subplots_adjust(top=0.86, bottom=0.20, left=0.10, right=0.97)
x0 = ax.get_position().x0
# titre en gras avec un sous-titre plus léger en dessous, aligné à gauche (style ggplot)
if title:
fig.text(x0, 0.965, title, ha="left", va="top",
fontsize=14, fontweight="bold")
if subtitle:
fig.text(x0, 0.915, subtitle, ha="left", va="top", fontsize=11)
# la légende se trouve bien au-dessus des étiquettes de graduation de l'axe x
fig.legend(handles=legend_handles, loc="lower center", ncol=3,
fontsize=9, bbox_to_anchor=(0.5, 0.02))
else:
groups = sorted(data[facet_col].dropna().unique())
n_groups = len(groups)
n_cols = facet_ncol
n_rows = int(np.ceil(n_groups / n_cols))
fig, axes = plt.subplots(
n_rows, n_cols,
figsize=(4 * n_cols, 3.2 * n_rows)
)
axes_flat = np.array(axes).reshape(-1)
for idx, grp in enumerate(groups):
_draw_panel(axes_flat[idx], data[data[facet_col] == grp], str(grp))
for ax in axes_flat[n_groups:]:
ax.set_visible(False)
fig.subplots_adjust(top=0.93, bottom=0.14, left=0.08, right=0.97,
hspace=0.75, wspace=0.28)
x0 = axes_flat[0].get_position().x0
if title:
fig.text(x0, 0.985, title, ha="left", va="top",
fontsize=15, fontweight="bold")
if subtitle:
fig.text(x0, 0.965, subtitle, ha="left", va="top", fontsize=12)
# la légende se trouve bien au-dessus des étiquettes de graduation de la dernière rangée
fig.legend(handles=legend_handles, loc="lower center", ncol=3,
fontsize=10, bbox_to_anchor=(0.5, 0.02))
return fig
df = df.sort_values(["hf_uid", "date"])
# indicateur cumulatif « a déjà déclaré » au sein de chaque établissement
df["ever_reported"] = (
df.groupby("hf_uid")["reported_any"]
.transform("cummax")
)
# méthode 1 : activation permanente à partir du premier mois de déclaration
df["activity_method1"] = np.select(
[
~df.groupby("hf_uid")["reported_any"].transform("any"),
~df["ever_reported"],
df["reported_any"],
],
[
"Inactif",
"Inactif",
"Déclarant actif",
],
default="Actif – Non déclarant",
)
plot_activity_heatmap(
data=df,
status_col="activity_method1",
title="Méthode 1 : Activation permanente",
subtitle="Les établissements restent Actifs une fois qu'ils ont déclaré",
)
df = df.sort_values(["hf_uid", "date"])
# mois entre le dernier rapport d'un établissement et la dernière date du panel
def months_since_last(g):
g = g.copy()
if g["last_rep"].isna().all():
g["months_since_last"] = np.inf
else:
last_rep = g["last_rep"].iloc[0]
last_date = g["last_date"].iloc[0]
# dmonths(1) = 30.4375 jours dans lubridate ; ceci correspond exactement à R
delta_days = (last_date - last_rep).days
g["months_since_last"] = delta_days / 30.4375
return g
df = (
df.groupby("hf_uid", group_keys=False)
.apply(months_since_last)
.reset_index(drop=True)
)
# méthode 2 : premier-au-dernier avec période de grâce
df["activity_method2"] = np.select(
[
df["first_rep"].isna(),
df["date"] < df["first_rep"],
df["reported_any"],
df["date"] <= df["last_rep"],
(df["date"] > df["last_rep"])
& (df["months_since_last"] >= nonreport_window),
],
[
"Inactif",
"Inactif",
"Déclarant actif",
"Actif – Non déclarant",
"Inactif",
],
default="Actif – Non déclarant",
)
plot_activity_heatmap(
data=df,
status_col="activity_method2",
title="Méthode 2 : Activer après le premier rapport, inactiver après le dernier",
subtitle=(
f"Queue finale au-delà du dernier rapport (>{nonreport_window} mois) est Inactif"
),
)
df = df.sort_values(["hf_uid", "date"])
def add_run_length(g):
"""Étiqueter chaque ligne avec la longueur de sa séquence de lacune consécutive."""
g = g.copy()
# 1 si l'établissement n'a pas déclaré ce mois, 0 s'il a déclaré
g["gap"] = (~g["reported_any"]).astype(int)
# identifiant de séquence consécutive (incrémente à chaque changement de gap)
g["gap_run"] = (g["gap"] != g["gap"].shift()).cumsum()
# longueur de chaque séquence (même valeur pour toutes les lignes de la même séquence)
g["run_len"] = g.groupby("gap_run")["gap"].transform("count")
return g
df = (
df.groupby("hf_uid", group_keys=False)
.apply(add_run_length)
.reset_index(drop=True)
)
# méthode 3 : activation dynamique — inactiver toute séquence de ≥ nonreport_window mois
never_reported = ~df.groupby("hf_uid")["reported_any"].transform("any")
df["activity_method3"] = np.select(
[
never_reported,
df["first_rep"].isna(),
df["date"] < df["first_rep"],
df["reported_any"],
(df["gap"] == 1) & (df["run_len"] < nonreport_window),
(df["gap"] == 1) & (df["run_len"] >= nonreport_window),
],
[
"Inactif",
"Inactif",
"Inactif",
"Déclarant actif",
"Actif – Non déclarant",
"Inactif",
],
default="Inactif",
)
plot_activity_heatmap(
data=df,
status_col="activity_method3",
title="Méthode 3 : Activation et inactivation dynamiques",
subtitle=(
f"Inactif dès qu'une séquence de ≥{nonreport_window} mois sans déclaration survient"
),
)
# décomposition par adm1 (région)
plot_activity_heatmap(
data=df,
status_col="activity_method3",
facet_col="adm1",
facet_ncol=2,
title="Méthode 3 — décomposée par adm1 (région)",
subtitle="Chaque panneau montre les établissements d'une région",
)
# décomposition par adm2 (district)
plot_activity_heatmap(
data=df,
status_col="activity_method3",
facet_col="adm2",
facet_ncol=4,
title="Méthode 3 — décomposée par adm2 (district)",
subtitle="Chaque panneau montre les établissements d'un district",
)
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
# reformater en format long : une ligne par établissement × mois × méthode
df_methods_long = (
df[["hf_uid", "date", "activity_method1", "activity_method2", "activity_method3"]]
.melt(
id_vars=["hf_uid", "date"],
value_vars=["activity_method1", "activity_method2", "activity_method3"],
var_name="method",
value_name="status",
)
.assign(
method=lambda d: d["method"].map({
"activity_method1": "Méthode 1",
"activity_method2": "Méthode 2",
"activity_method3": "Méthode 3",
}),
is_active=lambda d: d["status"].isin(
["Déclarant actif", "Actif – Non déclarant"]
),
)
)
df_active_per_month = (
df_methods_long.groupby(["date", "method"], as_index=False)
.agg(n_active=("is_active", "sum"))
)
# palette Dark2 (trois premières couleurs)
method_colours = {
"Méthode 1": "#1B9E77",
"Méthode 2": "#D95F02",
"Méthode 3": "#7570B3",
}
method_linestyles = {
"Méthode 1": "-",
"Méthode 2": "--",
"Méthode 3": ":",
}
fig, ax = plt.subplots(figsize=(10, 6))
for method, grp in df_active_per_month.groupby("method"):
ax.plot(
grp["date"],
grp["n_active"],
label=method,
color=method_colours[method],
linestyle=method_linestyles[method],
linewidth=1.5,
)
ax.xaxis.set_major_locator(mdates.MonthLocator(interval=6))
ax.xaxis.set_major_formatter(mdates.DateFormatter("%b %Y"))
plt.setp(ax.get_xticklabels(), rotation=45, ha="right")
ax.yaxis.set_major_formatter(
plt.FuncFormatter(lambda x, _: f"{int(x):,}")
)
ax.set_xlabel("")
ax.set_ylabel("Établissements actifs")
ax.set_title("Établissements actifs au fil du temps par méthode", fontweight="bold",
loc="left")
ax.legend(loc="lower center", ncol=3, bbox_to_anchor=(0.5, -0.25))
ax.grid(axis="y", linewidth=0.4, alpha=0.5)
fig.tight_layout()
import matplotlib.pyplot as plt
import numpy as np
# taux de déclaration par adm3 × mois sous chaque méthode
active_labels = ["Déclarant actif", "Actif – Non déclarant"]
df_rate = (
df.assign(
m1_active=lambda d: d["activity_method1"].isin(active_labels),
m2_active=lambda d: d["activity_method2"].isin(active_labels),
m3_active=lambda d: d["activity_method3"].isin(active_labels),
)
.groupby(["date", "adm3"], as_index=False)
.agg(
n_reported=("reported_any", "sum"),
n_m1_active=("m1_active", "sum"),
n_m2_active=("m2_active", "sum"),
n_m3_active=("m3_active", "sum"),
)
.assign(
rate_m1=lambda d: d["n_reported"] / d["n_m1_active"],
rate_m2=lambda d: d["n_reported"] / d["n_m2_active"],
rate_m3=lambda d: d["n_reported"] / d["n_m3_active"],
)
.replace([np.inf, -np.inf], np.nan)
.dropna(subset=["rate_m1", "rate_m2", "rate_m3"])
)
# fonction pour un panneau de nuage de points par paire
def make_scatter(ax, xcol, ycol, xlab, ylab, title, colour):
ax.scatter(
df_rate[xcol], df_rate[ycol],
alpha=0.4, s=8, color=colour, linewidths=0,
)
ax.plot([0, 1], [0, 1], linestyle="dashed", color="black", linewidth=0.8)
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
ax.set_xlabel(xlab, labelpad=12)
ax.set_ylabel(ylab, labelpad=12)
ax.set_title(title, fontweight="bold", fontsize=11)
for spine in ax.spines.values():
spine.set_visible(True)
spine.set_color("black")
ax.grid(False)
ax.minorticks_off()
fig, axes = plt.subplots(1, 3, figsize=(14, 5))
make_scatter(axes[0], "rate_m1", "rate_m2", "Méthode 1", "Méthode 2", "M1 vs M2", "#2A9D8F")
make_scatter(axes[1], "rate_m2", "rate_m3", "Méthode 2", "Méthode 3", "M2 vs M3", "#E76F51")
make_scatter(axes[2], "rate_m1", "rate_m3", "Méthode 1", "Méthode 3", "M1 vs M3", "#264653")
fig.suptitle(
"Taux de déclaration par adm3 × mois, par méthode\n"
"Chaque point = un district × mois. Ligne pointillée = accord parfait.",
fontsize=11,
x=0.02,
ha="left",
)
fig.tight_layout()
active_labels = ["Déclarant actif", "Actif – Non déclarant"]
df_expected = (
df.assign(
is_active=lambda d: d["activity_method1"].isin(active_labels),
YM=lambda d: d["date"].dt.strftime("%Y-%m"),
)
.groupby(["YM", "adm0", "adm1", "adm2", "adm3"], as_index=False)
.agg(denominator=("is_active", "sum"))
.sort_values(["YM", "adm0", "adm1", "adm2", "adm3"])
.reset_index(drop=True)
)
# décommenter pour sauvegarder
# from pathlib import Path
# from pyprojroot import here
# save_path = Path(
# here("01_data/1.2_epidemiology/1.2a_routine_surveillance/processed")
# )
# df_expected.to_parquet(
# save_path / "sle_active_facility_denominator.parquet",
# index=False,
# )