# Charger les paquets requis
pacman::p_load(
terra, # Pour les opérations raster
sf, # Pour les données vectorielles
exactextractr, # Pour une extraction précise à partir de rasters
dplyr, # Pour la manipulation des données
lubridate, # Pour la gestion des dates
here # Pour la gestion des chemins d'accès aux fichiers
)
# Téléchargez la dernière version de sntutils si ce n'est pas déjà fait
devtools::install_github("ahadi-analytics/sntutils")
# importer le shapefile des limites administratives
sl_adm3_shp <- readRDS(
here::here("01_foundational/1a_administrative_boundaries",
"1ai_adm3", "sle_spatial_adm3_2021.rds")
) |> sf::st_as_sf() # s'assurer qu'il est bien converti au format sfExtraction de données climatiques et environnementales à partir de données raster
Aperçu
Les conditions environnementales, en particulier la pluviométrie, la température, la végétation et la proximité de l’eau, jouent un rôle fondamental dans la transmission du paludisme. Elles influencent à la fois les milieux où se reproduisent les moustiques et les processus biologiques qui régissent la transmission. Des variables telles que la pluviométrie, la température et l’humidité affectent la survie des moustiques, la disponibilité des gîtes larvaires et la vitesse à laquelle les parasites se développent chez le vecteur. Ces facteurs varient souvent selon les saisons et les régions, ce qui rend leur analyse très utile pour le SNT.
Dans le cadre du processus SNT, les données climatiques sont intégrées dès le début de la collecte des données afin de garantir que les conditions environnementales sont correctement prises en compte dans les analyses en aval. Des résumés mensuels nettoyés des principales variables climatiques sont agrégés au niveau de l’unité opérationnelle pour analyse (généralement au niveau adm2 ou adm3) afin de faciliter la stratification des déterminants de la transmission du paludisme.
NoteObjectifs
- Identifier les sources de données climatiques appropriées pour le SNT
- Comprendre la structure et l’accès aux fichiers raster CHIRPS
- Télécharger et prévisualiser les rasters mensuels des précipitations à partir de CHIRPS
- Extraire les résumés des données pluviométriques par niveau infranational à l’aide de fichiers shapefiles
- Traiter par lots plusieurs rasters et préparer les données pour les flux de travail SNT
Types de données climatiques et environnementales disponibles
Grâce à la disponibilité croissante de la télédétection et d’autres sources de mégadonnées, les équipes ont désormais accès à un ensemble toujours plus vaste de produits climatiques, chacun présentant des compromis en termes de couverture, de résolution, d’accessibilité et de validation. Il n’existe pas de jeu de données unique et correct pour le SNT. Les exemples ci-dessous reflètent des sources largement utilisées et librement accessibles, mais les pays peuvent choisir différents jeux de données en fonction de leur disponibilité, de leur niveau de détail spatial ou temporel, des infrastructures disponibles ou de leur approbation par les programmes nationaux.
ImportantConsultez l’équipe SNT
Commencez toujours par demander à l’équipe SNT si elle dispose de données provenant de ses propres stations météorologiques ou météorologiques. Même si les stations météorologiques ne sont pas présentes partout, elles peuvent constituer une source d’information très fiable pour confirmer que les données extraites des images satellites ou d’autres sources reflètent bien la réalité.
| Source | Type | Format | Résolution | Accès et remarques |
|---|---|---|---|---|
| CHIRPS | Pluviométrie | Quotidiennes, mensuelles | ~5 km | Disponibles via l’interface utilisateur web ou par programmation à l’aide du package R chirps. Idéal pour les résumés infranationaux. |
| MODIS NDVI | Indice de végétation | Composite sur 16 jours | 250 m | Rasters NDVI disponibles via la page produit MODIS NDVI, en particulier le produit MOD13Q1. Souvent utilisé pour surveiller la dynamique saisonnière de la végétation et les conditions de couverture terrestre. |
| AVHRR NDVI | Indice de végétation | Composite sur 16 jours | ~4 km | Enregistrements à long terme depuis les années 1980. Disponible via NOAA. |
| IMERG | Pluviométrie | Toutes les demi-heures, quotidien | ~10 km | Estimations mondiales de la pluviométrie par satellite provenant du programme GPM de la NASA. Utile pour la surveillance en temps quasi réel, en particulier lorsque les stations au sol sont peu nombreuses. Accessible via NASA GES DISC. Nécessite un prétraitement pour l’analyse. |
| WorldClim | Normales climatiques | Mensuelles, dérivées | ~1 km | Moyennes climatiques historiques (période de référence). Utile pour déterminer l’adéquation ou comparer les anomalies. |
| CRU TS | Données sur les tendances climatiques | Mensuelles | ~50 km | Couvre la période de 1901 à aujourd’hui. Largement utilisé dans la modélisation universitaire ; détails spatiaux grossiers. |
| Services météorologiques nationaux* | Jauge ou grille | Variable | Variable | Souvent la référence en matière d’utilisation programmatique, si disponible. L’accès peut nécessiter une demande officielle, généralement coordonnée par l’équipe SNT. Exemple : Agence nationale de gestion des ressources en eau de la Sierra Leone fournit des résumés des données pluviométriques locales sur demande. |
Remarque : les services météorologiques nationaux* fournissent des données d’observation directe, et non des estimations dérivées de modèles comme les autres.
Chaque ensemble de données nécessite des compromis entre la couverture temporelle, la résolution spatiale, la facilité d’utilisation et la charge de traitement. Le choix le plus approprié dépend de l’analyse prévue et de la configuration opérationnelle de votre équipe. Veuillez prendre en considération les éléments suivants :
Période : Avez-vous besoin d’observations en temps quasi réel (par exemple pour l’alerte précoce) ou de données historiques à long terme (par exemple pour établir des références climatologiques) ? Certains ensembles de données proposent des enregistrements quotidiens depuis les années 1980, tandis que d’autres ne fournissent que des résumés mensuels ou des normales climatiques statiques. Pour la plupart des flux de travail SNT, la résolution mensuelle est la granularité minimale requise. Les données quotidiennes peuvent toujours être agrégées pour obtenir des valeurs mensuelles.
Résolution spatiale : Travaillez-vous au niveau du district (adm2/adm3) ou une échelle plus grossière est-elle suffisante ? CHIRPS fournit une résolution d’environ 5 km, adaptée aux résumés infranationaux. D’autres, comme ERA5 ou IMERG, peuvent offrir une résolution plus fine (1 km ou mieux), mais cela augmente la complexité et la taille des fichiers. Une résolution plus fine ne signifie pas toujours une meilleure précision, en particulier dans les zones où la validation au terrain est rare.
Exigences en matière d’infrastructure : Les ensembles de données à haute résolution (par exemple, quotidiens à 10 m) peuvent être exigeants en termes de stockage sur disque, de bande passante et de puissance de calcul. Les téléchargements sur plusieurs années peuvent représenter des gigaoctets de données, et le traitement peut dépasser la capacité standard d’un ordinateur portable. Pour de nombreux flux de travail, des rasters plus grossiers ou des tableaux pré-agrégés sont plus pratiques. Évaluez si votre infrastructure est capable de gérer des flux de travail raster volumineux ou si une approche simplifiée est préférable.
Préférence du pays : Certains pays ont des sources privilégiées, telles que les agences météorologiques nationales ou des ensembles de données approuvés. Lorsqu’elles sont accessibles et approuvées, elles peuvent offrir des avantages programmatiques. Cependant, leur accès est souvent restreint et ces sources ne sont pas toujours disponibles dans des formats ou des délais qui répondent aux besoins opérationnels de l’analyse SNT.
TipVous ne savez pas quoi utiliser ?
Ce qui est présenté ici n’est pas normatif. L’objectif est de disposer d’indicateurs climatiques adaptés à vos besoins opérationnels. En cas de doute, veuillez consulter vos homologues nationaux ou l’équipe SNT afin de confirmer les sources et les formats de données appropriés.
Le choix entre ces différents ensembles de données dépend du contexte. Par exemple :
Si votre objectif est d’extraire les données pluviométriques de 2020 à 2023 au niveau adm3, vous aurez besoin d’un ensemble de données qui couvre ces années de manière continue, avec une résolution spatiale suffisante pour refléter les variations infranationales. Dans ce cas, les ensembles de données maillées open source tels que CHIRPS (pour la pluviométrie) ou ERA5 (pour les données de température) constituent de bonnes options.
Ces ensembles de données sont régulièrement mis à jour, couvrent la plupart des pays où le paludisme est endémique et permettent soit l’extraction de rasters au niveau des pixels, soit des requêtes basées sur des coordonnées, en fonction de votre flux de travail. Leur résolution modérée (généralement comprise entre 5 km et 30 km) les rend efficaces à télécharger, stocker et traiter : les résumés mensuels peuvent être traités sur des ordinateurs portables standard sans nécessiter de calculs très performants.
Dans cette section, nous montrons comment travailler avec des rasters climatiques en pleine résolution (par exemple, les fichiers CHIRPS .tif) pour les équipes qui s’appuient sur cet ensemble de données ou qui disposent déjà de données raster en vrac. Bien que les exemples utilisent CHIRPS, le même flux de travail peut être adapté à d’autres ensembles de données raster maillés de structure similaire. Veuillez noter que le travail avec des données météorologiques nationales, lorsqu’elles sont fournies sous forme de tableaux récapitulatifs ou dans d’autres formats non raster, n’est pas couvert ici.
Étape par étape
Étape 1 : Configuration et téléchargement des fichiers raster CHIRPS
La première étape consiste à télécharger les fichiers raster CHIRPS pour la zone qui nous intéresse. Bien qu’ils puissent être obtenus manuellement sur le site web de CHIRPS, nous utilisons une fonction personnalisée du package sntutils pour automatiser ce processus pour l’Afrique. Avant cela, nous installons les packages requis, chargeons les fonctions nécessaires et importons le shapefile pour une extraction spatiale ultérieure.
Pour passer l’explication étape par étape, veuillez vous rendre directement au code complet à la fin de cette page.
Étape 1.1 : Configuration initiale
Pour adapter le code :
Lignes 2 et 8 : remplacez le répertoire de travail par celui dans lequel vous souhaitez enregistrer vos rasters.
Lignes 16-17 : mettez à jour le chemin d’accès au fichier afin qu’il corresponde à l’emplacement où est stocké votre shapefile contenant les limites administratives (par exemple,
votre/chemin/vers/shapefile.rds).Ligne 4 : remplacez
"sle_spatial_adm3_2021.rds"par le nom de votre shapefile.
Une fois la mise à jour effectuée, exécutez le code pour charger votre shapefile contenant les limites administratives.
Si vous avez déjà téléchargé les fichiers CHIRPS .tif ou si vous préférez gérer les téléchargements manuellement sans utiliser sntutils, vous pouvez ignorer l’étape 1.3 et passer directement à l’étape 2.
Étape 1.2 Vérifier les ensembles de données CHIRPS disponibles
Avant de télécharger des données, il est recommandé de vérifier quels ensembles de données CHIRPS sont pris en charge. La fonction chirps_options() de sntutils renvoie une liste claire des ensembles de données disponibles, y compris leur région et leur agrégation temporelle (par exemple, mensuelle).
Après avoir identifié un ensemble de données qui vous intéresse (par exemple, africa_monthly), vous pouvez vérifier les années et les mois disponibles au téléchargement à l’aide de la fonction check_chirps_available().
Il semble que les données soient disponibles de janvier 1981 à mars 2025, couvrant tous les mois de cette période jusqu’à la dernière publication disponible.
Étape 1.3 Télécharger les données raster CHIRPS
Maintenant que nous avons confirmé la disponibilité des données, nous pouvons télécharger 48 rasters mensuels CHIRPS de la pluviométrue en Afrique, couvrant la période de janvier 2020 à décembre 2023. Chaque fichier enregistre la pluviométrie totale en millimètres sur l’ensemble du continent avec une résolution d’environ 5 km. La fonction download_chirps() gère le téléchargement et, si nécessaire, la décompression, puis enregistre les fichiers avec des noms clairs préfixés par le nom de l’ensemble de données dans le répertoire spécifié. Cette configuration peut être facilement modifiée pour d’autres régions ou périodes à l’aide des options disponibles dans chirps_options().
Pour adapter le code :
Lignes 2 et 8 : remplacez
"05_climate_and environment"par le répertoire de travail dans lequel vous souhaitez enregistrer vos données climatiques.Ligne 5 : indiquez l’ensemble de données qui vous intéresse, en fonction de votre région et des options disponibles dans
"chirps_options()".Lignes 6 et 7 : définissez les dates de début et de fin de la période souhaitée.
Une fois la mise à jour effectuée, exécutez le code pour télécharger entièrement vos données CHIRPS.
Dans cet exemple axé sur l’Afrique, chaque fichier compressé pèse environ 5 Mo. Le téléchargement des 48 fichiers ne devrait donc pas prendre plus de 15 minutes avec une connexion Internet raisonnable.
Étape 2 : Charger, inspecter et traiter un seul raster CHIRPS
Avant de passer au traitement de tous les rasters CHIRPS, il est utile de suivre les étapes pour un seul fichier .tif, afin de comprendre comment les données sont traitées et transformées. Nous utiliserons le fichier raster de mai 2023 comme exemple.
*Si vous préférez ignorer cette illustration détaillée étape par étape et passer directement au traitement de tous les rasters en une seule fois, vous pouvez passer à l’étape 3 ci-dessous. Sinon, veuillez suivre les instructions pour comprendre le fonctionnement de la fonction de traitement par lots.
Étape 2.1 : Charger et nettoyer le raster
Nous lisons le raster, convertissons les valeurs manquantes CHIRPS (codées -9999) en NA et prévisualisons le fichier.
Étape 2.2 : Visualiser le raster
Nous visualisons maintenant le raster afin de vérifier qu’il est correctement chargé et qu’il représente des modèles spatiaux réalistes.
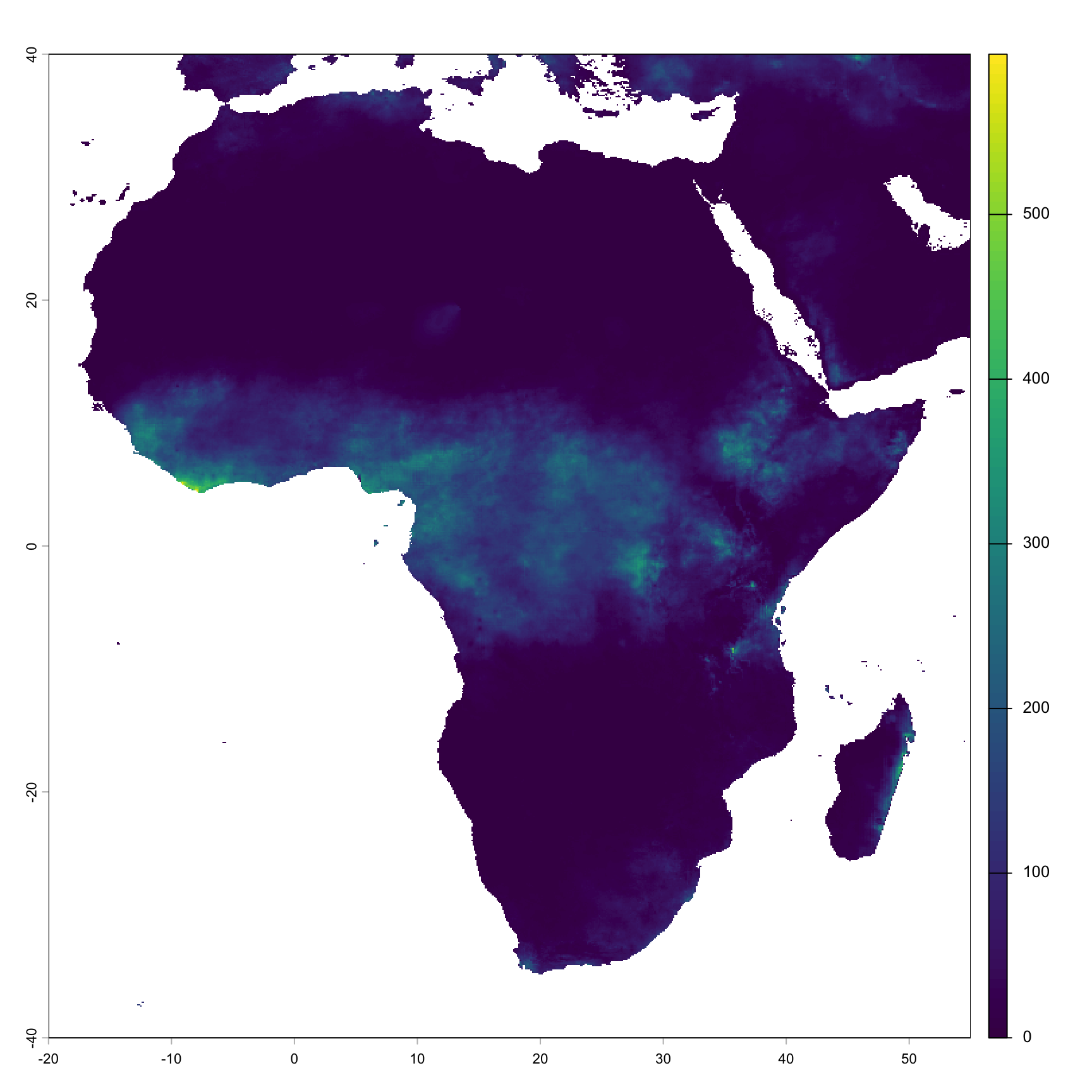
Une fois le raster chargé et visualisé, nous observons la répartition de la pluviométrie en Afrique pour le mois de mai 2023. La pluviométrie élevée en Afrique centrale et occidentale correspond aux tendances saisonnières attendues. Cela confirme que les données CHIRPS reflètent les tendances attendues et sont prêtes pour le traitement par lots.
Étape 2.3 : Extraire les valeurs de pluviométrie des rasters
Une fois le raster CHIRPS de mai 2023 chargé, nous extrayons les statistiques de pluviométrie pour chaque unité administrative. Nous alignons le système de résolution des coordonnées (SRC) du shapefile avec le raster, puis utilisons exactextractr pour calculer les valeurs moyennes de pluviométrie pour chaque polygone d’unité administrative.
Nous utilisons ici le shapefile ADM3 de la Sierra Leone (sle_spatial_adm3) à titre d’exemple. Veuillez remplacer ce fichier par votre propre shapefile correspondant à la zone qui vous intéresse.
Pour adapter le code :
Ligne 2 : remplacez chirps_may2023 par votre propre objet raster si vous utilisez un fichier différent
Ligne 7 : remplacez
fun = c("mean")par d’autres résumés si nécessaire (par exemple, c(“mean”, “sum”)).
Après avoir effectué les modifications, exécutez le bloc pour extraire les statistiques zonales de votre raster.
NoteFonctionnement de ce code et choix du résumé approprié
Le code d’exemple extrait des statistiques zonales en résumant les valeurs des pixels du raster à l’intérieur de chaque polygone de district. Plus précisément, il utilise exactextractr::exact_extract() avec fun = c("mean"), qui calcule la pluviométrie moyenne sur tous les pixels à l’intérieur des limites de chaque district.
Vous pouvez modifier ce comportement en fonction de vos besoins d’analyse :
Moyenne : moyenne de toutes les valeurs de pixels dans le polygone (utilisée dans l’exemple).
Somme : total de toutes les valeurs de pixels, utile pour les mesures cumulatives telles que la pluviométrie ou la population.
Valeur centroïde : extrait la valeur au centre du polygone, fournissant un point représentatif unique sans moyenne spatiale.
Conseil : la somme fonctionne bien pour les variables cumulatives telles que la population. Pour les taux, les proportions ou les conditions mesurées à un seul endroit, envisagez plutôt d’utiliser la moyenne ou la valeur centroïde.
Étape 2.4 Combiner avec des attributs et formater la sortie
Nous allons maintenant lier les statistiques de pluviométrie extraites aux attributs du fichier de formes du district et attribuer les métadonnées temporelles appropriées à la sortie.
# lier les valeurs extraites aux attributs d'unité administrative et formater la sortie
result_df <- cbind(sl_adm3_shp, as.data.frame(zonal_stats)) |>
dplyr::mutate(
year = 2023,
month = 5,
chirps_mean = mean,
chirps_total = sum
) |>
dplyr::select(adm0, adm1, adm2, adm3,
year, month,
chirps_mean) |>
sf::st_drop_geometry()
# prévisualiser les résultats pour mai 2023
head(result_df)Pour adapter le code :
Lignes 3-4 : mettez à jour les valeurs de l’année et du mois afin qu’elles correspondent au raster en cours de traitement.
Noms des colonnes : ajustez adm0, adm1, adm2, adm3 afin qu’ils reflètent la structure de votre propre shapefile.
Colonnes de résumé : incluez toute autre statistique (par exemple, chirps_total) si elle a été calculée.
Après personnalisation, veuillez exécuter le script pour formater et prévisualiser les résultats extraits.
Ce résultat fournit la pluviométrie moyenne et totale (en millimètres) pour chaque district en mai 2023, calculée directement à partir du raster. Ensuite, nous allons mettre cela à l’échelle pour traiter tous les mois de 2020 à 2023.
WarningVeuillez vérifier attentivement les unités
Les ensembles de données climatiques peuvent différer dans la manière dont la pluviométrie ou la température sont indiquées.
- Certains expriment la pluviométrie en millimètres (mm), d’autres en centimètres (cm) ou même en litres par mètre carré.
- La température peut être indiquée en Kelvin, en Celsius ou en maximum/minimum quotidien.
Vérifiez toujours les unités de l’ensemble de données que vous utilisez avant d’extraire ou de comparer des valeurs. Les incohérences entre les unités peuvent affecter les résultats de l’analyse sans que vous vous en rendiez compte.
Étape 3 : Traiter par lots tous les fichiers raster
Maintenant que vous avez terminé l’extraction d’un seul raster (ou si vous avez choisi de passer directement à cette étape), vous pouvez automatiser le processus pour tous les fichiers CHIRPS .tif à l’aide de la fonction sntutils::process_raster_collection().
NoteCe que fait
sntutils::process_raster_collection()
La fonction sntutils::process_raster_collection() automatise l’extraction des statistiques zonales d’un répertoire de fichiers raster climatiques par rapport à un shapefile. Elle est conçue pour fonctionner avec divers fichiers raster dont la date est intégrée dans le nom du fichier, tels que :
chirps2.0_2020_03.tifchirps2.0_03_2020.tifchirps2.0_2023.05.01.tif
La fonction :
- Analyse un dossier donné à la recherche de fichiers raster (prend en charge les formats lisibles par
terra::rast(), tels que.tif,.nc,.grd,.asc, etc.) - Détecte et analyse les métadonnées temporelles à partir des noms de fichiers (par exemple,
YYYY-MM,MM-YYYYouYYYY-MM-DD) - Assure l’alignement SRC entre les rasters et le shapefile
- Gère les valeurs manquantes de type CHIRPS (par exemple, remplace -9999 par
NA) - Extrait les statistiques zonales à l’aide de
exactextractr::exact_extract() - Permet des niveaux d’agrégation flexibles : “moyenne”, “somme”, “médiane” (et peut combiner plusieurs niveaux)
- Renvoie un cadre de données propre et ordonné, résumé par les colonnes d’ID et les unités de temps spécifiées (par exemple, année, mois)
Voici comment appliquer la fonction à vos rasters :
# Importer le shapefile des limites administratives
chirps_all <- sntutils::process_raster_collection(
directory = "05_climate_and environment/raw",
shapefile = sl_adm3_shp,
id_cols = c("adm0", "adm1", "adm2", "adm3"),
aggregations = c("mean"),
pattern = ".tif")
# Nettoyer l'ensemble de données
chirps_final <- chirps_all |>
dplyr::rename(
chirps_mean = mean,
) |>
dplyr::select(-file_name)
# Vérifier le début
chirps_final |>
dplyr::filter(year == 2023 & month == 05) |>
head()Pour adapter le code :
Ligne 2 : remplacez le chemin d’accès au répertoire où sont stockés vos fichiers raster sur votre ordinateur.
Ligne 3 : remplacez
sl_adm3_shppar votre propre objet shapefile si vous travaillez dans un autre pays ou à un autre niveau administratif.Ligne 4 : mettez à jour les id_cols afin qu’ils correspondent aux noms des colonnes de votre shapefile (par exemple, région, district, etc.).
Ligne 5 : ajustez les agrégations si vous avez besoin d’autres résumés tels que “sum” ou “median” en plus de “mean”.
Une fois la mise à jour effectuée, exécutez le code pour traiter vos rasters.
Veuillez noter que le résultat du traitement par lots pour mai 2023 doit correspondre exactement au résultat result_df produit à l’étape 2.4, ce qui confirme que les pipelines manuel et automatisé sont alignés.
Étape 4 : Visualiser les tendances mensuelles de la pluviométrie
Étape 4.1 : Préparer les données pour les visualisations
Après avoir extrait nos données de pluviométrie CHIRPS, il est important de visualiser les tendances de base avant de les enregistrer et de les utiliser pour une analyse ultérieure. Cette étape permet d’identifier les mois manquants, les zéros anormaux ou les valeurs aberrantes qui pourraient indiquer des problèmes de qualité des données ou des erreurs d’extraction.
Nous commençons par tracer la pluviométrie mensuelle totale pour un échantillon de districts afin d’inspecter les variations temporelles et d’évaluer si la saisonnalité de la pluviométrie correspond à ce que l’on sait de la dynamique locale de transmission.
Pour adapter le code :
Lignes 4 à 6 : assurez-vous que adm0, adm1 et adm2 correspondent aux colonnes de votre shapefile.
Ligne 8 : assurez-vous que chirps_rainfall_mean correspond au nom de la colonne généré par votre traitement.
- Si vous avez utilisé une agrégation différente ou renommé la colonne, mettez à jour en conséquence.
Ligne 3 : year_month est déjà créé à partir de year (année) et month (mois). Vous n’avez pas besoin de le modifier, sauf si votre structure est différente.
Une fois la mise à jour effectuée, exécutez le code pour préparer les données en vue de leur visualisation.
Étape 4.2 : Visualiser les tendances mensuelles de la pluviométrie
Nous représentons graphiquement la pluviométrie mensuelle pour un échantillon de districts afin d’évaluer les variations temporelles.
Montrer le code
# tracer les données mensuelles CHIRPS
plot <- rain_plot_data |>
ggplot2::ggplot(ggplot2::aes(x = year_month, y = avg_mean_rain)) +
ggplot2::geom_line(linewidth = 0.8, color = "steelblue") +
ggplot2::scale_x_date(
date_breaks = "6 months",
date_labels = "%b %Y",
expand = c(0.01, 0.01)
) +
ggplot2::facet_wrap(~ adm2, scales = "free_y", ncol = 4) +
ggplot2::labs(
title = "Pluviométrie mensuelle moyenne par adm2",
x = "mois",
y = "pluviométrie (mm)\n ",
caption = "Données CHIRPS provenant de https://data.chc.ucsb.edu"
) +
ggplot2::theme_minimal(base_size = 12) +
ggplot2::theme(
strip.text = ggplot2::element_text(face = "bold", size = 10),
axis.text.x = ggplot2::element_text(angle = 45, hjust = 1),
panel.spacing = ggplot2::unit(1, "lines")
)
NoteSortie
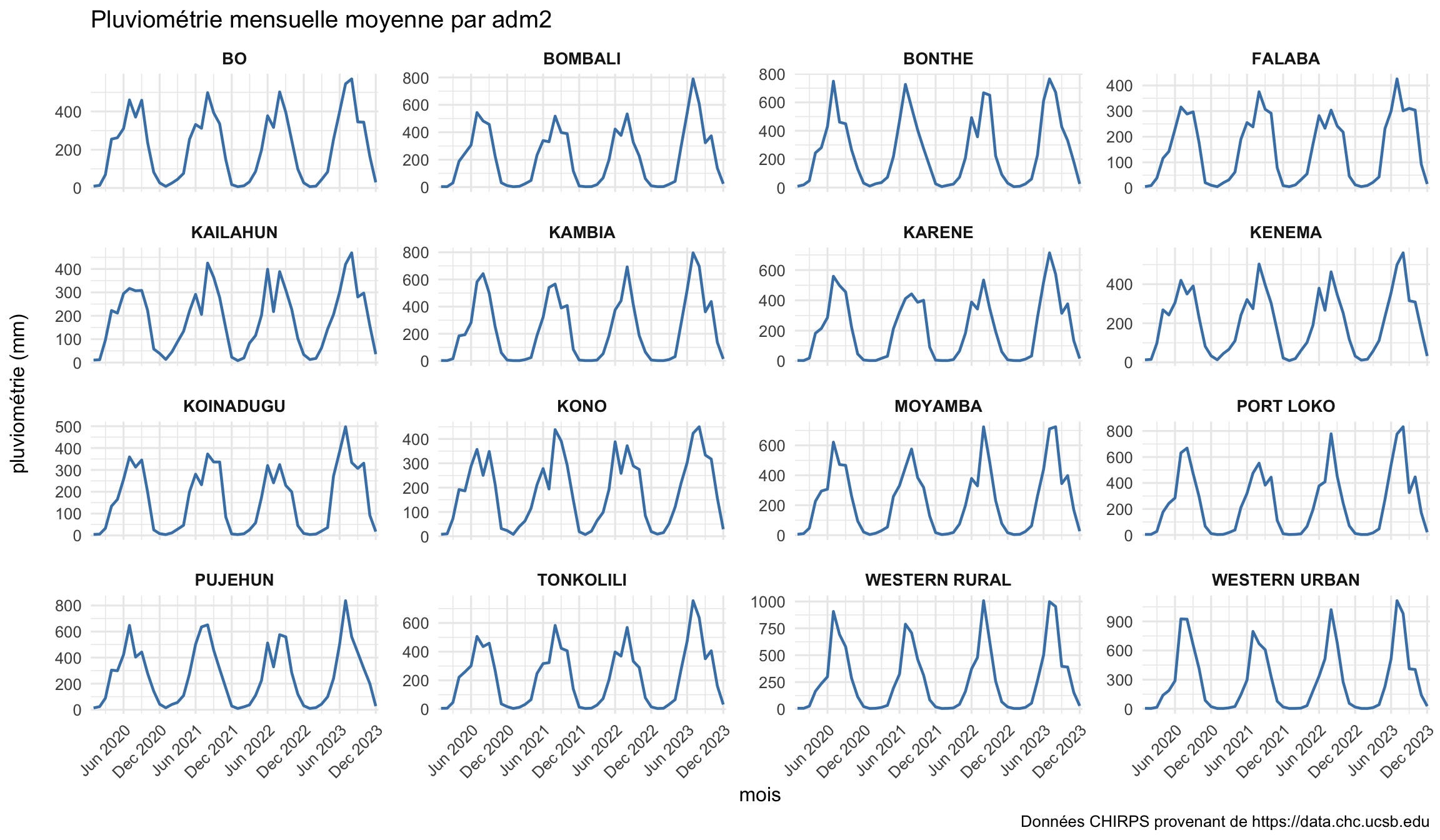
Pour adapter le code :
Ligne 2 :
year_month : devrait déjà exister dans votre ensemble de données.
avg_mean_rain : remplacez si votre colonne de pluviométrie porte un nom différent.
Ligne 9 :
facet_wrap(~ adm2):- Remplacez adm2 par le niveau administratif souhaité (par exemple, district, région, etc.).
Ligne 12 :
- titre : modifiez le texte du titre pour qu’il corresponde à votre région ou à la variable qui vous intéresse.
Ligne 15 :
- légende : mettez à jour le lien vers la source des données ou le texte si vous utilisez un autre ensemble de données.
Une fois la mise à jour effectuée, exécutez le code pour générer le graphique.
ImportantVérifier auprès de l’équipe SNT
Même si vous travaillez avec un ensemble de données climatiques ou environnementales maillées pour le SNT, veuillez vous renseigner auprès de l’équipe SNT pour savoir si elle a accès à des données d’observation provenant de stations météorologiques ou hydrologiques nationales. Même partielles, ces données au terrain constituent une référence importante pour confirmer l’exactitude des données satellitaires.
Par exemple, les couches raster telles que les estimations de pluviométrie CHIRPS ou les séries chronologiques NDVI peuvent être validées par rapport aux enregistrements observés par les stations afin de garantir que les tendances saisonnières et les gradients spatiaux reflètent les conditions réelles. Ces comparaisons permettent de garantir la fiabilité des données avant de les appliquer à une analyse épidémiologique, à une stratification des risques ou à une aide à la décision basée sur le SIG.
Que des données météorologiques locales soient disponibles ou non, présentez toujours les cartes et les séries chronologiques issues des extractions raster à l’équipe SNT pour discussion et validation avant utilisation dans des analyses ultérieures.
Enregistrons maintenant ce graphique pour référence future.
Pour adapter le code :
Ligne 3 :
Mettez à jour le chemin d’accès au fichier afin qu’il corresponde à la structure de vos dossiers.
Vous pouvez remplacer “chirps_seasonality_check_adm3_2020_2023.png” par le nom de votre fichier.
Lignes 4 à 6 : ajustez la largeur, la hauteur et la résolution si vous avez besoin d’une image de taille ou de qualité différente.
Une fois la mise à jour effectuée, exécutez le code pour enregistrer le graphique au format PNG.
Étape 5 : Enregistrer les données pluviométriques traitées
Nous enregistrons l’ensemble de données pluviométriques nettoyées et agrégées pour une utilisation ultérieure dans l’analyse de saisonnalité SNT.
# Définir le chemin d'enregistrement
save_path <- here::here("05_climate_and environment")
# Enregistrer le fichier traité au format CSV
rio::export(
rain_monthly_adm,
here::here(save_path, "processed", "chirps_rainfall_adm3_processed_2020_2023.csv")
)
# Enregistrer le fichier traité au format RDS
rio::export(
rain_monthly_adm,
here::here(save_path, "processed", "chirps_rainfall_adm3_processed_2020_2023.rds")
)Pour adapter le code :
Ligne 3 :
Mettez à jour
save_pathavec votre répertoire de sortie.avg_mean_rain : remplacez si votre colonne de pluviométrie porte un nom différent.
Noms de fichiers : modifiez les noms de fichiers (par exemple,
chirps_rainfall_raw_2020_2023.csv) afin qu’ils reflètent votre ensemble de données, votre durée temporelle ou votre niveau administratif.
Une fois la mise à jour effectuée, exécutez le code pour enregistrer vos résultats aux formats brut et traité.
Résumé
Cette section a présenté l’ensemble du processus de génération d’indicateurs mensuels de pluviométrie à l’aide des fichiers raster CHIRPS, depuis le téléchargement et l’inspection des données haute résolution .tif jusqu’à l’extraction des statistiques au niveau des districts et la visualisation des tendances saisonnières. N’oubliez pas de valider toutes les sorties avec l’équipe SNT, en présentant vos cartes et séries chronologiques ainsi que toutes les observations disponibles des stations avant de les intégrer dans des analyses en aval. Le pipeline complet est disponible à la fin de cette page pour être adapté à vos propres fichiers de forme, régions ou périodes. En suivant attentivement chacune des étapes du traitement des données, en particulier l’extraction et la visualisation, vous serez certain de savoir exactement quels résultats doivent être validés par l’équipe SNT.
Code complet
Montrer le code
#===============================================================================
# Étape 1 : Configuration et téléchargement des fichiers raster CHIRPS
#===============================================================================
# Charger les paquets requis
pacman::p_load(
terra, # Pour les opérations raster
sf, # Pour les données vectorielles
exactextractr, # Pour une extraction précise à partir de rasters
dplyr, # Pour la manipulation des données
lubridate, # Pour la gestion des dates
here # Pour la gestion des chemins d'accès aux fichiers
)
# Téléchargez la dernière version de sntutils si ce n'est pas déjà fait
devtools::install_github("ahadi-analytics/sntutils")
# importer le shapefile des limites administratives
sl_adm3_shp <- readRDS(
here::here("01_foundational/1a_administrative_boundaries",
"1ai_adm3", "sle_spatial_adm3_2021.rds")
) |>
sf::st_as_sf() # ensure it gets turned into sf format
# Vérifier les données disponibles à télécharger
sntutils::chirps_options()
# Définir le principal chemin d'accès aux données climatiques
climate_path <- "05_climate_and environment"
# Télécharger les données CHIRPS pour 2020-2023
sntutils::download_chirps(dataset = "africa_monthly",
start = "2020-01",
end = "2023-12",
out_dir = here::here(climate_path, "raw"))
#===============================================================================
# Étape 3 : Traiter par lots tous les fichiers raster
#===============================================================================
# Importer le shapefile des limites administratives
chirps_all <- sntutils::process_raster_collection(
directory = "05_climate_and environment/raw",
shapefile = sl_adm3_shp,
id_cols = c("adm0", "adm1", "adm2", "adm3"),
aggregations = c("mean"),
pattern = ".tif")
# Nettoyer l'ensemble de données
chirps_final <- chirps_all |>
dplyr::rename(
chirps_mean = mean,
) |>
dplyr::select(-file_name)
# Vérifier le début
chirps_final |>
dplyr::filter(year == 2023 & month == 05) |>
head()
#===============================================================================
# Étape 4 : Visualiser les tendances mensuelles de la pluviométrie
#===============================================================================
# préparer les données pour la visualisation
rain_plot_data <- chirps_final |>
dplyr::mutate(
year_month = lubridate::make_date(year, month, 1)
) |>
dplyr::group_by(adm0, adm1, adm2, year_month) |>
dplyr::summarise(
avg_mean_rain = mean(chirps_mean, na.rm = TRUE),
.groups = 'drop')
# tracer les données mensuelles CHIRPS
plot <- rain_plot_data |>
ggplot2::ggplot(ggplot2::aes(x = year_month, y = avg_mean_rain)) +
ggplot2::geom_line(linewidth = 0.8, color = "steelblue") +
ggplot2::scale_x_date(
date_breaks = "6 months",
date_labels = "%b %Y",
expand = c(0.01, 0.01)
) +
ggplot2::facet_wrap(~ adm2, scales = "free_y", ncol = 4) +
ggplot2::labs(
title = "Pluviométrie mensuelle moyenne par adm2",
x = "mois",
y = "pluviométrie (mm)\n ",
caption = "Données CHIRPS provenant de https://data.chc.ucsb.edu"
) +
ggplot2::theme_minimal(base_size = 12) +
ggplot2::theme(
strip.text = ggplot2::element_text(face = "bold", size = 10),
axis.text.x = ggplot2::element_text(angle = 45, hjust = 1),
panel.spacing = ggplot2::unit(1, "lines")
)
# générer le graphique
plot
# enregistrer le graphique
ggplot2::ggsave(
plot = adm3_pop_map,
here::here(
"03_output/3a_figures/chirps_seasonality_check_adm3_2020_2023.png"),
width = 12, height = 7, dpi = 300
)
#===============================================================================
# Étape 5 : Enregistrer les données pluviométriques traitées
#===============================================================================
# Définir le chemin d'enregistrement
save_path <- here::here("05_climate_and environment")
# Enregistrer le fichier brut au format CSV
rio::export(rain_monthly_adm,
here::here(save_path, "raw", "chirps_rainfall_raw_2020_2023.csv"))
# Enregistrer le fichier brut au format RDS
rio::export(rain_monthly_adm,
here::here(save_path, "raw", "chirps_rainfall_raw_2020_2023.rds"))
# Enregistrer le fichier traité au format CSV
rio::export(
rain_monthly_adm,
here::here(save_path, "processed",
"chirps_rainfall_adm3_processed_2020_2023.csv")
)
# Enregistrer le fichier traité au format RDS
rio::export(
rain_monthly_adm,
here::here(save_path, "processed",
"chirps_rainfall_adm3_processed_2020_2023.rds")
)
#===============================================================================
# Fin du code
#===============================================================================