# installer `pacman` s'il n'est pas déjà installé
if (!requireNamespace("pacman", quietly = TRUE)) {
install.packages("pacman")
}
# charger les packages requis avec pacman
pacman::p_load(
dplyr, # manipulation des données
ggplot2, # graphiques
ggtext, # texte markdown dans ggplot2
here, # gestion des chemins de fichiers
lubridate, # gestion des dates
naniar, # visualisation et analyse des données manquantes
tidyr, # restructuration des données
cli, # messages de journalisation propres
scales, # formatage des nombres
UpSetR, # graphiques upset pour la co-non-disponibilité
wesanderson # palettes de couleurs
)Méthodes de détection des données manquantes
Aperçu
Les données manquantes constituent un défi persistant dans les ensembles de données de santé publique et sont particulièrement pertinentes pour le processus SNT, où plusieurs sources de données doivent être intégrées à travers le temps, les niveaux administratifs et les plateformes de déclaration. L’exhaustivité et la cohérence de ces données sous-tendent la stratification des risques, l’allocation des ressources et l’évaluation de l’impact des interventions.
Ce défi est particulièrement aigu en Afrique subsaharienne, où 95 % des décès mondiaux dus au paludisme surviennent et où les systèmes d’information sanitaire font face aux pressions structurelles les plus importantes. Dans les systèmes de routine tels que DHIS2, qui constituent l’épine dorsale de la déclaration du paludisme dans la région, les données manquantes peuvent suivre des schémas reconnaissables liés au fonctionnement du système de santé, bien qu’une certaine part d’aléatoire puisse également être présente. Toutes les données manquantes ne sont pas dues à des erreurs, et toutes ne doivent pas ou ne peuvent pas être imputées.
Les lacunes dans les données DHIS2 sont déterminées par des contraintes structurelles sous-jacentes. Celles-ci comprennent les pannes d’internet, les téléchargements tardifs, la supervision limitée, les ruptures de stock des registres, le manque de personnel et la gestion peu claire des zéros par rapport aux valeurs manquantes. Ces problèmes contribuent à des schémas de déclaration inégaux selon les types d’établissements et les saisons. Les hôpitaux ont tendance à déclarer de manière moins régulière que les postes de santé, comme on peut l’observer au Sénégal, où les postes de santé ont maintenu une exhaustivité de déclaration plus élevée que les hôpitaux sur plusieurs années. La déclaration est également plus complète pendant la saison des pluies, certains mois affichant une augmentation de 7,5 % des soumissions (Sénégal). Au Ghana, les totaux de consultations externes étaient fréquemment soumis tandis que les indicateurs clés du traitement du paludisme étaient laissés vides, créant des lacunes sélectives. De même, dans l’État de Gombe au Nigéria, près de 40 % des enregistrements mensuels attendus étaient incomplets, et les indicateurs liés aux interventions tels que IPTp présentaient des taux de données manquantes disproportionnellement élevés. Lors des campagnes ou des périodes de forte charge de travail, les systèmes de déclaration parallèles et les priorités concurrentes augmentent davantage le risque de données manquantes ou contradictoires, comme l’ont montré l’Éthiopie et la Tanzanie, où des systèmes fragmentés et une utilisation peu claire des champs vides ont affaibli la fiabilité des données.
Ces lacunes systématiques créent des angles morts analytiques qui compromettent les résultats du SNT. Les zones à faible surveillance peuvent sembler avoir une charge moins élevée en raison d’une sous-déclaration, tandis que les zones à forte charge avec une faible connectivité peuvent être sous-représentées dans l’allocation des ressources. Si elles ne sont pas traitées, les données manquantes biaisent les estimations, faussent la stratification des risques, donnent une image inexacte de la couverture et affaiblissent le lien entre les intrants et les résultats. Elles réduisent également la stabilité des cartes de risques et la fiabilité des projections d’impact.
En même temps, toutes les données manquantes ne doivent pas être imputées. Certaines lacunes sont dues à un statut inactif d’établissement de santé, par exemple un établissement pas encore opérationnel. D’autres reflètent des valeurs manquantes pour des raisons qui ne peuvent pas être déduites des données disponibles. Dans ces cas, l’imputation n’est pas appropriée. Nous devons d’abord comprendre pourquoi les données manquent. Cela implique d’évaluer si la non-disponibilité des données est entièrement aléatoire, liée à d’autres variables observées, ou liée aux valeurs manquantes elles-mêmes.
Compte tenu de la complexité de ces décisions, la suppression des enregistrements incomplets est rarement justifiée. Comprendre la cause et les schémas de non-disponibilité des données est nécessaire pour déterminer les approches analytiques appropriées, qu’il s’agisse d’exclure certains enregistrements, d’appliquer une inférence logique ou de mettre en œuvre des méthodes statistiques qui préservent la structure spatiale et temporelle des données.
NoteObjectifs
- Apprendre des approches systématiques pour détecter et visualiser les schémas de données manquantes dans les systèmes de surveillance
- Examiner la non-disponibilité des données selon les dimensions temporelles, spatiales et démographiques
- Identifier les zéros structurels, les zéros légitimes et les incohérences logiques dans les indicateurs connexes
- Distinguer les mécanismes de données manquantes MCAR, MAR et MNAR
- Appliquer des visualisations diagnostiques pour évaluer la qualité des données et l’exhaustivité de la déclaration
- Générer des évaluations complètes des données manquantes pour orienter les décisions analytiques
Comprendre les données manquantes
Avant de procéder à toute approche analytique, il est important de comprendre les types de non-disponibilité présents dans l’ensemble de données, et d’identifier les méthodes les plus appropriées pour traiter chaque type, qu’il s’agisse de l’exclusion, de la logique clinique ou de techniques statistiques.
Comprendre les types de données manquantes
Lorsqu’on travaille avec des données incomplètes, il est important de comprendre pourquoi les valeurs sont manquantes. Cela détermine si l’imputation est appropriée.
TipSchémas clés à examiner pour déterminer le type de non-disponibilité des données
- Lacunes temporelles : Certains mois ou saisons sont-ils systématiquement sous-déclarés ?
- Lacunes spatiales : Existe-t-il des schémas cohérents entre les districts ou les régions ? Lorsque les données des établissements sont rares, les schémas de niveau supérieur peuvent orienter les approches analytiques en utilisant les établissements voisins du même type.
- Lacunes au niveau des établissements : Les taux de déclaration varient-ils selon le type d’établissement (par exemple, hôpitaux par rapport aux postes de santé), la propriété ou le volume de services ?
- Lacunes démographiques : Les données sont-elles plus fréquemment manquantes pour des groupes d’âge spécifiques (par exemple, les enfants de moins de cinq ans, les adolescents, les femmes enceintes) ?
- Lacunes au niveau des variables : Certains indicateurs (par exemple,
IPTp3, disponibilité de l’ACT) sont-ils plus fréquemment laissés vides ?
Ces schémas aident à identifier où la non-disponibilité des données se produit et pourquoi elle se produit. Comprendre ces schémas est la première étape pour diagnostiquer si la non-disponibilité est Manquante Complètement au Hasard (MCAR), Manquante au Hasard (MAR), ou Manquante Non au Hasard (MNAR).
Une fois les schémas identifiés, utilisez-les pour évaluer le mécanisme à l’origine des valeurs manquantes. Il existe trois principaux types de non-disponibilité des données, et comprendre lequel nous avons affaire nous aide à prendre des décisions analytiques éclairées sur la façon de traiter les données manquantes.
Toutes les lacunes dans les données ne reflètent pas une non-disponibilité. Certaines valeurs sont absentes parce qu’elles n’étaient jamais censées être présentes en premier lieu. Celles-ci reflètent un statut inactif de l’établissement de santé, et non des données manquantes. Par exemple, un établissement peut ne pas avoir été opérationnel pendant une période donnée, ou n’avoir jamais déclaré un indicateur spécifique. Dans de tels cas, l’absence de données doit être marquée comme non applicable et exclue de toute procédure d’imputation.
- Manquante Complètement au Hasard (MCAR)
Ce que cela signifie : Les données manquent sans raison particulière. La non-disponibilité est sans rapport avec quoi que ce soit dans l’ensemble de données.
Exemple : Supposons que certains rapports mensuels manquent parce qu’une pile de formulaires papier a été perdue lors d’une inondation. L’inondation ne ciblait pas des établissements ou des mois spécifiques, c’était aléatoire. Dans ce cas, les données manquantes sont MCAR.
Implication : L’imputation est généralement acceptable pour les données MCAR en utilisant des méthodes simples. Cependant, nous pouvons analyser en toute sécurité les données non manquantes. Elles sont toujours représentatives de l’ensemble.
- Manquante au Hasard (MAR)
Ce que cela signifie : La non-disponibilité est liée à quelque chose d’autre dans l’ensemble de données, mais pas à la valeur manquante elle-même.
Exemple : Imaginez que les rapports sur les cas de paludisme confirmés ont plus de chances d’être manquants dans les hôpitaux que dans les postes de santé. Mais nous savons quels établissements sont des hôpitaux et lesquels sont des postes de santé. La non-disponibilité n’est donc pas aléatoire, mais elle est explicable sur la base d’une autre variable : le type d’établissement.
Implication : Nous pouvons utiliser les informations dont nous disposons (comme le type d’établissement, le mois ou la région) pour prédire et imputer les valeurs manquantes. La plupart des méthodes d’imputation supposent un mécanisme MAR.
- Manquante Non au Hasard (MNAR)
Ce que cela signifie : La non-disponibilité est liée à la valeur qui manque, et elle ne peut pas être expliquée en utilisant d’autres informations dans les données.
Exemple : Supposons que certains établissements ne déclarent pas les décès dus au paludisme parce qu’ils craignent que cela reflète mal leur performance. La non-disponibilité n’est pas aléatoire et n’est pas expliquée par une variable de l’ensemble de données. Nous ne savons pas quels décès manquent, et nous ne pouvons pas les estimer de manière fiable.
Implication : L’imputation est risquée. Les données sont biaisées d’une manière qui ne peut pas être corrigée sans informations supplémentaires.
| Type | Cause | Peut être imputé ? | Exemple |
|---|---|---|---|
| MCAR | Facteurs externes aléatoires sans rapport avec aucune variable de l’ensemble de données | Oui | Rapports mensuels perdus lors d’une inondation, sans schéma systématique par lieu, période ou indicateur |
| MAR | La non-disponibilité dépend des variables observées | Oui | Les hôpitaux déclarent moins régulièrement que les postes de santé, mais le type d’établissement est connu et enregistré |
| MNAR | La non-disponibilité dépend de la valeur non observée elle-même | Déconseillé | Les établissements sous-déclarent les décès dus au paludisme pour éviter un contrôle ; la non-disponibilité ne peut pas être expliquée par d’autres variables |
ImportantConsultez l’équipe SNT
Si le mécanisme de non-disponibilité des données n’est pas clair (MCAR, MAR ou MNAR), consultez l’équipe SNT. Des schémas qui semblent techniques peuvent refléter des problèmes opérationnels connus (par exemple, les ruptures de stock, les déclarations parallèles lors des campagnes). Obtenir leurs contributions tôt peut prévenir des choix d’imputation incorrects par la suite.
Étape par étape
Cette section étape par étape montre comment détecter systématiquement les schémas de non-disponibilité en utilisant nos données DHIS2 de Sierra Leone (précédemment assemblées dans la page de prétraitement des données DHIS2). Elle s’appuie sur les principes exposés ci-dessus, en soulignant l’importance de détecter et de comprendre les schémas de données manquantes.
Les exemples se concentrent sur l’identification des schémas temporels, spatiaux et systématiques de non-disponibilité qui orientent nos décisions de classification. Comprendre ces schémas est nécessaire avant de passer à la page Méthodes d’imputation, où nous mettons en œuvre des techniques d’imputation structurelle et statistique.
Étape 1 : Installer et charger les bibliothèques
Commencez par installer et/ou charger les packages nécessaires à la manipulation des données, à la visualisation et à la détection des données manquantes.
Pour adapter le code :
- Ne modifiez rien dans le code ci-dessus
Show the code
from pathlib import Path
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
import matplotlib.ticker as mticker
import numpy as np
import pandas as pd
from pyprojroot import here
# ── assistants cli ───────────────────────────────────────────────────────────
def cli_header(message):
print(f"\n{message}")
def cli_info(message):
print(f"INFO: {message}")
def cli_success(message):
print(f"SUCCESS: {message}")
def cli_warning(message):
print(f"WARNING: {message}")
def cli_danger(message):
print(f"ERROR: {message}")
def anti_join(left, right, on):
"""Retourne les lignes de left sans correspondance dans right."""
right_keys = right[on].drop_duplicates()
return (
left.merge(right_keys, on=on, how="left", indicator=True)
.loc[lambda x: x["_merge"] == "left_only"]
.drop(columns="_merge")
)Pour adapter le code :
- Ne modifiez rien dans le code ci-dessus
Étape 2 : Charger les données
Chargez les données de surveillance DHIS2 et préparez-les pour la détection des données manquantes.
Dans cet exemple, nous nous concentrons sur les cinq dernières années (les données s’arrêtent en décembre 2023), donc filtrez tout ce qui est antérieur à 2019.
Show the code
# lire les données de surveillance traitées produites par le flux d'importation
df_routine <- readRDS(
here::here(
"01_data",
"1.2_epidemiology",
"1.2a_routine_surveillance",
"processed",
"clean_malaria_routine_data_final.rds"
)
) |>
# supprimer l'étiquette de source d'importation reportée depuis import.qmd
dplyr::select(-dplyr::any_of("sheet_admin")) |>
# filtrer sur les cinq dernières années
dplyr::filter(year >= 2019) |>
dplyr::rename(maladm_hf_u5 = maladm_u5) |>
dplyr::mutate(
# ym : libellé année-mois lisible, utilisé comme axe x discret
ym = format(date, "%Y-%m"),
# date reste de classe Date (déjà Date dans le .rds produit par import.qmd)
date = as.Date(date)
)Pour adapter le code :
- Lignes 2-8 : Mettez à jour le chemin pour pointer vers le fichier de surveillance de routine traité produit par le flux d’importation (voir la page de prétraitement des données DHIS2).
- Ligne 14 : Filtrez les données sur la période d’intérêt.
- Ligne 15 : Supprimez la ligne
dplyr::rename()si l’ensemble de données utilise déjà le nom de colonne cible.
Show the code
from pathlib import Path
import pandas as pd
from pyprojroot import here
# lire les données de surveillance traitées produites par le flux d'importation.
# le .rds (chargé par R) et le .parquet (chargé ici) sont écrits à partir
# du même dhis2_df dans import.qmd : les deux langages voient les mêmes données.
data_path = Path(here(
"01_data/1.2_epidemiology/1.2a_routine_surveillance/processed/"
"clean_malaria_routine_data_final.parquet"
))
df_routine = (
pd.read_parquet(data_path)
# supprimer l'étiquette de source d'importation reportée depuis import.qmd
.drop(columns="sheet_admin", errors="ignore")
# filtrer sur les cinq dernières années
.loc[lambda d: d["year"] >= 2019]
.rename(columns={"maladm_u5": "maladm_hf_u5"})
.assign(date=lambda d: pd.to_datetime(d["date"], errors="coerce"))
.assign(ym=lambda d: d["date"].dt.strftime("%Y-%m"))
.reset_index(drop=True)
)Pour adapter le code :
- Lignes 6-12 : Mettez à jour le chemin pour pointer vers le fichier de surveillance de routine traité produit par le flux d’importation (voir la page de prétraitement des données DHIS2).
- Ligne 14 : Filtrez les données sur la période d’intérêt.
- Ligne 15 : Supprimez la ligne
.rename()si l’ensemble de données utilise déjà le nom de colonne cible.
Étape 3 : Distinguer les lacunes de déclaration des données manquantes au niveau des indicateurs
Avant d’analyser les tendances temporelles, spatiales et par type d’établissement, il est utile de distinguer trois concepts souvent confondus sous le terme « données manquantes » :
- Complétude des déclarations : un rapport a-t-il été soumis pour un établissement-mois donné ?
- Données manquantes conditionnelles : parmi les rapports soumis, quels indicateurs ont été laissés vides ?
- Périodes non applicables : les mois antérieurs à l’ouverture d’un établissement ou postérieurs à l’arrêt de ses déclarations ne sont pas manquants. Ils ne sont simplement pas attendus.
Une bande verticale de mois « manquants » dans une carte thermique signifie généralement qu’aucun rapport n’a été soumis (toute la ligne est NA). Une cellule manquante isolée dans un rapport par ailleurs complet a une signification très différente et un mécanisme distinct. Démêler ces cas est la première étape avant de pouvoir interpréter correctement l’une quelconque des visualisations ci-dessous.
WarningFiltrer d’abord sur les établissements-mois actifs
Les périodes non applicables (mois antérieurs à l’ouverture d’un établissement, postérieurs à l’arrêt de ses déclarations ou pendant des interruptions de déclaration) sont définies sur la page Déterminer le statut actif et inactif. Exécutez ce flux de travail en premier ; les analyses ci-dessous supposent que df_routine a été filtré sur les établissements-mois actifs. L’inclusion de mois non encore actifs ou déjà inactifs gonflera les taux de données manquantes observés à chaque étape suivante.
Étape 3.1 : Données manquantes conditionnelles au sein des rapports soumis
Un établissement-mois est considéré comme un rapport soumis lorsqu’au moins un indicateur principal est renseigné. Parmi les rapports soumis, le pourcentage de chaque indicateur laissé vide indique si les données manquantes relèvent d’une pratique de remplissage du formulaire (indicateurs spécifiques volontairement omis) ou d’un échec de déclaration (lignes entières manquantes). Au sein d’un établissement-mois actif, un indicateur manquant devrait relever du premier cas.
Afficher le code
# définir les indicateurs principaux signalant qu'un rapport a été soumis
core_inds <- c("test", "conf", "maltreat")
# marquer chaque établissement-mois comme déclarant ou non
df_routine <- df_routine |>
dplyr::mutate(
report_submitted = dplyr::if_any(
dplyr::all_of(core_inds),
~ !is.na(.x)
)
)
# données manquantes conditionnelles : parmi les rapports soumis uniquement,
# quel % de chaque indicateur a été laissé vide ?
conditional_missing <- df_routine |>
dplyr::filter(report_submitted) |>
dplyr::summarise(
dplyr::across(
dplyr::all_of(core_inds),
~ round(mean(is.na(.x)) * 100, 1)
)
) |>
tidyr::pivot_longer(
dplyr::everything(),
names_to = "indicator",
values_to = "pct_missing_given_reported"
)
conditional_missing |>
dplyr::rename(
Indicateur = indicator,
`% manquant sachant déclaré` = pct_missing_given_reported
) |>
knitr::kable(align = "lr", digits = 1)Pour adapter le code :
- Ligne 2 : Mettez à jour
core_indsavec les indicateurs signalant qu’un rapport a été soumis dans l’ensemble de données.
Afficher le code
import pandas as pd
# définir les indicateurs principaux signalant qu'un rapport a été soumis
core_inds = ["test", "conf", "maltreat"]
# marquer chaque établissement-mois comme déclarant ou non
df_routine = df_routine.assign(
report_submitted=lambda d: d[core_inds].notna().any(axis=1)
)
# données manquantes conditionnelles : parmi les rapports soumis uniquement,
# quel % de chaque indicateur a été laissé vide ?
conditional_missing = (
df_routine.loc[df_routine["report_submitted"]]
[core_inds]
.isna()
.mean()
.mul(100)
.round(1)
.rename_axis("indicator")
.reset_index(name="pct_missing_given_reported")
)
conditional_missingPour adapter le code :
- Ligne 4 : Mettez à jour
core_indsavec les indicateurs signalant qu’un rapport a été soumis dans l’ensemble de données.
Étape 3.2 : Résumé quantitatif par variable
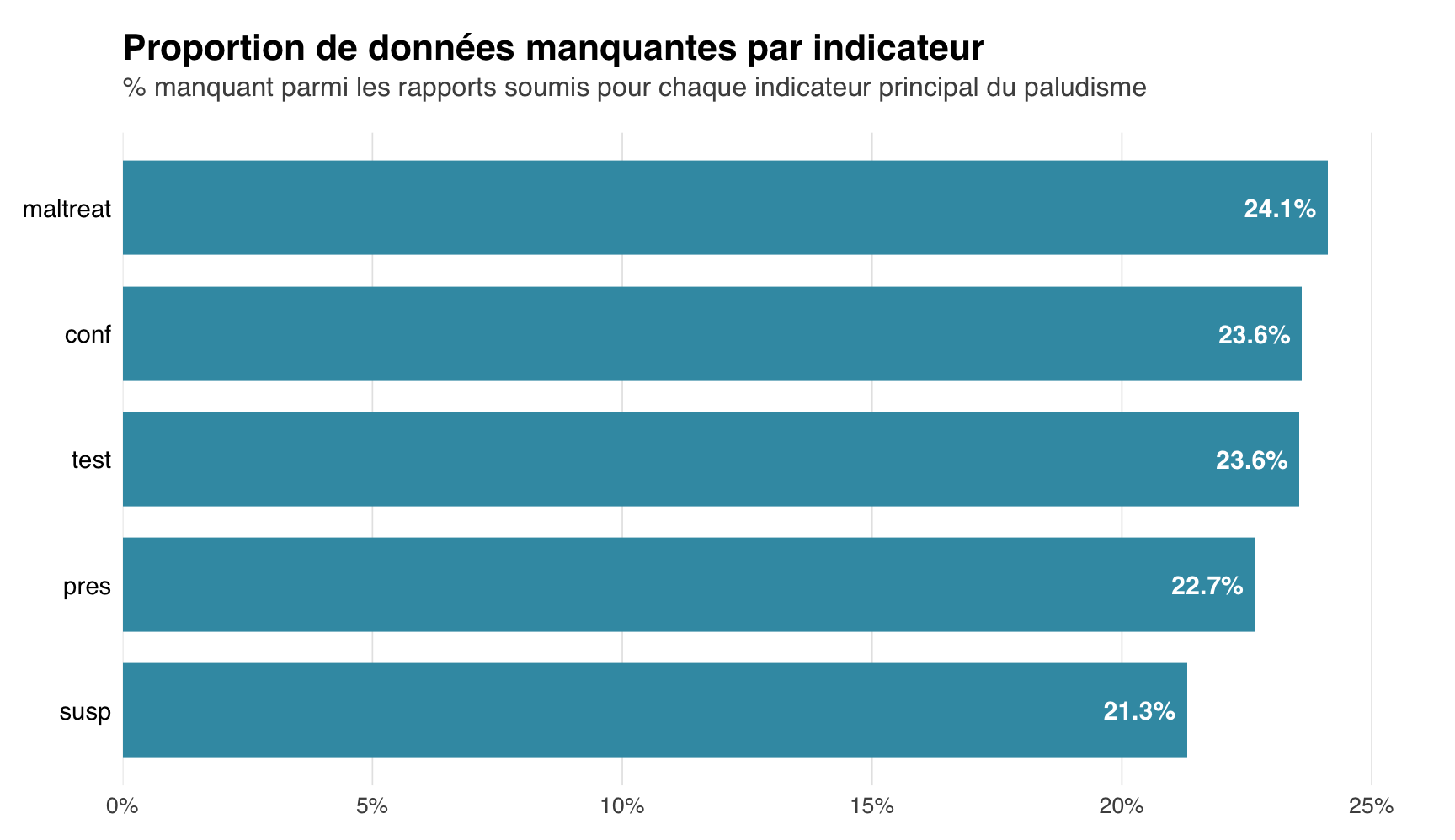
Un résumé tabulaire et un diagramme en barres donnent une vue par variable de la proportion globale de données manquantes. Le diagramme trie les indicateurs par taux de données manquantes, ce qui permet d’identifier facilement les indicateurs qui méritent un examen plus approfondi.
Afficher le code
# variables à résumer
summary_vars <- c("test", "susp", "pres", "conf", "maltreat")
# calculer le % de données manquantes pour les indicateurs agrégés principaux
miss_summary <- naniar::miss_var_summary(
df_routine |>
dplyr::select(dplyr::all_of(summary_vars))
) |>
dplyr::mutate(pct_miss = as.numeric(pct_miss))
# diagramme en barres du % de données manquantes par variable
miss_summary |>
dplyr::mutate(
variable = factor(variable, levels = rev(variable)),
label_text = paste0(round(pct_miss, 1), "%"),
inside = pct_miss > max(pct_miss) * 0.15
) |>
ggplot2::ggplot(ggplot2::aes(x = pct_miss, y = variable)) +
ggplot2::geom_col(fill = "#3B9AB2", width = 0.75) +
ggplot2::geom_text(
ggplot2::aes(
label = label_text,
hjust = ifelse(inside, 1.15, -0.15),
colour = ifelse(inside, "white", "grey20")
),
size = 4,
fontface = "bold",
family = "sans"
) +
ggplot2::scale_colour_identity() +
ggplot2::scale_x_continuous(
expand = ggplot2::expansion(mult = c(0, 0.05)),
labels = function(x) paste0(x, "%")
) +
ggplot2::labs(
title = "Proportion de données manquantes par indicateur",
subtitle = paste(
"% manquant parmi les rapports soumis pour chaque",
"indicateur principal du paludisme"
),
x = NULL,
y = NULL
) +
ggplot2::theme_minimal(base_family = "sans") +
ggplot2::theme(
plot.title = ggplot2::element_text(
size = 16,
face = "bold",
margin = ggplot2::margin(b = 4)
),
plot.subtitle = ggplot2::element_text(
size = 12,
colour = "grey30",
margin = ggplot2::margin(b = 14)
),
axis.text.y = ggplot2::element_text(size = 11, colour = "black"),
axis.text.x = ggplot2::element_text(size = 10, colour = "grey30"),
panel.grid.major.y = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank(),
panel.grid.major.x = ggplot2::element_line(
colour = "grey90",
size = 0.3
),
axis.ticks = ggplot2::element_blank(),
plot.margin = ggplot2::margin(15, 30, 10, 10)
)
NoteSortie
Pour adapter le code :
- Ligne 2 : Mettez à jour
summary_varspour correspondre aux indicateurs d’intérêt de l’ensemble de données.
TipCo-occurrence des données manquantes et test MCAR de Little comme diagnostics supplémentaires
Deux extensions aux diagnostics ci-dessus sont utiles lorsque le résumé de base laisse le mécanisme ambigu :
- Co-occurrence des données manquantes :
naniar::gg_miss_upset(df_routine |> dplyr::select(test, susp, pres, conf, maltreat), nsets = 5)montre quels indicateurs sont manquants ensemble. Nécessite le packageUpSetR. Une seule grande intersection pointe vers un échec de déclaration au niveau du rapport ; de nombreuses petites intersections pointent vers une pratique de remplissage du formulaire. - Test MCAR de Little :
naniar::mcar_test(df_routine |> dplyr::select(test, conf, maltreat))retourne une p-valeur pour l’hypothèse nulle que les données sont MCAR. Une p-valeur faible soutient MAR ou MNAR. Le test peut être lent sur les grands ensembles de données.
Afficher le code
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
import pandas as pd
# résumé tabulaire du % de données manquantes pour les indicateurs agrégés principaux
summary_vars = ["test", "susp", "pres", "conf", "maltreat"]
miss_summary = (
pd.DataFrame({
"variable": summary_vars,
"n_miss": [df_routine[v].isna().sum() for v in summary_vars],
"pct_miss": [
round(df_routine[v].isna().mean() * 100, 1)
for v in summary_vars
],
})
.sort_values("pct_miss", ascending=False)
.reset_index(drop=True)
)
# diagramme en barres du % de données manquantes par variable (horizontal, trié décroissant)
vmax = float(miss_summary["pct_miss"].max())
threshold = vmax * 0.15
fig, ax = plt.subplots(figsize=(9, 5.2))
bars = ax.barh(
miss_summary["variable"],
miss_summary["pct_miss"],
color="#3B9AB2",
height=0.75
)
ax.invert_yaxis()
# étiquettes de valeurs : à l'intérieur de la barre (blanc) si l'espace le permet,
# à l'extérieur (gris) pour les barres courtes
for bar, val in zip(bars, miss_summary["pct_miss"]):
label = f"{round(val, 1)}%"
if val > threshold:
ax.text(
val - vmax * 0.012,
bar.get_y() + bar.get_height() / 2,
label,
va="center",
ha="right",
color="white",
fontsize=11,
fontweight="bold"
)
else:
ax.text(
val + vmax * 0.012,
bar.get_y() + bar.get_height() / 2,
label,
va="center",
ha="left",
color="#333333",
fontsize=11,
fontweight="bold"
)
# titre (grand, gras) + sous-titre (plus petit, gris)
fig.suptitle(
"Proportion de données manquantes par indicateur",
fontsize=16,
fontweight="bold",
x=0.05,
ha="left",
y=0.98
)
ax.set_title(
"% manquant parmi les rapports soumis pour chaque indicateur principal du paludisme",
fontsize=12,
color="#555555",
loc="left",
pad=8
)
ax.set_xlabel("")
ax.set_ylabel("")
ax.xaxis.set_major_formatter(
mticker.FuncFormatter(lambda x, _: f"{int(x)}%")
)
ax.tick_params(left=False, labelsize=11, colors="#333333")
ax.tick_params(axis="x", colors="#555555", labelsize=10)
# apparence épurée : pas de bordure, seulement de légères lignes de grille sur l'axe x
for spine in ax.spines.values():
spine.set_visible(False)
ax.grid(axis="x", color="#E5E5E5", linewidth=0.6)
ax.grid(axis="y", visible=False)
ax.set_axisbelow(True)
ax.set_xlim(0, max(vmax * 1.05, 10))
plt.tight_layout(rect=[0, 0, 1, 0.94])
NoteSortie
(0.0, 25.305000000000003)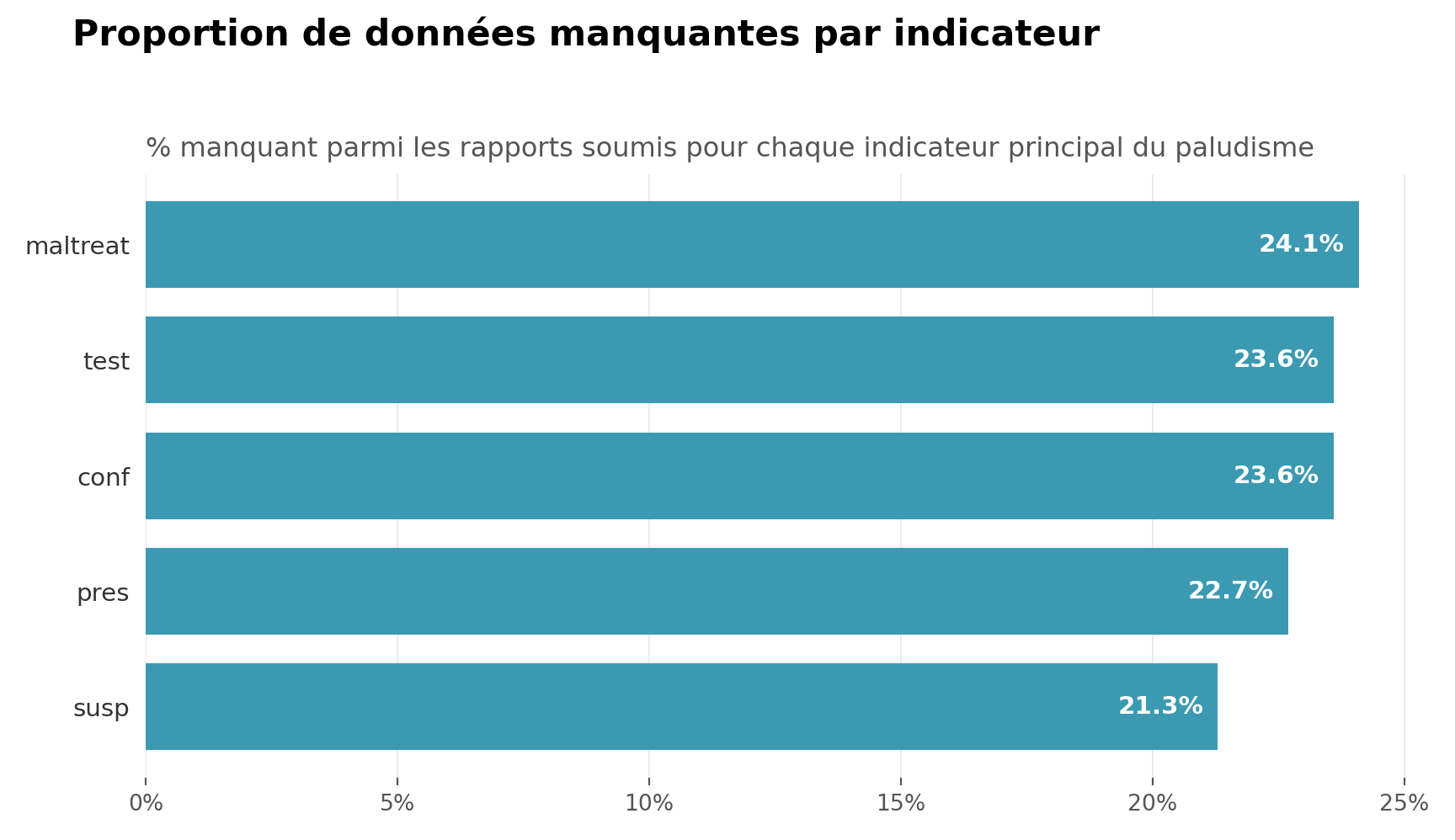
Pour adapter le code :
- Ligne 7 : Mettez à jour la liste des indicateurs dans
summary_varspour correspondre à l’ensemble de données.
ImportantConsultez l’équipe SNT
Les indicateurs présentant un taux de données manquantes très élevé ou de 100 % signalent souvent que la valeur se trouve ailleurs, et non qu’elle est véritablement absente. La gestion des données SNT est itérative : un indicateur qui apparaît vide au niveau de l’établissement peut se trouver dans un jeu de données mère différent (un formulaire de déclaration agrégé, un module de plateforme distinct, un système de déclaration parallèle, ou un champ renommé). Avant de traiter ces indicateurs comme des lacunes analytiques, consultez l’équipe SNT pour confirmer si l’indicateur est collecté ailleurs ou si l’ensemble de données analysé est le bon point de départ. Ce qui ressemble à un problème de données est souvent un problème de sourçage que l’équipe a déjà résolu.
Le tableau des données manquantes conditionnelles et le résumé global permettent ensemble de déterminer si les lacunes observées en aval sont principalement des échecs de déclaration (lignes entières manquantes, tous les indicateurs co-manquants) ou une pratique de remplissage du formulaire (indicateurs spécifiques manquants malgré le dépôt d’un rapport). Les deux nécessitent des réponses différentes sur la page Méthodes d’imputation.
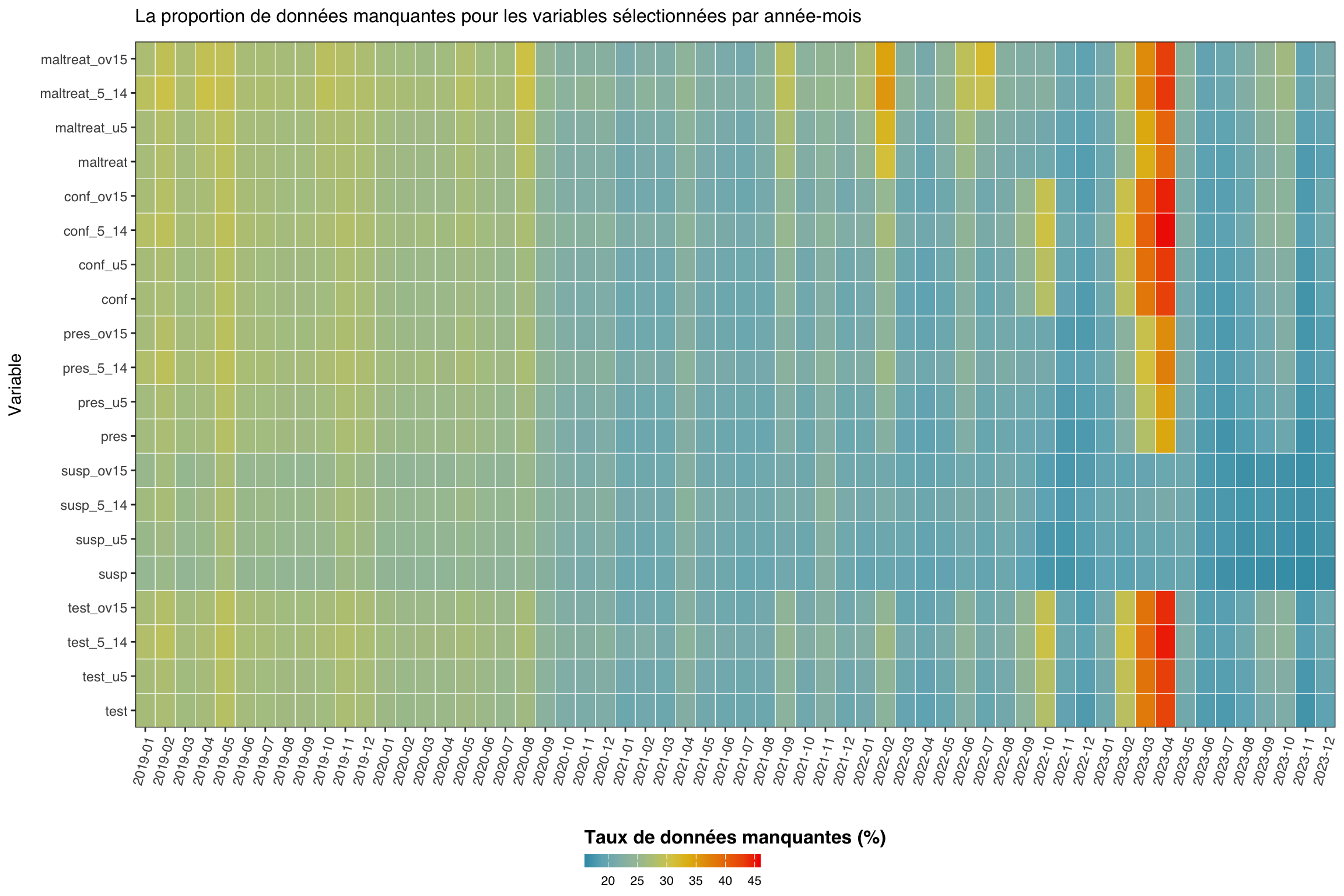
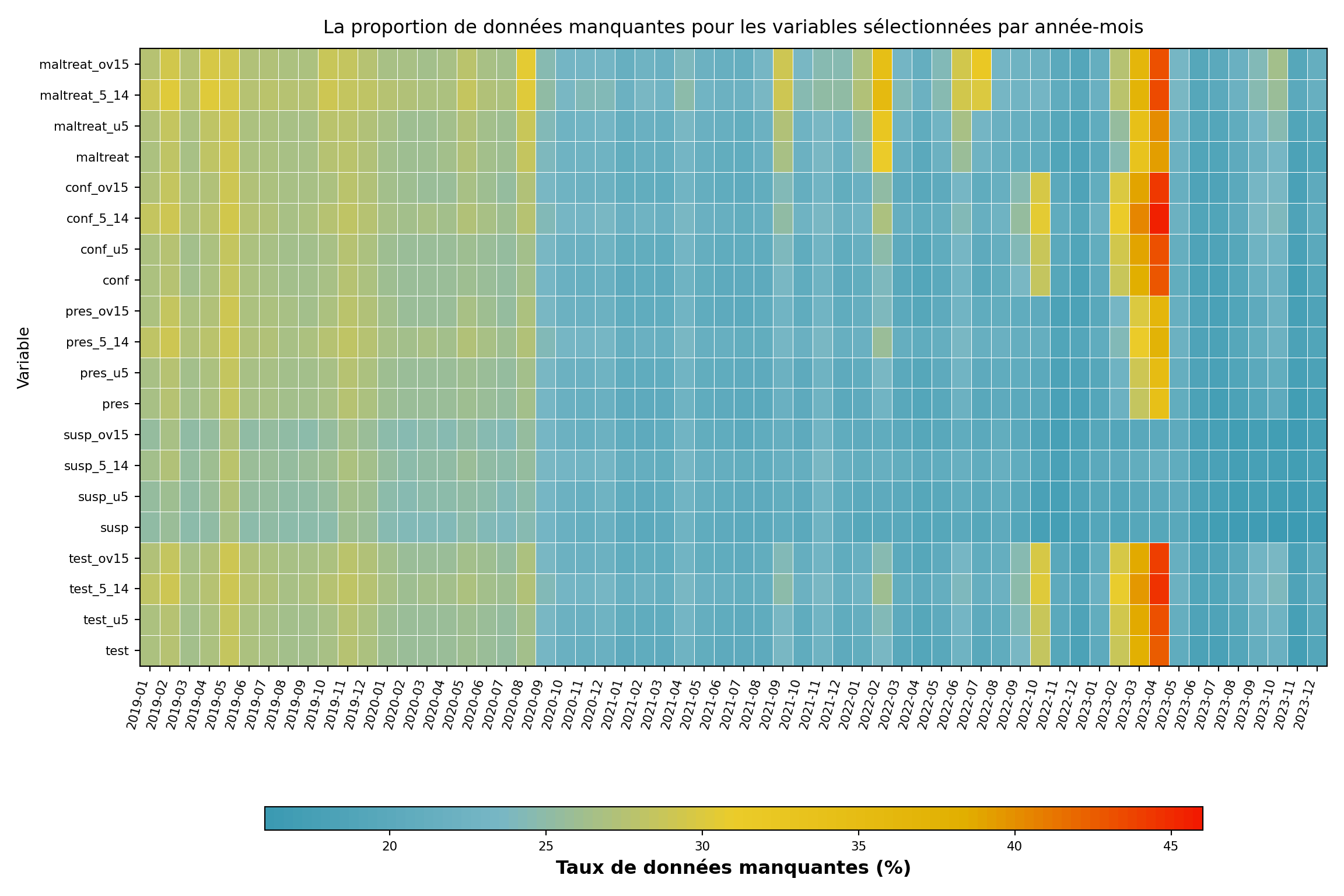
Étape 4 : Vérifier les données manquantes dans le temps
Dans cette étape, nous examinons le taux de données manquantes de nos variables d’intérêt dans le temps. Cette analyse nous aide à comprendre les tendances temporelles de la disponibilité des données et à identifier les périodes ou les variables présentant des problèmes systématiques de données manquantes. La visualisation en carte thermique donne un aperçu de la complétude des données pour tous les indicateurs du paludisme selon différents groupes d’âge sur toute la période d’étude. L’intensité des couleurs représente le pourcentage de valeurs manquantes, ce qui permet d’identifier rapidement les périodes ou les variables problématiques pouvant nécessiter un traitement particulier dans les analyses ultérieures.
Dans un premier temps, nous souhaitons vérifier l’ensemble de variables suivant : tests de paludisme, cas suspects, présumés et confirmés et traitements antipaludiques agrégés pour tous les groupes d’âge, ainsi que les ventilations par groupe d’âge.
Afficher le code
# obtenir les variables d'intérêt (agrégées et par groupe d'âge)
vars <- c(
"test", # tests de paludisme agrégés
"test_u5",
"test_5_14",
"test_ov15",
"susp", # cas suspects agrégés
"susp_u5",
"susp_5_14",
"susp_ov15",
"pres", # cas présumés agrégés
"pres_u5",
"pres_5_14",
"pres_ov15",
"conf", # cas confirmés agrégés
"conf_u5",
"conf_5_14",
"conf_ov15",
"maltreat", # traitements agrégés
"maltreat_u5",
"maltreat_5_14",
"maltreat_ov15"
)
# calculer les taux de données manquantes par date pour chaque variable
missing_rate_date <- df_routine |>
dplyr::group_by(date) |>
dplyr::summarise(
dplyr::across(
dplyr::all_of(vars),
~ mean(is.na(.x)) * 100
),
.groups = "drop"
) |>
dplyr::arrange(date) |>
tidyr::pivot_longer(
cols = -ym,
names_to = "variables",
values_to = "missing_rate"
) |>
# appliquer l'ordre explicite de `vars` sur l'axe y pour aligner
# R et Python
dplyr::mutate(variables = factor(variables, levels = vars))
# option pour contrôler la plage de l'échelle de couleurs de la
# carte thermique
# si TRUE : l'échelle de couleurs va de 0 à 100 % (plage complète
# des taux possibles, même si les données réelles ne couvrent pas
# cette plage)
# si FALSE : l'échelle de couleurs est limitée à la plage réelle
# des données manquantes (par ex., si les taux vont de 20 à 70 %,
# l'échelle de couleurs ne couvre que cette plage)
full_range <- FALSE
# définir les limites de l'échelle de remplissage selon l'option
# full_range
fill_limits <- if (full_range) {
# utiliser la plage complète 0-100 % pour l'échelle de couleurs
c(0, 100)
} else {
# utiliser la plage réelle des taux de données manquantes pour
# l'échelle de couleurs
fill_var_values <- missing_rate_date$missing_rate
c(
floor(min(fill_var_values, na.rm = TRUE)),
ceiling(max(fill_var_values, na.rm = TRUE))
)
}
# tracer la plage de données manquantes par variable
missing_plot_date <- ggplot2::ggplot(
missing_rate_date,
ggplot2::aes(
y = variables,
x = ym,
fill = missing_rate
)
) +
ggplot2::geom_tile(colour = "white", linewidth = .2) +
ggplot2::scale_fill_gradientn(
colours = wesanderson::wes_palette(
"Zissou1",
100,
type = "continuous"
),
limits = fill_limits
) +
ggplot2::guides(
fill = ggplot2::guide_colorbar(
title.position = "top",
nrow = 1,
label.position = "bottom",
direction = "horizontal",
barheight = ggplot2::unit(0.3, "cm"),
barwidth = ggplot2::unit(4, "cm"),
ticks = TRUE,
draw.ulim = TRUE,
draw.llim = TRUE
)
) +
ggplot2::scale_x_discrete(expand = c(0, 0)) +
ggplot2::scale_y_discrete(expand = c(0, 0)) +
ggplot2::theme_bw() +
ggplot2::theme(
legend.title = ggplot2::element_text(
size = 12,
face = "bold",
family = "sans"
),
legend.position = "bottom",
legend.direction = "horizontal",
legend.box = "horizontal",
legend.box.just = "center",
legend.margin = ggplot2::margin(t = 0, unit = "cm"),
legend.text = ggplot2::element_text(
size = 8,
family = "sans"
),
axis.title.x = ggplot2::element_text(
margin = ggplot2::margin(t = 5, unit = "pt")
),
axis.title.y = ggplot2::element_text(
margin = ggplot2::margin(r = 10, unit = "pt")
),
axis.text.x = ggplot2::element_text(
angle = 75,
hjust = 1,
family = "sans"
),
axis.text = ggplot2::element_text(family = "sans"),
axis.title = ggplot2::element_text(family = "sans"),
plot.title = ggtext::element_markdown(
size = 12,
family = "sans",
margin = ggplot2::margin(b = 10)
),
strip.text = ggplot2::element_text(
family = "sans",
face = "bold"
),
panel.grid.minor = ggplot2::element_blank(),
panel.grid.major = ggplot2::element_blank(),
panel.background = ggplot2::element_blank(),
strip.background = ggplot2::element_rect(fill = "grey90")
) +
ggplot2::labs(
fill = "Taux de données manquantes (%)",
y = "Variable",
x = "",
title = "La proportion de données manquantes pour les variables sélectionnées par année-mois"
)
# afficher le graphique
missing_plot_date
NoteSortie
Pour adapter le code :
- Lignes 1-23 : Mettez à jour le vecteur
varspour correspondre aux noms de variables de l’ensemble de données. Pour un autre pays ou un autre jeu de données, modifiez les noms des variables pour refléter les indicateurs pertinents (par ex., pour le Ghana cela pourrait êtrecases_u5,tests_5_14, etc.). - Ligne 26 : Remplacez
df_routinepar le nom de l’ensemble de données si différent. - Ligne 53 : Définissez
full_range <- TRUEpour étendre l’échelle de couleurs de 0 à 100 % pour une comparaison cohérente entre jeux de données ou périodes. Définissezfull_range <- FALSEpour limiter l’échelle de couleurs à la plage réelle des données pour un meilleur contraste visuel des tendances de données manquantes observées.
Afficher le code
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
import numpy as np
import pandas as pd
# variables d'intérêt (agrégées et par groupe d'âge)
vars_of_interest = [
"test", # tests de paludisme agrégés
"test_u5",
"test_5_14",
"test_ov15",
"susp", # cas suspects agrégés
"susp_u5",
"susp_5_14",
"susp_ov15",
"pres", # cas présumés agrégés
"pres_u5",
"pres_5_14",
"pres_ov15",
"conf", # cas confirmés agrégés
"conf_u5",
"conf_5_14",
"conf_ov15",
"maltreat", # traitements agrégés
"maltreat_u5",
"maltreat_5_14",
"maltreat_ov15",
]
# calculer les taux de données manquantes par année-mois pour chaque variable
missing_rate_date = (
df_routine.groupby("ym", as_index=False)[vars_of_interest]
.apply(lambda g: g[vars_of_interest].isna().mean() * 100)
.reset_index()
.rename(columns={"level_0": "ym"})
)
# reconstruire depuis groupby pour conserver ym correctement
_grouped = df_routine.groupby("ym")
missing_rate_date = pd.DataFrame(
{v: _grouped[v].apply(lambda s: s.isna().mean() * 100)
for v in vars_of_interest}
).reset_index()
# pivoter en format long
missing_rate_long = missing_rate_date.melt(
id_vars="ym",
value_vars=vars_of_interest,
var_name="variables",
value_name="missing_rate"
).sort_values("ym")
# option pour contrôler la plage de l'échelle de couleurs de la carte thermique
full_range = False
if full_range:
vmin, vmax = 0.0, 100.0
else:
vals = missing_rate_long["missing_rate"].dropna()
vmin = float(np.floor(vals.min()))
vmax = float(np.ceil(vals.max()))
# palette Zissou1 (reproduit wesanderson::wes_palette("Zissou1", 100))
zissou1_colors = ["#3B9AB2", "#78B7C5", "#EBCC2A", "#E1AF00", "#F21A00"]
zissou1_cmap = mcolors.LinearSegmentedColormap.from_list(
"Zissou1", zissou1_colors, N=100
)
# pivoter vers une matrice pour pcolormesh
ym_order = sorted(missing_rate_long["ym"].unique())
var_order = vars_of_interest # ordre de haut en bas sur l'axe y
pivot = (
missing_rate_long
.pivot(index="variables", columns="ym", values="missing_rate")
.reindex(index=var_order, columns=ym_order)
)
fig, ax = plt.subplots(figsize=(12, 8))
mesh = ax.pcolormesh(
np.arange(len(ym_order) + 1),
np.arange(len(var_order) + 1),
pivot.values,
cmap=zissou1_cmap,
vmin=vmin,
vmax=vmax,
linewidth=0.2,
edgecolors="white"
)
ax.set_aspect("auto")
# étiquettes et graduations de l'axe x
ax.set_xticks(np.arange(len(ym_order)) + 0.5)
ax.set_xticklabels(ym_order, rotation=75, ha="right", fontsize=8)
# étiquettes et graduations de l'axe y
ax.set_yticks(np.arange(len(var_order)) + 0.5)
ax.set_yticklabels(var_order, fontsize=8)
ax.set_xlabel("")
ax.set_ylabel("Variable")
ax.set_title(
"La proportion de données manquantes pour les variables sélectionnées par année-mois",
fontsize=12, pad=10
)
# barre de couleurs horizontale en bas
cbar = fig.colorbar(
mesh, ax=ax, orientation="horizontal",
fraction=0.03, pad=0.18, aspect=40
)
cbar.set_label("Taux de données manquantes (%)", fontsize=12, fontweight="bold")
cbar.ax.tick_params(labelsize=8)
# supprimer les lignes de grille
ax.grid(False)
plt.tight_layout()
NoteSortie
Pour adapter le code :
- Lignes 7-27 : Mettez à jour
vars_of_interestpour correspondre aux noms de variables de l’ensemble de données. Pour un autre pays ou un autre jeu de données, modifiez les noms des variables pour refléter les indicateurs pertinents. - Ligne 31 : Remplacez
df_routinepar le nom de l’ensemble de données si différent. - Ligne 52 : Définissez
full_range = Truepour étendre l’échelle de couleurs de 0 à 100 % pour une comparaison cohérente entre jeux de données ou périodes. Définissezfull_range = Falsepour limiter l’échelle de couleurs à la plage réelle des données pour un meilleur contraste visuel des tendances de données manquantes observées.
Plusieurs indicateurs présentent des données manquantes persistantes dans le temps. Entre mi-2022 et début 2023, les données manquantes ont fortement augmenté pour plusieurs indicateurs, avec test, maltreat et conf atteignant des taux supérieurs à 45 %.
Ce qu’il faut chercher dans les cartes thermiques de ce type sur n’importe quel ensemble de données :
- Les bandes verticales (tous les indicateurs manquants les mêmes mois) indiquent des pannes à l’échelle du système ou des migrations de plateforme et pointent généralement vers MCAR au niveau de la période temporelle.
- Les bandes horizontales (un indicateur constamment manquant sur tous les mois) indiquent une pratique de déclaration spécifique à l’indicateur ou des modifications du formulaire et pointent généralement vers MAR conditionnel à l’indicateur.
- Un bord droit qui s’étend indique un retard de déclaration pour les mois les plus récents ; envisagez d’exclure ces mois.
- Des bandes co-localisées sur des lignes désagrégées par âge (par ex.,
test_u5,test_5_14,test_ov15tous manquants ensemble) signifient généralement que l’agrégat a été déclaré mais que la désagrégation a été omise.
Les tendances ressemblant à MAR conditionnel sur le temps peuvent être traitées par imputation stratifiée par période sur la page Méthodes d’imputation.
Étape 5 : Vérifier les données manquantes dans le temps et par niveau administratif
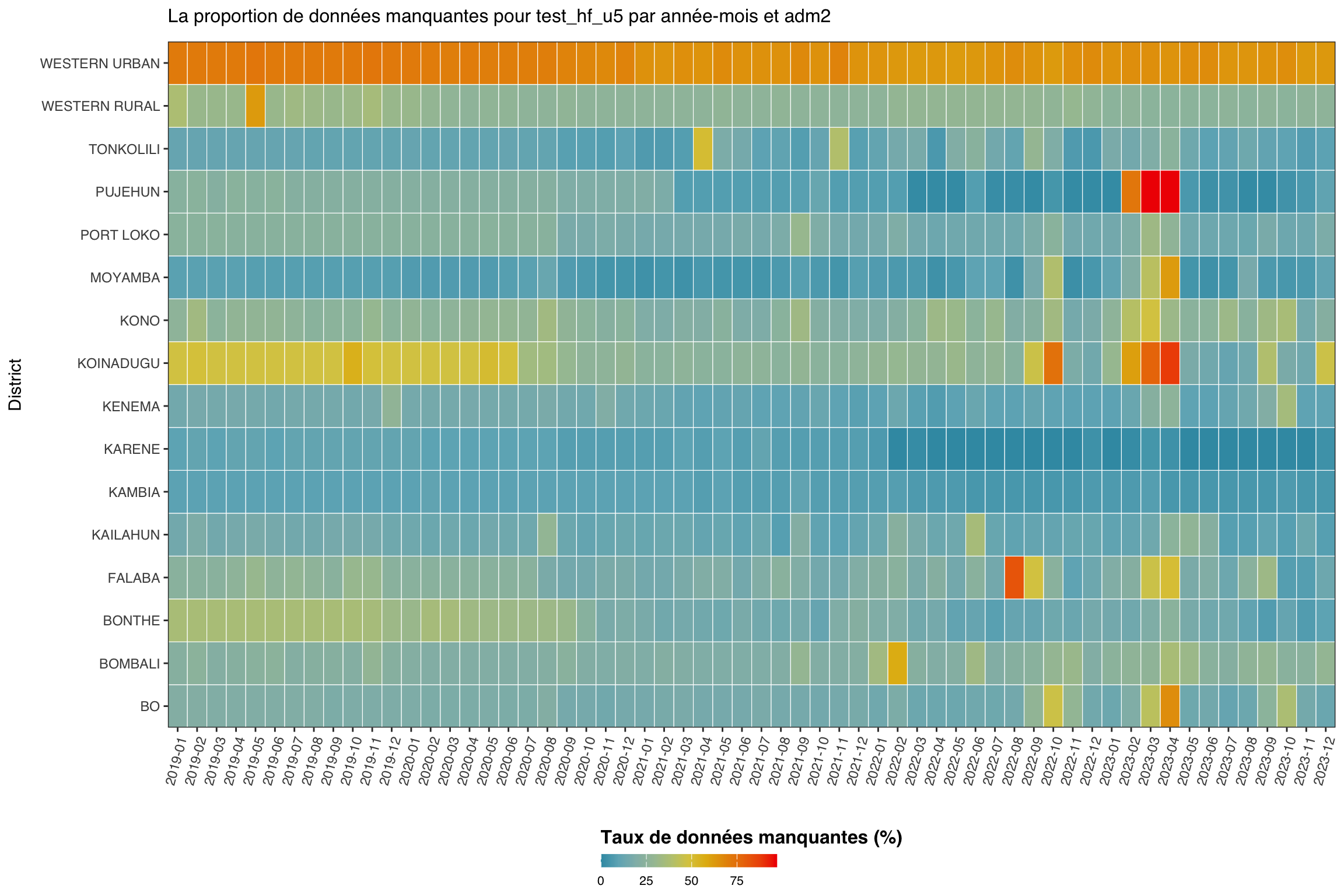
Dans cette étape, nous nous concentrons sur un seul indicateur, les tests de paludisme chez les enfants de moins de 5 ans au niveau de l’établissement de santé (test_hf_u5), pour examiner comment les données manquantes varient dans le temps selon les districts (niveau adm2). Cela nous permet d’identifier les zones infranationales présentant des déclarations systématiquement défaillantes et de repérer les périodes où la disponibilité des données a chuté brutalement.
Bien que les données soient disponibles au niveau de l’établissement de santé, l’unité de déclaration la plus granulaire, il reste important d’évaluer les données manquantes aux niveaux administratifs supérieurs. Cette vue plus large devient particulièrement utile lorsque les données au niveau de l’établissement sont peu denses. Dans de tels cas, nous pouvons recourir à des approches d’analyse de substitution qui s’appuient sur les tendances des établissements voisins au sein du même district.
Afficher le code
# calculer les taux de données manquantes par année-mois et adm2
# pour chaque variable
missing_rate_adm2 <- df_routine |>
dplyr::group_by(ym, adm2) |>
dplyr::summarise(
missing_rate = mean(is.na(test_hf_u5)) * 100,
.groups = "drop"
)
# option pour contrôler la plage de l'échelle de couleurs de la
# carte thermique
# si TRUE : l'échelle de couleurs va de 0 à 100 % (plage complète
# des taux possibles, même si les données réelles ne couvrent pas
# cette plage)
# si FALSE : l'échelle de couleurs est limitée à la plage réelle
# des données manquantes (par ex., si les taux vont de 20 à 70 %,
# l'échelle de couleurs ne couvre que cette plage)
full_range <- FALSE
# définir les limites de l'échelle de remplissage selon l'option
# full_range
fill_limits <- if (full_range) {
# utiliser la plage complète 0-100 % pour l'échelle de couleurs
c(0, 100)
} else {
# utiliser la plage réelle des taux de données manquantes pour
# l'échelle de couleurs
fill_var_values <- missing_rate_adm2$missing_rate
c(
floor(min(fill_var_values, na.rm = TRUE)),
ceiling(max(fill_var_values, na.rm = TRUE))
)
}
# tracer la plage de données manquantes par localisation
missing_plot_adm2 <- ggplot2::ggplot(
missing_rate_adm2,
ggplot2::aes(
y = adm2,
x = ym,
fill = missing_rate
)
) +
ggplot2::geom_tile(colour = "white", linewidth = .2) +
ggplot2::scale_fill_gradientn(
colours = wesanderson::wes_palette(
"Zissou1",
100,
type = "continuous"
),
limits = fill_limits
) +
ggplot2::guides(
fill = ggplot2::guide_colorbar(
title.position = "top",
nrow = 1,
label.position = "bottom",
direction = "horizontal",
barheight = ggplot2::unit(0.3, "cm"),
barwidth = ggplot2::unit(4, "cm"),
ticks = TRUE,
draw.ulim = TRUE,
draw.llim = TRUE
)
) +
ggplot2::scale_x_discrete(expand = c(0, 0)) +
ggplot2::scale_y_discrete(expand = c(0, 0)) +
ggplot2::theme_bw() +
ggplot2::theme(
legend.title = ggplot2::element_text(
size = 12,
face = "bold",
family = "sans"
),
legend.position = "bottom",
legend.direction = "horizontal",
legend.box = "horizontal",
legend.box.just = "center",
legend.margin = ggplot2::margin(t = 0, unit = "cm"),
legend.text = ggplot2::element_text(
size = 8,
family = "sans"
),
axis.title.x = ggplot2::element_text(
margin = ggplot2::margin(t = 5, unit = "pt")
),
axis.title.y = ggplot2::element_text(
margin = ggplot2::margin(r = 10, unit = "pt")
),
axis.text.x = ggplot2::element_text(
angle = 75,
hjust = 1,
family = "sans"
),
axis.text = ggplot2::element_text(family = "sans"),
axis.title = ggplot2::element_text(family = "sans"),
plot.title = ggtext::element_markdown(
size = 12,
family = "sans",
margin = ggplot2::margin(b = 10)
),
strip.text = ggplot2::element_text(
family = "sans",
face = "bold"
),
panel.grid.minor = ggplot2::element_blank(),
panel.grid.major = ggplot2::element_blank(),
panel.background = ggplot2::element_blank(),
strip.background = ggplot2::element_rect(fill = "grey90")
) +
ggplot2::labs(
fill = "Taux de données manquantes (%)",
y = "District",
x = "",
title = "La proportion de données manquantes pour test_hf_u5 par année-mois et adm2"
)
# afficher le graphique
missing_plot_adm2
NoteSortie
Pour adapter le code :
- Ligne 3 : Remplacez
df_routinepar le nom de l’ensemble de données si différent. - Ligne 6 : Mettez à jour le nom de la variable (
test_hf_u5) pour correspondre au nom de la variable d’intérêt dans l’ensemble de données. - Ligne 18 : Définissez
full_range <- TRUEpour étendre l’échelle de couleurs de 0 à 100 % pour une comparaison cohérente entre jeux de données ou périodes. Définissezfull_range <- FALSEpour limiter l’échelle de couleurs à la plage réelle des données pour un meilleur contraste visuel des tendances de données manquantes observées.
Afficher le code
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
import numpy as np
import pandas as pd
# calculer les taux de données manquantes par année-mois et adm2 pour test_hf_u5
missing_rate_adm2 = (
df_routine.groupby(["ym", "adm2"], as_index=False)
.agg(missing_rate=("test_hf_u5", lambda s: s.isna().mean() * 100))
)
# option pour contrôler la plage de l'échelle de couleurs de la carte thermique
full_range = False
if full_range:
vmin, vmax = 0.0, 100.0
else:
vals = missing_rate_adm2["missing_rate"].dropna()
vmin = float(np.floor(vals.min()))
vmax = float(np.ceil(vals.max()))
# palette Zissou1
zissou1_colors = ["#3B9AB2", "#78B7C5", "#EBCC2A", "#E1AF00", "#F21A00"]
zissou1_cmap = mcolors.LinearSegmentedColormap.from_list(
"Zissou1", zissou1_colors, N=100
)
ym_order = sorted(missing_rate_adm2["ym"].unique())
adm2_order = sorted(missing_rate_adm2["adm2"].unique())
pivot = (
missing_rate_adm2
.pivot(index="adm2", columns="ym", values="missing_rate")
.reindex(index=adm2_order, columns=ym_order)
)
fig, ax = plt.subplots(figsize=(12, 8))
mesh = ax.pcolormesh(
np.arange(len(ym_order) + 1),
np.arange(len(adm2_order) + 1),
pivot.values,
cmap=zissou1_cmap,
vmin=vmin,
vmax=vmax,
linewidth=0.2,
edgecolors="white"
)
ax.set_aspect("auto")
ax.set_xticks(np.arange(len(ym_order)) + 0.5)
ax.set_xticklabels(ym_order, rotation=75, ha="right", fontsize=8)
ax.set_yticks(np.arange(len(adm2_order)) + 0.5)
ax.set_yticklabels(adm2_order, fontsize=8)
ax.set_xlabel("")
ax.set_ylabel("District")
ax.set_title(
"La proportion de données manquantes pour test_hf_u5 par année-mois et adm2",
fontsize=12, pad=10
)
cbar = fig.colorbar(
mesh, ax=ax, orientation="horizontal",
fraction=0.03, pad=0.18, aspect=40
)
cbar.set_label("Taux de données manquantes (%)", fontsize=12, fontweight="bold")
cbar.ax.tick_params(labelsize=8)
ax.grid(False)
plt.tight_layout()
NoteSortie
Pour adapter le code :
- Ligne 8 : Remplacez
df_routinepar le nom de l’ensemble de données si différent. - Ligne 10 : Mettez à jour le nom de la variable (
test_hf_u5) pour correspondre au nom de la variable d’intérêt dans l’ensemble de données. - Ligne 13 : Définissez
full_range = Truepour étendre l’échelle de couleurs de 0 à 100 % pour une comparaison cohérente entre jeux de données ou périodes. Définissezfull_range = Falsepour limiter l’échelle de couleurs à la plage réelle des données pour un meilleur contraste visuel des tendances de données manquantes observées.
Les données manquantes pour test_hf_u5 varient selon le district et dans le temps. WESTERN URBAN présente le taux de données manquantes le plus élevé (environ 67 % en moyenne), avec KOINADUGU, WESTERN RURAL et KONO également au-dessus de 25 %. De nombreux districts affichent également une augmentation des données manquantes autour de mi à fin 2022, ce qui suggère un problème de déclaration plus large. En revanche, des districts comme KARENE, KAMBIA et MOYAMBA ont des taux de données manquantes plus faibles et plus stables. Ces tendances confirment que test_hf_u5 varie à la fois dans le temps et selon la localisation.
Cela suggère que les données manquantes pour test_hf_u5 sont probablement de type Missing At Random (MAR), car elles dépendent de facteurs observables tels que le district et la période de déclaration. Dans de tels cas, des approches d’analyse stratifiée sont appropriées. Le niveau district (adm2) peut également servir d’unité de substitution pour l’analyse, notamment lorsque les données au niveau de l’établissement sont peu denses, en s’appuyant sur les tendances des établissements voisins au sein du même district.
ImportantConsultez l’équipe SNT
Les tendances de données manquantes au niveau du district reflètent souvent des décisions opérationnelles que l’équipe SNT connaît déjà : quels districts ont changé d’instance DHIS2 ou migré vers d’autres plateformes, quand les réformes des systèmes d’information sanitaire ont été déployées, où des systèmes de déclaration parallèles coexistent avec DHIS2, et quels districts ont mené des campagnes perturbant la déclaration de routine. Avant de classer le profil d’un district comme MAR ou MNAR, consultez l’équipe SNT pour écarter une cause structurelle connue. L’équipe peut également indiquer une source alternative plus complète pour la période concernée.
Ce qu’il faut chercher lors de l’application sur un pays différent :
- Les bandes horizontales persistantes dans des districts spécifiques reflètent souvent les hôpitaux urbains ou périurbains qui déclarent moins régulièrement que les postes de santé ruraux. Vérifiez la composition en types d’établissements de ces districts.
- Les bandes verticales partagées entre districts indiquent une perturbation de la déclaration au niveau national telle qu’une migration DHIS2, un mois de campagne ou une période de vacances.
- Une région sombre en bas à gauche signifie que les données manquantes sont concentrées en début de série chronologique ; l’indicateur peut avoir été ajouté ultérieurement, auquel cas les mois antérieurs à l’activation doivent être masqués comme non applicables conformément à la page statut actif.
- Un dégradé régulier sans tendance marquée peut indiquer MCAR ; confirmez avec
naniar::mcar_test()pour cet indicateur.
Lorsque des tendances MAR comme celles ci-dessus sont présentes, planifiez l’utilisation d’une approche d’imputation stratifiée ou hiérarchique sur la page Méthodes d’imputation.
Étape 6 : Vérifier les données manquantes par type d’établissement de santé et groupes d’âge
Au-delà des tendances temporelles et géographiques, les données manquantes peuvent également varier de façon systématique selon d’autres facteurs, tels que le type d’établissement de santé et les groupes d’âge. De nombreux systèmes de surveillance de routine collectent des données déjà désagrégées selon ces facteurs (par exemple, test_hf_u5 représentant les tests de paludisme réalisés dans les établissements de santé pour les enfants de moins de 5 ans).
La première étape pour identifier ces tendances consiste à désagréger ces données pré-agrégées en format long, en créant des colonnes distinctes pour les indicateurs, les types d’établissements et les groupes d’âge. Ce format long nous permet d’examiner comment les données manquantes varient selon ces variables de stratification importantes et d’identifier des lacunes de déclaration systématiques pouvant être liées à la capacité des établissements, aux modèles de prestation de services ou aux défis de collecte de données propres à certains groupes démographiques.
Afficher le code
# définir les indicateurs de base à conserver lors de la désagrégation
core_indicators <- c(
"adm0",
"adm1",
"adm2",
"adm3",
"hf",
"hf_uid",
"year",
"month",
"ym",
"date"
)
# sélectionner les indicateurs de base et les variables désagrégées
df_routine_disagg <- df_routine |>
dplyr::select(
dplyr::any_of(core_indicators),
dplyr::matches("_(com|hf)_(u5|5_14|ov15)$")
)
# transformer en format long avec colonnes distinctes pour le type
# d'établissement et le groupe d'âge
df_routine_disagg_long <- df_routine_disagg |>
# exclure maladm_hf_u5 : n'a pas de contreparties au niveau
# communautaire ni pour les autres groupes d'âge, donc ne peut
# pas être pivoté dans le format long ci-dessous
dplyr::select(-maladm_hf_u5) |>
tidyr::pivot_longer(
cols = dplyr::matches("_(com|hf)_(u5|5_14|ov15)$"),
names_to = c("indicator", "facility_type", "age_group"),
names_pattern = "(.+)_(com|hf)_(u5|5_14|ov15)$",
values_to = "value"
) |>
# réétiqueter les facteurs
dplyr::mutate(
age_group = factor(
age_group,
levels = c("u5", "5_14", "ov15"),
labels = c("Moins de 5 ans", "5 à 15 ans", "Plus de 15 ans")
),
facility_type = factor(
facility_type,
levels = c("hf", "com"),
labels = c("Établissement de santé", "Communauté")
)
)
# aperçu de la structure des données désagrégées
df_routine_disagg_long |>
utils::head() |>
knitr::kable()Pour adapter le code :
- Lignes 2-13 : Mettre à jour le vecteur
core_indicatorspour qu’il corresponde aux noms de variables administratives et temporelles du jeu de données. - Ligne 16 : Remplacer
df_routinepar le nom du jeu de données si différent. - Lignes 19, 30 : Modifier le motif regex
"_(com|hf)_(u5|5_14|ov15)$"pour qu’il corresponde aux conventions de nommage des types d’établissements et des groupes d’âge (par exemple, si les données utilisent des codes d’établissements ou des catégories d’âge différents).
Afficher le code
import re
import pandas as pd
# définir les colonnes de base à conserver lors de la désagrégation
core_indicators = [
"adm0", "adm1", "adm2", "adm3",
"hf", "hf_uid",
"year", "month", "ym", "date"
]
# sélectionner les indicateurs de base et les colonnes désagrégées
disagg_pattern = re.compile(r".+_(com|hf)_(u5|5_14|ov15)$")
disagg_cols = [c for c in df_routine.columns if disagg_pattern.match(c)]
keep_core = [c for c in core_indicators if c in df_routine.columns]
df_routine_disagg = df_routine[keep_core + disagg_cols].copy()
# exclure maladm_hf_u5 : n'a pas de contreparties au niveau communautaire ni pour les autres groupes d'âge
if "maladm_hf_u5" in df_routine_disagg.columns:
df_routine_disagg = df_routine_disagg.drop(columns=["maladm_hf_u5"])
# ré-identifier les colonnes désagrégées après l'exclusion
disagg_cols_final = [
c for c in df_routine_disagg.columns
if c not in keep_core
]
# transformer en format long avec colonnes distinctes facility_type et age_group
def _parse_col(col):
"""Extract (indicator, facility_type, age_group) from column name."""
m = re.match(r"^(.+)_(com|hf)_(u5|5_14|ov15)$", col)
if m:
return m.group(1), m.group(2), m.group(3)
return None, None, None
long_rows = []
for col in disagg_cols_final:
ind, ftype, age = _parse_col(col)
if ind is None:
continue
tmp = df_routine_disagg[keep_core + [col]].copy()
tmp = tmp.rename(columns={col: "value"})
tmp["indicator"] = ind
tmp["facility_type"] = ftype
tmp["age_group"] = age
long_rows.append(tmp)
df_routine_disagg_long = pd.concat(long_rows, ignore_index=True)
# réétiqueter les facteurs pour correspondre à la sortie R
age_order = ["u5", "5_14", "ov15"]
age_labels = ["Moins de 5 ans", "5 à 15 ans", "Plus de 15 ans"]
ftype_order = ["hf", "com"]
ftype_labels = ["Établissement de santé", "Communauté"]
df_routine_disagg_long["age_group"] = pd.Categorical(
df_routine_disagg_long["age_group"].map(
dict(zip(age_order, age_labels))
),
categories=age_labels,
ordered=True
)
df_routine_disagg_long["facility_type"] = pd.Categorical(
df_routine_disagg_long["facility_type"].map(
dict(zip(ftype_order, ftype_labels))
),
categories=ftype_labels,
ordered=True
)
# aperçu de la structure des données désagrégées
df_routine_disagg_long.head().style.hide(axis="index")Pour adapter le code :
- Lignes 6-13 : Mettre à jour
core_indicatorspour qu’il corresponde aux noms de variables administratives et temporelles du jeu de données. - Ligne 15 : Remplacer
df_routinepar le nom du jeu de données si différent. - Lignes 15, 27 : Modifier le motif regex
r".+_(com|hf)_(u5|5_14|ov15)$"pour qu’il corresponde aux conventions de nommage des types d’établissements et des groupes d’âge dans le jeu de données.
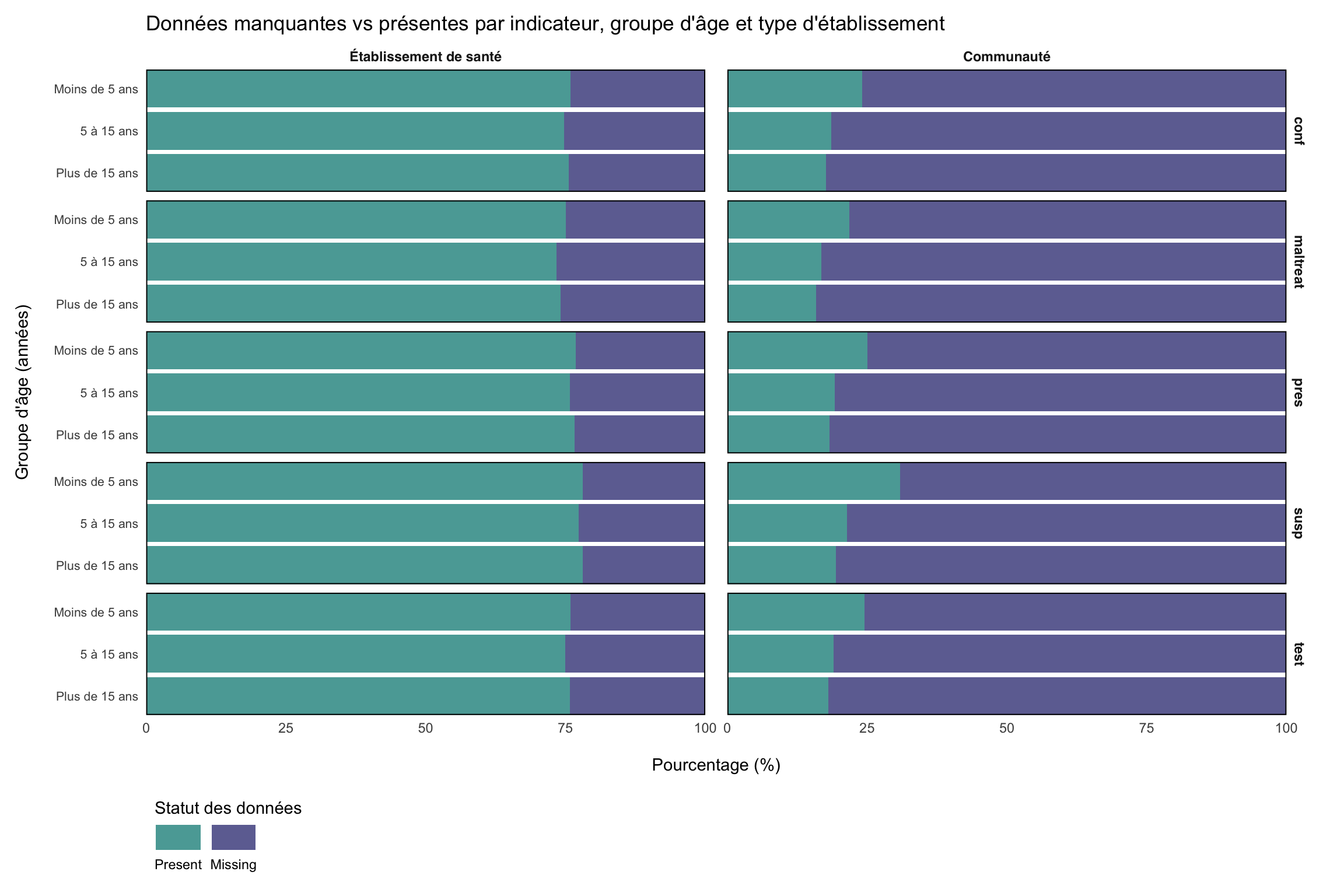
Maintenant que nous avons désagrégé les données, nous pouvons examiner comment les données manquantes varient selon tous les indicateurs par type d’établissement et groupe d’âge. Cette vérification permet d’identifier des tendances systématiques dans la disponibilité des données pouvant être liées aux modèles de prestation de services, à la capacité des établissements ou aux défis de déclaration propres à certains groupes démographiques.
Afficher le code
# préparer les données pour le diagramme à barres empilées avec
# groupe d'âge et type d'établissement
missing_present_data_facility <- df_routine_disagg_long |>
dplyr::group_by(indicator, age_group, facility_type) |>
dplyr::summarise(
total_records = dplyr::n(),
missing_count = sum(is.na(value)),
present_count = sum(!is.na(value)),
missing_pct = round(missing_count / total_records * 100, 2),
present_pct = round(present_count / total_records * 100, 2),
.groups = "drop"
) |>
tidyr::pivot_longer(
cols = c(missing_pct, present_pct),
names_to = "status",
values_to = "percentage",
names_pattern = "(.+)_pct"
) |>
dplyr::mutate(
status = factor(
status,
levels = c("missing", "present"),
labels = c("Missing", "Present")
)
)
# créer le diagramme à barres empilées avec facettes par groupe
# d'âge et type d'établissement
age_facility_miss_plot <- missing_present_data_facility |>
ggplot2::ggplot(ggplot2::aes(
x = percentage,
y = factor(age_group, levels = rev(levels(factor(age_group)))),
fill = status
)) +
ggplot2::geom_col(alpha = 0.8) +
ggplot2::facet_grid(indicator ~ facility_type) +
ggplot2::scale_fill_viridis_d(
option = "D",
begin = 0.2,
end = 0.5,
breaks = c("Present", "Missing")
) +
ggplot2::guides(
fill = ggplot2::guide_legend(
title.position = "top",
title.hjust = 0,
label.position = "bottom"
)
) +
ggplot2::labs(
title = "Données manquantes vs présentes par indicateur, groupe d'âge et type d'établissement",
x = "\nPourcentage (%)",
y = "Groupe d'âge (années)\n",
fill = "Statut des données"
) +
ggplot2::scale_x_continuous(expand = c(0, 0)) +
ggplot2::scale_y_discrete(expand = c(0, 0)) +
ggplot2::theme_minimal() +
ggplot2::theme(
legend.position = "bottom",
legend.direction = "horizontal",
legend.justification = "left",
legend.box.just = "left",
axis.text.y = ggplot2::element_text(size = 8),
strip.text = ggplot2::element_text(
family = "sans",
face = "bold"
),
panel.grid.minor = ggplot2::element_blank(),
panel.grid.major = ggplot2::element_blank(),
panel.background = ggplot2::element_blank(),
panel.border = ggplot2::element_rect(
colour = "black",
fill = NA,
size = .7
),
panel.spacing.x = ggplot2::unit(0.5, "cm"),
plot.margin = ggplot2::margin(10, 20, 10, 10)
)
# afficher le graphique
age_facility_miss_plot
NoteSortie
Pour adapter le code :
- Ligne 3 : Remplacer
df_routine_disagg_longpar le nom du jeu de données désagrégé si différent. - Lignes 19-23 : Mettre à jour les niveaux et libellés du facteur de statut pour utiliser des noms d’affichage différents pour les catégories de données manquantes/présentes.
- Lignes 50-54 : Modifier le titre du graphique et les libellés des axes pour correspondre au thème de l’analyse.
Afficher le code
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
import numpy as np
import pandas as pd
# préparer les données pour le diagramme à barres empilées avec
# groupe d'âge et type d'établissement
missing_present_data_facility = (
df_routine_disagg_long
.groupby(["indicator", "age_group", "facility_type"], observed=True,
as_index=False)
.agg(
total_records=("value", "count"),
missing_count=("value", lambda s: s.isna().sum()),
present_count=("value", lambda s: s.notna().sum()),
)
.assign(
missing_pct=lambda d: (d["missing_count"] / d["total_records"] * 100)
.round(2),
present_pct=lambda d: (d["present_count"] / d["total_records"] * 100)
.round(2),
)
)
# pivoter en format long pour la colonne status
mp_long = missing_present_data_facility.melt(
id_vars=["indicator", "age_group", "facility_type"],
value_vars=["missing_pct", "present_pct"],
var_name="status",
value_name="percentage"
).assign(
status=lambda d: pd.Categorical(
d["status"].map({"missing_pct": "Missing", "present_pct": "Present"}),
categories=["Missing", "Present"],
ordered=True
)
)
# palette viridis D : begin=0.2, end=0.5 pour deux catégories
import matplotlib.cm as cm
viridis = cm.get_cmap("viridis")
color_missing = viridis(0.2)
color_present = viridis(0.5)
status_colors = {"Missing": color_missing, "Present": color_present}
indicators = list(mp_long["indicator"].unique())
facility_types = list(mp_long["facility_type"].cat.categories)
age_labels_ordered = list(mp_long["age_group"].cat.categories)
age_rev = list(reversed(age_labels_ordered))
n_ind = len(indicators)
n_ftype = len(facility_types)
fig, axes = plt.subplots(
n_ind, n_ftype,
figsize=(12, 8),
sharex=True,
sharey="row"
)
for i, ind in enumerate(indicators):
for j, ftype in enumerate(facility_types):
ax = axes[i][j] if n_ind > 1 else axes[j]
subset = mp_long.loc[
(mp_long["indicator"] == ind) &
(mp_long["facility_type"] == ftype)
]
for status in ["Present", "Missing"]:
s_sub = subset.loc[subset["status"] == status]
s_sub = s_sub.set_index("age_group").reindex(age_rev)
ax.barh(
s_sub.index,
s_sub["percentage"],
color=status_colors[status],
alpha=0.8,
label=status
)
ax.set_xlim(0, 100)
ax.set_xlabel("")
ax.set_ylabel("")
# bordure du panneau
for spine in ax.spines.values():
spine.set_linewidth(0.7)
# libellés des bandes
if i == 0:
ax.set_title(str(ftype), fontsize=9, fontweight="bold")
if j == n_ftype - 1:
ax.yaxis.set_label_position("right")
ax.set_ylabel(str(ind), rotation=270, labelpad=12,
fontsize=9, fontweight="bold")
# pas de grille
ax.grid(False)
# libellés des axes partagés
fig.supxlabel("Pourcentage (%)", y=0.02, fontsize=10)
fig.supylabel("Groupe d'âge (années)", x=0.02, fontsize=10)
fig.suptitle(
"Données manquantes vs présentes par indicateur, groupe d'âge et type d'établissement",
fontsize=12, y=1.01
)
# légende partagée
handles = [
plt.Rectangle((0, 0), 1, 1, color=status_colors["Present"], alpha=0.8),
plt.Rectangle((0, 0), 1, 1, color=status_colors["Missing"], alpha=0.8),
]
fig.legend(
handles, ["Present", "Missing"],
title="Data Status",
loc="lower left",
bbox_to_anchor=(0.0, -0.04),
ncol=2,
frameon=False,
fontsize=9
)
plt.tight_layout()
NoteSortie
Pour adapter le code :
- Ligne 8 : Remplacer
df_routine_disagg_longpar le nom du jeu de données désagrégé si différent. - Lignes 30-34 : Mettre à jour le mapping de statut si des noms d’affichage différents sont nécessaires pour les catégories de données manquantes/présentes.
- Lignes 73-76 : Modifier le titre du graphique et les libellés des axes pour correspondre au thème de l’analyse.
La visualisation ci-dessus montre des différences substantielles dans les tendances des données manquantes entre les types d’établissements, les établissements communautaires présentant des taux de données manquantes nettement plus élevés, d’environ 70 % en moyenne. Cette tendance est cohérente entre les indicateurs et les groupes d’âge. À noter que, parmi les établissements communautaires, les données sur les moins de cinq ans sont déclarées plus fréquemment que celles des groupes d’âge plus avancés, une tendance observée pour les indicateurs clés. Ces résultats indiquent des différences systématiques dans la capacité de collecte et de déclaration des données entre les types d’établissements.
Ce qu’il faut chercher lors de l’application à un autre jeu de données :
- Un grand écart entre les types d’établissements (communauté vs établissement) reflète des différences dans la capacité de collecte des données, la fréquence de supervision ou les indicateurs imposés à chaque niveau. Stratifier l’imputation par type d’établissement.
- Un écart plus important dans les groupes d’âge plus avancés reflète souvent que le programme se concentre sur les moins de cinq ans ; les données sur les groupes d’âge plus avancés peuvent constituer un non-applicable structurel plutôt que des données manquantes.
- Un écart spécifique à un indicateur (une rangée de facettes nettement moins bonne que les autres) signifie souvent que le formulaire n’inclut pas cet indicateur à ce niveau. Vérifier avec l’équipe nationale avant d’imputer.
Marquer les indicateurs qui ne sont structurellement pas collectés pour un type d’établissement ou une tranche d’âge donnés comme non applicables plutôt que de les imputer. Les stratégies d’imputation pour les tendances MAR réelles liées au type d’établissement sont traitées sur la page Méthodes d’imputation.
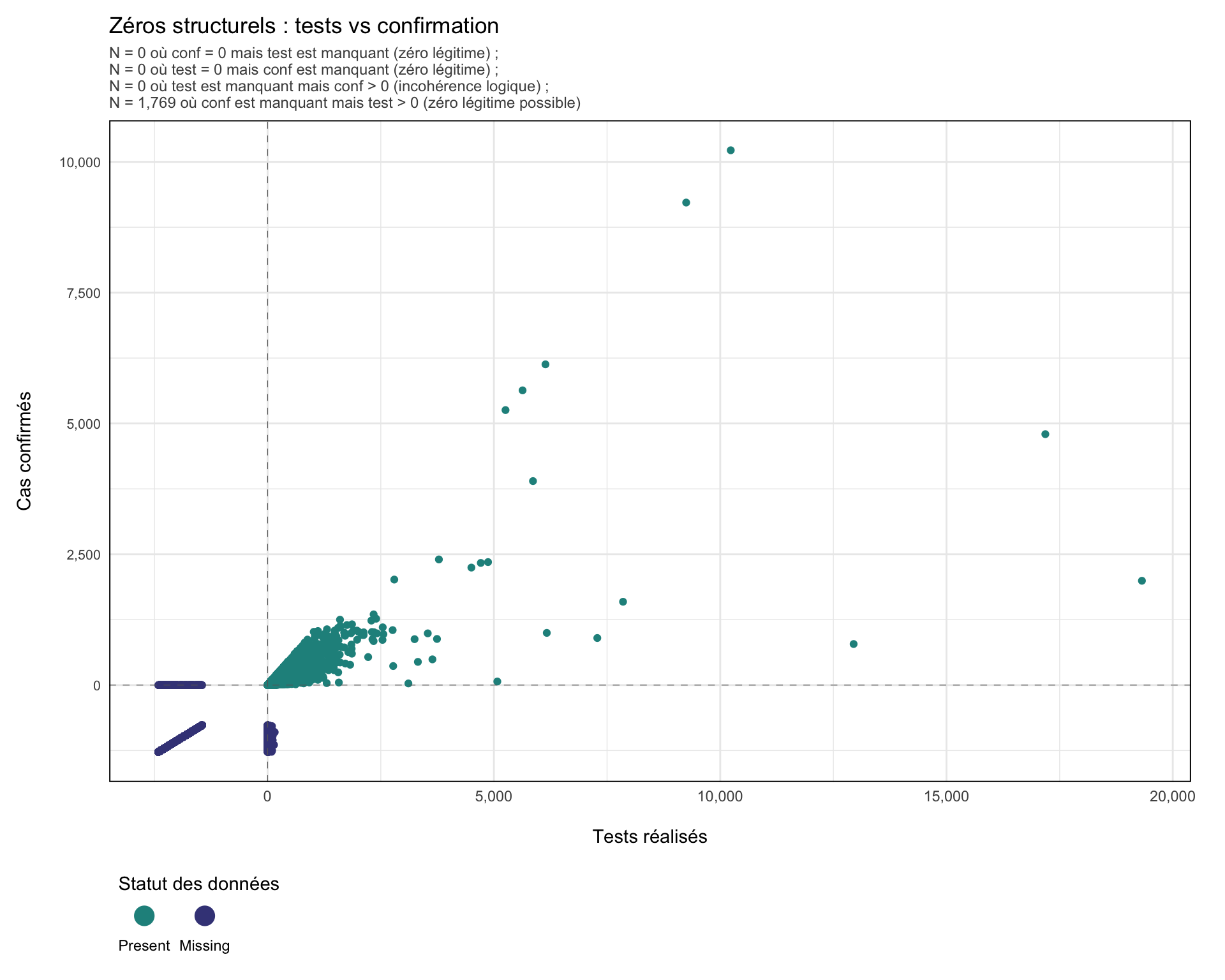
Étape 7 : Visualiser les zéros structurels et les relations logiques
Avant de classifier les valeurs manquantes, nous visualisons les relations entre les indicateurs liés. Ce graphique met en évidence les zéros structurels probables (par exemple, aucun test avec une confirmation manquante), les zéros structurels possibles (par exemple, des cas confirmés égaux à zéro avec des valeurs de tests manquantes) et les incohérences logiques (par exemple, des cas confirmés enregistrés mais des données de tests manquantes). Ces tendances reflètent le parcours de soins cliniques et aident à identifier où les valeurs peuvent être logiquement inférées, imputées structurellement à zéro ou nécessitent des méthodes statistiques.
Plus précisément :
test= 0,confmanquant : Zéro légitime probable (aucun test = confirmation impossible).conf= 0,testmanquant : Zéro légitime possible (aucun cas confirmé suggère l’absence de cas positifs, mais des tests ont pu avoir lieu).conf> 0,testmanquant : Incohérence logique (les cas confirmés impliquent que des tests ont eu lieu ; la valeur doit être imputée).test> 0,confmanquant : Zéro légitime possible (des tests ont eu lieu mais sans cas positifs ; la confirmation peut être légitimement nulle ou manquante).
Note : Ci-dessous, nous utilisons le paquet naniar pour explorer les données manquantes. Contrairement à geom_point(), qui supprime silencieusement les valeurs manquantes, geom_miss_point() indique l’emplacement des valeurs manquantes pour une ou les deux variables en les décalant vers les marges du graphique. Cela facilite la détection des zéros structurels, des lacunes de déclaration et des incohérences logiques.
Afficher le code
# transformer les données en format large pour examiner les
# relations entre indicateurs
df_wide <- df_routine_disagg_long |>
dplyr::select(
dplyr::any_of(core_indicators),
facility_type,
age_group,
indicator,
value
) |>
tidyr::pivot_wider(
names_from = indicator,
values_from = value
)
# calculer les effectifs détaillés de données manquantes pour le sous-titre
n_test_missing_conf_zero <- df_wide |>
dplyr::filter(conf == 0, is.na(test)) |>
nrow()
n_conf_missing_test_zero <- df_wide |>
dplyr::filter(test == 0, is.na(conf)) |>
nrow()
n_test_na_conf_positive <- df_wide |>
dplyr::filter(is.na(test), conf > 0) |>
nrow()
n_conf_na_test_positive <- df_wide |>
dplyr::filter(is.na(conf), test > 0) |>
nrow()
# créer le sous-titre détaillé avec tous les scénarios de données manquantes
subtitle_text <- paste0(
"N = ",
scales::comma(n_test_missing_conf_zero),
" où conf = 0 mais test est manquant (zéro légitime) ; \n",
"N = ",
scales::comma(n_conf_missing_test_zero),
" où test = 0 mais conf est manquant (zéro légitime) ; \n",
"N = ",
scales::comma(n_test_na_conf_positive),
" où test est manquant mais conf > 0 (incohérence logique) ; \n",
"N = ",
scales::comma(n_conf_na_test_positive),
" où conf est manquant mais test > 0 (zéro légitime possible)"
)
# créer le nuage de points montrant la relation entre tests et cas confirmés
structural_zeros_plot <- ggplot2::ggplot(
data = df_wide,
mapping = ggplot2::aes(x = test, y = conf)
) +
naniar::geom_miss_point() +
ggplot2::geom_vline(
xintercept = 0,
linetype = "dashed",
color = "grey40",
linewidth = 0.2
) +
ggplot2::geom_hline(
yintercept = 0,
linetype = "dashed",
color = "grey40",
linewidth = 0.2
) +
ggplot2::scale_x_continuous(
labels = scales::comma_format()
) +
ggplot2::scale_y_continuous(
labels = scales::comma_format()
) +
ggplot2::scale_color_viridis_d(
option = "D",
begin = 0.2,
end = 0.5,
breaks = c("Not Missing", "Missing"),
labels = c("Present", "Missing")
) +
ggplot2::guides(
color = ggplot2::guide_legend(
title.position = "top",
title.hjust = 0,
override.aes = list(
size = 5
),
label.position = "bottom"
)
) +
ggplot2::labs(
title = "Zéros structurels : tests vs confirmation",
subtitle = subtitle_text,
x = "\nTests réalisés",
y = "Cas confirmés\n",
color = "Statut des données"
) +
ggplot2::theme_minimal() +
ggplot2::theme(
legend.position = "bottom",
legend.direction = "horizontal",
legend.justification = "left",
legend.box.just = "left",
axis.text.y = ggplot2::element_text(size = 8),
strip.text = ggplot2::element_text(
family = "sans",
face = "bold"
),
panel.border = ggplot2::element_rect(
colour = "black",
fill = NA,
size = .7
),
panel.spacing.x = ggplot2::unit(0.5, "cm"),
plot.margin = ggplot2::margin(10, 20, 10, 10),
plot.subtitle = ggplot2::element_text(size = 9, color = "grey30")
)
# afficher le graphique
structural_zeros_plot
NoteSortie
Pour adapter le code :
- Lignes 18, 22, 26, 30 : Mettre à jour les noms de variables (
test,conf) dans les conditions de filtre pour qu’ils correspondent aux noms de variables d’intérêt du jeu de données. - Lignes 3-9 : Mettre à jour
core_indicatorset la sélection de colonnes pour qu’ils correspondent à la structure du jeu de données. - Lignes 10-13 : Modifier la transformation
pivot_wider()pour inclure les indicateurs spécifiques à examiner pour les relations structurelles. - Ligne 52 : Modifier les mappings esthétiques x et y pour examiner différentes paires de variables (par exemple,
x = maltreat, y = confpour examiner les relations traitement/confirmation).
Note : Ci-dessous, nous répliquons l’approche naniar::geom_miss_point() en Python. Les valeurs manquantes sur un axe sont décalées vers la marge du graphique (10 % en dessous de la valeur observée minimale) afin que les tendances de zéros structurels restent visibles.
Afficher le code
import matplotlib.cm as cm
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
import numpy as np
import pandas as pd
# transformer en format large pour examiner les relations entre indicateurs
keep_core = [
"adm0", "adm1", "adm2", "adm3",
"hf", "hf_uid", "year", "month", "ym", "date"
]
keep_cols = [c for c in keep_core if c in df_routine_disagg_long.columns]
df_wide = (
df_routine_disagg_long[keep_cols + ["facility_type", "age_group",
"indicator", "value"]]
.pivot_table(
index=keep_cols + ["facility_type", "age_group"],
columns="indicator",
values="value",
aggfunc="first",
observed=True
)
.reset_index()
)
df_wide.columns.name = None
# calculer les effectifs de données manquantes pour le sous-titre
n_test_missing_conf_zero = df_wide.loc[
(df_wide["conf"] == 0) & df_wide["test"].isna()
].shape[0]
n_conf_missing_test_zero = df_wide.loc[
(df_wide["test"] == 0) & df_wide["conf"].isna()
].shape[0]
n_test_na_conf_positive = df_wide.loc[
df_wide["test"].isna() & (df_wide["conf"] > 0)
].shape[0]
n_conf_na_test_positive = df_wide.loc[
df_wide["conf"].isna() & (df_wide["test"] > 0)
].shape[0]
subtitle_text = (
f"N = {n_test_missing_conf_zero:,} où conf = 0 mais test est manquant "
f"(zéro légitime) ; \n"
f"N = {n_conf_missing_test_zero:,} où test = 0 mais conf est manquant "
f"(zéro légitime) ; \n"
f"N = {n_test_na_conf_positive:,} où test est manquant mais conf > 0 "
f"(incohérence logique) ; \n"
f"N = {n_conf_na_test_positive:,} où conf est manquant mais test > 0 "
f"(zéro légitime possible)"
)
# créer les données de démonstration correspondant au chunk R de rendu :
# lignes 400-600 où conf est NA obtiennent test = 0 (tendance zéro légitime)
# lignes 490-900 où test est NA obtiennent conf = 0 (tendance zéro légitime)
df_wide_demo = df_wide.copy().reset_index(drop=True)
mask1 = (df_wide_demo.index.isin(range(400, 601))) & df_wide_demo["conf"].isna()
df_wide_demo.loc[mask1, "test"] = 0.0
mask2 = (df_wide_demo.index.isin(range(490, 901))) & df_wide_demo["test"].isna()
df_wide_demo.loc[mask2, "conf"] = 0.0
# calculer les décalages de marge pour le comportement miss_point
test_obs = df_wide_demo["test"].dropna()
conf_obs = df_wide_demo["conf"].dropna()
test_range = test_obs.max() - test_obs.min() if len(test_obs) > 1 else 1.0
conf_range = conf_obs.max() - conf_obs.min() if len(conf_obs) > 1 else 1.0
test_margin = test_obs.min() - 0.1 * test_range
conf_margin = conf_obs.min() - 0.1 * conf_range
viridis = cm.get_cmap("viridis")
color_present = viridis(0.5) # "Not Missing"
color_missing = viridis(0.2) # "Missing"
fig, ax = plt.subplots(figsize=(10, 8))
# --- points présents-présents ---
mask_pp = df_wide_demo["test"].notna() & df_wide_demo["conf"].notna()
ax.scatter(
df_wide_demo.loc[mask_pp, "test"],
df_wide_demo.loc[mask_pp, "conf"],
color=color_present, alpha=0.4, s=10, label="Present", rasterized=True
)
# --- test manquant, conf présent : décaler test vers la marge gauche ---
mask_tm = df_wide_demo["test"].isna() & df_wide_demo["conf"].notna()
ax.scatter(
[test_margin] * mask_tm.sum(),
df_wide_demo.loc[mask_tm, "conf"],
color=color_missing, alpha=0.4, s=10, label="Missing", rasterized=True
)
# --- conf manquant, test présent : décaler conf vers la marge inférieure ---
mask_cm = df_wide_demo["conf"].isna() & df_wide_demo["test"].notna()
ax.scatter(
df_wide_demo.loc[mask_cm, "test"],
[conf_margin] * mask_cm.sum(),
color=color_missing, alpha=0.4, s=10, rasterized=True
)
# lignes de référence à zéro
ax.axvline(0, linestyle="dashed", color="grey", linewidth=0.2)
ax.axhline(0, linestyle="dashed", color="grey", linewidth=0.2)
# libellés des graduations au format avec virgule
ax.xaxis.set_major_formatter(mticker.FuncFormatter(
lambda x, _: f"{x:,.0f}"
))
ax.yaxis.set_major_formatter(mticker.FuncFormatter(
lambda y, _: f"{y:,.0f}"
))
ax.set_xlabel("\nTests réalisés")
ax.set_ylabel("Cas confirmés\n")
ax.set_title("Zéros structurels : tests vs confirmation", fontsize=12)
ax.text(
0.0, -0.12, subtitle_text,
transform=ax.transAxes, fontsize=9, color="grey",
verticalalignment="top"
)
handles = [
plt.Line2D([0], [0], marker="o", color="w",
markerfacecolor=color_present, markersize=8),
plt.Line2D([0], [0], marker="o", color="w",
markerfacecolor=color_missing, markersize=8),
]
ax.legend(
handles, ["Present", "Missing"],
title="Data Status",
loc="lower left",
frameon=True,
fontsize=9
)
for spine in ax.spines.values():
spine.set_linewidth(0.7)
plt.tight_layout()
NoteSortie
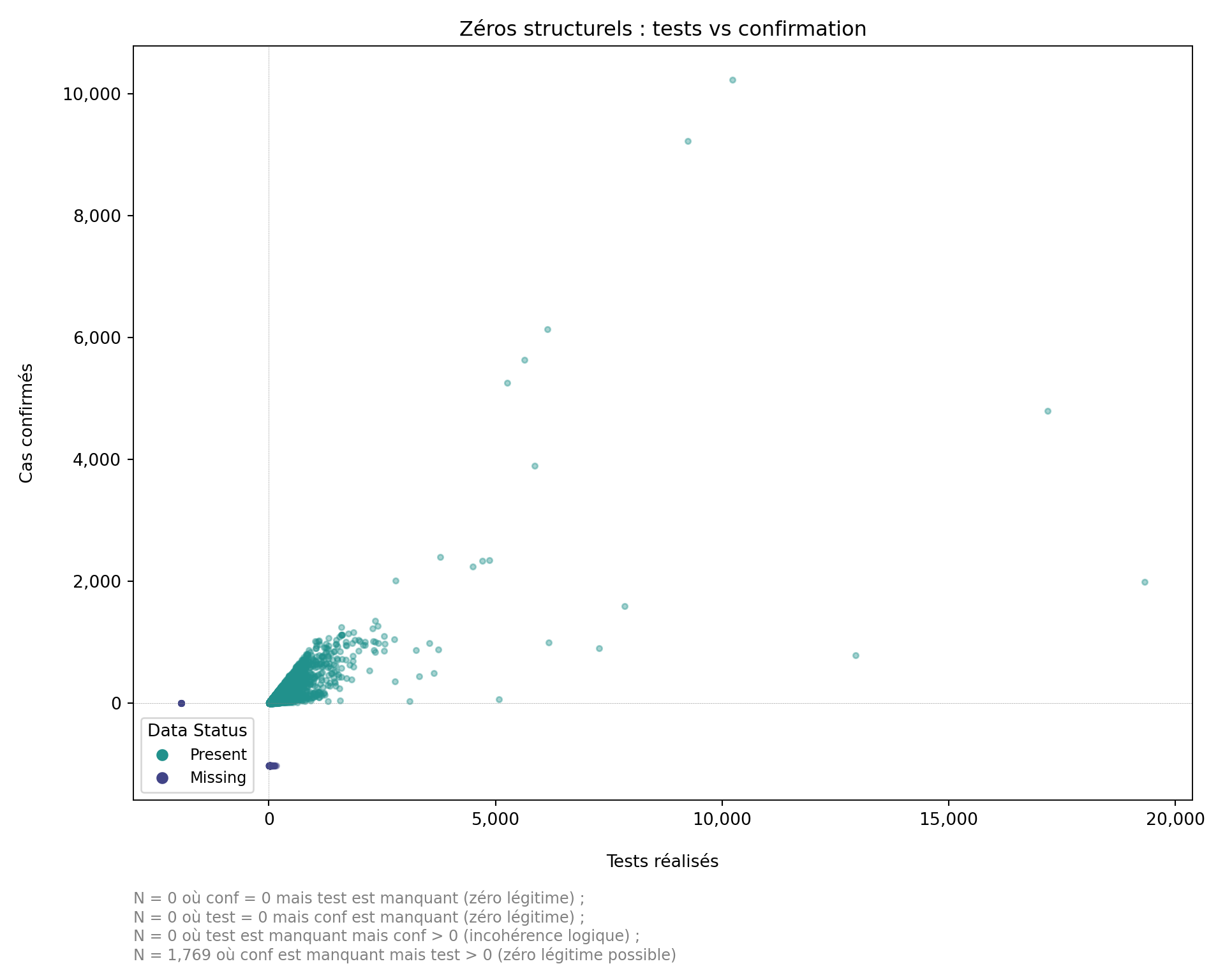
Pour adapter le code :
- Lignes 32, 36, 40, 44 : Mettre à jour les noms de variables (
test,conf) dans les conditions de filtre pour qu’ils correspondent aux noms de variables d’intérêt du jeu de données. - Lignes 9-12 : Mettre à jour
keep_coreet la sélection de colonnes pour qu’ils correspondent à la structure du jeu de données. - Lignes 13-16 : Modifier la transformation
pivot_table()pour inclure les indicateurs spécifiques à examiner pour les relations structurelles. - Lignes 66, 67 : Modifier les références de colonnes x et y du nuage de points pour examiner différentes paires de variables (par exemple,
maltreatetconf).
Le graphique met en évidence des tendances clés dans les données manquantes entre les tests de paludisme (test) et les effectifs de cas confirmés (conf). La ligne verticale en pointillés marque zéro test ; la ligne horizontale en pointillés marque zéro confirmation. Cette visualisation montre 1 769 cas où conf est manquant mais test > 0. Il s’agit vraisemblablement de zéros structurels, où des tests ont été effectués mais aucun cas confirmé n’a été enregistré. Dans ces cas, les effectifs de confirmations manquants peuvent raisonnablement être mis à zéro.
Ce qu’il faut chercher dans ce graphique pour tout jeu de données :
- Un groupe de marqueurs « Manquant » le long de la marge de l’axe y avec
test> 0 : des tests ont été enregistrés mais les confirmations ont été laissées vides. Zéro structurel probable ; mettreconfà 0. - Un groupe de marqueurs « Manquant » le long de la marge de l’axe x avec
conf> 0 : des confirmations ont été enregistrées mais les tests ont été laissés vides. Incohérence logique ; signaler pour révision ou imputertestà partir deconfet d’un taux de positivité historique. - Marqueurs « Manquant » à l’origine : les deux indicateurs sont manquants, ce qui indique une défaillance de déclaration plutôt qu’un zéro structurel.
- Asymétrie le long d’un seul axe : pratique de saisie de données propre à un indicateur. Vérifier si le formulaire distingue 0 d’une case vide.
Résumé
Cette section a présenté des approches pour visualiser et diagnostiquer les données manquantes dans les systèmes de surveillance de routine. En examinant les tendances temporelles, géographiques, par type d’établissement et par relations entre indicateurs, nous avons montré comment les données manquantes peuvent être évaluées de façon systématique plutôt que traitées comme des lacunes aléatoires. La section a démontré comment des graphiques simples et des vérifications logiques permettent de distinguer les vraies valeurs manquantes des problèmes structurels de déclaration, offrant une compréhension plus claire de la fiabilité des données. Ces méthodes établissent une base pour classer la nature des données manquantes et choisir des stratégies appropriées pour y remédier. Les techniques d’imputation structurelle et statistique sont mises en œuvre en détail sur la page Méthodes d’imputation.
Lectures complémentaires
- Rubin, D. B. (1976). Inference and missing data. Biometrika, 63(3), 581–592. Article fondateur introduisant le cadre MCAR / MAR / MNAR.
- van Buuren, S. (2018). Flexible Imputation of Missing Data (2nd ed.). Chapman & Hall/CRC. Référence de base pour l’imputation multiple ; disponible gratuitement sur https://stefvanbuuren.name/fimd/.
- WHO. (2017). Data Quality Review (DQR) toolkit. Cadre recommandé pour évaluer l’exhaustivité, la ponctualité, la cohérence interne et la cohérence externe des données des systèmes d’information sanitaire de routine.
- Maïga, A. et al. (2019). Generating statistics from health facility data: the state of routine health information systems in Eastern and Southern Africa. BMJ Global Health, 4(5), e001849.
- Documentation du paquet
naniar: https://naniar.njtierney.com. Guide pratique pour la visualisation des données manquantes en R, incluant les graphiques upset et le test MCAR de Little.
Code complet
Retrouvez le script de code complet pour les méthodes de détection des données manquantes ci-dessous.
Show full code
################################################################################
########## ~ Méthodes de détection des données manquantes full code ~ ##########
################################################################################
### Step -----------------------------------------------------------------------
# installer `pacman` s'il n'est pas déjà installé
if (!requireNamespace("pacman", quietly = TRUE)) {
install.packages("pacman")
}
# charger les packages requis avec pacman
pacman::p_load(
dplyr, # manipulation des données
ggplot2, # graphiques
ggtext, # texte markdown dans ggplot2
here, # gestion des chemins de fichiers
lubridate, # gestion des dates
naniar, # visualisation et analyse des données manquantes
tidyr, # restructuration des données
cli, # messages de journalisation propres
scales, # formatage des nombres
UpSetR, # graphiques upset pour la co-non-disponibilité
wesanderson # palettes de couleurs
)
# lire les données de surveillance traitées produites par le flux d'importation
df_routine <- readRDS(
here::here(
"01_data",
"1.2_epidemiology",
"1.2a_routine_surveillance",
"processed",
"clean_malaria_routine_data_final.rds"
)
) |>
# supprimer l'étiquette de source d'importation reportée depuis import.qmd
dplyr::select(-dplyr::any_of("sheet_admin")) |>
# filtrer sur les cinq dernières années
dplyr::filter(year >= 2019) |>
dplyr::rename(maladm_hf_u5 = maladm_u5) |>
dplyr::mutate(
# ym : libellé année-mois lisible, utilisé comme axe x discret
ym = format(date, "%Y-%m"),
# date reste de classe Date (déjà Date dans le .rds produit par import.qmd)
date = as.Date(date)
)
# définir les indicateurs principaux signalant qu'un rapport a été soumis
core_inds <- c("test", "conf", "maltreat")
# marquer chaque établissement-mois comme déclarant ou non
df_routine <- df_routine |>
dplyr::mutate(
report_submitted = dplyr::if_any(
dplyr::all_of(core_inds),
~ !is.na(.x)
)
)
# données manquantes conditionnelles : parmi les rapports soumis uniquement,
# quel % de chaque indicateur a été laissé vide ?
conditional_missing <- df_routine |>
dplyr::filter(report_submitted) |>
dplyr::summarise(
dplyr::across(
dplyr::all_of(core_inds),
~ round(mean(is.na(.x)) * 100, 1)
)
) |>
tidyr::pivot_longer(
dplyr::everything(),
names_to = "indicator",
values_to = "pct_missing_given_reported"
)
conditional_missing |>
dplyr::rename(
Indicateur = indicator,
`% manquant sachant déclaré` = pct_missing_given_reported
) |>
knitr::kable(align = "lr", digits = 1)
# variables à résumer
summary_vars <- c("test", "susp", "pres", "conf", "maltreat")
# calculer le % de données manquantes pour les indicateurs agrégés principaux
miss_summary <- naniar::miss_var_summary(
df_routine |>
dplyr::select(dplyr::all_of(summary_vars))
) |>
dplyr::mutate(pct_miss = as.numeric(pct_miss))
# diagramme en barres du % de données manquantes par variable
miss_summary |>
dplyr::mutate(
variable = factor(variable, levels = rev(variable)),
label_text = paste0(round(pct_miss, 1), "%"),
inside = pct_miss > max(pct_miss) * 0.15
) |>
ggplot2::ggplot(ggplot2::aes(x = pct_miss, y = variable)) +
ggplot2::geom_col(fill = "#3B9AB2", width = 0.75) +
ggplot2::geom_text(
ggplot2::aes(
label = label_text,
hjust = ifelse(inside, 1.15, -0.15),
colour = ifelse(inside, "white", "grey20")
),
size = 4,
fontface = "bold",
family = "sans"
) +
ggplot2::scale_colour_identity() +
ggplot2::scale_x_continuous(
expand = ggplot2::expansion(mult = c(0, 0.05)),
labels = function(x) paste0(x, "%")
) +
ggplot2::labs(
title = "Proportion de données manquantes par indicateur",
subtitle = paste(
"% manquant parmi les rapports soumis pour chaque",
"indicateur principal du paludisme"
),
x = NULL,
y = NULL
) +
ggplot2::theme_minimal(base_family = "sans") +
ggplot2::theme(
plot.title = ggplot2::element_text(
size = 16,
face = "bold",
margin = ggplot2::margin(b = 4)
),
plot.subtitle = ggplot2::element_text(
size = 12,
colour = "grey30",
margin = ggplot2::margin(b = 14)
),
axis.text.y = ggplot2::element_text(size = 11, colour = "black"),
axis.text.x = ggplot2::element_text(size = 10, colour = "grey30"),
panel.grid.major.y = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank(),
panel.grid.major.x = ggplot2::element_line(
colour = "grey90",
size = 0.3
),
axis.ticks = ggplot2::element_blank(),
plot.margin = ggplot2::margin(15, 30, 10, 10)
)
# obtenir les variables d'intérêt (agrégées et par groupe d'âge)
vars <- c(
"test", # tests de paludisme agrégés
"test_u5",
"test_5_14",
"test_ov15",
"susp", # cas suspects agrégés
"susp_u5",
"susp_5_14",
"susp_ov15",
"pres", # cas présumés agrégés
"pres_u5",
"pres_5_14",
"pres_ov15",
"conf", # cas confirmés agrégés
"conf_u5",
"conf_5_14",
"conf_ov15",
"maltreat", # traitements agrégés
"maltreat_u5",
"maltreat_5_14",
"maltreat_ov15"
)
# calculer les taux de données manquantes par date pour chaque variable
missing_rate_date <- df_routine |>
dplyr::group_by(date) |>
dplyr::summarise(
dplyr::across(
dplyr::all_of(vars),
~ mean(is.na(.x)) * 100
),
.groups = "drop"
) |>
dplyr::arrange(date) |>
tidyr::pivot_longer(
cols = -ym,
names_to = "variables",
values_to = "missing_rate"
) |>
# appliquer l'ordre explicite de `vars` sur l'axe y pour aligner
# R et Python
dplyr::mutate(variables = factor(variables, levels = vars))
# option pour contrôler la plage de l'échelle de couleurs de la
# carte thermique
# si TRUE : l'échelle de couleurs va de 0 à 100 % (plage complète
# des taux possibles, même si les données réelles ne couvrent pas
# cette plage)
# si FALSE : l'échelle de couleurs est limitée à la plage réelle
# des données manquantes (par ex., si les taux vont de 20 à 70 %,
# l'échelle de couleurs ne couvre que cette plage)
full_range <- FALSE
# définir les limites de l'échelle de remplissage selon l'option
# full_range
fill_limits <- if (full_range) {
# utiliser la plage complète 0-100 % pour l'échelle de couleurs
c(0, 100)
} else {
# utiliser la plage réelle des taux de données manquantes pour
# l'échelle de couleurs
fill_var_values <- missing_rate_date$missing_rate
c(
floor(min(fill_var_values, na.rm = TRUE)),
ceiling(max(fill_var_values, na.rm = TRUE))
)
}
# tracer la plage de données manquantes par variable
missing_plot_date <- ggplot2::ggplot(
missing_rate_date,
ggplot2::aes(
y = variables,
x = ym,
fill = missing_rate
)
) +
ggplot2::geom_tile(colour = "white", linewidth = .2) +
ggplot2::scale_fill_gradientn(
colours = wesanderson::wes_palette(
"Zissou1",
100,
type = "continuous"
),
limits = fill_limits
) +
ggplot2::guides(
fill = ggplot2::guide_colorbar(
title.position = "top",
nrow = 1,
label.position = "bottom",
direction = "horizontal",
barheight = ggplot2::unit(0.3, "cm"),
barwidth = ggplot2::unit(4, "cm"),
ticks = TRUE,
draw.ulim = TRUE,
draw.llim = TRUE
)
) +
ggplot2::scale_x_discrete(expand = c(0, 0)) +
ggplot2::scale_y_discrete(expand = c(0, 0)) +
ggplot2::theme_bw() +
ggplot2::theme(
legend.title = ggplot2::element_text(
size = 12,
face = "bold",
family = "sans"
),
legend.position = "bottom",
legend.direction = "horizontal",
legend.box = "horizontal",
legend.box.just = "center",
legend.margin = ggplot2::margin(t = 0, unit = "cm"),
legend.text = ggplot2::element_text(
size = 8,
family = "sans"
),
axis.title.x = ggplot2::element_text(
margin = ggplot2::margin(t = 5, unit = "pt")
),
axis.title.y = ggplot2::element_text(
margin = ggplot2::margin(r = 10, unit = "pt")
),
axis.text.x = ggplot2::element_text(
angle = 75,
hjust = 1,
family = "sans"
),
axis.text = ggplot2::element_text(family = "sans"),
axis.title = ggplot2::element_text(family = "sans"),
plot.title = ggtext::element_markdown(
size = 12,
family = "sans",
margin = ggplot2::margin(b = 10)
),
strip.text = ggplot2::element_text(
family = "sans",
face = "bold"
),
panel.grid.minor = ggplot2::element_blank(),
panel.grid.major = ggplot2::element_blank(),
panel.background = ggplot2::element_blank(),
strip.background = ggplot2::element_rect(fill = "grey90")
) +
ggplot2::labs(
fill = "Taux de données manquantes (%)",
y = "Variable",
x = "",
title = "La proportion de données manquantes pour les variables sélectionnées par année-mois"
)
# afficher le graphique
missing_plot_date
# calculer les taux de données manquantes par année-mois et adm2
# pour chaque variable
missing_rate_adm2 <- df_routine |>
dplyr::group_by(ym, adm2) |>
dplyr::summarise(
missing_rate = mean(is.na(test_hf_u5)) * 100,
.groups = "drop"
)
# option pour contrôler la plage de l'échelle de couleurs de la
# carte thermique
# si TRUE : l'échelle de couleurs va de 0 à 100 % (plage complète
# des taux possibles, même si les données réelles ne couvrent pas
# cette plage)
# si FALSE : l'échelle de couleurs est limitée à la plage réelle
# des données manquantes (par ex., si les taux vont de 20 à 70 %,
# l'échelle de couleurs ne couvre que cette plage)
full_range <- FALSE
# définir les limites de l'échelle de remplissage selon l'option
# full_range
fill_limits <- if (full_range) {
# utiliser la plage complète 0-100 % pour l'échelle de couleurs
c(0, 100)
} else {
# utiliser la plage réelle des taux de données manquantes pour
# l'échelle de couleurs
fill_var_values <- missing_rate_adm2$missing_rate
c(
floor(min(fill_var_values, na.rm = TRUE)),
ceiling(max(fill_var_values, na.rm = TRUE))
)
}
# tracer la plage de données manquantes par localisation
missing_plot_adm2 <- ggplot2::ggplot(
missing_rate_adm2,
ggplot2::aes(
y = adm2,
x = ym,
fill = missing_rate
)
) +
ggplot2::geom_tile(colour = "white", linewidth = .2) +
ggplot2::scale_fill_gradientn(
colours = wesanderson::wes_palette(
"Zissou1",
100,
type = "continuous"
),
limits = fill_limits
) +
ggplot2::guides(
fill = ggplot2::guide_colorbar(
title.position = "top",
nrow = 1,
label.position = "bottom",
direction = "horizontal",
barheight = ggplot2::unit(0.3, "cm"),
barwidth = ggplot2::unit(4, "cm"),
ticks = TRUE,
draw.ulim = TRUE,
draw.llim = TRUE
)
) +
ggplot2::scale_x_discrete(expand = c(0, 0)) +
ggplot2::scale_y_discrete(expand = c(0, 0)) +
ggplot2::theme_bw() +
ggplot2::theme(
legend.title = ggplot2::element_text(
size = 12,
face = "bold",
family = "sans"
),
legend.position = "bottom",
legend.direction = "horizontal",
legend.box = "horizontal",
legend.box.just = "center",
legend.margin = ggplot2::margin(t = 0, unit = "cm"),
legend.text = ggplot2::element_text(
size = 8,
family = "sans"
),
axis.title.x = ggplot2::element_text(
margin = ggplot2::margin(t = 5, unit = "pt")
),
axis.title.y = ggplot2::element_text(
margin = ggplot2::margin(r = 10, unit = "pt")
),
axis.text.x = ggplot2::element_text(
angle = 75,
hjust = 1,
family = "sans"
),
axis.text = ggplot2::element_text(family = "sans"),
axis.title = ggplot2::element_text(family = "sans"),
plot.title = ggtext::element_markdown(
size = 12,
family = "sans",
margin = ggplot2::margin(b = 10)
),
strip.text = ggplot2::element_text(
family = "sans",
face = "bold"
),
panel.grid.minor = ggplot2::element_blank(),
panel.grid.major = ggplot2::element_blank(),
panel.background = ggplot2::element_blank(),
strip.background = ggplot2::element_rect(fill = "grey90")
) +
ggplot2::labs(
fill = "Taux de données manquantes (%)",
y = "District",
x = "",
title = "La proportion de données manquantes pour test_hf_u5 par année-mois et adm2"
)
# afficher le graphique
missing_plot_adm2
# définir les indicateurs de base à conserver lors de la désagrégation
core_indicators <- c(
"adm0",
"adm1",
"adm2",
"adm3",
"hf",
"hf_uid",
"year",
"month",
"ym",
"date"
)
# sélectionner les indicateurs de base et les variables désagrégées
df_routine_disagg <- df_routine |>
dplyr::select(
dplyr::any_of(core_indicators),
dplyr::matches("_(com|hf)_(u5|5_14|ov15)$")
)
# transformer en format long avec colonnes distinctes pour le type
# d'établissement et le groupe d'âge
df_routine_disagg_long <- df_routine_disagg |>
# exclure maladm_hf_u5 : n'a pas de contreparties au niveau
# communautaire ni pour les autres groupes d'âge, donc ne peut
# pas être pivoté dans le format long ci-dessous
dplyr::select(-maladm_hf_u5) |>
tidyr::pivot_longer(
cols = dplyr::matches("_(com|hf)_(u5|5_14|ov15)$"),
names_to = c("indicator", "facility_type", "age_group"),
names_pattern = "(.+)_(com|hf)_(u5|5_14|ov15)$",
values_to = "value"
) |>
# réétiqueter les facteurs
dplyr::mutate(
age_group = factor(
age_group,
levels = c("u5", "5_14", "ov15"),
labels = c("Moins de 5 ans", "5 à 15 ans", "Plus de 15 ans")
),
facility_type = factor(
facility_type,
levels = c("hf", "com"),
labels = c("Établissement de santé", "Communauté")
)
)
# aperçu de la structure des données désagrégées
df_routine_disagg_long |>
utils::head() |>
knitr::kable()
# préparer les données pour le diagramme à barres empilées avec
# groupe d'âge et type d'établissement
missing_present_data_facility <- df_routine_disagg_long |>
dplyr::group_by(indicator, age_group, facility_type) |>
dplyr::summarise(
total_records = dplyr::n(),
missing_count = sum(is.na(value)),
present_count = sum(!is.na(value)),
missing_pct = round(missing_count / total_records * 100, 2),
present_pct = round(present_count / total_records * 100, 2),
.groups = "drop"
) |>
tidyr::pivot_longer(
cols = c(missing_pct, present_pct),
names_to = "status",
values_to = "percentage",
names_pattern = "(.+)_pct"
) |>
dplyr::mutate(
status = factor(
status,
levels = c("missing", "present"),
labels = c("Missing", "Present")
)
)
# créer le diagramme à barres empilées avec facettes par groupe
# d'âge et type d'établissement
age_facility_miss_plot <- missing_present_data_facility |>
ggplot2::ggplot(ggplot2::aes(
x = percentage,
y = factor(age_group, levels = rev(levels(factor(age_group)))),
fill = status
)) +
ggplot2::geom_col(alpha = 0.8) +
ggplot2::facet_grid(indicator ~ facility_type) +
ggplot2::scale_fill_viridis_d(
option = "D",
begin = 0.2,
end = 0.5,
breaks = c("Present", "Missing")
) +
ggplot2::guides(
fill = ggplot2::guide_legend(
title.position = "top",
title.hjust = 0,
label.position = "bottom"
)
) +
ggplot2::labs(
title = "Données manquantes vs présentes par indicateur, groupe d'âge et type d'établissement",
x = "\nPourcentage (%)",
y = "Groupe d'âge (années)\n",
fill = "Statut des données"
) +
ggplot2::scale_x_continuous(expand = c(0, 0)) +
ggplot2::scale_y_discrete(expand = c(0, 0)) +
ggplot2::theme_minimal() +
ggplot2::theme(
legend.position = "bottom",
legend.direction = "horizontal",
legend.justification = "left",
legend.box.just = "left",
axis.text.y = ggplot2::element_text(size = 8),
strip.text = ggplot2::element_text(
family = "sans",
face = "bold"
),
panel.grid.minor = ggplot2::element_blank(),
panel.grid.major = ggplot2::element_blank(),
panel.background = ggplot2::element_blank(),
panel.border = ggplot2::element_rect(
colour = "black",
fill = NA,
size = .7
),
panel.spacing.x = ggplot2::unit(0.5, "cm"),
plot.margin = ggplot2::margin(10, 20, 10, 10)
)
# afficher le graphique
age_facility_miss_plot
# transformer les données en format large pour examiner les
# relations entre indicateurs
df_wide <- df_routine_disagg_long |>
dplyr::select(
dplyr::any_of(core_indicators),
facility_type,
age_group,
indicator,
value
) |>
tidyr::pivot_wider(
names_from = indicator,
values_from = value
)
# calculer les effectifs détaillés de données manquantes pour le sous-titre
n_test_missing_conf_zero <- df_wide |>
dplyr::filter(conf == 0, is.na(test)) |>
nrow()
n_conf_missing_test_zero <- df_wide |>
dplyr::filter(test == 0, is.na(conf)) |>
nrow()
n_test_na_conf_positive <- df_wide |>
dplyr::filter(is.na(test), conf > 0) |>
nrow()
n_conf_na_test_positive <- df_wide |>
dplyr::filter(is.na(conf), test > 0) |>
nrow()
# créer le sous-titre détaillé avec tous les scénarios de données manquantes
subtitle_text <- paste0(
"N = ",
scales::comma(n_test_missing_conf_zero),
" où conf = 0 mais test est manquant (zéro légitime) ; \n",
"N = ",
scales::comma(n_conf_missing_test_zero),
" où test = 0 mais conf est manquant (zéro légitime) ; \n",
"N = ",
scales::comma(n_test_na_conf_positive),
" où test est manquant mais conf > 0 (incohérence logique) ; \n",
"N = ",
scales::comma(n_conf_na_test_positive),
" où conf est manquant mais test > 0 (zéro légitime possible)"
)
# créer le nuage de points montrant la relation entre tests et cas confirmés
structural_zeros_plot <- ggplot2::ggplot(
data = df_wide,
mapping = ggplot2::aes(x = test, y = conf)
) +
naniar::geom_miss_point() +
ggplot2::geom_vline(
xintercept = 0,
linetype = "dashed",
color = "grey40",
linewidth = 0.2
) +
ggplot2::geom_hline(
yintercept = 0,
linetype = "dashed",
color = "grey40",
linewidth = 0.2
) +
ggplot2::scale_x_continuous(
labels = scales::comma_format()
) +
ggplot2::scale_y_continuous(
labels = scales::comma_format()
) +
ggplot2::scale_color_viridis_d(
option = "D",
begin = 0.2,
end = 0.5,
breaks = c("Not Missing", "Missing"),
labels = c("Present", "Missing")
) +
ggplot2::guides(
color = ggplot2::guide_legend(
title.position = "top",
title.hjust = 0,
override.aes = list(
size = 5
),
label.position = "bottom"
)
) +
ggplot2::labs(
title = "Zéros structurels : tests vs confirmation",
subtitle = subtitle_text,
x = "\nTests réalisés",
y = "Cas confirmés\n",
color = "Statut des données"
) +
ggplot2::theme_minimal() +
ggplot2::theme(
legend.position = "bottom",
legend.direction = "horizontal",
legend.justification = "left",
legend.box.just = "left",
axis.text.y = ggplot2::element_text(size = 8),
strip.text = ggplot2::element_text(
family = "sans",
face = "bold"
),
panel.border = ggplot2::element_rect(
colour = "black",
fill = NA,
size = .7
),
panel.spacing.x = ggplot2::unit(0.5, "cm"),
plot.margin = ggplot2::margin(10, 20, 10, 10),
plot.subtitle = ggplot2::element_text(size = 9, color = "grey30")
)
# afficher le graphique
structural_zeros_plotShow full code
################################################################################
########## ~ Méthodes de détection des données manquantes full code ~ ##########
################################################################################
### Step -----------------------------------------------------------------------
from pathlib import Path
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
import matplotlib.ticker as mticker
import numpy as np
import pandas as pd
from pyprojroot import here
# ── assistants cli ───────────────────────────────────────────────────────────
def cli_header(message):
print(f"\n{message}")
def cli_info(message):
print(f"INFO: {message}")
def cli_success(message):
print(f"SUCCESS: {message}")
def cli_warning(message):
print(f"WARNING: {message}")
def cli_danger(message):
print(f"ERROR: {message}")
def anti_join(left, right, on):
"""Retourne les lignes de left sans correspondance dans right."""
right_keys = right[on].drop_duplicates()
return (
left.merge(right_keys, on=on, how="left", indicator=True)
.loc[lambda x: x["_merge"] == "left_only"]
.drop(columns="_merge")
)
from pathlib import Path
import pandas as pd
from pyprojroot import here
# lire les données de surveillance traitées produites par le flux d'importation.
# le .rds (chargé par R) et le .parquet (chargé ici) sont écrits à partir
# du même dhis2_df dans import.qmd : les deux langages voient les mêmes données.
data_path = Path(here(
"01_data/1.2_epidemiology/1.2a_routine_surveillance/processed/"
"clean_malaria_routine_data_final.parquet"
))
df_routine = (
pd.read_parquet(data_path)
# supprimer l'étiquette de source d'importation reportée depuis import.qmd
.drop(columns="sheet_admin", errors="ignore")
# filtrer sur les cinq dernières années
.loc[lambda d: d["year"] >= 2019]
.rename(columns={"maladm_u5": "maladm_hf_u5"})
.assign(date=lambda d: pd.to_datetime(d["date"], errors="coerce"))
.assign(ym=lambda d: d["date"].dt.strftime("%Y-%m"))
.reset_index(drop=True)
)
import pandas as pd
# définir les indicateurs principaux signalant qu'un rapport a été soumis
core_inds = ["test", "conf", "maltreat"]
# marquer chaque établissement-mois comme déclarant ou non
df_routine = df_routine.assign(
report_submitted=lambda d: d[core_inds].notna().any(axis=1)
)
# données manquantes conditionnelles : parmi les rapports soumis uniquement,
# quel % de chaque indicateur a été laissé vide ?
conditional_missing = (
df_routine.loc[df_routine["report_submitted"]]
[core_inds]
.isna()
.mean()
.mul(100)
.round(1)
.rename_axis("indicator")
.reset_index(name="pct_missing_given_reported")
)
conditional_missing
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
import pandas as pd
# résumé tabulaire du % de données manquantes pour les indicateurs agrégés principaux
summary_vars = ["test", "susp", "pres", "conf", "maltreat"]
miss_summary = (
pd.DataFrame({
"variable": summary_vars,
"n_miss": [df_routine[v].isna().sum() for v in summary_vars],
"pct_miss": [
round(df_routine[v].isna().mean() * 100, 1)
for v in summary_vars
],
})
.sort_values("pct_miss", ascending=False)
.reset_index(drop=True)
)
# diagramme en barres du % de données manquantes par variable (horizontal, trié décroissant)
vmax = float(miss_summary["pct_miss"].max())
threshold = vmax * 0.15
fig, ax = plt.subplots(figsize=(9, 5.2))
bars = ax.barh(
miss_summary["variable"],
miss_summary["pct_miss"],
color="#3B9AB2",
height=0.75
)
ax.invert_yaxis()
# étiquettes de valeurs : à l'intérieur de la barre (blanc) si l'espace le permet,
# à l'extérieur (gris) pour les barres courtes
for bar, val in zip(bars, miss_summary["pct_miss"]):
label = f"{round(val, 1)}%"
if val > threshold:
ax.text(
val - vmax * 0.012,
bar.get_y() + bar.get_height() / 2,
label,
va="center",
ha="right",
color="white",
fontsize=11,
fontweight="bold"
)
else:
ax.text(
val + vmax * 0.012,
bar.get_y() + bar.get_height() / 2,
label,
va="center",
ha="left",
color="#333333",
fontsize=11,
fontweight="bold"
)
# titre (grand, gras) + sous-titre (plus petit, gris)
fig.suptitle(
"Proportion de données manquantes par indicateur",
fontsize=16,
fontweight="bold",
x=0.05,
ha="left",
y=0.98
)
ax.set_title(
"% manquant parmi les rapports soumis pour chaque indicateur principal du paludisme",
fontsize=12,
color="#555555",
loc="left",
pad=8
)
ax.set_xlabel("")
ax.set_ylabel("")
ax.xaxis.set_major_formatter(
mticker.FuncFormatter(lambda x, _: f"{int(x)}%")
)
ax.tick_params(left=False, labelsize=11, colors="#333333")
ax.tick_params(axis="x", colors="#555555", labelsize=10)
# apparence épurée : pas de bordure, seulement de légères lignes de grille sur l'axe x
for spine in ax.spines.values():
spine.set_visible(False)
ax.grid(axis="x", color="#E5E5E5", linewidth=0.6)
ax.grid(axis="y", visible=False)
ax.set_axisbelow(True)
ax.set_xlim(0, max(vmax * 1.05, 10))
plt.tight_layout(rect=[0, 0, 1, 0.94])
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
import numpy as np
import pandas as pd
# variables d'intérêt (agrégées et par groupe d'âge)
vars_of_interest = [
"test", # tests de paludisme agrégés
"test_u5",
"test_5_14",
"test_ov15",
"susp", # cas suspects agrégés
"susp_u5",
"susp_5_14",
"susp_ov15",
"pres", # cas présumés agrégés
"pres_u5",
"pres_5_14",
"pres_ov15",
"conf", # cas confirmés agrégés
"conf_u5",
"conf_5_14",
"conf_ov15",
"maltreat", # traitements agrégés
"maltreat_u5",
"maltreat_5_14",
"maltreat_ov15",
]
# calculer les taux de données manquantes par année-mois pour chaque variable
missing_rate_date = (
df_routine.groupby("ym", as_index=False)[vars_of_interest]
.apply(lambda g: g[vars_of_interest].isna().mean() * 100)
.reset_index()
.rename(columns={"level_0": "ym"})
)
# reconstruire depuis groupby pour conserver ym correctement
_grouped = df_routine.groupby("ym")
missing_rate_date = pd.DataFrame(
{v: _grouped[v].apply(lambda s: s.isna().mean() * 100)
for v in vars_of_interest}
).reset_index()
# pivoter en format long
missing_rate_long = missing_rate_date.melt(
id_vars="ym",
value_vars=vars_of_interest,
var_name="variables",
value_name="missing_rate"
).sort_values("ym")
# option pour contrôler la plage de l'échelle de couleurs de la carte thermique
full_range = False
if full_range:
vmin, vmax = 0.0, 100.0
else:
vals = missing_rate_long["missing_rate"].dropna()
vmin = float(np.floor(vals.min()))
vmax = float(np.ceil(vals.max()))
# palette Zissou1 (reproduit wesanderson::wes_palette("Zissou1", 100))
zissou1_colors = ["#3B9AB2", "#78B7C5", "#EBCC2A", "#E1AF00", "#F21A00"]
zissou1_cmap = mcolors.LinearSegmentedColormap.from_list(
"Zissou1", zissou1_colors, N=100
)
# pivoter vers une matrice pour pcolormesh
ym_order = sorted(missing_rate_long["ym"].unique())
var_order = vars_of_interest # ordre de haut en bas sur l'axe y
pivot = (
missing_rate_long
.pivot(index="variables", columns="ym", values="missing_rate")
.reindex(index=var_order, columns=ym_order)
)
fig, ax = plt.subplots(figsize=(12, 8))
mesh = ax.pcolormesh(
np.arange(len(ym_order) + 1),
np.arange(len(var_order) + 1),
pivot.values,
cmap=zissou1_cmap,
vmin=vmin,
vmax=vmax,
linewidth=0.2,
edgecolors="white"
)
ax.set_aspect("auto")
# étiquettes et graduations de l'axe x
ax.set_xticks(np.arange(len(ym_order)) + 0.5)
ax.set_xticklabels(ym_order, rotation=75, ha="right", fontsize=8)
# étiquettes et graduations de l'axe y
ax.set_yticks(np.arange(len(var_order)) + 0.5)
ax.set_yticklabels(var_order, fontsize=8)
ax.set_xlabel("")
ax.set_ylabel("Variable")
ax.set_title(
"La proportion de données manquantes pour les variables sélectionnées par année-mois",
fontsize=12, pad=10
)
# barre de couleurs horizontale en bas
cbar = fig.colorbar(
mesh, ax=ax, orientation="horizontal",
fraction=0.03, pad=0.18, aspect=40
)
cbar.set_label("Taux de données manquantes (%)", fontsize=12, fontweight="bold")
cbar.ax.tick_params(labelsize=8)
# supprimer les lignes de grille
ax.grid(False)
plt.tight_layout()
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
import numpy as np
import pandas as pd
# calculer les taux de données manquantes par année-mois et adm2 pour test_hf_u5
missing_rate_adm2 = (
df_routine.groupby(["ym", "adm2"], as_index=False)
.agg(missing_rate=("test_hf_u5", lambda s: s.isna().mean() * 100))
)
# option pour contrôler la plage de l'échelle de couleurs de la carte thermique
full_range = False
if full_range:
vmin, vmax = 0.0, 100.0
else:
vals = missing_rate_adm2["missing_rate"].dropna()
vmin = float(np.floor(vals.min()))
vmax = float(np.ceil(vals.max()))
# palette Zissou1
zissou1_colors = ["#3B9AB2", "#78B7C5", "#EBCC2A", "#E1AF00", "#F21A00"]
zissou1_cmap = mcolors.LinearSegmentedColormap.from_list(
"Zissou1", zissou1_colors, N=100
)
ym_order = sorted(missing_rate_adm2["ym"].unique())
adm2_order = sorted(missing_rate_adm2["adm2"].unique())
pivot = (
missing_rate_adm2
.pivot(index="adm2", columns="ym", values="missing_rate")
.reindex(index=adm2_order, columns=ym_order)
)
fig, ax = plt.subplots(figsize=(12, 8))
mesh = ax.pcolormesh(
np.arange(len(ym_order) + 1),
np.arange(len(adm2_order) + 1),
pivot.values,
cmap=zissou1_cmap,
vmin=vmin,
vmax=vmax,
linewidth=0.2,
edgecolors="white"
)
ax.set_aspect("auto")
ax.set_xticks(np.arange(len(ym_order)) + 0.5)
ax.set_xticklabels(ym_order, rotation=75, ha="right", fontsize=8)
ax.set_yticks(np.arange(len(adm2_order)) + 0.5)
ax.set_yticklabels(adm2_order, fontsize=8)
ax.set_xlabel("")
ax.set_ylabel("District")
ax.set_title(
"La proportion de données manquantes pour test_hf_u5 par année-mois et adm2",
fontsize=12, pad=10
)
cbar = fig.colorbar(
mesh, ax=ax, orientation="horizontal",
fraction=0.03, pad=0.18, aspect=40
)
cbar.set_label("Taux de données manquantes (%)", fontsize=12, fontweight="bold")
cbar.ax.tick_params(labelsize=8)
ax.grid(False)
plt.tight_layout()
import re
import pandas as pd
# définir les colonnes de base à conserver lors de la désagrégation
core_indicators = [
"adm0", "adm1", "adm2", "adm3",
"hf", "hf_uid",
"year", "month", "ym", "date"
]
# sélectionner les indicateurs de base et les colonnes désagrégées
disagg_pattern = re.compile(r".+_(com|hf)_(u5|5_14|ov15)$")
disagg_cols = [c for c in df_routine.columns if disagg_pattern.match(c)]
keep_core = [c for c in core_indicators if c in df_routine.columns]
df_routine_disagg = df_routine[keep_core + disagg_cols].copy()
# exclure maladm_hf_u5 : n'a pas de contreparties au niveau communautaire ni pour les autres groupes d'âge
if "maladm_hf_u5" in df_routine_disagg.columns:
df_routine_disagg = df_routine_disagg.drop(columns=["maladm_hf_u5"])
# ré-identifier les colonnes désagrégées après l'exclusion
disagg_cols_final = [
c for c in df_routine_disagg.columns
if c not in keep_core
]
# transformer en format long avec colonnes distinctes facility_type et age_group
def _parse_col(col):
"""Extract (indicator, facility_type, age_group) from column name."""
m = re.match(r"^(.+)_(com|hf)_(u5|5_14|ov15)$", col)
if m:
return m.group(1), m.group(2), m.group(3)
return None, None, None
long_rows = []
for col in disagg_cols_final:
ind, ftype, age = _parse_col(col)
if ind is None:
continue
tmp = df_routine_disagg[keep_core + [col]].copy()
tmp = tmp.rename(columns={col: "value"})
tmp["indicator"] = ind
tmp["facility_type"] = ftype
tmp["age_group"] = age
long_rows.append(tmp)
df_routine_disagg_long = pd.concat(long_rows, ignore_index=True)
# réétiqueter les facteurs pour correspondre à la sortie R
age_order = ["u5", "5_14", "ov15"]
age_labels = ["Moins de 5 ans", "5 à 15 ans", "Plus de 15 ans"]
ftype_order = ["hf", "com"]
ftype_labels = ["Établissement de santé", "Communauté"]
df_routine_disagg_long["age_group"] = pd.Categorical(
df_routine_disagg_long["age_group"].map(
dict(zip(age_order, age_labels))
),
categories=age_labels,
ordered=True
)
df_routine_disagg_long["facility_type"] = pd.Categorical(
df_routine_disagg_long["facility_type"].map(
dict(zip(ftype_order, ftype_labels))
),
categories=ftype_labels,
ordered=True
)
# aperçu de la structure des données désagrégées
df_routine_disagg_long.head().style.hide(axis="index")
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
import numpy as np
import pandas as pd
# préparer les données pour le diagramme à barres empilées avec
# groupe d'âge et type d'établissement
missing_present_data_facility = (
df_routine_disagg_long
.groupby(["indicator", "age_group", "facility_type"], observed=True,
as_index=False)
.agg(
total_records=("value", "count"),
missing_count=("value", lambda s: s.isna().sum()),
present_count=("value", lambda s: s.notna().sum()),
)
.assign(
missing_pct=lambda d: (d["missing_count"] / d["total_records"] * 100)
.round(2),
present_pct=lambda d: (d["present_count"] / d["total_records"] * 100)
.round(2),
)
)
# pivoter en format long pour la colonne status
mp_long = missing_present_data_facility.melt(
id_vars=["indicator", "age_group", "facility_type"],
value_vars=["missing_pct", "present_pct"],
var_name="status",
value_name="percentage"
).assign(
status=lambda d: pd.Categorical(
d["status"].map({"missing_pct": "Missing", "present_pct": "Present"}),
categories=["Missing", "Present"],
ordered=True
)
)
# palette viridis D : begin=0.2, end=0.5 pour deux catégories
import matplotlib.cm as cm
viridis = cm.get_cmap("viridis")
color_missing = viridis(0.2)
color_present = viridis(0.5)
status_colors = {"Missing": color_missing, "Present": color_present}
indicators = list(mp_long["indicator"].unique())
facility_types = list(mp_long["facility_type"].cat.categories)
age_labels_ordered = list(mp_long["age_group"].cat.categories)
age_rev = list(reversed(age_labels_ordered))
n_ind = len(indicators)
n_ftype = len(facility_types)
fig, axes = plt.subplots(
n_ind, n_ftype,
figsize=(12, 8),
sharex=True,
sharey="row"
)
for i, ind in enumerate(indicators):
for j, ftype in enumerate(facility_types):
ax = axes[i][j] if n_ind > 1 else axes[j]
subset = mp_long.loc[
(mp_long["indicator"] == ind) &
(mp_long["facility_type"] == ftype)
]
for status in ["Present", "Missing"]:
s_sub = subset.loc[subset["status"] == status]
s_sub = s_sub.set_index("age_group").reindex(age_rev)
ax.barh(
s_sub.index,
s_sub["percentage"],
color=status_colors[status],
alpha=0.8,
label=status
)
ax.set_xlim(0, 100)
ax.set_xlabel("")
ax.set_ylabel("")
# bordure du panneau
for spine in ax.spines.values():
spine.set_linewidth(0.7)
# libellés des bandes
if i == 0:
ax.set_title(str(ftype), fontsize=9, fontweight="bold")
if j == n_ftype - 1:
ax.yaxis.set_label_position("right")
ax.set_ylabel(str(ind), rotation=270, labelpad=12,
fontsize=9, fontweight="bold")
# pas de grille
ax.grid(False)
# libellés des axes partagés
fig.supxlabel("Pourcentage (%)", y=0.02, fontsize=10)
fig.supylabel("Groupe d'âge (années)", x=0.02, fontsize=10)
fig.suptitle(
"Données manquantes vs présentes par indicateur, groupe d'âge et type d'établissement",
fontsize=12, y=1.01
)
# légende partagée
handles = [
plt.Rectangle((0, 0), 1, 1, color=status_colors["Present"], alpha=0.8),
plt.Rectangle((0, 0), 1, 1, color=status_colors["Missing"], alpha=0.8),
]
fig.legend(
handles, ["Present", "Missing"],
title="Data Status",
loc="lower left",
bbox_to_anchor=(0.0, -0.04),
ncol=2,
frameon=False,
fontsize=9
)
plt.tight_layout()
import matplotlib.cm as cm
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
import numpy as np
import pandas as pd
# transformer en format large pour examiner les relations entre indicateurs
keep_core = [
"adm0", "adm1", "adm2", "adm3",
"hf", "hf_uid", "year", "month", "ym", "date"
]
keep_cols = [c for c in keep_core if c in df_routine_disagg_long.columns]
df_wide = (
df_routine_disagg_long[keep_cols + ["facility_type", "age_group",
"indicator", "value"]]
.pivot_table(
index=keep_cols + ["facility_type", "age_group"],
columns="indicator",
values="value",
aggfunc="first",
observed=True
)
.reset_index()
)
df_wide.columns.name = None
# calculer les effectifs de données manquantes pour le sous-titre
n_test_missing_conf_zero = df_wide.loc[
(df_wide["conf"] == 0) & df_wide["test"].isna()
].shape[0]
n_conf_missing_test_zero = df_wide.loc[
(df_wide["test"] == 0) & df_wide["conf"].isna()
].shape[0]
n_test_na_conf_positive = df_wide.loc[
df_wide["test"].isna() & (df_wide["conf"] > 0)
].shape[0]
n_conf_na_test_positive = df_wide.loc[
df_wide["conf"].isna() & (df_wide["test"] > 0)
].shape[0]
subtitle_text = (
f"N = {n_test_missing_conf_zero:,} où conf = 0 mais test est manquant "
f"(zéro légitime) ; \n"
f"N = {n_conf_missing_test_zero:,} où test = 0 mais conf est manquant "
f"(zéro légitime) ; \n"
f"N = {n_test_na_conf_positive:,} où test est manquant mais conf > 0 "
f"(incohérence logique) ; \n"
f"N = {n_conf_na_test_positive:,} où conf est manquant mais test > 0 "
f"(zéro légitime possible)"
)
# créer les données de démonstration correspondant au chunk R de rendu :
# lignes 400-600 où conf est NA obtiennent test = 0 (tendance zéro légitime)
# lignes 490-900 où test est NA obtiennent conf = 0 (tendance zéro légitime)
df_wide_demo = df_wide.copy().reset_index(drop=True)
mask1 = (df_wide_demo.index.isin(range(400, 601))) & df_wide_demo["conf"].isna()
df_wide_demo.loc[mask1, "test"] = 0.0
mask2 = (df_wide_demo.index.isin(range(490, 901))) & df_wide_demo["test"].isna()
df_wide_demo.loc[mask2, "conf"] = 0.0
# calculer les décalages de marge pour le comportement miss_point
test_obs = df_wide_demo["test"].dropna()
conf_obs = df_wide_demo["conf"].dropna()
test_range = test_obs.max() - test_obs.min() if len(test_obs) > 1 else 1.0
conf_range = conf_obs.max() - conf_obs.min() if len(conf_obs) > 1 else 1.0
test_margin = test_obs.min() - 0.1 * test_range
conf_margin = conf_obs.min() - 0.1 * conf_range
viridis = cm.get_cmap("viridis")
color_present = viridis(0.5) # "Not Missing"
color_missing = viridis(0.2) # "Missing"
fig, ax = plt.subplots(figsize=(10, 8))
# --- points présents-présents ---
mask_pp = df_wide_demo["test"].notna() & df_wide_demo["conf"].notna()
ax.scatter(
df_wide_demo.loc[mask_pp, "test"],
df_wide_demo.loc[mask_pp, "conf"],
color=color_present, alpha=0.4, s=10, label="Present", rasterized=True
)
# --- test manquant, conf présent : décaler test vers la marge gauche ---
mask_tm = df_wide_demo["test"].isna() & df_wide_demo["conf"].notna()
ax.scatter(
[test_margin] * mask_tm.sum(),
df_wide_demo.loc[mask_tm, "conf"],
color=color_missing, alpha=0.4, s=10, label="Missing", rasterized=True
)
# --- conf manquant, test présent : décaler conf vers la marge inférieure ---
mask_cm = df_wide_demo["conf"].isna() & df_wide_demo["test"].notna()
ax.scatter(
df_wide_demo.loc[mask_cm, "test"],
[conf_margin] * mask_cm.sum(),
color=color_missing, alpha=0.4, s=10, rasterized=True
)
# lignes de référence à zéro
ax.axvline(0, linestyle="dashed", color="grey", linewidth=0.2)
ax.axhline(0, linestyle="dashed", color="grey", linewidth=0.2)
# libellés des graduations au format avec virgule
ax.xaxis.set_major_formatter(mticker.FuncFormatter(
lambda x, _: f"{x:,.0f}"
))
ax.yaxis.set_major_formatter(mticker.FuncFormatter(
lambda y, _: f"{y:,.0f}"
))
ax.set_xlabel("\nTests réalisés")
ax.set_ylabel("Cas confirmés\n")
ax.set_title("Zéros structurels : tests vs confirmation", fontsize=12)
ax.text(
0.0, -0.12, subtitle_text,
transform=ax.transAxes, fontsize=9, color="grey",
verticalalignment="top"
)
handles = [
plt.Line2D([0], [0], marker="o", color="w",
markerfacecolor=color_present, markersize=8),
plt.Line2D([0], [0], marker="o", color="w",
markerfacecolor=color_missing, markersize=8),
]
ax.legend(
handles, ["Present", "Missing"],
title="Data Status",
loc="lower left",
frameon=True,
fontsize=9
)
for spine in ax.spines.values():
spine.set_linewidth(0.7)
plt.tight_layout()