# Vérifier si 'pacman' est installé; l'installer s'il manque
if (!requireNamespace("pacman", quietly = TRUE)) {
install.packages("pacman")
}
# Charger tous les packages requis avec pacman
pacman::p_load(
sf, # pour lire et manipuler les shapefiles
rio, # pour importer des fichiers Excel (remplace readxl)
dplyr, # pour manipuler les données
stringr, # pour nettoyer et formater les chaînes
ggplot2, # pour créer des graphiques
cli, # pour les sorties console stylisées
here # pour les chemins de fichiers multiplateformes
)
# sntutils contient plusieurs fonctions d'aide utiles pour la gestion
# et le nettoyage des données
if (!requireNamespace("sntutils", quietly = TRUE)) {
devtools::install_github("ahadi-analytics/sntutils")
}
# pour analyser les coordonnées
if (!requireNamespace("parzer", quietly = TRUE)) {
remotes::install_github("ropensci/parzer")
}Fusion des shapefiles avec des données tabulaires
Intermédiaire
Vue d’ensemble
Dans le cadre de la SNT, la dimension spatiale est centrale, car tout le processus vise à appuyer des évaluations et des recommandations adaptées aux niveaux infranationaux. L’objectif est de refléter les hétérogénéités locales de transmission du paludisme, de couverture des interventions et de capacité du système de santé. Pour cela, les données doivent être correctement reliées à des unités géographiques comme les districts ou les chiefdoms. Chaque intrant principal, des estimations de PfPR et indicateurs de surveillance de routine aux données environnementales et de campagne, est associé à un lieu. Notre capacité à stratifier la charge, évaluer la performance du programme et prioriser les actions dépend d’une liaison spatiale propre et cohérente.
La fusion de données tabulaires avec des limites spatiales associe des valeurs telles que l’incidence, la couverture ou les classifications de risque aux bonnes unités administratives. Ce processus permet la cartographie, la stratification et la prise de décision. De nombreuses étapes du flux de travail SNT dépendent de la fusion spatiale : les surfaces modélisées comme le PfPR et les covariables environnementales sont superposées aux limites administratives pendant la stratification; les indicateurs de routine issus de DHIS2 sont joints aux shapefiles de districts pour l’analyse de la charge; les données de campagne sont reliées aux zones géographiques pour repérer les lacunes de couverture. Une structure spatiale cohérente garantit que les données provenant de différentes sources s’intègrent correctement, soutient l’alignement entre intrants et produit des cartes, résumés et résultats de ciblage utilisables par le programme.
Les shapefiles constituent la base de toutes les composantes du processus SNT; il faut donc des méthodes fiables pour les joindre à d’autres jeux de données. Les différences de nommage, de formatage ou de précision des coordonnées provoquent souvent des fusions échouées ou inexactes. Cette section montre comment préparer les jeux de données pour la jointure, choisir les méthodes de jointure appropriées et valider les résultats. Ces techniques forment le socle des flux de travail d’analyse spatiale auxquels les analystes se référeront dans toute la bibliothèque de code.
TipPlus d’informations sur les données spatiales
Pour des informations de contexte sur les shapefiles et des liens vers tout le contenu sur les données spatiales de la bibliothèque de code SNT, y compris les rasters et les données ponctuelles, consultez la page Vue d’ensemble des données spatiales.
NoteObjectifs
- Intégrer des données spatiales et tabulaires à l’aide de méthodes de jointure attributaire et fondée sur les coordonnées
- Résoudre les incohérences de noms, les problèmes de coordonnées et les désalignements de CRS par une validation systématique
- Appliquer des contrôles diagnostiques pour garantir une liaison spatiale complète et exacte
- Gérer les cas limites, notamment les jointures avec tampon, la conversion DMS et les problèmes de précision des limites
- Valider les résultats à l’aide de techniques de visualisation
- Enregistrer les sorties pour les analyses ultérieures
Comprendre les jointures spatiales
Avant d’analyser ou de visualiser des données dans les flux de travail SNT, nous devons les relier aux bonnes limites géographiques. Ce processus, appelé jointure spatiale, connecte des jeux de données tabulaires (comme des indicateurs de routine, des résultats d’enquêtes ou des registres d’établissements de santé) aux shapefiles qui définissent les régions, districts ou autres unités administratives. Une jointure exacte garantit que tous les indicateurs sont correctement alignés sur la géographie pour l’analyse et la cartographie. Cette section couvre les deux principaux types de jointures utilisés dans la SNT : les jointures attributaires et les jointures fondées sur les coordonnées. Elle explique quand utiliser chaque méthode et met en évidence les pièges courants. Ces méthodes de jointure fournissent la base de l’analyse spatiale dans tout ce guide.
Jointure par noms administratifs (jointures attributaires)
Dans la SNT, nous relions couramment les données tabulaires aux shapefiles en faisant correspondre les noms d’unités administratives, comme region, district ou chiefdom, au moyen d’une jointure attributaire. Cette méthode est essentielle lorsque les jeux de données ne contiennent pas de coordonnées, car de nombreux indicateurs de routine, résultats d’enquêtes et résumés de campagnes sont organisés par nom. Lorsque les noms correspondent parfaitement entre les données tabulaires et le shapefile, les valeurs telles que l’incidence ou la couverture sont correctement rattachées aux unités géographiques, ce qui permet une analyse tenant compte de l’espace. De petites différences d’orthographe, de formatage ou de ponctuation peuvent rompre la jointure ou provoquer des correspondances incorrectes. Un alignement soigneux des noms garantit des résultats valides.
Quand utiliser les jointures attributaires
Utilisez cette méthode lorsque :
- Le jeu de données tabulaire ne contient pas de coordonnées spatiales
- Les noms administratifs sont relativement propres, standardisés et à jour
- Vous travaillez avec des données de routine ou d’enquête organisées par géographie
- Une table de correspondance existe pour résoudre les incohérences
Problèmes courants qui bloquent les jointures
Les jointures attributaires échouent souvent à cause d’incohérences subtiles dans la clé de jointure, c’est-à-dire la colonne utilisée pour faire correspondre les enregistrements entre jeux de données. Lorsque les noms utilisés comme clés de jointure diffèrent même légèrement entre les données tabulaires et le shapefile, les jointures échouent ou renvoient des résultats incorrects. Les problèmes courants qui compromettent les jointures incluent :
- Incohérences d’orthographe :
KailahunvsKialohun - Différences de casse :
BOvsBo - Espaces supplémentaires ou caractères invisibles :
BovsBoou doubles espaces - Ponctuation ou caractères spéciaux :
Bo.vsBo,Western-AreavsWestern Area - Accents:
BonthévsBonthe,PréfecturevsPrefecture - Abréviations et suffixes :
KonovsKono District,Western UrbanvsWestern Area Urban - Incohérences d’encodage : des noms visuellement identiques ne correspondent pas en raison de l’encodage sous-jacent des caractères, comme
UTF-8,Windows-1252ouISO-8859-1
Même lorsque les noms semblent corrects, des différences invisibles de formatage ou d’encodage peuvent rompre les jointures sans message explicite. Cela produit des zones manquantes sur les cartes, des résumés incomplets ou des sorties mal alignées. Une analyse spatiale fiable dans la SNT exige des noms propres et standardisés ainsi qu’une validation attentive des jointures pour garantir que tous les enregistrements correspondent correctement.
Jointure par coordonnées (jointures basées sur les coordonnées)
Une autre méthode pour relier des données tabulaires aux shapefiles dans la SNT utilise des coordonnées géographiques (des valeurs de latitude et longitude qui indiquent des emplacements précis). Cette jointure fondée sur les coordonnées relie chaque point de données à l’unité administrative dont la limite le contient physiquement. La méthode repose sur la position géographique. Chaque point doit se trouver à l’intérieur du polygone correspondant, comme un district ou un chiefdom, pour que la jointure réussisse. Si le point tombe à l’extérieur, même de peu à cause d’une erreur GPS ou d’une imprécision des limites, la jointure échoue ou classe mal l’emplacement. Des jointures exactes exigent des données de coordonnées bien alignées, des géométries valides et un système de référence de coordonnées (CRS) commun entre les jeux de points et de polygones.
Les jointures fondées sur les coordonnées sont essentielles lorsque l’on travaille avec des données géoréférencées, comme les registres d’établissements de santé, les sites de surveillance environnementale ou les emplacements de grappes d’enquête. Comme elles reposent sur la position spatiale plutôt que sur la correspondance textuelle, elles évitent de nombreux problèmes observés dans les jointures par noms. Les analystes doivent néanmoins assurer la validité spatiale et la cohérence entre les jeux de données.
Quand utiliser les jointures par coordonnées
Utilisez cette méthode lorsque :
- Le jeu de données tabulaire contient des valeurs valides de latitude et longitude
- Vous affectez des données ponctuelles (établissements, grappes d’enquête) à des zones administratives
- Les noms administratifs sont manquants, peu fiables ou formatés de manière incohérente
- Vous travaillez avec des sources spatiales brutes, comme des enquêtes coordonnées par GPS, des shapefiles avec entités ponctuelles ou des registres géolocalisés
Problèmes courants qui bloquent les jointures
Les jointures par coordonnées semblent simples, mais plusieurs problèmes subtils entraînent des échecs inattendus, des correspondances incorrectes ou des points exclus. Comprendre ces difficultés permet d’assurer une liaison spatiale exacte :
Incohérences de CRS (Coordinate Reference Systems) : l’erreur la plus fréquente survient lorsque les données ponctuelles et les shapefiles utilisent des systèmes de référence de coordonnées différents. Si l’un utilise des coordonnées latitude-longitude comme WGS84 (EPSG:4326) et l’autre des coordonnées projetées comme UTM, les jointures spatiales produisent des résultats incorrects ou manquants si les données ne sont pas correctement alignées.
Surveiller les doublons : si plusieurs points se trouvent au même emplacement (établissements superposés), la jointure produit des comptes gonflés. Envisagez une déduplication avant l’agrégation.
Lacunes du shapefile ou géométries invalides : des limites spatiales avec erreurs topologiques (fragments, lacunes ou chevauchements) provoquent des échecs de jointure. Si un point tombe dans l’une de ces erreurs, il ne sera affecté à aucune unité.
Points proches des limites : des points GPS réels se situent parfois près des limites administratives, et de petites différences entre la limite réelle et sa représentation numérique peuvent entraîner des classifications erronées. Cela se produit souvent dans les zones frontalières ou lorsque les polygones ont été simplifiés.
Coordonnées hors limites : certains points tombent entièrement en dehors de l’étendue du shapefile. Cela peut provenir de relevés GPS incorrects ou manquants comme lat=0 et long=0, de valeurs mal formées comme des coordonnées inversées, ou de fichiers de limites incompatibles, obsolètes ou agrégés.
Précision des coordonnées : l’arrondi ou la troncature des valeurs de latitude/longitude affecte le placement des points, surtout près d’unités petites ou de forme irrégulière.
Incohérence de datum : même lorsque les étiquettes CRS correspondent, les datums sous-jacents (WGS84 vs NAD83) peuvent différer légèrement, causant de petits décalages spatiaux qui influencent le polygone contenant un point.
Conseils pour réussir les jointures par coordonnées
Pour assurer des jointures spatiales exactes à partir des coordonnées, suivez ces bonnes pratiques :
Harmoniser le CRS : reprojetez toujours les données ponctuelles et le shapefile dans le même CRS avant d’effectuer la jointure. WGS84 (EPSG:4326) sert de standard pour les coordonnées GPS, mais les systèmes projetés comme UTM offrent une meilleure précision pour les analyses de petites zones.
Inspecter les points non appariés : après la jointure, recherchez les enregistrements qui n’ont correspondu à aucun polygone. Examinez-les individuellement ou visualisez-les sur une carte pour détecter des valeurs aberrantes ou des problèmes systématiques.
Utiliser les tampons avec prudence : si de nombreux points tombent juste à l’extérieur des limites, évaluez si un petit tampon autour des polygones est justifié. Les tampons aident à récupérer les points proches des limites, mais introduisent de l’ambiguïté dans les zones à limites denses.
Valider avec des données connues : lorsque des noms administratifs ou des métadonnées existent, comparez les jointures fondées sur les coordonnées avec les jointures par noms ou des listes de référence. Cela est particulièrement utile pour repérer des désalignements à grande échelle.
Standardiser le format des coordonnées : assurez-vous que toutes les valeurs lat/lon sont numériques, non nulles et exprimées en degrés décimaux avec une précision cohérente. Évitez les formats DMS (degrés-minutes-secondes) ou autres formats non standard.
Vérification visuelle : pour les sorties sensibles, cartographiez les données jointes et vérifiez visuellement que chaque point apparaît dans le bon polygone. C’est particulièrement important lors de la préparation de figures destinées aux décideurs.
Les jointures fondées sur les coordonnées sont des outils puissants dans la boîte à outils SNT. Elles permettent aux analystes de travailler directement avec des données spatiales brutes, de contourner les incohérences de noms et d’obtenir une agrégation géographique exacte. Lorsqu’elles sont appliquées avec soin, elles offrent une méthode fiable pour cartographier, résumer et interpréter des données localisées dans tout le flux de travail SNT.
Les jointures spatiales constituent une étape récurrente et fondamentale du flux de travail SNT. Après l’assemblage et le nettoyage des données, nous relions chaque jeu de données aux bonnes unités géographiques pour la stratification, la visualisation ou la modélisation. Sans jointures réussies, il est impossible de cartographier, d’agréger ou d’interpréter correctement les indicateurs par lieu. Que les données proviennent d’enquêtes, d’établissements de santé ou de systèmes de routine, nous devons d’abord les aligner spatialement avant toute analyse ou production de sortie significative. Cette section établit les bases des processus de jointure spatiale utilisés dans tout le guide.
Étape par étape
Cette section guide les analystes dans la fusion de données tabulaires avec des shapefiles et la production de différents types de cartes. Nous illustrons à la fois les jointures par noms et les jointures par coordonnées à l’aide de centroïdes d’établissements. L’exemple utilise les shapefiles de limites administratives de la Sierra Leone avec des données DHIS2, mais les mêmes principes s’appliquent à n’importe quelles limites spatiales et à tout jeu de données tabulaire. Pour confirmer que les jointures fonctionnent comme prévu, nous visualisons le nombre d’enfants de moins de 5 ans confirmés avec paludisme par adm3.
Étape 1 : Installer et charger les packages
Commencez par installer et charger les packages nécessaires au traitement des données spatiales, à la lecture de différents formats de fichiers, à la manipulation des données et à la visualisation.
Pour adapter le code:
- Ne modifiez rien dans le code ci-dessus
WarningInstallation requise dans le terminal
Installez les packages dans votre terminal s’ils ne sont pas déjà installés. Si vous avez besoin d’aide pour installer les packages, consultez la page Bien démarrer.
from pathlib import Path
import re
import geopandas as gpd
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pyreadr
from matplotlib import colors
from mpl_toolkits.axes_grid1 import make_axes_locatable
from pyprojroot import here
from sntutils.geo import prep_geonames
def read_rds(path):
"""Lire un fichier RDS à objet unique comme objet pandas."""
result = pyreadr.read_r(str(path))
return next(iter(result.values()))
def cli_header(message):
print(f"\n{message}")
def cli_info(message):
print(f"INFO: {message}")
def cli_success(message):
print(f"SUCCESS: {message}")
def cli_warning(message):
print(f"WARNING: {message}")
def anti_join(left, right, on):
"""Renvoyer les lignes de gauche sans clé correspondante à droite."""
right_keys = right[on].drop_duplicates()
return (
left.merge(right_keys, on=on, how="left", indicator=True)
.loc[lambda x: x["_merge"] == "left_only"]
.drop(columns="_merge")
)
def geometry_key(series):
"""Créer des clés WKB stables pour compter les géométries distinctes."""
return series.apply(lambda geom: geom.wkb if geom is not None else None)
def detect_dms_value(value):
"""Détecter les chaînes de coordonnées en degrés-minutes-secondes."""
return bool(re.search(r"[°º].*['′\"″]", str(value)))
def parse_coord(value):
"""Analyser des valeurs latitude/longitude décimales ou DMS en degrés décimaux."""
if pd.isna(value):
return np.nan
text = str(value).strip()
try:
return float(text)
except ValueError:
pass
# extraire d'abord l'indicateur d'hémisphère pour que le `\D*` gourmand
# du regex DMS principal ci-dessous ne l'absorbe pas. sans cela, des
# chaînes comme "11°8'37.08\"W" seraient analysées en +11,14 au lieu de
# -11,14, plaçant le point hors des limites de longitude du pays.
hemi_match = re.search(r"[NSEW]", text, flags=re.IGNORECASE)
hemi = hemi_match.group(0).upper() if hemi_match else ""
match = re.search(
r"(\d+(?:\.\d+)?)\D+(\d+(?:\.\d+)?)?\D*(\d+(?:\.\d+)?)?",
text,
flags=re.IGNORECASE
)
if not match:
return np.nan
deg = float(match.group(1))
minute = float(match.group(2) or 0)
second = float(match.group(3) or 0)
decimal = deg + minute / 60 + second / 3600
return -decimal if hemi in {"S", "W"} else decimal
def plot_validation_maps(data, value_col, method_col, title):
"""Créer des cartes de validation côte à côte avec une échelle de couleurs commune."""
methods = list(data[method_col].dropna().unique())
# protection contre une liste de méthodes vide pour éviter que
# matplotlib ne lève `Number of columns must be a positive integer,
# not 0`. Cela se produit lorsqu'un filtre en amont (par exemple un
# filtre d'année) supprime toutes les lignes.
if len(methods) == 0:
raise ValueError(
f"Aucune valeur trouvée dans `{method_col}` après dropna(); "
"vérifier qu'au moins une ligne survit aux filtres en amont."
)
fig, axes = plt.subplots(1, len(methods), figsize=(10, 6), constrained_layout=True)
if len(methods) == 1:
axes = [axes]
vmin = data[value_col].min(skipna=True) / 1000
vmax = data[value_col].max(skipna=True) / 1000
norm = colors.Normalize(vmin=vmin, vmax=vmax)
cmap = plt.get_cmap("magma_r")
for ax, method in zip(axes, methods):
# fixer l'aspect sur l'axe et désactiver le calcul d'aspect de
# geopandas pour qu'un sous-ensemble dégénéré ne déclenche pas
# `aspect must be finite and positive`
ax.set_aspect("equal")
subset = data.loc[data[method_col] == method].copy()
subset["plot_value"] = subset[value_col] / 1000
subset.plot(
ax=ax,
column="plot_value",
cmap=cmap,
norm=norm,
# matplotlib ne reconnaît pas le « grey20 » de R ; utiliser
# l'équivalent hexadécimal valide pour les deux moteurs
edgecolor="#333333",
linewidth=0.15,
missing_kwds={"color": "lightgrey"},
aspect=None,
)
ax.set_title(method, fontsize=10, fontweight="bold")
ax.set_axis_off()
fig.suptitle(title, fontsize=14)
sm = plt.cm.ScalarMappable(cmap=cmap, norm=norm)
sm.set_array([])
fig.colorbar(
sm,
ax=axes,
orientation="horizontal",
fraction=0.04,
pad=0.05,
label="Cas confirmés (moins de 5 ans, milliers)",
)
return figPour adapter le code:
- Gardez ces imports et fonctions d’aide au début du flux de travail Python. Les chunks Python suivants les utilisent pour les imports RDS, les contrôles de correspondance, l’analyse des coordonnées et les cartes.
ImportantAssurer une liaison réussie des données
Lors de la fusion de données tabulaires avec des shapefiles, la réussite dépend d’une correspondance parfaite des clés de jointure entre les jeux de données. Avant de continuer :
- Identifier les colonnes de jointure : déterminez quelles colonnes contiennent les noms d’unités administratives dans le shapefile et dans les données tabulaires
- Standardiser les noms : nettoyez et standardisez les noms d’unités administratives pour garantir des correspondances exactes
- Vérifier l’exhaustivité : vérifiez que toutes les zones géographiques de l’analyse apparaissent dans les deux jeux de données
- Tester la fusion : examinez toujours le jeu de données fusionné pour confirmer que toutes les zones ont été correctement reliées
Remarque : si une valeur dans l’une ou l’autre colonne ne fusionne pas malgré tous les efforts diagnostiques, consultez l’équipe SNT pour obtenir des conseils.
Étape 2 : Importer et examiner les données
Importez les deux jeux de données et examinez leur structure afin d’identifier les clés de jointure appropriées. Cette étape importante permet de comprendre les données avant de tenter la fusion.
Commencez par importer le shapefile et les données tabulaires pertinentes. Pour plus d’efficacité, cet exemple utilise des données spatiales prétraitées enregistrées sous forme de fichiers RDS. En pratique, on commence généralement avec les composants bruts du shapefile (.shp, .shx, .dbf), comme montré dans les sections précédentes.
Afficher le code
# importer le shapefile
shp_adm3 <- readRDS(
here::here(
"1.1_foundational",
"1.1a_administrative_boundaries",
"processed",
"sle_spatial_adm3_2021.rds"
)
) |>
# garantir que la sortie reste un objet sf valide pour les jointures suivantes
sf::st_as_sf()
# chemin des données de surveillance
surv_path <- here::here("1.2_epidemiology", "1.2a_routine_surveillance")
# obtenir les données sur le paludisme
dhis2_df <- rio::import(
here::here(
surv_path,
"raw",
"clean_malaria_routine_data_final.rds"
)
)
# vérifier les données DHIS2 et le shapefile
cli::cli_h2("Données DHIS2")
dhis2_df |>
dplyr::distinct(adm0, adm1, adm2, adm3) |>
dplyr::arrange(adm0, adm1, adm2, adm3) |>
head(n = 10)
cli::cli_h2("Shapefile Adm3")
shp_adm3 |>
dplyr::distinct(adm0, adm1, adm2, adm3) |>
dplyr::arrange(adm0, adm1, adm2, adm3) |>
head(n = 10)Pour adapter le code:
- Lignes 3 à 8 et 18 à 22 : adaptez les chemins
here::here()à la structure de vos dossiers pour le shapefile et les données tabulaires à fusionner.
Afficher le code
# importer le shapefile
spat_path = here("1.1_foundational/1.1a_administrative_boundaries")
shp_adm3 = (
gpd.read_file(Path(spat_path) / "raw" / "Chiefdom2021.shp")
.assign(adm0="SIERRA LEONE")
.rename(columns={
"FIRST_REGI": "adm1",
"FIRST_DNAM": "adm2",
"FIRST_CHIE": "adm3",
})
[["adm0", "adm1", "adm2", "adm3", "geometry"]]
)
# chemin des données de surveillance
surv_path = here("1.2_epidemiology/1.2a_routine_surveillance")
# obtenir les données sur le paludisme
dhis2_df = read_rds(Path(surv_path) / "raw" / "clean_malaria_routine_data_final.rds")
# vérifier les données DHIS2 et le shapefile
cli_header("Données DHIS2")
dhis2_df[["adm0", "adm1", "adm2", "adm3"]].drop_duplicates().sort_values(
["adm0", "adm1", "adm2", "adm3"]
).head(10)
cli_header("Shapefile Adm3")
shp_adm3[["adm0", "adm1", "adm2", "adm3"]].drop_duplicates().sort_values(
["adm0", "adm1", "adm2", "adm3"]
).head(10)Pour adapter le code:
- Lignes 3 à 13 et 24 à 26 : adaptez les chemins
here()à la structure de vos dossiers pour le shapefile et les données tabulaires à fusionner.
En examinant l’extrait DHIS2 complet, le principal problème se situe au niveau adm1. Dans DHIS2, adm1 n’est pas la région comme dans le shapefile. Il répète plutôt le nom du district, tandis que adm2 porte la structure de conseil, comme District Council, City Council ou Municipal Council. À l’inverse, le shapefile suit une hiérarchie géographique : adm1 = région, adm2 = district, adm3 = chiefdom. Cette incohérence signifie que les données DHIS2 ne contiennent pas de niveau régional approprié, et que leurs noms sont programmatiques plutôt que purement géographiques.
Étape 3 : Identifier et corriger les incohérences de hiérarchie
La correction consiste à nettoyer et standardiser les noms en les convertissant en majuscules et en supprimant les suffixes comme District et Chiefdom. Une fois les noms harmonisés, le niveau régional peut être reconstruit en regroupant les districts dans leurs catégories supérieures correctes.
Remarque : l’incohérence de hiérarchie illustrée ici (adm1 qui répète les noms de districts) est propre aux données DHIS2 de la Sierra Leone. D’autres pays peuvent avoir des structures hiérarchiques différentes; examinez toujours la structure de vos propres données avant d’appliquer ces transformations.
Afficher le code
# nettoyage initial
dhis2_df <- dhis2_df |>
dplyr::mutate(
adm0 = toupper(adm0),
adm2 = toupper(adm1),
adm3 = toupper(adm3),
adm2 = stringr::str_replace(
adm2,
stringr::fixed(" DISTRICT"),
""
),
adm3 = stringr::str_replace(
adm3,
stringr::fixed(" CHIEFDOM"),
""
)
) |>
dplyr::mutate(
adm1 = dplyr::case_when(
adm2 %in% c("KAILAHUN", "KENEMA", "KONO") ~
"EASTERN",
adm2 %in% c("BOMBALI", "FALABA", "KOINADUGU", "TONKOLILI") ~
"NORTH EAST",
adm2 %in% c("KAMBIA", "KARENE", "PORT LOKO") ~
"NORTH WEST",
adm2 %in% c("BO", "BONTHE", "MOYAMBA", "PUJEHUN") ~
"SOUTHERN",
adm2 %in% c("WESTERN AREA RURAL", "WESTERN AREA URBAN") ~
"WESTERN"
)
)
# vérifier les données DHIS2 et le shapefile
cli::cli_h2("Données DHIS2 (nettoyage initial) ")
dhis2_df |>
dplyr::distinct(adm0, adm1, adm2, adm3) |>
dplyr::arrange(adm0, adm1, adm2, adm3) |>
head(n = 10)
cli::cli_h2("Shapefile Adm3")
shp_adm3 |>
dplyr::distinct(adm0, adm1, adm2, adm3) |>
dplyr::arrange(adm0, adm1, adm2, adm3) |>
head(n = 10)Pour adapter le code:
- Ligne 2 : assurez-vous que le dataframe d’entrée contient les colonnes requises (
adm0,adm1,adm3) avant d’appliquer la transformation. Sinon, ajustez les noms de colonnes en conséquence. - Lignes 4 à 16 : adaptez les règles
toupper()etstr_replace()si votre extrait DHIS2 utilise d’autres suffixes ou une autre capitalisation. Par exemple, d’autres pays peuvent utiliserMUNICIPALITYau lieu deDISTRICTouCHIEFDOM. - Lignes 19 à 30 : adaptez la correspondance
case_when()pour refléter la structure régionale de votre pays. La correspondance affichée est propre à la Sierra Leone et ne se généralise pas ailleurs. Remplacez-la par les regroupements district-région corrects pour votre contexte.
Afficher le code
region_lookup = {
"KAILAHUN": "EASTERN",
"KENEMA": "EASTERN",
"KONO": "EASTERN",
"BOMBALI": "NORTH EAST",
"FALABA": "NORTH EAST",
"KOINADUGU": "NORTH EAST",
"TONKOLILI": "NORTH EAST",
"KAMBIA": "NORTH WEST",
"KARENE": "NORTH WEST",
"PORT LOKO": "NORTH WEST",
"BO": "SOUTHERN",
"BONTHE": "SOUTHERN",
"MOYAMBA": "SOUTHERN",
"PUJEHUN": "SOUTHERN",
"WESTERN AREA RURAL": "WESTERN",
"WESTERN AREA URBAN": "WESTERN",
}
# nettoyage initial
dhis2_df = dhis2_df.copy()
dhis2_df["adm0"] = dhis2_df["adm0"].str.upper()
dhis2_df["adm2"] = dhis2_df["adm1"].str.upper().str.replace(" DISTRICT", "", regex=False)
dhis2_df["adm3"] = dhis2_df["adm3"].str.upper().str.replace(" CHIEFDOM", "", regex=False)
dhis2_df["adm1"] = dhis2_df["adm2"].map(region_lookup)
# vérifier les données DHIS2 et le shapefile
cli_header("Données DHIS2 (nettoyage initial)")
dhis2_df[["adm0", "adm1", "adm2", "adm3"]].drop_duplicates().sort_values(
["adm0", "adm1", "adm2", "adm3"]
).head(10)
cli_header("Shapefile Adm3")
shp_adm3[["adm0", "adm1", "adm2", "adm3"]].drop_duplicates().sort_values(
["adm0", "adm1", "adm2", "adm3"]
).head(10)Pour adapter le code:
- Ligne 25 : assurez-vous que le dataframe d’entrée contient les colonnes requises (
adm0,adm1,adm3) avant d’appliquer la transformation. Sinon, ajustez les noms de colonnes en conséquence. - Lignes 26 à 28 : adaptez les règles
.str.upper()et.str.replace()si votre extrait DHIS2 utilise d’autres suffixes ou une autre capitalisation. - Lignes 8 à 23 : adaptez la correspondance
region_lookuppour refléter la structure régionale de votre pays. La correspondance affichée est propre à la Sierra Leone et ne se généralise pas ailleurs.
Étape 4 : Joindre par noms administratifs (jointures attributaires)
Étape 4.1 : Évaluer si les deux jeux de données peuvent être joints
Les sorties de l’étape 3 montrent maintenant que les noms administratifs (adm0, adm1, adm2 et adm3) des deux jeux de données suivent un format cohérent : majuscules et organisation dans la même hiérarchie. Avec les régions au niveau supérieur, les districts au niveau intermédiaire et les chiefdoms au troisième niveau, les deux jeux de données sont désormais alignés. Cet alignement permet de tenter une jointure interne sur ces champs pour fusionner le shapefile avec le jeu de données DHIS2.
Afficher le code
# obtenir les noms administratifs distincts de DHIS2
dhis2_admins <-
dhis2_df |>
dplyr::distinct(adm0, adm1, adm2, adm3)
# supprimer la géométrie pour les jointures par noms seulement
shp_names <-
shp_adm3 |>
sf::st_drop_geometry() |>
dplyr::distinct(adm0, adm1, adm2, adm3)
# jointure interne pour compter les correspondances (polygones ∩ dhis2)
shp_with_dhis2 <-
shp_names |>
dplyr::inner_join(
dhis2_admins,
by = c("adm0", "adm1", "adm2", "adm3")
)
# polygones sans admin DHIS2 correspondante (shapefile ▷ dhis2)
polygons_without_dhis2 <-
shp_names |>
dplyr::anti_join(
dhis2_admins,
by = c("adm0", "adm1", "adm2", "adm3")
)
# admins DHIS2 sans polygone correspondant (dhis2 ▷ shapefile)
dhis2_without_polygons <-
dhis2_admins |>
dplyr::anti_join(
shp_names,
by = c("adm0", "adm1", "adm2", "adm3")
)
# comptes pour des diagnostics clairs
total_polygons <- nrow(shp_adm3)
matched_polygons <- nrow(shp_with_dhis2)
polygons_no_match <- nrow(polygons_without_dhis2)
dhis2_no_match <- nrow(dhis2_without_polygons)
# rapport
cli::cli_h2("Diagnostics de jointure admin (adm0 à adm3)")
# perspective des polygones
cli::cli_alert_success(
"Unités administratives du shapefile (uniques) : {total_polygons}"
)
cli::cli_alert_success(
"Correspondant avec DHIS2 : {matched_polygons}"
)
# perspective DHIS2
cli::cli_alert_warning(
"Unités administratives DHIS2 non appariées (aucun polygone) : {dhis2_no_match}"
)
cli::cli_alert_warning(
"Unités administratives du shapefile non appariées (aucune entrée DHIS2) : {polygons_no_match}"
)
# aperçus
if (nrow(dhis2_without_polygons) > 0) {
cli::cli_h2("Admins DHIS2 sans polygone correspondant (exemple)")
dhis2_without_polygons |> head(10)
}
if (nrow(polygons_without_dhis2) > 0) {
cli::cli_h2("Polygones sans correspondance DHIS2 (exemple)")
polygons_without_dhis2 |> head(10)
}Pour adapter le code:
- Lignes 4, 10, 17, 25 et 33 : remplacez les clés de jointure (
adm0,adm1,adm2,adm3) par les noms de colonnes réellement utilisés dans votre shapefile et votre jeu de données DHIS2. - Lignes 4, 10, 17, 25 et 33 : si vous utilisez moins de niveaux administratifs (seulement
adm1etadm2), mettez à jour toutes les lignes de jointure et de comparaison pour refléter uniquement ces niveaux.
Afficher le code
join_keys = ["adm0", "adm1", "adm2", "adm3"]
# obtenir les noms administratifs distincts de DHIS2
dhis2_admins = dhis2_df[join_keys].drop_duplicates()
# supprimer la géométrie pour les jointures par noms seulement
shp_names = shp_adm3.drop(columns="geometry")[join_keys].drop_duplicates()
# jointure interne pour compter les correspondances
shp_with_dhis2 = shp_names.merge(dhis2_admins, on=join_keys, how="inner")
# polygones sans admin DHIS2 correspondante
polygons_without_dhis2 = anti_join(shp_names, dhis2_admins, on=join_keys)
# admins DHIS2 sans polygone correspondant
dhis2_without_polygons = anti_join(dhis2_admins, shp_names, on=join_keys)
# comptes pour des diagnostics clairs
total_polygons = len(shp_adm3)
matched_polygons = len(shp_with_dhis2)
polygons_no_match = len(polygons_without_dhis2)
dhis2_no_match = len(dhis2_without_polygons)
# rapport
cli_header("Diagnostics de jointure admin (adm0 à adm3)")
cli_success(f"Unités administratives du shapefile (uniques) : {total_polygons}")
cli_success(f"Correspondant avec DHIS2 : {matched_polygons}")
cli_warning(f"Unités administratives DHIS2 non appariées (aucun polygone) : {dhis2_no_match}")
cli_warning(f"Unités administratives du shapefile non appariées (aucune entrée DHIS2) : {polygons_no_match}")
# aperçus
if len(dhis2_without_polygons) > 0:
cli_header("Admins DHIS2 sans polygone correspondant (exemple)")
print(dhis2_without_polygons.head(10))
if len(polygons_without_dhis2) > 0:
cli_header("Polygones sans correspondance DHIS2 (exemple)")
print(polygons_without_dhis2.head(10))Pour adapter le code:
- Ligne 1 : remplacez les clés de jointure (
adm0,adm1,adm2,adm3) par les noms de colonnes réellement utilisés dans votre shapefile et votre jeu de données DHIS2. - Si vous utilisez moins de niveaux administratifs, mettez à jour
join_keysune seule fois et réutilisez-le dans toutes les lignes de comparaison.
Sur 208 unités administratives uniques dans les données DHIS2, 135 ont été appariées avec succès, laissant 73 unités non appariées. La plupart des incohérences proviennent de petites différences d’espacement, d’orthographe ou de formatage entre les différents niveaux administratifs.
Pour obtenir une correspondance complète, les 61 unités DHIS2 restantes non appariées doivent être nettoyées et alignées sur les conventions de nommage du shapefile.
Étape 4.2 : Résoudre les incohérences avec sntutils::prep_geonames()
Lorsque l’on travaille avec des données DHIS2 et des shapefiles administratifs, les noms ne s’alignent souvent pas parfaitement. De petites différences, comme les accents, les espaces supplémentaires ou les variantes orthographiques, peuvent bloquer les jointures et produire des enregistrements non appariés. La résolution de ces incohérences est essentielle pour une agrégation et une analyse spatiale fiables.
TipDeux approches pour harmoniser les noms
Les incohérences de noms administratifs peuvent être résolues à l’aide de deux approches complémentaires :
Appariement approximatif (non interactif) Attribue automatiquement les correspondances les plus proches à partir de scores de similarité de chaînes. Le prétraitement supprime les parenthèses, normalise la casse et la ponctuation, et gère les accents. Voir la section Correspondance approximative des noms entre jeux de données pour plus de détails.
Harmonisation interactive (
prep_geonames()) Utilise les mêmes étapes de prétraitement, puis suggère des correspondances probables à confirmer par l’utilisateur. Les décisions sont stockées et réutilisées lors des exécutions futures.
Astuce : pour les jeux de données complexes, appliquez d’abord l’appariement approximatif afin de résoudre la plupart des incohérences, puis utilisez l’harmonisation interactive pour les cas restants.
sntutils::prep_geonames() harmonise la hiérarchie administrative d’un jeu de données cible (par exemple DHIS2) avec un jeu de données de référence (par exemple un shapefile). La fonction travaille de manière hiérarchique :
- Commencer par
adm0(pays). - Passer ensuite par
adm1,adm2etadm3. - À chaque niveau, vérifier si les valeurs cibles existent dans la référence. Sinon, appliquer :
- la mise en majuscules et le retrait des espaces superflus
- la suppression des accents et de la ponctuation
- l’appariement par distance de chaînes (Levenshtein, Jaro-Winkler, etc.) pour suggérer les meilleures correspondances
Les unités non appariées sont renvoyées avec des suggestions classées par score de similarité. Le processus tient compte du contexte : les noms ne sont comparés qu’au sein de leur unité parente (par exemple, adm2 est comparé uniquement dans le même adm1). Cela réduit les faux positifs et maintient la cohérence géographique des correspondances.
Les corrections peuvent être appliquées de manière interactive ou scriptée. Pour fluidifier les flux de travail, utilisez l’argument cache_path pour enregistrer les décisions. Les corrections en cache sont automatiquement réutilisées sur les jeux de données mis à jour, ce qui garantit la cohérence entre les réexécutions et les membres de l’équipe.
La courte vidéo ci-dessous montre l’interface interactive de sntutils::prep_geonames() :
Étape 4.3 : Vérifier la jointure finale avec le shapefile
Une fois tous les noms non appariés résolus avec prep_geonames(), les données DHIS2 sont maintenant alignées sur la structure du shapefile. Les corrections sont enregistrées dans le cache pour une réutilisation cohérente.
Vérifions maintenant que les données DHIS2 nettoyées correspondent entièrement au shapefile, en nous assurant qu’aucune unité non appariée ne subsiste.
Afficher le code
# obtenir les noms administratifs distincts de dhis2
dhis2_admins <-
dhis2_df_cleaned |>
dplyr::distinct(adm0, adm1, adm2, adm3)
# drop geometry for name-only joins
shp_names <-
shp_adm3 |>
sf::st_drop_geometry() |>
dplyr::distinct(adm0, adm1, adm2, adm3)
# jointure interne pour compter les correspondances (polygones ∩ dhis2)
shp_with_dhis2 <-
shp_names |>
dplyr::inner_join(
dhis2_admins,
by = c("adm0", "adm1", "adm2", "adm3")
)
# polygones sans admin DHIS2 correspondante (shapefile ▷ dhis2)
polygons_without_dhis2 <-
shp_names |>
dplyr::anti_join(
dhis2_admins,
by = c("adm0", "adm1", "adm2", "adm3")
)
# admins DHIS2 sans polygone correspondant (dhis2 ▷ shapefile)
dhis2_without_polygons <-
dhis2_admins |>
dplyr::anti_join(
shp_names,
by = c("adm0", "adm1", "adm2", "adm3")
)
# comptes pour des diagnostics clairs
total_polygons <- nrow(shp_adm3)
matched_polygons <- nrow(shp_with_dhis2)
polygons_no_match <- nrow(polygons_without_dhis2)
dhis2_no_match <- nrow(dhis2_without_polygons)
# rapport
cli::cli_h2("Diagnostics de jointure admin (adm0 à adm3)")
# perspective des polygones
cli::cli_alert_success(
"Unités administratives du shapefile (uniques) : {total_polygons}"
)
cli::cli_alert_success(
"Correspondant avec DHIS2 : {matched_polygons}"
)
# perspective DHIS2
cli::cli_alert_warning(
"Unités administratives DHIS2 non appariées (aucun polygone) : {dhis2_no_match}"
)
cli::cli_alert_warning(
"Unités administratives du shapefile non appariées (aucune entrée DHIS2) : {polygons_no_match}"
)
# aperçus
if (nrow(dhis2_without_polygons) > 0) {
cli::cli_h2("Admins DHIS2 sans polygone correspondant (exemple)")
dhis2_without_polygons |> head(10)
}
if (nrow(polygons_without_dhis2) > 0) {
cli::cli_h2("Polygones sans correspondance DHIS2 (exemple)")
polygons_without_dhis2 |> head(10)
}Pour adapter le code:
- Lignes 4, 10, 17, 25 et 33 : remplacez les clés de jointure (
adm0,adm1,adm2,adm3) par les noms de colonnes réellement utilisés dans le shapefile et le jeu de données DHIS2. - Lignes 4, 10, 17, 25 et 33 : si vous utilisez moins de niveaux administratifs (par exemple, seulement
adm1etadm2), mettez à jour toutes les lignes de jointure et de comparaison pour refléter uniquement ces niveaux.
Afficher le code
join_keys = ["adm0", "adm1", "adm2", "adm3"]
# obtenir les noms administratifs distincts de dhis2 nettoyées
dhis2_admins = dhis2_df_cleaned[join_keys].drop_duplicates()
# supprimer la géométrie pour les jointures par noms seulement
shp_names = shp_adm3.drop(columns="geometry")[join_keys].drop_duplicates()
# jointure interne pour compter les correspondances
shp_with_dhis2 = shp_names.merge(dhis2_admins, on=join_keys, how="inner")
# polygones sans admin DHIS2 correspondante
polygons_without_dhis2 = anti_join(shp_names, dhis2_admins, on=join_keys)
# admins DHIS2 sans polygone correspondant
dhis2_without_polygons = anti_join(dhis2_admins, shp_names, on=join_keys)
total_polygons = len(shp_adm3)
matched_polygons = len(shp_with_dhis2)
polygons_no_match = len(polygons_without_dhis2)
dhis2_no_match = len(dhis2_without_polygons)
cli_header("Diagnostics de jointure admin (adm0 à adm3)")
cli_success(f"Unités administratives du shapefile (uniques) : {total_polygons}")
cli_success(f"Correspondant avec DHIS2 : {matched_polygons}")
cli_warning(f"Unités administratives DHIS2 non appariées (aucun polygone) : {dhis2_no_match}")
cli_warning(f"Unités administratives du shapefile non appariées (aucune entrée DHIS2) : {polygons_no_match}")
if len(dhis2_without_polygons) > 0:
cli_header("Exemple d'unités administratives DHIS2 non appariées (10 premières)")
print(dhis2_without_polygons.head(10))
if len(polygons_without_dhis2) > 0:
cli_header("Exemple d'unités administratives du shapefile non appariées (10 premières)")
print(polygons_without_dhis2.head(10))Pour adapter le code:
- Ligne 1 : remplacez les clés de jointure (
adm0,adm1,adm2,adm3) par les noms de colonnes réellement utilisés dans le shapefile et le jeu de données DHIS2. - Si vous utilisez moins de niveaux administratifs, mettez à jour
join_keysune seule fois et réutilisez-le dans toutes les lignes de jointure et de comparaison.
Nous avons maintenant une correspondance complète des noms, et le jeu de données DHIS2 a été entièrement fusionné avec le shapefile, avec 208 unités adm3 dans les données DHIS2 appariées à leurs formes respectives. Cela garantit que toutes les analyses spatiales ultérieures seront alignées sur des limites administratives validées.
Étape 4.5 : Effectuer la jointure basée sur les noms
Maintenant que nous avons vérifié que tous les noms correspondent, effectuons la jointure réelle entre le shapefile et les données DHIS2 nettoyées :
Afficher le code
# joindre les données DHIS2 nettoyées au shapefile par noms administratifs
dhis2_df_coord_shp <- shp_adm3 |>
dplyr::left_join(
dhis2_df_cleaned,
by = c("adm0", "adm1", "adm2", "adm3")
)
# obtenir le nombre distinct de formes jointes aux données dhis2
dist_shapes <- dplyr::n_distinct(dhis2_df_coord_shp$geometry)
# vérifier le résultat
cli::cli_h2("Résultat de jointure basée sur les noms")
cli::cli_alert_success(
"{dist_shapes} polygones joints avec succès aux données DHIS2"
)Pour adapter le code:
- Ligne 4 : remplacez les clés de jointure (
adm0,adm1,adm2,adm3) par les noms de colonnes réellement utilisés dans votre shapefile et votre jeu de données.
Afficher le code
join_keys = ["adm0", "adm1", "adm2", "adm3"]
# joindre les données DHIS2 nettoyées au shapefile par noms administratifs
dhis2_df_coord_shp = shp_adm3.merge(
dhis2_df_cleaned,
on=join_keys,
how="left"
)
# obtenir le nombre distinct de formes jointes aux données dhis2
dist_shapes = geometry_key(dhis2_df_coord_shp.geometry).nunique()
# vérifier le résultat
cli_header("Résultat de jointure basée sur les noms")
cli_success(f"{dist_shapes} polygones joints avec succès aux données DHIS2")Pour adapter le code:
- Ligne 1 : remplacez les clés de jointure (
adm0,adm1,adm2,adm3) par les noms de colonnes réellement utilisés dans votre shapefile et votre jeu de données.
Étape 5 : Joindre par coordonnées (jointures basées sur les coordonnées)
Nous passons maintenant de l’appariement basé sur les noms aux jointures basées sur les coordonnées. Lorsque les noms administratifs sont manquants ou peu fiables, les coordonnées géographiques fournissent une alternative robuste (si elles sont disponibles). Le jeu de données DHIS2 inclut la latitude et la longitude des établissements de santé, ce qui nous permet d’affecter spatialement les enregistrements aux unités administratives du shapefile. Nous calculons ensuite le centroïde des établissements dans chaque adm3 pour visualiser ultérieurement le nombre d’enfants de moins de 5 ans confirmés avec paludisme par adm3.
Étape 5.1 : Valider et examiner les coordonnées
Avant de procéder à la jointure, nous devons confirmer que les centroïdes au sein des limites adm3 sont valides, correctement formatés et se situent à l’intérieur de la zone d’étude. Les vérifications incluent :
WarningVérifications des coordonnées
- Vérifier que les colonnes de latitude et longitude existent et ne contiennent aucune valeur manquante ou nulle.
- Confirmer que les valeurs sont en degrés décimaux, et non en degrés-minutes-secondes ou autres formats.
- Vérifier que les longitudes se situent dans la plage correcte (par exemple, -13 à -10 pour la Sierra Leone).
- Détecter et corriger les coordonnées inversées (par exemple, lat/lon accidentellement inversées).
- Tracer pour inspecter visuellement si les points centroïdes se situent à l’intérieur de la limite du pays.
Vérifier les coordonnées manquantes
Commençons par vérifier la présence de valeurs de latitude ou longitude manquantes dans le jeu de données. Celles-ci doivent être traitées avant de poursuivre avec les jointures basées sur les coordonnées.
Pour adapter le code:
- Lines 2 and 3: Replace
dhis2_dfwith your dataset name, and updatelatandlonif your coordinate columns have different names.
Afficher le code
Pour adapter le code:
- Lines 2 and 3: Replace
dhis2_dfwith your dataset name, and updatelatandlonif your coordinate columns have different names.
Il semble qu’il n’y ait pas de coordonnées manquantes. Toutefois, si certains enregistrements manquent de coordonnées, nous pouvons les signaler pour examen et inspection manuelle.
Vérifier si les coordonnées sont en degrés décimaux
La plupart des jointures spatiales exigent des coordonnées en degrés décimaux tels que 7,7675. Mais certains enregistrements peuvent utiliser le format degrés-minutes-secondes tel que 7°46′3,93″N, ce qui causera des erreurs.
Avant de poursuivre, nous vérifions la présence de motifs DMS à l’aide d’une fonction de détection simple.
Afficher le code
# function to detect DMS format using common symbols for
# degrees, minutes, or seconds
detect_dms <- function(x) {
grepl("[°º].*['′\"″]", x)
}
# filter rows where lat or lon appears to be in DMS format
dms_detected <- dhis2_df |>
dplyr::filter(detect_dms(lat) | detect_dms(lon)) |>
dplyr::distinct(adm1, adm2, adm3, lat, lon)
# print summary
cli::cli_h2("DMS Coordinate Check")
cli::cli_alert_info(
"Number of rows with suspected DMS format: {nrow(dms_detected)}"
)
cat("\n")
dms_detectedPour adapter le code:
- Ligne 7 : remplacez
dhis2_dfpar le nom de votre jeu de données. - Lignes 8 et 9 : mettez à jour
latetlonsi vos colonnes de coordonnées portent des noms différents. - Ligne 9 : ajustez
adm1,adm2,adm3pour qu’ils correspondent à vos colonnes d’identifiant pertinentes pour le contexte.
Afficher le code
# filtrer les lignes où lat ou lon semble être au format DMS
dms_detected = (
dhis2_df.loc[
dhis2_df["lat"].apply(detect_dms_value)
| dhis2_df["lon"].apply(detect_dms_value),
["adm1", "adm2", "adm3", "lat", "lon"]
]
.drop_duplicates()
)
cli_header("Vérification des coordonnées DMS")
cli_info(f"Nombre de lignes avec format DMS suspecté : {len(dms_detected)}")
print(dms_detected)Pour adapter le code:
- Ligne 3 : remplacez
dhis2_dfpar le nom de votre jeu de données. - Lignes 4 et 5 : mettez à jour
latetlonsi vos colonnes de coordonnées portent des noms différents. - Ligne 6 : ajustez
adm1,adm2,adm3pour qu’ils correspondent à vos colonnes d’identifiant pertinentes pour le contexte.
Seulement 3 lignes ont été signalées comme utilisant le formatage DMS. Ces entrées incluent des unités de KONO, PUJEHUN et TONKOLILI, ce qui suggère que la majorité du jeu de données utilise déjà des degrés décimaux. Les enregistrements signalés seront convertis au format décimal à l’étape suivante.
Afficher le code
# check if DMS values were successfully converted
check_output <- dhis2_df |>
dplyr::filter(detect_dms(lat) | detect_dms(lon)) |>
dplyr::distinct(adm1, adm2, adm3, lat, lon) |>
dplyr::mutate(
lat_fixed = parzer::parse_lat(lat),
lon_fixed = parzer::parse_lon(lon)
)
# apply conversion to full dataset
dhis2_df_clean <- dhis2_df |>
dplyr::mutate(
lat = parzer::parse_lat(lat),
lon = parzer::parse_lon(lon)
)
# print summary of conversion
cli::cli_h2("DMS Coordinate Conversion Summary")
check_outputPour adapter le code:
- Lignes 2 et 11 : remplacez
dhis2_dfpar le nom de votre jeu de données. - Lignes 2 à 7 et 12 à 14 : mettez à jour
latetlonsi vos colonnes de coordonnées portent des noms différents.
Afficher le code
# vérifier si les valeurs DMS ont été converties avec succès
check_output = (
dhis2_df.loc[
dhis2_df["lat"].apply(detect_dms_value)
| dhis2_df["lon"].apply(detect_dms_value),
["adm1", "adm2", "adm3", "lat", "lon"]
]
.drop_duplicates()
.assign(
lat_fixed=lambda x: x["lat"].apply(parse_coord),
lon_fixed=lambda x: x["lon"].apply(parse_coord),
)
)
# appliquer la conversion au jeu de données complet
dhis2_df_clean = dhis2_df.copy()
dhis2_df_clean["lat"] = dhis2_df_clean["lat"].apply(parse_coord)
dhis2_df_clean["lon"] = dhis2_df_clean["lon"].apply(parse_coord)
cli_header("Résumé de la conversion des coordonnées DMS")
check_outputPour adapter le code:
- Lignes 2 et 17 : remplacez
dhis2_dfpar le nom de votre jeu de données. - Lignes 4 à 5 et 18 à 19 : mettez à jour
latetlonsi vos colonnes de coordonnées portent des noms différents.
Les colonnes lat_fixed et lon_fixed confirment que nos coordonnées au format DMS ont été analysées avec précision en degrés décimaux. Ces valeurs nettoyées sont maintenant stockées dans dhis2_df_clean.
Vérifier si les coordonnées sont inversées
Parfois, les valeurs de latitude et de longitude sont accidentellement échangées. Par exemple, une latitude de -12,345 et une longitude de 8,765 alors que cela devrait être inversé. Cela peut placer des points dans le mauvais hémisphère ou complètement en dehors du pays d’intérêt. Dans cette sous-section, nous effectuons une vérification de base pour signaler les coordonnées potentiellement inversées.
TipComment nous détectons les coordonnées inversées
Lorsque des jeux de données contiennent des coordonnées géographiques, une erreur courante consiste à échanger accidentellement les valeurs de latitude et de longitude. Cela peut faire apparaître des points dans le mauvais pays ou même sur le mauvais continent.
Pour détecter les coordonnées possiblement inversées, nous utilisons une approche par boîte englobante :
- Extraire la boîte englobante géographique du shapefile, qui fournit la plage valide de latitudes et longitudes pour le pays.
- Pour chaque ligne du jeu de données :
- Vérifier si la latitude se situe dans la plage de longitude de la boîte englobante.
- Vérifier si la longitude se situe dans la plage de latitude.
- Si les deux conditions sont remplies, cela suggère que les valeurs peuvent avoir été inversées.
Cette méthode utilise des limites spatiales plutôt que des statistiques récapitulatives, ce qui la rend plus robuste dans les pays avec de grandes étendues géographiques (par exemple, Nigeria, RDC).
Afficher le code
# get bounding box from the shapefile
bbox <- sf::st_bbox(shp_adm3)
# create `possibly_flipped` column in the main dataset
dhis2_df_flagged <- dhis2_df_clean |>
dplyr::mutate(
out_of_bounds = lat < bbox[['ymin']] |
lat > bbox[['ymax']] |
lon < bbox[['xmin']] |
lon > bbox[['xmax']],
looks_flipped = lat > bbox[['xmin']] &
# lat in lon range
lat < bbox[['xmax']] &
lon > bbox[['ymin']] &
# lon in lat range
lon < bbox[['ymax']],
possibly_flipped = looks_flipped
)
# quick summary output
cli::cli_h2("Bounding Box Coordinate Check")
cli::cli_alert_info(
"Out-of-bounds rows: {sum(dhis2_df_flagged$out_of_bounds)}"
)
cli::cli_alert_info(
"Possible flipped rows: {sum(dhis2_df_flagged$possibly_flipped)}"
)
# check output
dhis2_df_flagged |>
dplyr::filter(possibly_flipped) |>
dplyr::select(adm0, adm1, adm2, adm3, lon, lat)Pour adapter le code:
- Lines 2 and 5: Replace
dhis2_df_cleanwith your dataset name andshp_adm3with your shapefile name if different. - Lines 6–13: Update
latandlonif your coordinate columns have different names. - Line 32: Adjust
adm0,adm1,adm2,adm3to match your relevant identifier columns for context. - It works well when latitudes and longitudes fall in clearly separated ranges (e.g., lat ~8, lon ~–11 in Sierra Leone).
- ⚠️ In countries like Nigeria, where both lat and lon values can fall in similar ranges (e.g., 11°N, 11°E), this check may produce false positives. Use with caution and review flagged rows manually.
Afficher le code
# get bounding box from the shapefile
xmin, ymin, xmax, ymax = shp_adm3.total_bounds
# create flags in the main dataset
dhis2_df_flagged = dhis2_df_clean.copy()
dhis2_df_flagged["out_of_bounds"] = (
(dhis2_df_flagged["lat"] < ymin)
| (dhis2_df_flagged["lat"] > ymax)
| (dhis2_df_flagged["lon"] < xmin)
| (dhis2_df_flagged["lon"] > xmax)
)
dhis2_df_flagged["possibly_flipped"] = (
(dhis2_df_flagged["lat"] > xmin)
& (dhis2_df_flagged["lat"] < xmax)
& (dhis2_df_flagged["lon"] > ymin)
& (dhis2_df_flagged["lon"] < ymax)
)
cli_header("Vérification des coordonnées de boîte englobante")
cli_info(f"Lignes hors limites : {dhis2_df_flagged['out_of_bounds'].sum()}")
cli_info(f"Lignes possiblement inversées : {dhis2_df_flagged['possibly_flipped'].sum()}")
dhis2_df_flagged.loc[
dhis2_df_flagged["possibly_flipped"],
["adm0", "adm1", "adm2", "adm3", "lon", "lat"]
]Pour adapter le code:
- Lines 2 and 5: Replace
dhis2_df_cleanwith your dataset name andshp_adm3with your shapefile name if different. - Lines 6–13: Update
latandlonif your coordinate columns have different names. - Line 25: Adjust
adm0,adm1,adm2,adm3to match your relevant identifier columns for context. - This check works best when latitude and longitude ranges are clearly separated. Review flagged rows manually in countries where ranges overlap.
These results include three rows with coordinates that either fall outside the expected bounding box or appear to be flipped (For example, cases where latitude is negative or outside the plausible range). Since Sierra Leone has negative longitudes but not latitudes, such records should be flagged for review or corrected manually based on contextual program knowledge.
Now we will convert this cleaned dataset into an sf object and begin spatially joining each row to its corresponding administrative unit based on location.
Afficher le code
# reverse flipped coordinates
dhis2_df_corrected <- dhis2_df_flagged |>
dplyr::mutate(
lat_temp = dplyr::if_else(possibly_flipped, lon, lat),
lon_temp = dplyr::if_else(possibly_flipped, lat, lon),
lat = lat_temp,
lon = lon_temp
) |>
dplyr::select(-lat_temp, -lon_temp)
# check output
dhis2_df_corrected |>
dplyr::filter(possibly_flipped) |>
dplyr::select(adm0, adm1, adm2, adm3, lon, lat)Pour adapter le code:
- Lines 2 and 3–7: Update variable names if your dataset or coordinate columns have different names.
- Line 14: Adjust
adm0,adm1,adm2,adm3to match your relevant identifier columns for context.
Afficher le code
# reverse flipped coordinates
dhis2_df_corrected = dhis2_df_flagged.copy()
lat_temp = np.where(
dhis2_df_corrected["possibly_flipped"],
dhis2_df_corrected["lon"],
dhis2_df_corrected["lat"],
)
lon_temp = np.where(
dhis2_df_corrected["possibly_flipped"],
dhis2_df_corrected["lat"],
dhis2_df_corrected["lon"],
)
dhis2_df_corrected["lat"] = lat_temp
dhis2_df_corrected["lon"] = lon_temp
dhis2_df_corrected.loc[
dhis2_df_corrected["possibly_flipped"],
["adm0", "adm1", "adm2", "adm3", "lon", "lat"]
]Pour adapter le code:
- Lines 2 and 3–15: Update variable names if your dataset or coordinate columns have different names.
- Line 19: Adjust
adm0,adm1,adm2,adm3to match your relevant identifier columns for context.
Étape 5.2 : Vérifier et aligner le système de référence de coordonnées (CRS)
Before performing any spatial join, it’s essential to ensure that the DHIS2 data and the shapefile use the same coordinate reference system. Most shapefiles are in geographic coordinates using EPSG:4326, but your DHIS2 data may not be explicitly tagged.
We’ll check the CRS of both datasets and, if needed, set or transform the CRS of the DHIS2 data to match the shapefile.
Afficher le code
# check CRS of shapefile
shp_crs <- sf::st_crs(shp_adm3)
# convert DHIS2 data to an sf object
dhis2_df_sf <- dhis2_df_corrected |>
# only keep rows with valid coordinates
dplyr::filter(!is.na(lat), !is.na(lon)) |>
# assume input is EPSG:4326
sf::st_as_sf(coords = c("lon", "lat"), crs = 4326)
# reproject if CRS mismatch
if (sf::st_crs(dhis2_df_sf) != shp_crs) {
dhis2_df_sf <- sf::st_transform(dhis2_df_sf, shp_crs)
}
# summary
cli::cli_h2("CRS Alignment Summary")
cli::cli_alert_info("Shapefile CRS: {.strong {shp_crs$input}}")
cli::cli_alert_info(
"Intervention data CRS: {.strong {sf::st_crs(dhis2_df_sf)$input}}")
crs_summary <- data.frame(
dataset = c("Shapefile", "DHIS2 point data"),
crs = c(shp_crs$input, sf::st_crs(dhis2_df_sf)$input)
)
crs_summaryPour adapter le code:
- Line 2: Replace
shp_adm3with the name of your own shapefile object. - Lines 5 and 6: Ensure your dataset (
dhis2_df_corrected) contains numericlatandloncolumns before converting tosfobject. - Line 8: If your coordinates use a different input CRS (e.g., not
EPSG:4326), update thecrs = 4326argument accordingly. - Note: In this demonstration, coordinates represent centroid points within
adm3boundaries.
Afficher le code
# vérifier le SCR du shapefile et attribuer une valeur par défaut si manquante
if shp_adm3.crs is None:
shp_adm3 = shp_adm3.set_crs("EPSG:4326")
shp_crs = shp_adm3.crs
# convertir les données DHIS2 en GeoDataFrame
dhis2_df_sf = gpd.GeoDataFrame(
dhis2_df_corrected.dropna(subset=["lat", "lon"]),
geometry=gpd.points_from_xy(
dhis2_df_corrected.dropna(subset=["lat", "lon"])["lon"],
dhis2_df_corrected.dropna(subset=["lat", "lon"])["lat"],
),
crs="EPSG:4326",
)
# reprojeter en cas de SCR incompatible
if dhis2_df_sf.crs != shp_crs:
dhis2_df_sf = dhis2_df_sf.to_crs(shp_crs)
cli_header("Résumé de l'alignement du SCR")
cli_info(f"SCR du shapefile : {shp_crs}")
cli_info(f"SCR des données d'intervention : {dhis2_df_sf.crs}")
crs_summary = pd.DataFrame({
"dataset": ["Shapefile", "Données ponctuelles DHIS2"],
"crs": [str(shp_crs), str(dhis2_df_sf.crs)],
})
crs_summaryPour adapter le code :
- Lignes 2–4 : Remplacez
shp_adm3par le nom de votre propre objet shapefile. Le repliset_crs("EPSG:4326")garantit qu’un SCR est attribué au shapefile avant la reprojection. - Lignes 7–14 : Vérifiez que votre jeu de données (
dhis2_df_corrected) contient des colonnes numériqueslatetlonavant la conversion en GeoDataFrame. - Ligne 13 : Si vos coordonnées utilisent un SCR d’entrée différent, mettez à jour
crs="EPSG:4326"en conséquence.
Le shapefile et le jeu de données DHIS2 utilisent désormais le même SCR (EPSG:4326). Nous avons également converti avec succès les données DHIS2 avec des points centroïdes dans les limites adm3 en une couche spatiale ponctuelle.
Cela signifie que nous pouvons maintenant superposer en toute confiance les points centroïdes sur les limites administratives et procéder aux jointures spatiales.
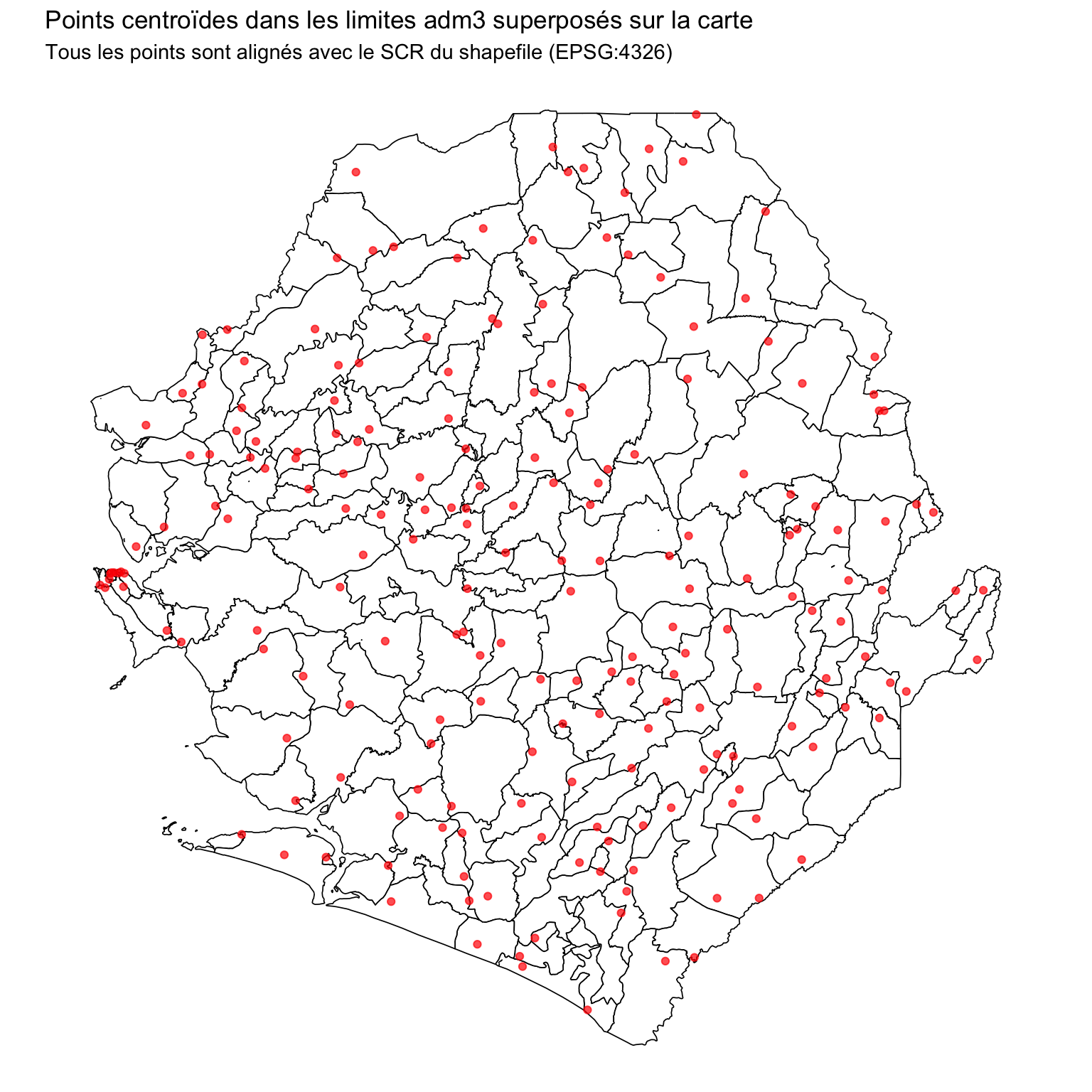
Traçons maintenant les deux ensembles.
Afficher le code
# plot shapefile and points
ggplot2::ggplot() +
ggplot2::geom_sf(
data = shp_adm3,
fill = "white",
color = "black",
size = 0.3
) +
ggplot2::geom_sf(data = dhis2_df_sf, color = "red", size = 1.5, alpha = 0.7) +
ggplot2::labs(
title = "Points centroïdes dans les limites adm3 superposés sur la carte",
subtitle = "Tous les points sont alignés avec le SCR du shapefile (EPSG:4326)"
) +
ggplot2::theme_void()
NoteSortie
Pour adapter le code:
- Line 3: Replace
shp_adm3with your own shapefile if using a different admin level or region. - Line 8: Ensure
dhis2_df_sfis your dataset with coordinates converted to ansfobject with the correct CRS. - Lines 3–7 and 8: Adjust the
fill,color, andsizeoptions ingeom_sf()as needed to match your visualization style or presentation needs. - Lines 9–11: Update the plot title and subtitle to reflect your dataset and context.
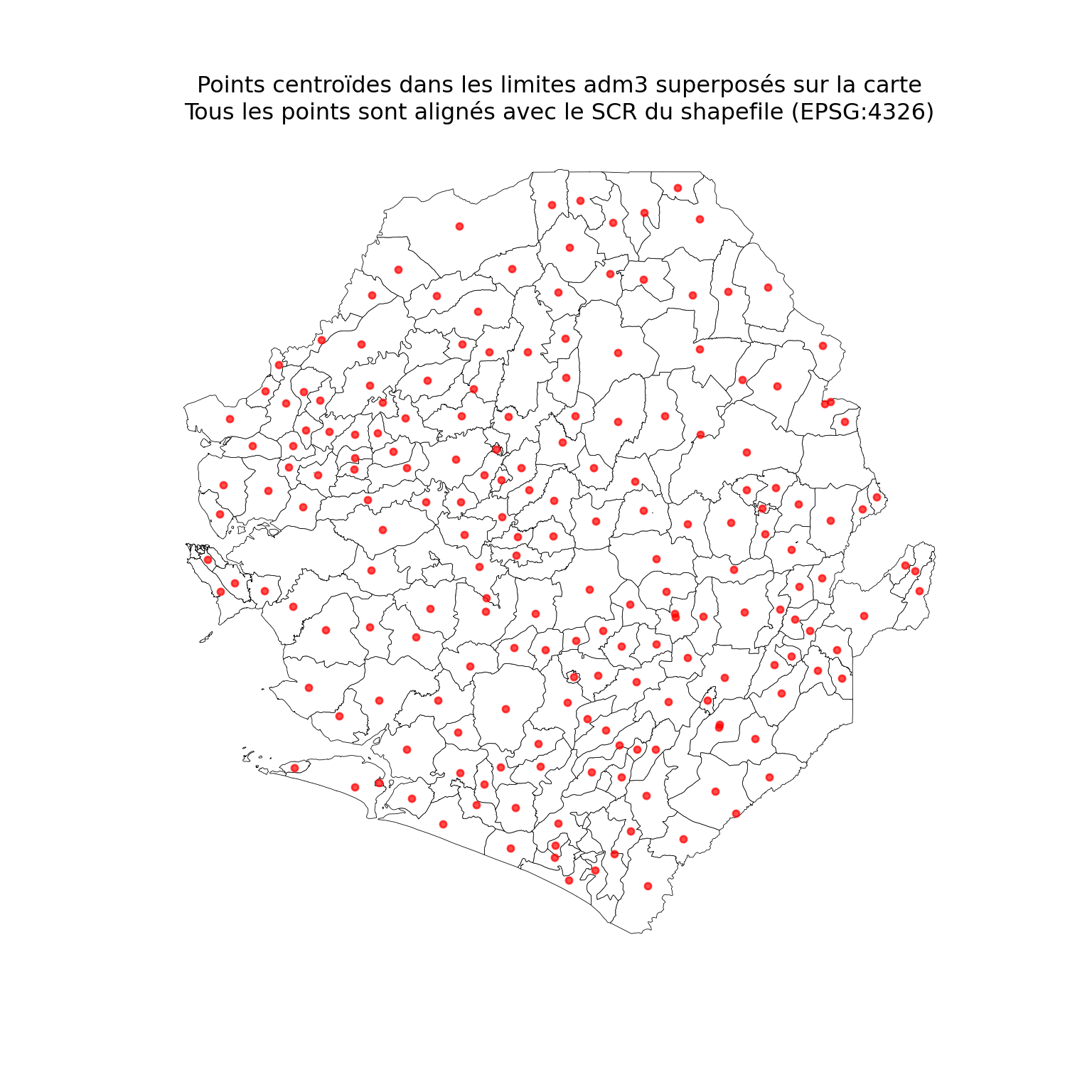
Afficher le code
fig, ax = plt.subplots(figsize=(8, 8))
# fixer l'aspect une seule fois sur l'axe ; passer aspect=None à
# gdf.plot() pour que geopandas ne recalcule pas un aspect à partir des
# limites de chaque couche (ce qui peut donner des valeurs non finies
# si une couche a une géométrie vide ou dégénérée et déclencher
# `aspect must be finite and positive`)
ax.set_aspect("equal")
shp_adm3.plot(
ax=ax, facecolor="white", edgecolor="black", linewidth=0.3, aspect=None
)
dhis2_df_sf.plot(
ax=ax, color="red", markersize=12, alpha=0.7, aspect=None
)
ax.set_title(
"centroid points within adm3 Boundaries Overlaid on Map\n"
"All points are aligned with shapefile CRS (EPSG:4326)"
)
ax.set_axis_off()
plt.show()
NoteSortie
Pour adapter le code:
- Line 2: Replace
shp_adm3with your own shapefile if using a different admin level or region. - Line 3: Ensure
dhis2_df_sfis your dataset with coordinates converted to a GeoDataFrame with the correct CRS. - Lines 2–3: Adjust the fill, colour, and marker size options as needed.
- Lines 4–7: Update the plot title and subtitle to reflect your dataset and context.
We have successfully cleaned and aligned our coordinate data. The centroid points within adm3 boundaries now correctly overlay the shapefile, and we’re ready for the next step: spatially joining these points to admin units.
Étape 5.3 : Agréger les coordonnées au niveau adm3
After validating and parsing facility coordinates, before joining them to the shapefile, the next step is to aggregate them to the adm3 level. This involves calculating a representative centroid for each adm3 by averaging the latitude and longitude of facilities within its boundary. These centroids provide a spatial reference point for visualizing aggregated indicators.
We then join these aggregated centroids with DHIS2 indicators for 2023, which are grouped and summed at the adm3 level. The result is a dataset where each administrative unit is linked to both its aggregated malaria indicators and its corresponding centroid coordinate, ready for mapping and further analysis.
Afficher le code
# get the hf centroids at the adm3 level
dhis2_hf_coords <- dhis2_df_sf |>
sf::st_drop_geometry() |>
dplyr::select(adm0, adm1, adm2, adm3, lat, lon) |>
dplyr::group_by(adm0, adm1, adm2, adm3) |>
dplyr::summarise(
lon = mean(lon, na.rm = T),
lat = mean(lat, na.rm = T),
.groups = "drop"
)
# get indicators for 2023 at the adm3 level and join back
dhis2_df_sf <- dhis2_df_sf |>
sf::st_drop_geometry() |>
dplyr::select(
adm0,
adm1,
adm2,
adm3,
year,
conf_u5
) |>
dplyr::filter(year == 2023) |>
dplyr::group_by(adm0, adm1, adm2, adm3, year) |>
dplyr::summarise(
conf_u5 = sum(conf_u5, na.rm = TRUE),
.groups = "drop"
) |>
# join the coords
dplyr::left_join(
dhis2_hf_coords,
by = c("adm0", "adm1", "adm2", "adm3")
) |>
sf::st_as_sf(coords = c("lon", "lat"), crs = sf::st_crs(shp_adm3), remove = FALSE)Pour adapter le code:
- Lines 2 and 3–4: Adjust the selected columns to match your dataset (e.g., adm levels, lat/lon field names, or any additional grouping variables).
- Lines 14 and 17: Replace the indicator variables (
year,conf_u5) with the indicators available in your dataset. - Line 22: Update the join keys (
adm0–adm3) if your dataset uses different administrative levels.
Afficher le code
# get the centroid coordinates at the adm3 level
dhis2_hf_coords = (
pd.DataFrame(dhis2_df_sf.drop(columns="geometry"))
.groupby(["adm0", "adm1", "adm2", "adm3"], as_index=False)
.agg(lon=("lon", "mean"), lat=("lat", "mean"))
)
# get indicators for 2023 at adm3 level and join back coordinates
dhis2_df_sf = (
pd.DataFrame(dhis2_df_sf.drop(columns="geometry"))
[["adm0", "adm1", "adm2", "adm3", "year", "conf_u5"]]
# convertir year en chaîne pour que le filtre fonctionne que la
# colonne source soit stockée en entier ou en caractère (l'import
# rio de R conserve year en caractère)
.loc[lambda x: x["year"].astype(str) == "2023"]
.groupby(["adm0", "adm1", "adm2", "adm3", "year"], as_index=False)
.agg(conf_u5=("conf_u5", "sum"))
.merge(dhis2_hf_coords, on=["adm0", "adm1", "adm2", "adm3"], how="left")
)
dhis2_df_sf = gpd.GeoDataFrame(
dhis2_df_sf,
geometry=gpd.points_from_xy(dhis2_df_sf["lon"], dhis2_df_sf["lat"]),
crs=shp_adm3.crs,
)Pour adapter le code:
- Lines 4 and 5: Adjust the selected columns to match your dataset.
- Lines 12 and 15: Replace
yearandconf_u5with the indicators available in your dataset. - Line 17: Update the join keys (
adm0–adm3) if your dataset uses different administrative levels.
Étape 5.4 : Jointure spatiale des points centroïdes au shapefile
After preparing and validating our coordinate data, we’re now ready to join our DHIS2 dataset with centroid points within adm3 boundaries to administrative boundaries using a spatial join. This step assigns each centroid point to its corresponding polygon such as district or chiefdom, allowing us to summarize and analyze testing coverage by geographic area.
R provides several methods for determining how points relate to polygons during spatial joins::
sf::st_contains: Points contained within polygon (most common method, used in the code below)sf::st_intersects: Point touches or is within polygonsf::st_within: Point is completely within polygon (inverse of contains)sf::st_nearest_feature: Assigns to closest polygon when boundaries are ambiguous
Afficher le code
# joined to shapefile using spatial coordinates
dhis2_df_spatial_join <- sf::st_join(
dplyr::select(shp_adm3, geometry),
dhis2_df_sf,
join = sf::st_contains
) |>
dplyr::distinct(.keep_all = TRUE)
# vérifier les lignes non appariées
unmatched_points <- dhis2_df_spatial_join |> dplyr::filter(is.na(adm3))
cli::cli_h2("Validation de la jointure spatiale")
cli::cli_alert_info("Nombre de points non appariés : {nrow(unmatched_points)}")
# vérifier la sortie
head(dhis2_df_spatial_join)Pour adapter le code:
- Lines 2 and 3: Replace
shp_adm3with your polygon shapefile anddhis2_df_sfwith your point-based data (must be an sf object). - Line 6: Adjust the final
dplyr::distinct()to retain the relevant administrative levels and variables of interest (e.g.,conf_u5) and drop any duplicates. - Line 9: Adjust
adm3to match your relevant identifier column for checking unmatched points. - Important: The order of datasets in
sf::st_join()determines both the output geometry and which spatial predicate to use:- If we want the polygon geometry in results → mention polygons first:
sf::st_join(polygons, points, join = sf::st_contains). - If we want the point geometry in results → mention points first:
sf::st_join(points, polygons, join = sf::st_within). - We want to join our shapefile to our tabular data, so we mention
shp_adm3first.
- If we want the polygon geometry in results → mention polygons first:
sf::st_containsandsf::st_withinare inverse relationships - a polygon contains a point if and only if the point is within the polygon.
Python provides the same spatial predicates through geopandas.sjoin():
predicate="contains": polygons contain points.predicate="intersects": polygons touch or contain points.predicate="within": points are within polygons, usually with points as the left dataset.sjoin_nearest(): assigns the nearest polygon when boundaries are ambiguous.
Afficher le code
# join to shapefile using spatial coordinates
dhis2_df_spatial_join = (
gpd.sjoin(
shp_adm3[["geometry"]],
dhis2_df_sf,
how="left",
predicate="contains"
)
.drop(columns="index_right", errors="ignore")
.drop_duplicates(subset=["adm0", "adm1", "adm2", "adm3", "year", "conf_u5"])
)
# vérifier les lignes non appariées
unmatched_points = dhis2_df_spatial_join.loc[dhis2_df_spatial_join["adm3"].isna()]
cli_header("Validation de la jointure spatiale")
cli_info(f"Nombre de points non appariés : {len(unmatched_points)}")
dhis2_df_spatial_join.head()Pour adapter le code:
- Lines 4 and 5: Replace
shp_adm3with your polygon shapefile anddhis2_df_sfwith your point-based data. - Line 12: Adjust the final duplicate subset to retain the relevant administrative levels and variables of interest.
- Line 16: Adjust
adm3to match your relevant identifier column for checking unmatched points. - If you want point geometry in the output, place
dhis2_df_sfon the left and usepredicate="within".
We have successfully joined the DHIS2 data to the shapefile. All centroid points within adm3 boundaries now inherit administrative context (e.g., district, chiefdom) based on where they fall within the shapefile polygons.
Étape 5.5 : Utiliser des jointures avec tampon pour les points proches des limites (alternative à l’étape 5.4)
Parfois, les jointures basées sur les coordonnées échouent parce que les points tombent juste en dehors des limites administratives en raison d’erreurs GPS, de différences de numérisation des limites ou d’arrondissement des coordonnées. Dans ces cas, une jointure avec tampon peut aider en créant une petite zone de tolérance autour des limites.
Il est important de noter que cette étape est une alternative à l’étape 5.3, et ne doit pas être effectuée en plus de la jointure spatiale standard.
WarningPoints en dehors des limites
Envisagez des jointures avec tampon lorsque :
- Les points tombent juste en dehors des limites (surtout près des frontières)
- Les coordonnées GPS proviennent d’appareils mobiles (précision moindre) : tampon de 500 m à 1 km
- Données historiques (les limites ont pu changer) : tampon de 1 km à 3 km
- Établissements de santé près des frontières administratives : tampon de 500 m à 2 km
- Grappes d’enquête (déplacées pour la confidentialité, DHS par exemple) : tampon de 100 m à 500 m
Note : Il s’agit de distances de tampon suggérées ; ajustez en fonction de la qualité de vos données et du contexte spécifique.
Bien que le tampon permette de récupérer les points quasi manqués, il peut également :
- Attribuer des points à des unités administratives incorrectes dans les zones de limites denses
- Créer des chevauchements entre unités adjacentes
- Masquer de véritables problèmes de qualité des données qui devraient être traités à la source
Les décisions de tampon doivent être déterminées par la compréhension du contexte ainsi que par l’intégrité des données. Évaluez toujours si les points non appariés sont vraiment proches des limites (problèmes de précision GPS) ou éloignés (problèmes de qualité des données) avant d’appliquer des tampons.
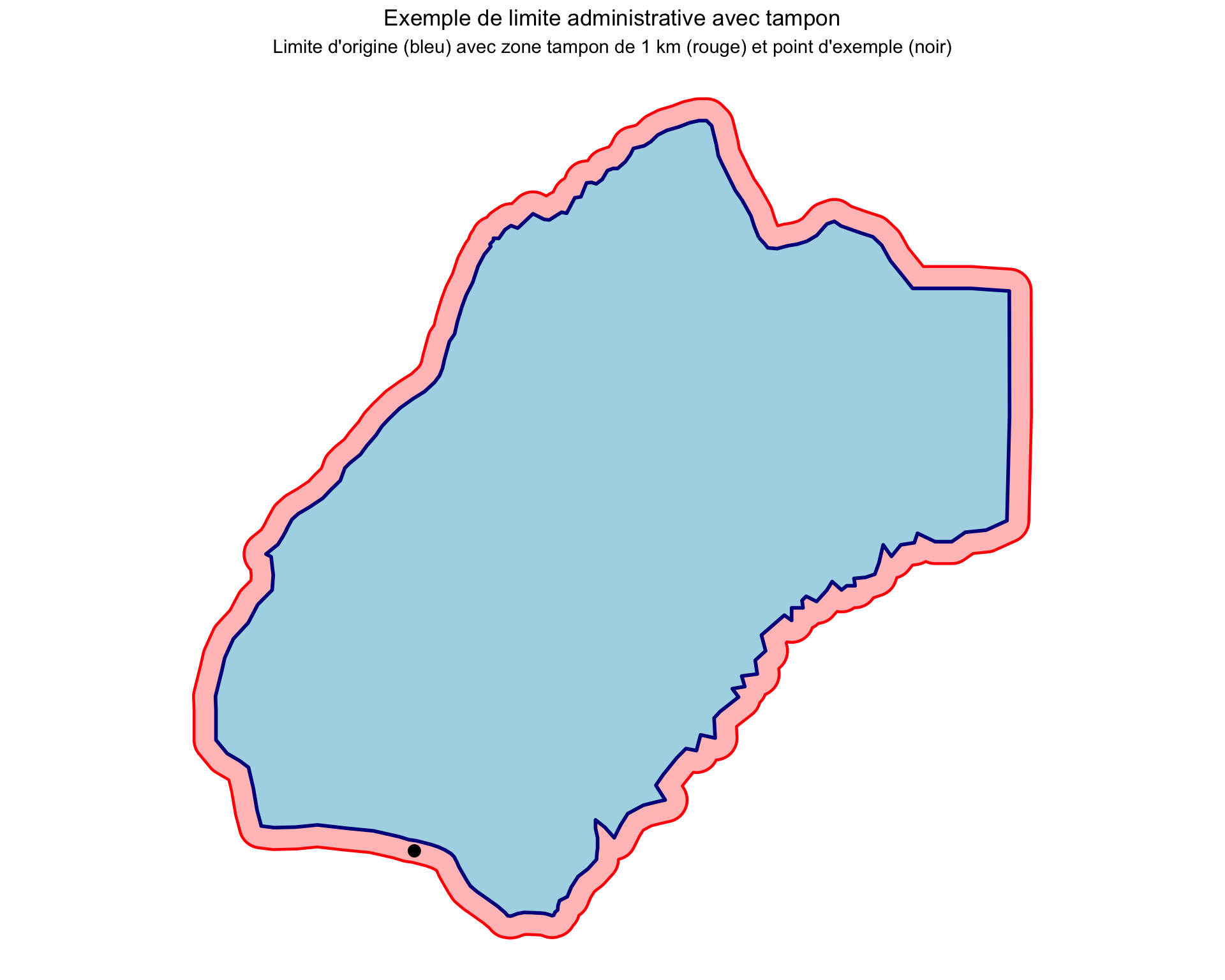
Dans cette section, nous allons créer une version avec tampon de shp_adm3 appelée shp_adm3_buffered, puis montrer un exemple de coordonnée qui tombe en dehors de MALEMA mais devrait être attribuée à la chefferie MALEMA grâce au tampon.
Pour adapter le code:
- Ligne 5 : Ajustez
dist = 1000pour modifier la taille du tampon (en mètres). Utilisez différentes distances de tampon pour différents niveaux administratifs si nécessaire. - Ligne 6 : Remplacez
crs = 4326par la sortie desf::st_crs(shp_adm3)pour préserver la CRS d’origine.- Ligne 4 : Note : Nous transformons en
crs = 3857(Web Mercator) pour un tampon précis basé sur les mètres.
- Ligne 4 : Note : Nous transformons en
Pour adapter le code:
- Line 4: Adjust
.buffer(1000)to change buffer size in meters. - Line 5: Replace
epsg=4326withshp_adm3.crsto preserve the original CRS. - Line 3: The code transforms to EPSG:3857 for meter-based buffering.
Now let’s create an example coordinate that falls just outside MALEMA chiefdom but should logically belong to it:
Afficher le code
# select MALEMA chiefdom for our example
malema_original <- shp_adm3 |>
dplyr::filter(adm3 == "MALEMA")
malema_buffered <- shp_adm3_buffered |>
dplyr::filter(adm3 == "MALEMA")
# create example point that falls just outside MALEMA but within
# buffer zone (this simulates a GPS point with slight inaccuracy)
example_point <- data.frame(
# 10.85 W (negative for west)
lon = -10.85,
# 7.641 N (positive for north)
lat = 7.641
) |>
sf::st_as_sf(coords = c("lon", "lat"), crs = 4326)
# create visualization
ggplot2::ggplot() +
# plot the buffer first (so it appears behind)
ggplot2::geom_sf(
data = malema_buffered,
fill = "red",
alpha = 0.3,
color = "red",
size = 0.8
) +
# plot the original boundary on top
ggplot2::geom_sf(
data = malema_original,
fill = "lightblue",
color = "darkblue",
size = 1
) +
# add the example point
ggplot2::geom_sf(
data = example_point,
color = "black",
size = 3,
# filled circle
shape = 19
) +
ggplot2::labs(
title = "Exemple de limite administrative avec tampon",
subtitle = "Limite d'origine (bleu) avec zone tampon de 1 km (rouge) et point d'exemple (noir)"
) +
ggplot2::theme_void() +
ggplot2::theme(
plot.title = ggplot2::element_text(hjust = 0.5),
plot.subtitle = ggplot2::element_text(hjust = 0.5)
)
NoteSortie
Afficher le code
# select MALEMA chiefdom for the example
malema_original = shp_adm3.loc[shp_adm3["adm3"] == "MALEMA"]
malema_buffered = shp_adm3_buffered.loc[shp_adm3_buffered["adm3"] == "MALEMA"]
# create example point that falls just outside MALEMA but within the buffer zone
example_point = gpd.GeoDataFrame(
{"lon": [-10.85], "lat": [7.641]},
geometry=gpd.points_from_xy([-10.85], [7.641]),
crs="EPSG:4326"
)
fig, ax = plt.subplots(figsize=(10, 8))
# fixer l'aspect une seule fois sur l'axe et désactiver le calcul
# d'aspect de geopandas pour qu'une couche dégénérée ne déclenche pas
# `aspect must be finite and positive`
ax.set_aspect("equal")
malema_buffered.plot(
ax=ax, color="red", alpha=0.3, edgecolor="red", linewidth=0.8, aspect=None
)
malema_original.plot(
ax=ax, color="lightblue", edgecolor="darkblue", linewidth=1, aspect=None
)
example_point.plot(ax=ax, color="black", markersize=35, aspect=None)
ax.set_title(
"Exemple de limite administrative avec tampon\n"
"Limite d'origine (bleu) avec zone tampon de 1 km (rouge) et point d'exemple (noir)"
)
ax.set_axis_off()
plt.show()
NoteSortie
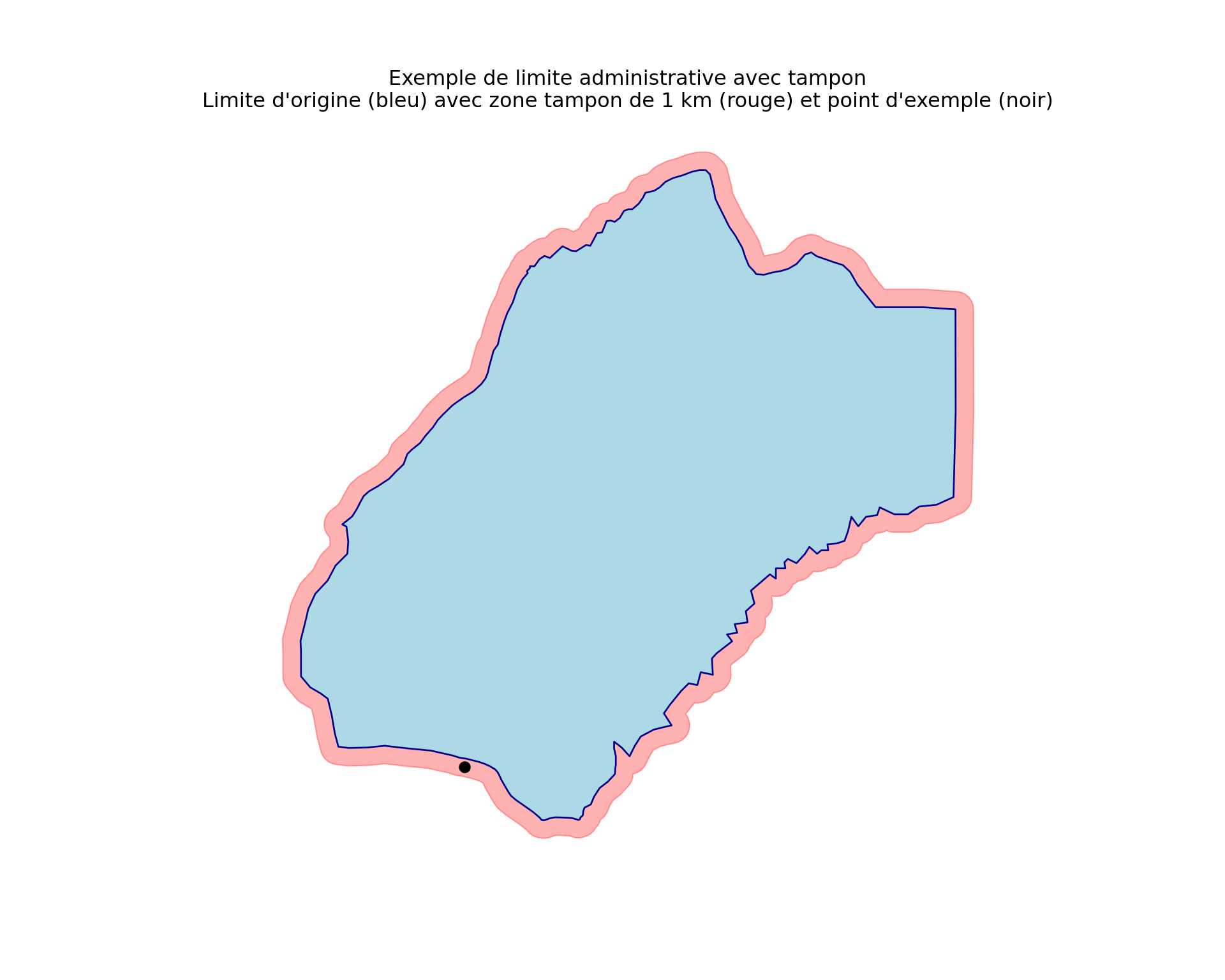
The original boundary is shown as the blue fill, but with the 1km buffer (in red) the boundary has changed slightly. Now we can see that the coordinate just outside the border of MALEMA will be included as part of MALEMA chiefdom if shp_adm3_buffered is used. This will be true for any other points in the map that fall within the buffer zones of their nearest administrative units.
If one wished to use the buffered approach to joining their data, they would be looking to use shp_adm3_buffered for their spatial joining instead of shp_adm3.
Pour adapter le code:
- Lines 2 and 3: Replace
shp_adm3_bufferedwith your polygon shapefile anddhis2_df_sfwith your point-based data (must be an sf object). - Line 6: Adjust the final
dplyr::distinct()to retain the relevant administrative levels and variables of interest (e.g.,conf_u5) and drop any duplicates. - Important: The order of datasets in
sf::st_join()determines both the output geometry and which spatial predicate to use:- If we want the polygon geometry in results → mention polygons first:
sf::st_join(polygons, points, join = sf::st_contains). - If we want the point geometry in results → mention points first:
sf::st_join(points, polygons, join = sf::st_within). - We want to join our shapefile to our tabular data, so we mention
shp_adm3_bufferedfirst.
- If we want the polygon geometry in results → mention polygons first:
sf::st_containsandsf::st_withinare inverse relationships - a polygon contains a point if and only if the point is within the polygon.
Pour adapter le code:
- Lines 4 and 5: Replace
shp_adm3_bufferedwith your buffered polygon shapefile anddhis2_df_sfwith your point-based data. - Line 11: Adjust the final
.drop_duplicates()to retain the relevant administrative levels and variables of interest. - If you want point geometry in the output, place
dhis2_df_sfon the left and usepredicate="within".
Étape 6 : Valider les deux méthodes de jointure
After successfully demonstrating both attribute-based (name) and coordinate-based joining methods, we need to validate that both approaches produce consistent and complete results. This validation step ensures that our spatial data linkage is robust and that we can confidently use either method depending on data availability and quality.
We’ll compare the results from both join methods to confirm they produce the same spatial coverage and identify any discrepancies that need investigation.
Étape 6.1 : Préparer les deux résultats de jointure pour comparaison
First, let’s create clean versions of both join results with consistent column names for easy comparison.
Afficher le code
# name-based join result (from Step 4.5)
name_join_result <- dhis2_df_coord_shp |>
dplyr::mutate(join_method = "Attribute-based Join") |>
as.data.frame() |>
dplyr::select(
adm0,
adm1,
adm2,
adm3,
year,
conf_u5,
join_method
) |>
dplyr::filter(year == 2023) |>
dplyr::group_by(adm0, adm1, adm2, adm3, year, join_method) |>
dplyr::summarise(
conf_u5 = sum(conf_u5, na.rm = TRUE),
.groups = "drop"
) |>
# join back shapefile
dplyr::left_join(
shp_adm3,
by = c("adm0", "adm1", "adm2", "adm3")
)
# coordinate-based join result (from Step 5.3)
coord_join_result <- dhis2_df_spatial_join |>
dplyr::mutate(join_method = "Coordinate-based Join") |>
dplyr::select(
adm0,
adm1,
adm2,
adm3,
conf_u5,
join_method
) |>
# remove unmatched points
dplyr::filter(!is.na(adm3))
# bind both together
joined_plot_data <- dplyr::bind_rows(
name_join_result,
coord_join_result
)
# check summary statistics for conf_u5
joined_plot_data |>
as.data.frame() |>
dplyr::group_by(join_method) |>
dplyr::summarise(
min_conf_u5 = min(conf_u5, na.rm = TRUE),
mean_conf_u5 = mean(conf_u5, na.rm = TRUE),
max_conf_u5 = max(conf_u5, na.rm = TRUE),
n_missing = sum(is.na(conf_u5))
)Pour adapter le code:
- Lines 10, 16, and 28: Replace
conf_u5with your own malaria indicator. - Lines 5–10 and 23–28: Adjust the selected columns to match your dataset structure and variables of interest.
Afficher le code
# name-based join result from Step 4.5
name_join_result = (
pd.DataFrame(dhis2_df_coord_shp.drop(columns="geometry"))
.assign(join_method="Attribute-based Join")
[["adm0", "adm1", "adm2", "adm3", "year", "conf_u5", "join_method"]]
# convertir year en chaîne pour que le filtre fonctionne que la
# colonne source soit stockée en entier ou en caractère (l'import
# rio de R conserve year en caractère)
.loc[lambda x: x["year"].astype(str) == "2023"]
.groupby(["adm0", "adm1", "adm2", "adm3", "year", "join_method"], as_index=False)
.agg(conf_u5=("conf_u5", "sum"))
.merge(shp_adm3, on=["adm0", "adm1", "adm2", "adm3"], how="left")
)
name_join_result = gpd.GeoDataFrame(name_join_result, geometry="geometry", crs=shp_adm3.crs)
# coordinate-based join result from Step 5.3
coord_join_result = (
dhis2_df_spatial_join
.assign(join_method="Coordinate-based Join")
[["adm0", "adm1", "adm2", "adm3", "conf_u5", "join_method", "geometry"]]
.loc[lambda x: x["adm3"].notna()]
)
# bind both together
joined_plot_data = gpd.GeoDataFrame(
pd.concat([name_join_result, coord_join_result], ignore_index=True, sort=False),
geometry="geometry",
crs=shp_adm3.crs
)
# check summary statistics for conf_u5
joined_plot_data.groupby("join_method").agg(
min_conf_u5=("conf_u5", "min"),
mean_conf_u5=("conf_u5", "mean"),
max_conf_u5=("conf_u5", "max"),
n_missing=("conf_u5", lambda x: x.isna().sum()),
).reset_index()Pour adapter le code:
- Lines 6, 9 and 18: Replace
conf_u5with your own malaria indicator. - Lines 5–6 and 17–18: Adjust the selected columns to match your dataset structure and variables of interest.
We can see that the join worked as the summary stats for conf_u5 for both datasets are exactly the same.
Étape 6.2 : Validation visuelle - comparaison côte à côte
Finally, let’s create side-by-side maps to visually confirm that both join methods produce identical spatial patterns. Each polygon in the shapefile should have the same color fill in both maps.
Afficher le code
adm3_validation_map <- joined_plot_data |>
sf::st_as_sf() |>
ggplot2::ggplot() +
ggplot2::geom_sf(
aes(fill = conf_u5 / 1000),
color = "grey20",
size = 0.15
) +
ggplot2::scale_fill_viridis_c(
option = "A",
direction = -1,
labels = scales::label_number(
accuracy = 1,
# formats as 5k, 10k, 20k
suffix = "k"
),
na.value = "lightgrey",
guide = ggplot2::guide_colorbar(
barwidth = grid::unit(5, "cm"),
barheight = grid::unit(0.4, "cm"),
title.position = "top"
)
) +
ggplot2::facet_wrap(~join_method, nrow = 1) +
ggplot2::labs(
title = "Cas confirmés de moins de 5 ans par Admin-3 en 2023\n",
fill = "Cas confirmés (moins de 5 ans)"
) +
ggplot2::coord_sf(datum = NA) +
ggplot2::theme_void() +
ggplot2::theme(
strip.text = ggplot2::element_text(size = 10, face = "bold"),
legend.position = "bottom",
legend.title = ggplot2::element_text(hjust = 0.5),
plot.title = ggplot2::element_text(hjust = 0.5)
)
# afficher le graphique
adm3_validation_map
# enregistrer le graphique
ggplot2::ggsave(
plot = adm3_validation_map,
here::here("03_output/3a_figures/shapefile_check_conf_adm3.png"),
width = 12,
height = 5,
dpi = 300
)
NoteSortie
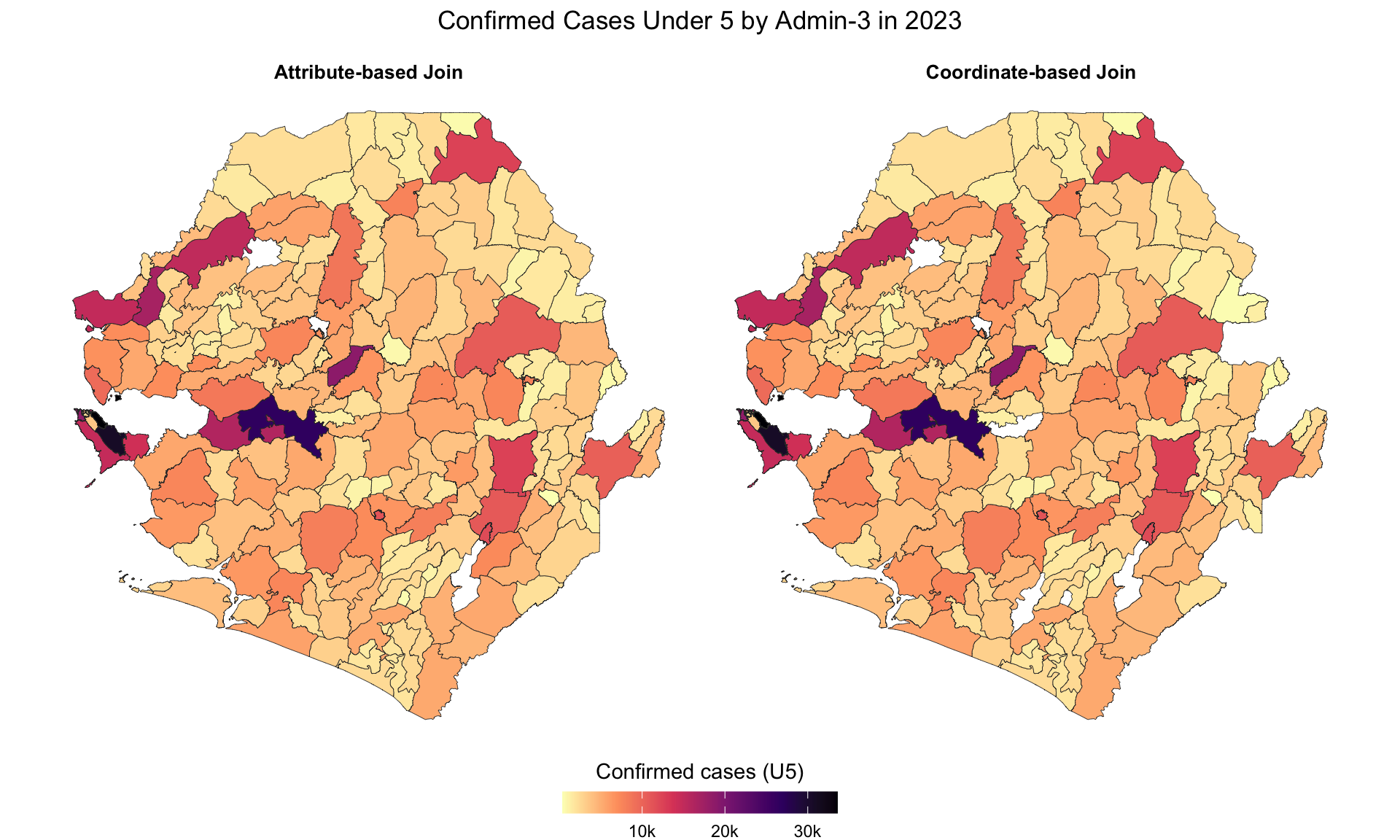
Pour adapter le code:
- Line 5: Replace
conf_u5with your continuous malaria indicator variable. - Lines 25–27: Update plot titles and subtitles to reflect your specific context.
Afficher le code
validation_plot = plot_validation_maps(
joined_plot_data,
value_col="conf_u5",
method_col="join_method",
title="Cas confirmés de moins de 5 ans par Admin-3 en 2023",
)
plt.show()
# enregistrer le graphique
validation_plot.savefig(
here("03_output/3a_figures/shapefile_check_conf_adm3.png"),
dpi=300,
bbox_inches="tight",
)
NoteSortie
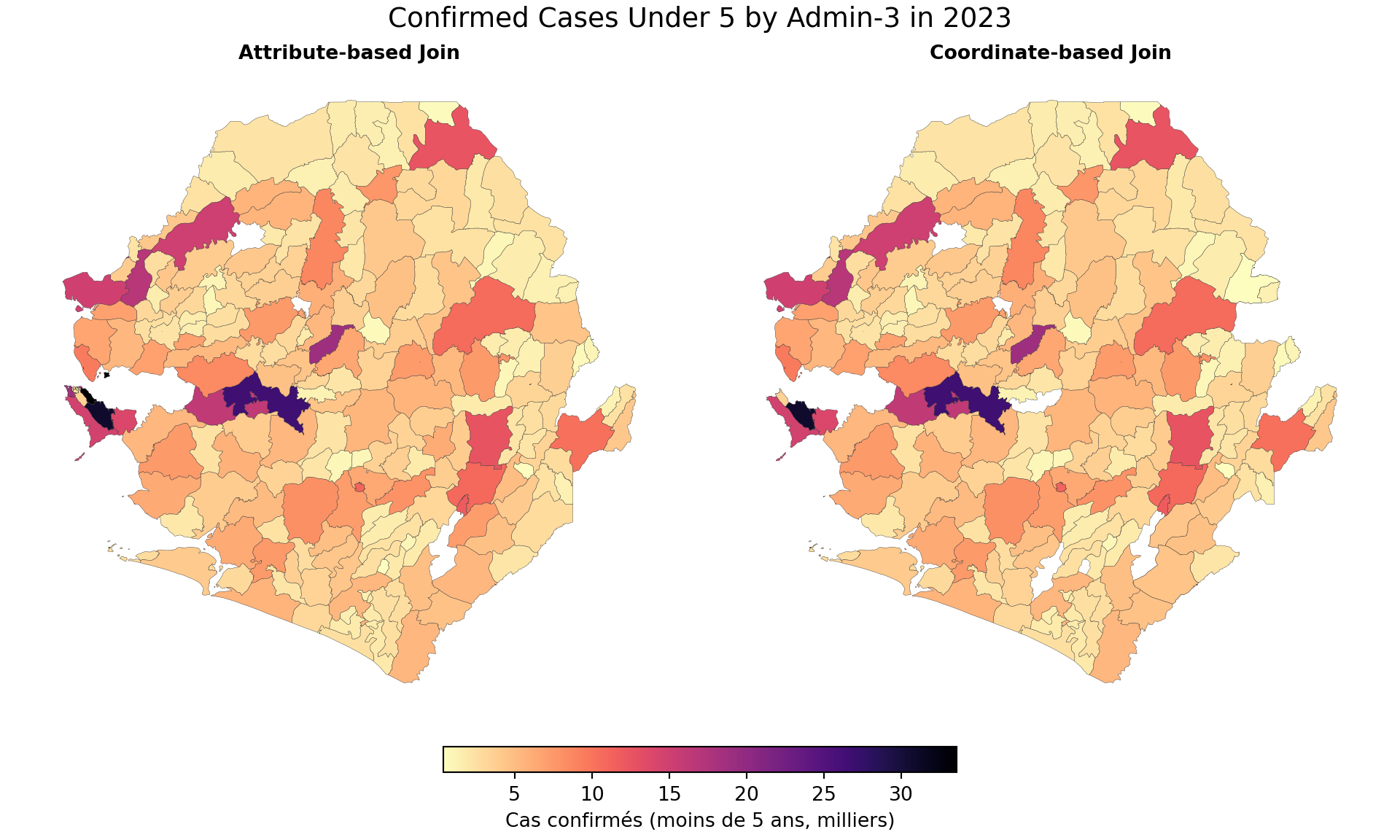
Pour adapter le code:
- Ligne 4 : Remplacez
conf_u5par votre variable d’indicateur du paludisme continue. - Ligne 6 : Mettez à jour le titre du graphique pour refléter votre contexte spécifique.
Les 208 zones ont été jointes avec succès avec des taux de dépistage identiques. Les cartes côte à côte confirment que tout s’est aligné correctement. Utilisez des inspections visuelles comme celle-ci pour voir si votre fusion a fonctionné correctement et détecter d’éventuels problèmes de données dès le début.
Étape 7 : Enregistrer les données
Dans cette étape, nous enregistrons les données DHIS2 fusionnées finales avec notre shapefile.
Il existe plusieurs formats pour enregistrer vos données, tous démontrés dans l’étape 7 de la page Gestion et personnalisation des shapefiles. Dans cet exemple, nous utiliserons le simple format RDS, en veillant à ce que lors d’une utilisation future, lorsque nous le chargeons, nous le convertissions en objet sf :
Afficher le code
Pour adapter le code:
- Lines 2–4 and 7–9: Be sure to adapt the file paths and objects for files to be saved appropriately before saving.
Afficher le code
save_path = Path(surv_path) / "processed"
save_path.mkdir(parents=True, exist_ok=True)
# save the name-based joined data
dhis2_df_coord_shp.to_file(
save_path / "sle_dhis2_df_name_joined_adm3.gpkg",
layer="name_joined_adm3",
driver="GPKG"
)
# save the coordinate-based joined data
dhis2_df_spatial_join.to_file(
save_path / "sle_dhis2_df_coord_joined_adm3.gpkg",
layer="coord_joined_adm3",
driver="GPKG"
)Pour adapter le code:
- Lignes 2–4 et 10–12 : Adaptez les chemins de fichiers et les objets avant d’enregistrer.
- Utilisez GeoPackage pour les sorties spatiales et CSV ou Parquet pour les tables non spatiales.
Résumé
Dans cette section, nous avons parcouru la préparation complète des données de coordonnées pour l’analyse spatiale. Nous avons identifié et converti les valeurs au format DMS, signalé et corrigé les coordonnées potentiellement inversées à l’aide de la logique de boîte englobante et de vérifications visuelles, et nous nous sommes assurés que les deux jeux de données partageaient une CRS cohérente. Après avoir converti les données DHIS2 en objet sf, nous avons effectué avec succès une jointure spatiale avec le shapefile et visualisé les résultats à l’aide de cartes propres et catégorisées. Cette section constitue une référence clé pour toute personne préparant des jeux de données basés sur des points pour l’intégration avec des limites administratives ; consultez-la chaque fois que vous devez aligner et valider des données géospatiales.
Code complet
Le script complet pour fusionner des shapefiles avec des données tabulaires est disponible ci-dessous.
Show full code
################################################################################
####### ~ Fusion des shapefiles avec des données tabulaires full code ~ ########
################################################################################
### Step -----------------------------------------------------------------------
# Vérifier si 'pacman' est installé; l'installer s'il manque
if (!requireNamespace("pacman", quietly = TRUE)) {
install.packages("pacman")
}
# Charger tous les packages requis avec pacman
pacman::p_load(
sf, # pour lire et manipuler les shapefiles
rio, # pour importer des fichiers Excel (remplace readxl)
dplyr, # pour manipuler les données
stringr, # pour nettoyer et formater les chaînes
ggplot2, # pour créer des graphiques
cli, # pour les sorties console stylisées
here # pour les chemins de fichiers multiplateformes
)
# sntutils contient plusieurs fonctions d'aide utiles pour la gestion
# et le nettoyage des données
if (!requireNamespace("sntutils", quietly = TRUE)) {
devtools::install_github("ahadi-analytics/sntutils")
}
# pour analyser les coordonnées
if (!requireNamespace("parzer", quietly = TRUE)) {
remotes::install_github("ropensci/parzer")
}
# importer le shapefile
shp_adm3 <- readRDS(
here::here(
"1.1_foundational",
"1.1a_administrative_boundaries",
"processed",
"sle_spatial_adm3_2021.rds"
)
) |>
# garantir que la sortie reste un objet sf valide pour les jointures suivantes
sf::st_as_sf()
# chemin des données de surveillance
surv_path <- here::here("1.2_epidemiology", "1.2a_routine_surveillance")
# obtenir les données sur le paludisme
dhis2_df <- rio::import(
here::here(
surv_path,
"raw",
"clean_malaria_routine_data_final.rds"
)
)
# vérifier les données DHIS2 et le shapefile
cli::cli_h2("Données DHIS2")
dhis2_df |>
dplyr::distinct(adm0, adm1, adm2, adm3) |>
dplyr::arrange(adm0, adm1, adm2, adm3) |>
head(n = 10)
cli::cli_h2("Shapefile Adm3")
shp_adm3 |>
dplyr::distinct(adm0, adm1, adm2, adm3) |>
dplyr::arrange(adm0, adm1, adm2, adm3) |>
head(n = 10)
# nettoyage initial
dhis2_df <- dhis2_df |>
dplyr::mutate(
adm0 = toupper(adm0),
adm2 = toupper(adm1),
adm3 = toupper(adm3),
adm2 = stringr::str_replace(
adm2,
stringr::fixed(" DISTRICT"),
""
),
adm3 = stringr::str_replace(
adm3,
stringr::fixed(" CHIEFDOM"),
""
)
) |>
dplyr::mutate(
adm1 = dplyr::case_when(
adm2 %in% c("KAILAHUN", "KENEMA", "KONO") ~
"EASTERN",
adm2 %in% c("BOMBALI", "FALABA", "KOINADUGU", "TONKOLILI") ~
"NORTH EAST",
adm2 %in% c("KAMBIA", "KARENE", "PORT LOKO") ~
"NORTH WEST",
adm2 %in% c("BO", "BONTHE", "MOYAMBA", "PUJEHUN") ~
"SOUTHERN",
adm2 %in% c("WESTERN AREA RURAL", "WESTERN AREA URBAN") ~
"WESTERN"
)
)
# vérifier les données DHIS2 et le shapefile
cli::cli_h2("Données DHIS2 (nettoyage initial) ")
dhis2_df |>
dplyr::distinct(adm0, adm1, adm2, adm3) |>
dplyr::arrange(adm0, adm1, adm2, adm3) |>
head(n = 10)
cli::cli_h2("Shapefile Adm3")
shp_adm3 |>
dplyr::distinct(adm0, adm1, adm2, adm3) |>
dplyr::arrange(adm0, adm1, adm2, adm3) |>
head(n = 10)
# obtenir les noms administratifs distincts de DHIS2
dhis2_admins <-
dhis2_df |>
dplyr::distinct(adm0, adm1, adm2, adm3)
# supprimer la géométrie pour les jointures par noms seulement
shp_names <-
shp_adm3 |>
sf::st_drop_geometry() |>
dplyr::distinct(adm0, adm1, adm2, adm3)
# jointure interne pour compter les correspondances (polygones ∩ dhis2)
shp_with_dhis2 <-
shp_names |>
dplyr::inner_join(
dhis2_admins,
by = c("adm0", "adm1", "adm2", "adm3")
)
# polygones sans admin DHIS2 correspondante (shapefile ▷ dhis2)
polygons_without_dhis2 <-
shp_names |>
dplyr::anti_join(
dhis2_admins,
by = c("adm0", "adm1", "adm2", "adm3")
)
# admins DHIS2 sans polygone correspondant (dhis2 ▷ shapefile)
dhis2_without_polygons <-
dhis2_admins |>
dplyr::anti_join(
shp_names,
by = c("adm0", "adm1", "adm2", "adm3")
)
# comptes pour des diagnostics clairs
total_polygons <- nrow(shp_adm3)
matched_polygons <- nrow(shp_with_dhis2)
polygons_no_match <- nrow(polygons_without_dhis2)
dhis2_no_match <- nrow(dhis2_without_polygons)
# rapport
cli::cli_h2("Diagnostics de jointure admin (adm0 à adm3)")
# perspective des polygones
cli::cli_alert_success(
"Unités administratives du shapefile (uniques) : {total_polygons}"
)
cli::cli_alert_success(
"Correspondant avec DHIS2 : {matched_polygons}"
)
# perspective DHIS2
cli::cli_alert_warning(
"Unités administratives DHIS2 non appariées (aucun polygone) : {dhis2_no_match}"
)
cli::cli_alert_warning(
"Unités administratives du shapefile non appariées (aucune entrée DHIS2) : {polygons_no_match}"
)
# aperçus
if (nrow(dhis2_without_polygons) > 0) {
cli::cli_h2("Admins DHIS2 sans polygone correspondant (exemple)")
dhis2_without_polygons |> head(10)
}
if (nrow(polygons_without_dhis2) > 0) {
cli::cli_h2("Polygones sans correspondance DHIS2 (exemple)")
polygons_without_dhis2 |> head(10)
}
# jointure interne (conserver uniquement les polygones appariés)
# définir l'emplacement du cache
cache_loc <- "1.1_foundational/1d_cache_files"
# harmoniser les noms administratifs dans dhis2_df
# à l'aide de shp_adm3
dhis2_df_cleaned <-
sntutils::prep_geonames(
target_df = dhis2_df, # jeu de données à nettoyer
lookup_df = shp_adm3, # jeu de référence avec les bons noms admin
level0 = "adm0",
level1 = "adm1",
level2 = "adm2",
level3 = "adm3",
method = "lv", # distance de Levenshtein pour l'appariement
cache_path = here::here(cache_loc, "geoname_cache.rds")
)
# obtenir les noms administratifs distincts de dhis2
dhis2_admins <-
dhis2_df_cleaned |>
dplyr::distinct(adm0, adm1, adm2, adm3)
# drop geometry for name-only joins
shp_names <-
shp_adm3 |>
sf::st_drop_geometry() |>
dplyr::distinct(adm0, adm1, adm2, adm3)
# jointure interne pour compter les correspondances (polygones ∩ dhis2)
shp_with_dhis2 <-
shp_names |>
dplyr::inner_join(
dhis2_admins,
by = c("adm0", "adm1", "adm2", "adm3")
)
# polygones sans admin DHIS2 correspondante (shapefile ▷ dhis2)
polygons_without_dhis2 <-
shp_names |>
dplyr::anti_join(
dhis2_admins,
by = c("adm0", "adm1", "adm2", "adm3")
)
# admins DHIS2 sans polygone correspondant (dhis2 ▷ shapefile)
dhis2_without_polygons <-
dhis2_admins |>
dplyr::anti_join(
shp_names,
by = c("adm0", "adm1", "adm2", "adm3")
)
# comptes pour des diagnostics clairs
total_polygons <- nrow(shp_adm3)
matched_polygons <- nrow(shp_with_dhis2)
polygons_no_match <- nrow(polygons_without_dhis2)
dhis2_no_match <- nrow(dhis2_without_polygons)
# rapport
cli::cli_h2("Diagnostics de jointure admin (adm0 à adm3)")
# perspective des polygones
cli::cli_alert_success(
"Unités administratives du shapefile (uniques) : {total_polygons}"
)
cli::cli_alert_success(
"Correspondant avec DHIS2 : {matched_polygons}"
)
# perspective DHIS2
cli::cli_alert_warning(
"Unités administratives DHIS2 non appariées (aucun polygone) : {dhis2_no_match}"
)
cli::cli_alert_warning(
"Unités administratives du shapefile non appariées (aucune entrée DHIS2) : {polygons_no_match}"
)
# aperçus
if (nrow(dhis2_without_polygons) > 0) {
cli::cli_h2("Admins DHIS2 sans polygone correspondant (exemple)")
dhis2_without_polygons |> head(10)
}
if (nrow(polygons_without_dhis2) > 0) {
cli::cli_h2("Polygones sans correspondance DHIS2 (exemple)")
polygons_without_dhis2 |> head(10)
}
# joindre les données DHIS2 nettoyées au shapefile par noms administratifs
dhis2_df_coord_shp <- shp_adm3 |>
dplyr::left_join(
dhis2_df_cleaned,
by = c("adm0", "adm1", "adm2", "adm3")
)
# obtenir le nombre distinct de formes jointes aux données dhis2
dist_shapes <- dplyr::n_distinct(dhis2_df_coord_shp$geometry)
# vérifier le résultat
cli::cli_h2("Résultat de jointure basée sur les noms")
cli::cli_alert_success(
"{dist_shapes} polygones joints avec succès aux données DHIS2"
)
# Count missing coordinates
missing_lat <- sum(is.na(dhis2_df$lat))
missing_lon <- sum(is.na(dhis2_df$lon))
cli::cli_h2("Missing Coordinate Check")
cli::cli_alert_info("Missing latitude values: {missing_lat}")
cli::cli_alert_info("Missing longitude values: {missing_lon}")
# function to detect DMS format using common symbols for
# degrees, minutes, or seconds
detect_dms <- function(x) {
grepl("[°º].*['′\"″]", x)
}
# filter rows where lat or lon appears to be in DMS format
dms_detected <- dhis2_df |>
dplyr::filter(detect_dms(lat) | detect_dms(lon)) |>
dplyr::distinct(adm1, adm2, adm3, lat, lon)
# print summary
cli::cli_h2("DMS Coordinate Check")
cli::cli_alert_info(
"Number of rows with suspected DMS format: {nrow(dms_detected)}"
)
cat("\n")
dms_detected
# check if DMS values were successfully converted
check_output <- dhis2_df |>
dplyr::filter(detect_dms(lat) | detect_dms(lon)) |>
dplyr::distinct(adm1, adm2, adm3, lat, lon) |>
dplyr::mutate(
lat_fixed = parzer::parse_lat(lat),
lon_fixed = parzer::parse_lon(lon)
)
# apply conversion to full dataset
dhis2_df_clean <- dhis2_df |>
dplyr::mutate(
lat = parzer::parse_lat(lat),
lon = parzer::parse_lon(lon)
)
# print summary of conversion
cli::cli_h2("DMS Coordinate Conversion Summary")
check_output
# get bounding box from the shapefile
bbox <- sf::st_bbox(shp_adm3)
# create `possibly_flipped` column in the main dataset
dhis2_df_flagged <- dhis2_df_clean |>
dplyr::mutate(
out_of_bounds = lat < bbox[['ymin']] |
lat > bbox[['ymax']] |
lon < bbox[['xmin']] |
lon > bbox[['xmax']],
looks_flipped = lat > bbox[['xmin']] &
# lat in lon range
lat < bbox[['xmax']] &
lon > bbox[['ymin']] &
# lon in lat range
lon < bbox[['ymax']],
possibly_flipped = looks_flipped
)
# quick summary output
cli::cli_h2("Bounding Box Coordinate Check")
cli::cli_alert_info(
"Out-of-bounds rows: {sum(dhis2_df_flagged$out_of_bounds)}"
)
cli::cli_alert_info(
"Possible flipped rows: {sum(dhis2_df_flagged$possibly_flipped)}"
)
# check output
dhis2_df_flagged |>
dplyr::filter(possibly_flipped) |>
dplyr::select(adm0, adm1, adm2, adm3, lon, lat)
# reverse flipped coordinates
dhis2_df_corrected <- dhis2_df_flagged |>
dplyr::mutate(
lat_temp = dplyr::if_else(possibly_flipped, lon, lat),
lon_temp = dplyr::if_else(possibly_flipped, lat, lon),
lat = lat_temp,
lon = lon_temp
) |>
dplyr::select(-lat_temp, -lon_temp)
# check output
dhis2_df_corrected |>
dplyr::filter(possibly_flipped) |>
dplyr::select(adm0, adm1, adm2, adm3, lon, lat)
# check CRS of shapefile
shp_crs <- sf::st_crs(shp_adm3)
# convert DHIS2 data to an sf object
dhis2_df_sf <- dhis2_df_corrected |>
# only keep rows with valid coordinates
dplyr::filter(!is.na(lat), !is.na(lon)) |>
# assume input is EPSG:4326
sf::st_as_sf(coords = c("lon", "lat"), crs = 4326)
# reproject if CRS mismatch
if (sf::st_crs(dhis2_df_sf) != shp_crs) {
dhis2_df_sf <- sf::st_transform(dhis2_df_sf, shp_crs)
}
# summary
cli::cli_h2("CRS Alignment Summary")
cli::cli_alert_info("Shapefile CRS: {.strong {shp_crs$input}}")
cli::cli_alert_info(
"Intervention data CRS: {.strong {sf::st_crs(dhis2_df_sf)$input}}")
crs_summary <- data.frame(
dataset = c("Shapefile", "DHIS2 point data"),
crs = c(shp_crs$input, sf::st_crs(dhis2_df_sf)$input)
)
crs_summary
# plot shapefile and points
ggplot2::ggplot() +
ggplot2::geom_sf(
data = shp_adm3,
fill = "white",
color = "black",
size = 0.3
) +
ggplot2::geom_sf(data = dhis2_df_sf, color = "red", size = 1.5, alpha = 0.7) +
ggplot2::labs(
title = "Points centroïdes dans les limites adm3 superposés sur la carte",
subtitle = "Tous les points sont alignés avec le SCR du shapefile (EPSG:4326)"
) +
ggplot2::theme_void()
# get the hf centroids at the adm3 level
dhis2_hf_coords <- dhis2_df_sf |>
sf::st_drop_geometry() |>
dplyr::select(adm0, adm1, adm2, adm3, lat, lon) |>
dplyr::group_by(adm0, adm1, adm2, adm3) |>
dplyr::summarise(
lon = mean(lon, na.rm = T),
lat = mean(lat, na.rm = T),
.groups = "drop"
)
# get indicators for 2023 at the adm3 level and join back
dhis2_df_sf <- dhis2_df_sf |>
sf::st_drop_geometry() |>
dplyr::select(
adm0,
adm1,
adm2,
adm3,
year,
conf_u5
) |>
dplyr::filter(year == 2023) |>
dplyr::group_by(adm0, adm1, adm2, adm3, year) |>
dplyr::summarise(
conf_u5 = sum(conf_u5, na.rm = TRUE),
.groups = "drop"
) |>
# join the coords
dplyr::left_join(
dhis2_hf_coords,
by = c("adm0", "adm1", "adm2", "adm3")
) |>
sf::st_as_sf(coords = c("lon", "lat"), crs = sf::st_crs(shp_adm3), remove = FALSE)
# joined to shapefile using spatial coordinates
dhis2_df_spatial_join <- sf::st_join(
dplyr::select(shp_adm3, geometry),
dhis2_df_sf,
join = sf::st_contains
) |>
dplyr::distinct(.keep_all = TRUE)
# vérifier les lignes non appariées
unmatched_points <- dhis2_df_spatial_join |> dplyr::filter(is.na(adm3))
cli::cli_h2("Validation de la jointure spatiale")
cli::cli_alert_info("Nombre de points non appariés : {nrow(unmatched_points)}")
# vérifier la sortie
head(dhis2_df_spatial_join)
# create 1km buffer around all administrative boundaries
# transform to meters
shp_adm3_buffered <- shp_adm3 |>
sf::st_transform(crs = 3857) |>
# buffer 1000 meters
sf::st_buffer(dist = 1000) |>
sf::st_transform(crs = 4326)
# select MALEMA chiefdom for our example
malema_original <- shp_adm3 |>
dplyr::filter(adm3 == "MALEMA")
malema_buffered <- shp_adm3_buffered |>
dplyr::filter(adm3 == "MALEMA")
# create example point that falls just outside MALEMA but within
# buffer zone (this simulates a GPS point with slight inaccuracy)
example_point <- data.frame(
# 10.85 W (negative for west)
lon = -10.85,
# 7.641 N (positive for north)
lat = 7.641
) |>
sf::st_as_sf(coords = c("lon", "lat"), crs = 4326)
# create visualization
ggplot2::ggplot() +
# plot the buffer first (so it appears behind)
ggplot2::geom_sf(
data = malema_buffered,
fill = "red",
alpha = 0.3,
color = "red",
size = 0.8
) +
# plot the original boundary on top
ggplot2::geom_sf(
data = malema_original,
fill = "lightblue",
color = "darkblue",
size = 1
) +
# add the example point
ggplot2::geom_sf(
data = example_point,
color = "black",
size = 3,
# filled circle
shape = 19
) +
ggplot2::labs(
title = "Exemple de limite administrative avec tampon",
subtitle = "Limite d'origine (bleu) avec zone tampon de 1 km (rouge) et point d'exemple (noir)"
) +
ggplot2::theme_void() +
ggplot2::theme(
plot.title = ggplot2::element_text(hjust = 0.5),
plot.subtitle = ggplot2::element_text(hjust = 0.5)
)
# join using buffered shp
dhis2_df_coord_shp_buff <- sf::st_join(
dplyr::select(shp_adm3_buffered, geometry),
dhis2_df_sf,
join = sf::st_contains
) |>
dplyr::distinct()
# name-based join result (from Step 4.5)
name_join_result <- dhis2_df_coord_shp |>
dplyr::mutate(join_method = "Attribute-based Join") |>
as.data.frame() |>
dplyr::select(
adm0,
adm1,
adm2,
adm3,
year,
conf_u5,
join_method
) |>
dplyr::filter(year == 2023) |>
dplyr::group_by(adm0, adm1, adm2, adm3, year, join_method) |>
dplyr::summarise(
conf_u5 = sum(conf_u5, na.rm = TRUE),
.groups = "drop"
) |>
# join back shapefile
dplyr::left_join(
shp_adm3,
by = c("adm0", "adm1", "adm2", "adm3")
)
# coordinate-based join result (from Step 5.3)
coord_join_result <- dhis2_df_spatial_join |>
dplyr::mutate(join_method = "Coordinate-based Join") |>
dplyr::select(
adm0,
adm1,
adm2,
adm3,
conf_u5,
join_method
) |>
# remove unmatched points
dplyr::filter(!is.na(adm3))
# bind both together
joined_plot_data <- dplyr::bind_rows(
name_join_result,
coord_join_result
)
# check summary statistics for conf_u5
joined_plot_data |>
as.data.frame() |>
dplyr::group_by(join_method) |>
dplyr::summarise(
min_conf_u5 = min(conf_u5, na.rm = TRUE),
mean_conf_u5 = mean(conf_u5, na.rm = TRUE),
max_conf_u5 = max(conf_u5, na.rm = TRUE),
n_missing = sum(is.na(conf_u5))
)
adm3_validation_map <- joined_plot_data |>
sf::st_as_sf() |>
ggplot2::ggplot() +
ggplot2::geom_sf(
aes(fill = conf_u5 / 1000),
color = "grey20",
size = 0.15
) +
ggplot2::scale_fill_viridis_c(
option = "A",
direction = -1,
labels = scales::label_number(
accuracy = 1,
# formats as 5k, 10k, 20k
suffix = "k"
),
na.value = "lightgrey",
guide = ggplot2::guide_colorbar(
barwidth = grid::unit(5, "cm"),
barheight = grid::unit(0.4, "cm"),
title.position = "top"
)
) +
ggplot2::facet_wrap(~join_method, nrow = 1) +
ggplot2::labs(
title = "Cas confirmés de moins de 5 ans par Admin-3 en 2023\n",
fill = "Cas confirmés (moins de 5 ans)"
) +
ggplot2::coord_sf(datum = NA) +
ggplot2::theme_void() +
ggplot2::theme(
strip.text = ggplot2::element_text(size = 10, face = "bold"),
legend.position = "bottom",
legend.title = ggplot2::element_text(hjust = 0.5),
plot.title = ggplot2::element_text(hjust = 0.5)
)
# afficher le graphique
adm3_validation_map
# enregistrer le graphique
ggplot2::ggsave(
plot = adm3_validation_map,
here::here("03_output/3a_figures/shapefile_check_conf_adm3.png"),
width = 12,
height = 5,
dpi = 300
)
# save the name-based joined data
saveRDS(
dhis2_df_coord_shp,
here::here(
surv_path, "processed", "sle_dhis2_df_name_joined_adm3.rds"
)
)
# save the coordinate-based joined data
saveRDS(
dhis2_df_spatial_join,
here::here(
surv_path, "processed", "sle_dhis2_df_coord_joined_adm3.rds"
)
)Show full code
################################################################################
####### ~ Fusion des shapefiles avec des données tabulaires full code ~ ########
################################################################################
### Step -----------------------------------------------------------------------
from pathlib import Path
import re
import geopandas as gpd
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pyreadr
from matplotlib import colors
from mpl_toolkits.axes_grid1 import make_axes_locatable
from pyprojroot import here
from sntutils.geo import prep_geonames
def read_rds(path):
"""Lire un fichier RDS à objet unique comme objet pandas."""
result = pyreadr.read_r(str(path))
return next(iter(result.values()))
def cli_header(message):
print(f"\n{message}")
def cli_info(message):
print(f"INFO: {message}")
def cli_success(message):
print(f"SUCCESS: {message}")
def cli_warning(message):
print(f"WARNING: {message}")
def anti_join(left, right, on):
"""Renvoyer les lignes de gauche sans clé correspondante à droite."""
right_keys = right[on].drop_duplicates()
return (
left.merge(right_keys, on=on, how="left", indicator=True)
.loc[lambda x: x["_merge"] == "left_only"]
.drop(columns="_merge")
)
def geometry_key(series):
"""Créer des clés WKB stables pour compter les géométries distinctes."""
return series.apply(lambda geom: geom.wkb if geom is not None else None)
def detect_dms_value(value):
"""Détecter les chaînes de coordonnées en degrés-minutes-secondes."""
return bool(re.search(r"[°º].*['′\"″]", str(value)))
def parse_coord(value):
"""Analyser des valeurs latitude/longitude décimales ou DMS en degrés décimaux."""
if pd.isna(value):
return np.nan
text = str(value).strip()
try:
return float(text)
except ValueError:
pass
# extraire d'abord l'indicateur d'hémisphère pour que le `\D*` gourmand
# du regex DMS principal ci-dessous ne l'absorbe pas. sans cela, des
# chaînes comme "11°8'37.08\"W" seraient analysées en +11,14 au lieu de
# -11,14, plaçant le point hors des limites de longitude du pays.
hemi_match = re.search(r"[NSEW]", text, flags=re.IGNORECASE)
hemi = hemi_match.group(0).upper() if hemi_match else ""
match = re.search(
r"(\d+(?:\.\d+)?)\D+(\d+(?:\.\d+)?)?\D*(\d+(?:\.\d+)?)?",
text,
flags=re.IGNORECASE
)
if not match:
return np.nan
deg = float(match.group(1))
minute = float(match.group(2) or 0)
second = float(match.group(3) or 0)
decimal = deg + minute / 60 + second / 3600
return -decimal if hemi in {"S", "W"} else decimal
def plot_validation_maps(data, value_col, method_col, title):
"""Créer des cartes de validation côte à côte avec une échelle de couleurs commune."""
methods = list(data[method_col].dropna().unique())
# protection contre une liste de méthodes vide pour éviter que
# matplotlib ne lève `Number of columns must be a positive integer,
# not 0`. Cela se produit lorsqu'un filtre en amont (par exemple un
# filtre d'année) supprime toutes les lignes.
if len(methods) == 0:
raise ValueError(
f"Aucune valeur trouvée dans `{method_col}` après dropna(); "
"vérifier qu'au moins une ligne survit aux filtres en amont."
)
fig, axes = plt.subplots(1, len(methods), figsize=(10, 6), constrained_layout=True)
if len(methods) == 1:
axes = [axes]
vmin = data[value_col].min(skipna=True) / 1000
vmax = data[value_col].max(skipna=True) / 1000
norm = colors.Normalize(vmin=vmin, vmax=vmax)
cmap = plt.get_cmap("magma_r")
for ax, method in zip(axes, methods):
# fixer l'aspect sur l'axe et désactiver le calcul d'aspect de
# geopandas pour qu'un sous-ensemble dégénéré ne déclenche pas
# `aspect must be finite and positive`
ax.set_aspect("equal")
subset = data.loc[data[method_col] == method].copy()
subset["plot_value"] = subset[value_col] / 1000
subset.plot(
ax=ax,
column="plot_value",
cmap=cmap,
norm=norm,
# matplotlib ne reconnaît pas le « grey20 » de R ; utiliser
# l'équivalent hexadécimal valide pour les deux moteurs
edgecolor="#333333",
linewidth=0.15,
missing_kwds={"color": "lightgrey"},
aspect=None,
)
ax.set_title(method, fontsize=10, fontweight="bold")
ax.set_axis_off()
fig.suptitle(title, fontsize=14)
sm = plt.cm.ScalarMappable(cmap=cmap, norm=norm)
sm.set_array([])
fig.colorbar(
sm,
ax=axes,
orientation="horizontal",
fraction=0.04,
pad=0.05,
label="Cas confirmés (moins de 5 ans, milliers)",
)
return fig
# importer le shapefile
spat_path = here("1.1_foundational/1.1a_administrative_boundaries")
shp_adm3 = (
gpd.read_file(Path(spat_path) / "raw" / "Chiefdom2021.shp")
.assign(adm0="SIERRA LEONE")
.rename(columns={
"FIRST_REGI": "adm1",
"FIRST_DNAM": "adm2",
"FIRST_CHIE": "adm3",
})
[["adm0", "adm1", "adm2", "adm3", "geometry"]]
)
# chemin des données de surveillance
surv_path = here("1.2_epidemiology/1.2a_routine_surveillance")
# obtenir les données sur le paludisme
dhis2_df = read_rds(Path(surv_path) / "raw" / "clean_malaria_routine_data_final.rds")
# vérifier les données DHIS2 et le shapefile
cli_header("Données DHIS2")
dhis2_df[["adm0", "adm1", "adm2", "adm3"]].drop_duplicates().sort_values(
["adm0", "adm1", "adm2", "adm3"]
).head(10)
cli_header("Shapefile Adm3")
shp_adm3[["adm0", "adm1", "adm2", "adm3"]].drop_duplicates().sort_values(
["adm0", "adm1", "adm2", "adm3"]
).head(10)
region_lookup = {
"KAILAHUN": "EASTERN",
"KENEMA": "EASTERN",
"KONO": "EASTERN",
"BOMBALI": "NORTH EAST",
"FALABA": "NORTH EAST",
"KOINADUGU": "NORTH EAST",
"TONKOLILI": "NORTH EAST",
"KAMBIA": "NORTH WEST",
"KARENE": "NORTH WEST",
"PORT LOKO": "NORTH WEST",
"BO": "SOUTHERN",
"BONTHE": "SOUTHERN",
"MOYAMBA": "SOUTHERN",
"PUJEHUN": "SOUTHERN",
"WESTERN AREA RURAL": "WESTERN",
"WESTERN AREA URBAN": "WESTERN",
}
# nettoyage initial
dhis2_df = dhis2_df.copy()
dhis2_df["adm0"] = dhis2_df["adm0"].str.upper()
dhis2_df["adm2"] = dhis2_df["adm1"].str.upper().str.replace(" DISTRICT", "", regex=False)
dhis2_df["adm3"] = dhis2_df["adm3"].str.upper().str.replace(" CHIEFDOM", "", regex=False)
dhis2_df["adm1"] = dhis2_df["adm2"].map(region_lookup)
# vérifier les données DHIS2 et le shapefile
cli_header("Données DHIS2 (nettoyage initial)")
dhis2_df[["adm0", "adm1", "adm2", "adm3"]].drop_duplicates().sort_values(
["adm0", "adm1", "adm2", "adm3"]
).head(10)
cli_header("Shapefile Adm3")
shp_adm3[["adm0", "adm1", "adm2", "adm3"]].drop_duplicates().sort_values(
["adm0", "adm1", "adm2", "adm3"]
).head(10)
join_keys = ["adm0", "adm1", "adm2", "adm3"]
# obtenir les noms administratifs distincts de DHIS2
dhis2_admins = dhis2_df[join_keys].drop_duplicates()
# supprimer la géométrie pour les jointures par noms seulement
shp_names = shp_adm3.drop(columns="geometry")[join_keys].drop_duplicates()
# jointure interne pour compter les correspondances
shp_with_dhis2 = shp_names.merge(dhis2_admins, on=join_keys, how="inner")
# polygones sans admin DHIS2 correspondante
polygons_without_dhis2 = anti_join(shp_names, dhis2_admins, on=join_keys)
# admins DHIS2 sans polygone correspondant
dhis2_without_polygons = anti_join(dhis2_admins, shp_names, on=join_keys)
# comptes pour des diagnostics clairs
total_polygons = len(shp_adm3)
matched_polygons = len(shp_with_dhis2)
polygons_no_match = len(polygons_without_dhis2)
dhis2_no_match = len(dhis2_without_polygons)
# rapport
cli_header("Diagnostics de jointure admin (adm0 à adm3)")
cli_success(f"Unités administratives du shapefile (uniques) : {total_polygons}")
cli_success(f"Correspondant avec DHIS2 : {matched_polygons}")
cli_warning(f"Unités administratives DHIS2 non appariées (aucun polygone) : {dhis2_no_match}")
cli_warning(f"Unités administratives du shapefile non appariées (aucune entrée DHIS2) : {polygons_no_match}")
# aperçus
if len(dhis2_without_polygons) > 0:
cli_header("Admins DHIS2 sans polygone correspondant (exemple)")
print(dhis2_without_polygons.head(10))
if len(polygons_without_dhis2) > 0:
cli_header("Polygones sans correspondance DHIS2 (exemple)")
print(polygons_without_dhis2.head(10))
# définir l'emplacement du cache
cache_loc = "1.1_foundational/1d_cache_files"
# harmoniser les noms administratifs de dhis2_df en utilisant shp_adm3 comme référence
dhis2_df_cleaned = prep_geonames(
target_df=dhis2_df,
lookup_df=shp_adm3.drop(columns="geometry"),
level0="adm0",
level1="adm1",
level2="adm2",
level3="adm3",
method="lv",
cache_path=here(cache_loc, "geoname_cache.csv"),
preserve_case=True,
)
join_keys = ["adm0", "adm1", "adm2", "adm3"]
# obtenir les noms administratifs distincts de dhis2 nettoyées
dhis2_admins = dhis2_df_cleaned[join_keys].drop_duplicates()
# supprimer la géométrie pour les jointures par noms seulement
shp_names = shp_adm3.drop(columns="geometry")[join_keys].drop_duplicates()
# jointure interne pour compter les correspondances
shp_with_dhis2 = shp_names.merge(dhis2_admins, on=join_keys, how="inner")
# polygones sans admin DHIS2 correspondante
polygons_without_dhis2 = anti_join(shp_names, dhis2_admins, on=join_keys)
# admins DHIS2 sans polygone correspondant
dhis2_without_polygons = anti_join(dhis2_admins, shp_names, on=join_keys)
total_polygons = len(shp_adm3)
matched_polygons = len(shp_with_dhis2)
polygons_no_match = len(polygons_without_dhis2)
dhis2_no_match = len(dhis2_without_polygons)
cli_header("Diagnostics de jointure admin (adm0 à adm3)")
cli_success(f"Unités administratives du shapefile (uniques) : {total_polygons}")
cli_success(f"Correspondant avec DHIS2 : {matched_polygons}")
cli_warning(f"Unités administratives DHIS2 non appariées (aucun polygone) : {dhis2_no_match}")
cli_warning(f"Unités administratives du shapefile non appariées (aucune entrée DHIS2) : {polygons_no_match}")
if len(dhis2_without_polygons) > 0:
cli_header("Exemple d'unités administratives DHIS2 non appariées (10 premières)")
print(dhis2_without_polygons.head(10))
if len(polygons_without_dhis2) > 0:
cli_header("Exemple d'unités administratives du shapefile non appariées (10 premières)")
print(polygons_without_dhis2.head(10))
join_keys = ["adm0", "adm1", "adm2", "adm3"]
# joindre les données DHIS2 nettoyées au shapefile par noms administratifs
dhis2_df_coord_shp = shp_adm3.merge(
dhis2_df_cleaned,
on=join_keys,
how="left"
)
# obtenir le nombre distinct de formes jointes aux données dhis2
dist_shapes = geometry_key(dhis2_df_coord_shp.geometry).nunique()
# vérifier le résultat
cli_header("Résultat de jointure basée sur les noms")
cli_success(f"{dist_shapes} polygones joints avec succès aux données DHIS2")
# compter les coordonnées manquantes
missing_lat = dhis2_df["lat"].isna().sum()
missing_lon = dhis2_df["lon"].isna().sum()
cli_header("Vérification des coordonnées manquantes")
cli_info(f"Valeurs de latitude manquantes : {missing_lat}")
cli_info(f"Valeurs de longitude manquantes : {missing_lon}")
# filtrer les lignes où lat ou lon semble être au format DMS
dms_detected = (
dhis2_df.loc[
dhis2_df["lat"].apply(detect_dms_value)
| dhis2_df["lon"].apply(detect_dms_value),
["adm1", "adm2", "adm3", "lat", "lon"]
]
.drop_duplicates()
)
cli_header("Vérification des coordonnées DMS")
cli_info(f"Nombre de lignes avec format DMS suspecté : {len(dms_detected)}")
print(dms_detected)
# vérifier si les valeurs DMS ont été converties avec succès
check_output = (
dhis2_df.loc[
dhis2_df["lat"].apply(detect_dms_value)
| dhis2_df["lon"].apply(detect_dms_value),
["adm1", "adm2", "adm3", "lat", "lon"]
]
.drop_duplicates()
.assign(
lat_fixed=lambda x: x["lat"].apply(parse_coord),
lon_fixed=lambda x: x["lon"].apply(parse_coord),
)
)
# appliquer la conversion au jeu de données complet
dhis2_df_clean = dhis2_df.copy()
dhis2_df_clean["lat"] = dhis2_df_clean["lat"].apply(parse_coord)
dhis2_df_clean["lon"] = dhis2_df_clean["lon"].apply(parse_coord)
cli_header("Résumé de la conversion des coordonnées DMS")
check_output
# get bounding box from the shapefile
xmin, ymin, xmax, ymax = shp_adm3.total_bounds
# create flags in the main dataset
dhis2_df_flagged = dhis2_df_clean.copy()
dhis2_df_flagged["out_of_bounds"] = (
(dhis2_df_flagged["lat"] < ymin)
| (dhis2_df_flagged["lat"] > ymax)
| (dhis2_df_flagged["lon"] < xmin)
| (dhis2_df_flagged["lon"] > xmax)
)
dhis2_df_flagged["possibly_flipped"] = (
(dhis2_df_flagged["lat"] > xmin)
& (dhis2_df_flagged["lat"] < xmax)
& (dhis2_df_flagged["lon"] > ymin)
& (dhis2_df_flagged["lon"] < ymax)
)
cli_header("Vérification des coordonnées de boîte englobante")
cli_info(f"Lignes hors limites : {dhis2_df_flagged['out_of_bounds'].sum()}")
cli_info(f"Lignes possiblement inversées : {dhis2_df_flagged['possibly_flipped'].sum()}")
dhis2_df_flagged.loc[
dhis2_df_flagged["possibly_flipped"],
["adm0", "adm1", "adm2", "adm3", "lon", "lat"]
]
# reverse flipped coordinates
dhis2_df_corrected = dhis2_df_flagged.copy()
lat_temp = np.where(
dhis2_df_corrected["possibly_flipped"],
dhis2_df_corrected["lon"],
dhis2_df_corrected["lat"],
)
lon_temp = np.where(
dhis2_df_corrected["possibly_flipped"],
dhis2_df_corrected["lat"],
dhis2_df_corrected["lon"],
)
dhis2_df_corrected["lat"] = lat_temp
dhis2_df_corrected["lon"] = lon_temp
dhis2_df_corrected.loc[
dhis2_df_corrected["possibly_flipped"],
["adm0", "adm1", "adm2", "adm3", "lon", "lat"]
]
# vérifier le SCR du shapefile et attribuer une valeur par défaut si manquante
if shp_adm3.crs is None:
shp_adm3 = shp_adm3.set_crs("EPSG:4326")
shp_crs = shp_adm3.crs
# convertir les données DHIS2 en GeoDataFrame
dhis2_df_sf = gpd.GeoDataFrame(
dhis2_df_corrected.dropna(subset=["lat", "lon"]),
geometry=gpd.points_from_xy(
dhis2_df_corrected.dropna(subset=["lat", "lon"])["lon"],
dhis2_df_corrected.dropna(subset=["lat", "lon"])["lat"],
),
crs="EPSG:4326",
)
# reprojeter en cas de SCR incompatible
if dhis2_df_sf.crs != shp_crs:
dhis2_df_sf = dhis2_df_sf.to_crs(shp_crs)
cli_header("Résumé de l'alignement du SCR")
cli_info(f"SCR du shapefile : {shp_crs}")
cli_info(f"SCR des données d'intervention : {dhis2_df_sf.crs}")
crs_summary = pd.DataFrame({
"dataset": ["Shapefile", "Données ponctuelles DHIS2"],
"crs": [str(shp_crs), str(dhis2_df_sf.crs)],
})
crs_summary
fig, ax = plt.subplots(figsize=(8, 8))
# fixer l'aspect une seule fois sur l'axe ; passer aspect=None à
# gdf.plot() pour que geopandas ne recalcule pas un aspect à partir des
# limites de chaque couche (ce qui peut donner des valeurs non finies
# si une couche a une géométrie vide ou dégénérée et déclencher
# `aspect must be finite and positive`)
ax.set_aspect("equal")
shp_adm3.plot(
ax=ax, facecolor="white", edgecolor="black", linewidth=0.3, aspect=None
)
dhis2_df_sf.plot(
ax=ax, color="red", markersize=12, alpha=0.7, aspect=None
)
ax.set_title(
"centroid points within adm3 Boundaries Overlaid on Map\n"
"All points are aligned with shapefile CRS (EPSG:4326)"
)
ax.set_axis_off()
plt.show()
# get the centroid coordinates at the adm3 level
dhis2_hf_coords = (
pd.DataFrame(dhis2_df_sf.drop(columns="geometry"))
.groupby(["adm0", "adm1", "adm2", "adm3"], as_index=False)
.agg(lon=("lon", "mean"), lat=("lat", "mean"))
)
# get indicators for 2023 at adm3 level and join back coordinates
dhis2_df_sf = (
pd.DataFrame(dhis2_df_sf.drop(columns="geometry"))
[["adm0", "adm1", "adm2", "adm3", "year", "conf_u5"]]
# convertir year en chaîne pour que le filtre fonctionne que la
# colonne source soit stockée en entier ou en caractère (l'import
# rio de R conserve year en caractère)
.loc[lambda x: x["year"].astype(str) == "2023"]
.groupby(["adm0", "adm1", "adm2", "adm3", "year"], as_index=False)
.agg(conf_u5=("conf_u5", "sum"))
.merge(dhis2_hf_coords, on=["adm0", "adm1", "adm2", "adm3"], how="left")
)
dhis2_df_sf = gpd.GeoDataFrame(
dhis2_df_sf,
geometry=gpd.points_from_xy(dhis2_df_sf["lon"], dhis2_df_sf["lat"]),
crs=shp_adm3.crs,
)
# join to shapefile using spatial coordinates
dhis2_df_spatial_join = (
gpd.sjoin(
shp_adm3[["geometry"]],
dhis2_df_sf,
how="left",
predicate="contains"
)
.drop(columns="index_right", errors="ignore")
.drop_duplicates(subset=["adm0", "adm1", "adm2", "adm3", "year", "conf_u5"])
)
# vérifier les lignes non appariées
unmatched_points = dhis2_df_spatial_join.loc[dhis2_df_spatial_join["adm3"].isna()]
cli_header("Validation de la jointure spatiale")
cli_info(f"Nombre de points non appariés : {len(unmatched_points)}")
dhis2_df_spatial_join.head()
# create 1km buffer around all administrative boundaries
shp_adm3_buffered = shp_adm3.to_crs(epsg=3857).copy()
shp_adm3_buffered["geometry"] = shp_adm3_buffered.geometry.buffer(1000)
shp_adm3_buffered = shp_adm3_buffered.to_crs(epsg=4326)
# select MALEMA chiefdom for the example
malema_original = shp_adm3.loc[shp_adm3["adm3"] == "MALEMA"]
malema_buffered = shp_adm3_buffered.loc[shp_adm3_buffered["adm3"] == "MALEMA"]
# create example point that falls just outside MALEMA but within the buffer zone
example_point = gpd.GeoDataFrame(
{"lon": [-10.85], "lat": [7.641]},
geometry=gpd.points_from_xy([-10.85], [7.641]),
crs="EPSG:4326"
)
fig, ax = plt.subplots(figsize=(10, 8))
# fixer l'aspect une seule fois sur l'axe et désactiver le calcul
# d'aspect de geopandas pour qu'une couche dégénérée ne déclenche pas
# `aspect must be finite and positive`
ax.set_aspect("equal")
malema_buffered.plot(
ax=ax, color="red", alpha=0.3, edgecolor="red", linewidth=0.8, aspect=None
)
malema_original.plot(
ax=ax, color="lightblue", edgecolor="darkblue", linewidth=1, aspect=None
)
example_point.plot(ax=ax, color="black", markersize=35, aspect=None)
ax.set_title(
"Exemple de limite administrative avec tampon\n"
"Limite d'origine (bleu) avec zone tampon de 1 km (rouge) et point d'exemple (noir)"
)
ax.set_axis_off()
plt.show()
# join using buffered shapefile
dhis2_df_coord_shp_buff = (
gpd.sjoin(
shp_adm3_buffered[["geometry"]],
dhis2_df_sf,
how="left",
predicate="contains"
)
.drop(columns="index_right", errors="ignore")
.drop_duplicates()
)
# name-based join result from Step 4.5
name_join_result = (
pd.DataFrame(dhis2_df_coord_shp.drop(columns="geometry"))
.assign(join_method="Attribute-based Join")
[["adm0", "adm1", "adm2", "adm3", "year", "conf_u5", "join_method"]]
# convertir year en chaîne pour que le filtre fonctionne que la
# colonne source soit stockée en entier ou en caractère (l'import
# rio de R conserve year en caractère)
.loc[lambda x: x["year"].astype(str) == "2023"]
.groupby(["adm0", "adm1", "adm2", "adm3", "year", "join_method"], as_index=False)
.agg(conf_u5=("conf_u5", "sum"))
.merge(shp_adm3, on=["adm0", "adm1", "adm2", "adm3"], how="left")
)
name_join_result = gpd.GeoDataFrame(name_join_result, geometry="geometry", crs=shp_adm3.crs)
# coordinate-based join result from Step 5.3
coord_join_result = (
dhis2_df_spatial_join
.assign(join_method="Coordinate-based Join")
[["adm0", "adm1", "adm2", "adm3", "conf_u5", "join_method", "geometry"]]
.loc[lambda x: x["adm3"].notna()]
)
# bind both together
joined_plot_data = gpd.GeoDataFrame(
pd.concat([name_join_result, coord_join_result], ignore_index=True, sort=False),
geometry="geometry",
crs=shp_adm3.crs
)
# check summary statistics for conf_u5
joined_plot_data.groupby("join_method").agg(
min_conf_u5=("conf_u5", "min"),
mean_conf_u5=("conf_u5", "mean"),
max_conf_u5=("conf_u5", "max"),
n_missing=("conf_u5", lambda x: x.isna().sum()),
).reset_index()
validation_plot = plot_validation_maps(
joined_plot_data,
value_col="conf_u5",
method_col="join_method",
title="Cas confirmés de moins de 5 ans par Admin-3 en 2023",
)
plt.show()
# enregistrer le graphique
validation_plot.savefig(
here("03_output/3a_figures/shapefile_check_conf_adm3.png"),
dpi=300,
bbox_inches="tight",
)
save_path = Path(surv_path) / "processed"
save_path.mkdir(parents=True, exist_ok=True)
# save the name-based joined data
dhis2_df_coord_shp.to_file(
save_path / "sle_dhis2_df_name_joined_adm3.gpkg",
layer="name_joined_adm3",
driver="GPKG"
)
# save the coordinate-based joined data
dhis2_df_spatial_join.to_file(
save_path / "sle_dhis2_df_coord_joined_adm3.gpkg",
layer="coord_joined_adm3",
driver="GPKG"
)