# installer `pacman` si ce n'est pas déjà fait
if (!requireNamespace("pacman", quietly = TRUE)) {
install.packages("pacman")
}
# charger les paquets requis en utilisant pacman
pacman::p_load(
readxl, # lire les fichiers Excel
tidyr, # organisation des données
sf, # gérer les données shapefile
dplyr, # manipulation des données
ggplot2, # traçage
viridis, # palettes de couleurs
shadowtext, # étiquettes de tracé
cli, # sortie console stylisée
here, # gestion des chemins de fichiers
stringr # nettoyage des chaînes de caractères
)Utilisation et visualisation de base des shapefiles
Débutant
Aperçu
Dans le contexte SNT, disposer de shapefiles officiels, précis et à jour est important. Ces fichiers constituent la base permettant de relier les données aux unités géographiques. Cette page fournit un guide étape par étape sur la manière de charger, visualiser et utiliser efficacement les données shapefile.
La visualisation efficace des shapefiles remplit deux objectifs critiques dans le SNT :
- Valider l’intégrité géométrique des limites elles-mêmes
- Fournir le cadre spatial pour toutes les analyses de données ultérieures
Un shapefile bien préparé doit s’afficher clairement aux échelles nationale et infranationale, avec des limites qui s’alignent précisément avec les caractéristiques géographiques et les divisions administratives connues.
TipEn savoir plus sur les données spatiales
Pour des informations générales sur les shapefiles et des liens vers tout le contenu sur les données spatiales dans la bibliothèque de code SNT, y compris les rasters et les données ponctuelles, veuillez consulter Aperçu des données spatiales. Pour des suggestions sur le dépannage de votre shapefile, veuillez consulter Gestion et personnalisation des shapefiles.
NoteObjectifs
- Importer les shapefiles nettoyés et traités produits dans Gestion et personnalisation des shapefiles
- Créer des cartes de base à partir des données shapefile
- Superposer plusieurs niveaux administratifs
- Utiliser les shapefiles pour visualiser différents types de données
Utilisation des bons shapefiles
ImportantConsultez l’équipe SNT
Tous les shapefiles ne conviennent pas au SNT.
L’une des premières étapes clés avant le lancement de toute analyse SNT est la discussion au sein de l’équipe SNT concernant la plus petite unité administrative opérationnelle pour la prise de décision dans le pays où des interventions spécifiques peuvent être mises en œuvre de manière réalisable. Nous devons toujours confirmer cette décision avant d’entreprendre l’analyse, ou engager une discussion si cela n’a pas encore eu lieu. L’unité d’analyse affecte l’unité de collecte de données et l’échelle géographique à laquelle l’analyse est menée. Cette dernière déterminera le shapefile utilisé pour le SNT.
Tous les shapefiles utilisés dans le SNT doivent être examinés et validés par l’équipe SNT et doivent représenter l’ensemble officiel des limites nationales. Cela garantit l’alignement avec les normes nationales, l’exactitude des limites et évite les divergences dans les données spatiales.
N’oubliez pas de demander également tous les shapefiles officiels de niveaux supérieurs (moins granulaires) que le shapefile de l’unité d’analyse choisie. Par exemple, si l’équipe SNT a sélectionné adm2 comme unité d’analyse, vous aurez également besoin des shapefiles adm1. Ceci est important car les cartes de sortie pour le SNT doivent toujours inclure toutes les limites officielles pour faciliter l’interprétation.
Si une combinaison personnalisée de shapefiles (par exemple, un mélange d’adm2 et d’adm3) est requise pour le SNT, veuillez consulter Gestion et personnalisation des shapefiles.
Étape par étape
Dans cette section, nous parcourons les étapes essentielles pour charger et visualiser les données shapefile.
L’exemple utilise des shapefiles de limites administratives de la Sierra Leone, en se concentrant sur les niveaux de chefferie (adm3) et de district (adm2). Les principes peuvent être appliqués aux shapefiles de n’importe quel pays.
Pour ignorer l’explication étape par étape, passez au code complet à la fin de cette page.
Étape 1 : Installer et charger les paquets
Tout d’abord, installez et chargez les paquets nécessaires pour gérer les données spatiales, la manipulation des données et la visualisation. Ces bibliothèques fournissent des fonctions essentielles pour travailler avec des données spatiales.
Le paquet sf est particulièrement important car il implémente des normes de fonctionnalités simples pour la gestion des données vectorielles géographiques dans R.
Pour adapter le code :
- Ne modifiez rien dans le code ci-dessus
WarningInstallation en ligne de commande requise
Installez les paquets dans votre terminal, s’ils ne sont pas déjà installés. Si vous avez besoin d’aide pour installer des paquets, veuillez consulter la page Premiers pas.
from pathlib import Path
import geopandas as gpd
import matplotlib.colors as mcolors
import matplotlib.patches as mpatches
import matplotlib.patheffects as path_effects
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pyreadr
from matplotlib.cm import ScalarMappable
from matplotlib_scalebar.scalebar import ScaleBar
from pyprojroot import here
def read_rds(path):
"""lire un fichier RDS à objet unique en tant qu'objet pandas."""
result = pyreadr.read_r(str(path))
return next(iter(result.values()))
def ensure_output_dir(path):
"""créer le répertoire parent avant d'enregistrer des figures ou des données."""
Path(path).parent.mkdir(parents=True, exist_ok=True)
def add_title(ax, title=None, subtitle=None):
"""utiliser un bloc de titre matplotlib pour correspondre à la sortie titre/sous-titre de ggplot."""
if title and subtitle:
ax.set_title(f"{title}\n{subtitle}", loc="left", fontsize=14, fontweight="bold")
elif title:
ax.set_title(title, loc="left", fontsize=14, fontweight="bold")
def finish_map(ax, title=None, subtitle=None):
"""appliquer le style de carte statique partagé utilisé sur cette page."""
add_title(ax, title, subtitle)
ax.set_axis_off()
def save_figure(fig, filename, width, height, dpi=300):
"""enregistrer une figure matplotlib avec des dimensions correspondant aux exemples R."""
ensure_output_dir(filename)
fig.set_size_inches(width, height)
fig.savefig(filename, dpi=dpi, bbox_inches="tight")
def label_points(ax, data, label_col, x_col="lon", y_col="lat", dy=0.08, size=8):
"""ajouter des étiquettes de points avec un halo blanc pour la lisibilité."""
for _, row in data.iterrows():
text = ax.text(
row[x_col],
row[y_col] + dy,
row[label_col],
ha="center",
va="center",
fontsize=size,
fontweight="bold",
color="black",
)
text.set_path_effects([
path_effects.Stroke(linewidth=3, foreground="white"),
path_effects.Normal(),
])
def legend_patches(palette, labels=None):
"""créer des poignées de légende catégorielle à partir d'un dictionnaire de couleurs nommé."""
labels = labels or {}
return [
mpatches.Patch(facecolor=color, edgecolor="black", label=labels.get(key, key))
for key, color in palette.items()
]
def add_bottom_legend(ax, handles, title=None, ncol=None):
"""placer une légende horizontale compacte sous une carte."""
ncol = ncol or len(handles)
ax.legend(
handles=handles,
title=title,
loc="lower center",
bbox_to_anchor=(0.5, -0.10),
ncol=ncol,
frameon=False,
fontsize=8,
title_fontsize=9,
)
def plot_binned_map(ax, data, fill_col, palette, title=None, subtitle=None,
overlay=None, overlay_color="black", overlay_width=0.5):
"""dessiner une carte choroplèthe binée avec une légende en bas et une superposition optionnelle."""
plot_colors = data[fill_col].map(palette).fillna("#E5E5E5")
data.plot(
ax=ax,
color=plot_colors,
edgecolor="white",
linewidth=0.2,
)
if overlay is not None:
overlay.plot(ax=ax, facecolor="none", edgecolor=overlay_color, linewidth=overlay_width)
finish_map(ax, title, subtitle)
present_keys = [key for key in palette if key in set(data[fill_col].dropna().astype(str))]
handles = legend_patches({key: palette[key] for key in present_keys})
add_bottom_legend(ax, handles, title="Taux de positivité des tests (%)", ncol=len(handles))
def plot_gradient_map(ax, data, fill_col, colors, title=None, subtitle=None,
overlay=None, legend_label="Taux de positivité des tests (%)",
vmin=0, vmax=100):
"""dessiner une carte choroplèthe continue avec une barre de couleur horizontale."""
cmap = mcolors.LinearSegmentedColormap.from_list("snt_gradient", colors)
data.plot(
ax=ax,
column=fill_col,
cmap=cmap,
vmin=vmin,
vmax=vmax,
edgecolor="white",
linewidth=0.2,
missing_kwds={"color": "#E5E5E5"},
)
if overlay is not None:
overlay.plot(ax=ax, facecolor="none", edgecolor="black", linewidth=0.5)
finish_map(ax, title, subtitle)
sm = ScalarMappable(norm=mcolors.Normalize(vmin=vmin, vmax=vmax), cmap=cmap)
sm.set_array([])
cbar = ax.figure.colorbar(sm, ax=ax, orientation="horizontal", fraction=0.04, pad=0.04)
cbar.set_label(legend_label, fontweight="bold")
snt_palettes = {
"blues": ["#deebf7", "#c6dbef", "#9ecae1", "#6baed6", "#4292c6", "#2171b5", "#08519c"],
"ylord": ["#ffffcc", "#ffeda0", "#fed976", "#feb24c", "#fd8d3c", "#fc4e2a", "#bd0026"],
"viridis": [
"#440154", "#482878", "#3e4a89", "#31688e", "#26828e",
"#1f9e89", "#35b779", "#6ece58", "#b5de2b", "#fde725"
],
"byor": [
"#1a5276", "#2980b9", "#5dade2", "#85c1e9", "#aed6f1",
"#d6eaf8", "#f7dc6f", "#e67e22", "#c0392b", "#7b0d0d"
],
"rdbu": ["#b2182b", "#d6604d", "#f4a582", "#fddbc7", "#d1e5f0", "#92c5de", "#4393c3", "#2166ac"],
"spectral": ["#d53e4f", "#f46d43", "#fdae61", "#fee08b", "#e6f598", "#abdda4", "#66c2a5", "#3288bd"],
"set2": ["#66c2a5", "#fc8d62", "#8da0cb", "#e78ac3", "#a6d854", "#ffd92f"],
"accent": ["#7fc97f", "#beaed4", "#fdc086", "#ffff99", "#386cb0", "#f0027f"],
}
tpr_bin_labels = [
"0-10", "10-20", "20-30", "30-40", "40-50",
"50-60", "60-70", "70-80", "80-90", "90-100"
]
tpr_bin_palette = dict(zip(tpr_bin_labels, snt_palettes["byor"]))
tpr_gradient_colors = [
"#1a5276", "#5dade2", "#d6eaf8", "#f7dc6f",
"#e67e22", "#c0392b", "#7b0d0d"
]Pour adapter le code :
- Conservez ces importations et fonctions d’aide en haut du flux de travail Python. Les blocs Python ultérieurs les utilisent pour lire les fichiers spatiaux, faire correspondre les styles de carte, créer des légendes et enregistrer des figures.
Étape 2 : Importer les shapefiles
Dans cette étape, nous chargeons les objets spatiaux adm3 (Chefferie) et adm2 (District) nettoyés et traités, produits dans la page Gestion et personnalisation des shapefiles. Ces fichiers ont été enregistrés au format .rds avec la nomenclature standard adm0 / adm1 / adm2 / adm3 et un CRS cohérent, de sorte qu’aucun renommage ou transformation supplémentaire n’est nécessaire ici.
Afficher le code
# définir le chemin spatial
spat_path <- here::here(
"1.1_foundational",
"1.1a_administrative_boundaries"
)
# charger l'objet spatial chefferie (adm3) traité
gdf <- readRDS(
here::here(spat_path, "processed", "sle_spatial_adm3_2021.rds")
) |>
# garantir que la sortie reste un objet sf valide pour usage en aval
sf::st_as_sf()
# charger l'objet spatial district (adm2) traité
adm2_gdf <- readRDS(
here::here(spat_path, "processed", "sle_spatial_adm2_2021.rds")
) |>
sf::st_as_sf()
# charger l'objet spatial région (adm1) traité, utilisé comme
# superposition de niveau supérieur dans les cartes choroplèthes
# à partir de l'Étape 4
adm1_gdf <- readRDS(
here::here(spat_path, "processed", "sle_spatial_adm1_2021.rds")
) |>
sf::st_as_sf()Pour adapter le code :
- Lignes 2–5 : Mettre à jour
spat_pathpour pointer vers le dossier où vos fichiers spatiaux.rdstraités sont stockés - Lignes 9 et 16 : Remplacer
"sle_spatial_adm3_2021.rds"et"sle_spatial_adm2_2021.rds"par vos noms de fichiers traités issus de l’étape Gestion et personnalisation des shapefiles
Afficher le code
# définir le chemin spatial
spat_path = here("1.1_foundational/1.1a_administrative_boundaries/processed")
# charger l'objet spatial chiefdom (adm3) traité
gdf = gpd.read_file(Path(spat_path) / "sle_spatial_adm3_2021.geojson")
# charger l'objet spatial district (adm2) traité
adm2_gdf = gpd.read_file(Path(spat_path) / "sle_spatial_adm2_2021.geojson")
# charger l'objet spatial region (adm1) traité, utilisé comme superposition de niveau supérieur
# dans les cartes choroplèthes à partir de l'Étape 4
adm1_gdf = gpd.read_file(Path(spat_path) / "sle_spatial_adm1_2021.geojson")Pour adapter le code :
- Ligne 2 : Mettre à jour
spat_pathpour pointer vers le dossier où vos fichiers spatiaux traités sont stockés - Lignes 5, 8 et 12 : Remplacer les noms de fichiers GeoJSON par vos noms de fichiers traités de l’étape Gestion et personnalisation des shapefiles
Étape 3 : Visualiser le contenu du shapefile
Une inspection approfondie des données d’attributs et des géométries aide à identifier les problèmes avant qu’ils n’affectent l’analyse, tels que :
- Incompatibilités administratives : divergences entre les noms d’unités administratives dans le shapefile par rapport aux autres données
- Artefacts géométriques : lacunes, chevauchements ou polygones invalides pouvant perturber les opérations spatiales
- Incohérences CRS : systèmes de coordonnées qui ne correspondent pas aux autres ensembles de données du programme
Cette page suppose que vous travaillez avec un shapefile propre et bien formaté. Bien que quelques conseils de dépannage soient présentés ci-dessous, veuillez consulter Gestion et personnalisation des shapefiles pour des suggestions supplémentaires sur l’inspection, le dépannage et le nettoyage de votre shapefile.
La cartographie initiale sert d’outil de diagnostic. L’inspection visuelle peut révéler des problèmes tels que des formes de limites implausibles ou des enclaves mal alignées. Un shapefile propre devrait :
- Maintenir des limites nettes à tous les niveaux
- Préserver les relations topologiques (aucun polygone qui se chevauche)
- S’aligner avec les limites géographiques connues
- Afficher les données d’attributs sans artefacts de rendu
Dans cette étape, nous générons des cartes pour représenter visuellement les données spatiales, en commençant par une carte de base d’un seul niveau administratif. Ce code génère les limites administratives au niveau de la chefferie (adm3) pour la Sierra Leone.
Étape 3.1 : Carte de base des unités administratives
Afficher le code
# thème de carte partagé réutilisé par chaque carte de cette page
# (theme_void() supprime les axes/la grille par défaut ; le bloc theme
# ci-dessous contrôle les polices, tailles, mise en page de la légende
# et marges, afin que chaque tracé des Étapes 3 à 5 ait la même
# apparence)
snt_map_theme <- function() {
ggplot2::theme_void() +
ggplot2::theme(
legend.position = "bottom",
legend.direction = "horizontal",
# le titre se place au-dessus des cases de la légende, les
# étiquettes des graduations en dessous
legend.title.position = "top",
legend.text.position = "bottom",
legend.title = ggplot2::element_text(
face = "bold",
size = 10,
hjust = 0.5,
margin = ggplot2::margin(b = 6)
),
legend.box.margin = ggplot2::margin(t = 8),
# une largeur de clé étroite garde les légendes sur une seule
# ligne compactes même avec beaucoup de classes ; les Étapes
# 4.3 / 4.6 / 5.2 / 5.3 / 5.4 dépendent toutes de ce défaut
legend.key.width = grid::unit(0.9, "cm"),
strip.text = ggplot2::element_text(
face = "bold",
size = 10,
margin = ggplot2::margin(t = 2, b = 6, l = 4, r = 4)
),
strip.text.y = ggplot2::element_text(angle = -90),
panel.spacing = grid::unit(4, "pt"),
plot.title = ggplot2::element_text(
face = "bold",
size = 14,
margin = ggplot2::margin(b = 8)
),
plot.subtitle = ggplot2::element_text(
size = 11,
margin = ggplot2::margin(b = 10)
),
plot.margin = ggplot2::margin(t = 5, r = 5, b = 5, l = 5)
)
}
# tracer le shapefile de chefferie
basic_map <- ggplot2::ggplot() +
ggplot2::geom_sf(
data = gdf,
fill = "lightblue",
color = "black"
) +
ggplot2::labs(
title = "Carte des chefferies de Sierra Leone (adm3)",
subtitle = "limites adm3"
) +
snt_map_theme()
# enregistrer le tracé
ggplot2::ggsave(
plot = basic_map,
filename = here::here("03_output", "3a_figures", "basic_map.png"),
width = 10,
height = 8,
dpi = 300
)
NoteSortie
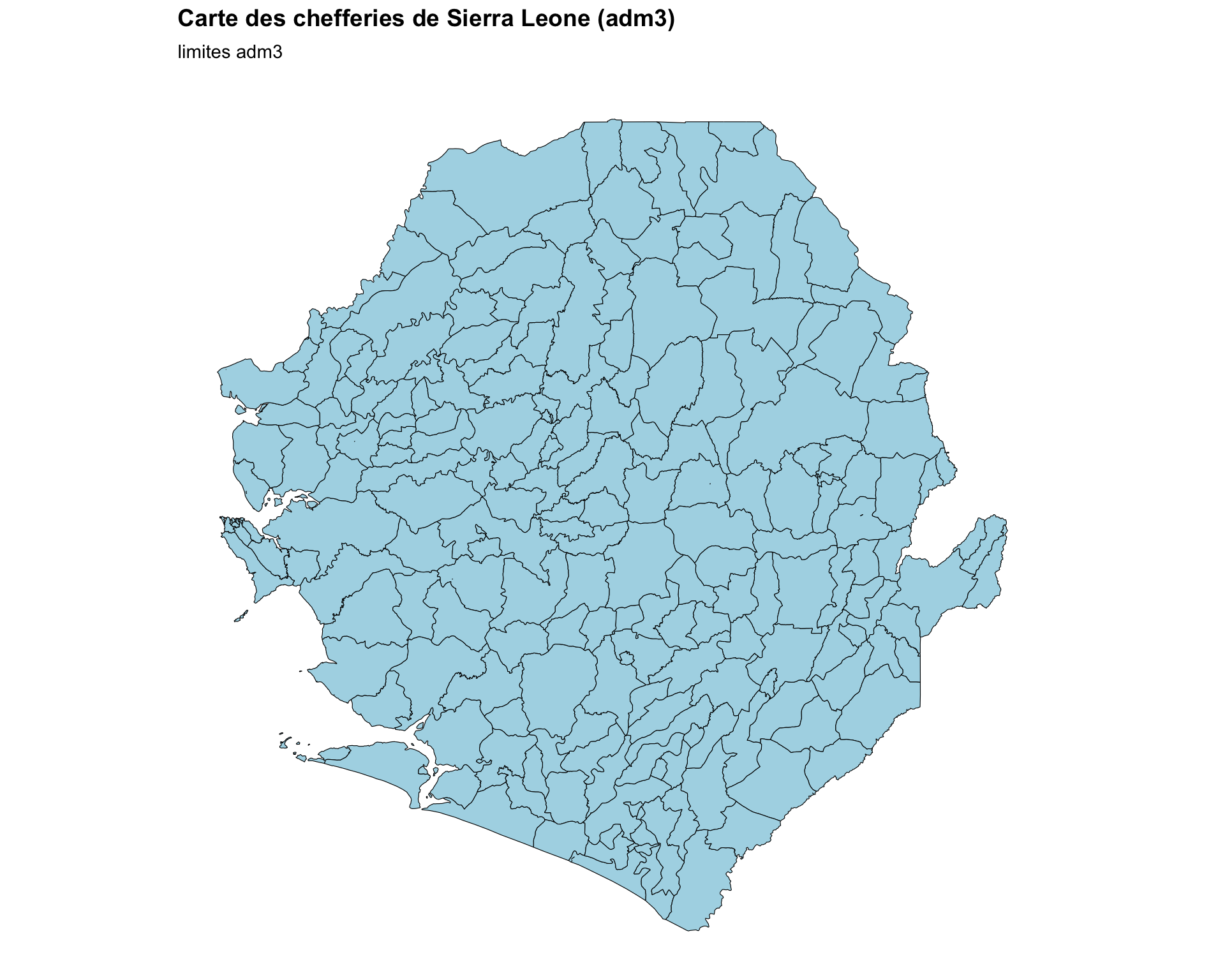
Pour adapter le code :
- Lignes 17–21 : Ajuster
filletcolordansgeom_sf()pour répondre à vos préférences - Lignes 22–25 : Modifier
titleetsubtitledu tracé pour refléter le pays que vous cartographiez - Lignes 30–35 : Ajuster
width,heightetdpidansggsave()en fonction de vos besoins de sortie
Afficher le code
fig, ax = plt.subplots(figsize=(10, 8))
gdf.plot(ax=ax, facecolor="lightblue", edgecolor="black", linewidth=0.6)
finish_map(
ax,
title="Carte des chefferies de la Sierra Leone (adm3)",
subtitle="limites adm3"
)
# enregistrer le tracé
save_figure(
fig,
here("03_output/3a_figures/basic_map.png"),
width=10,
height=8,
dpi=300
)
plt.show()
NoteSortie
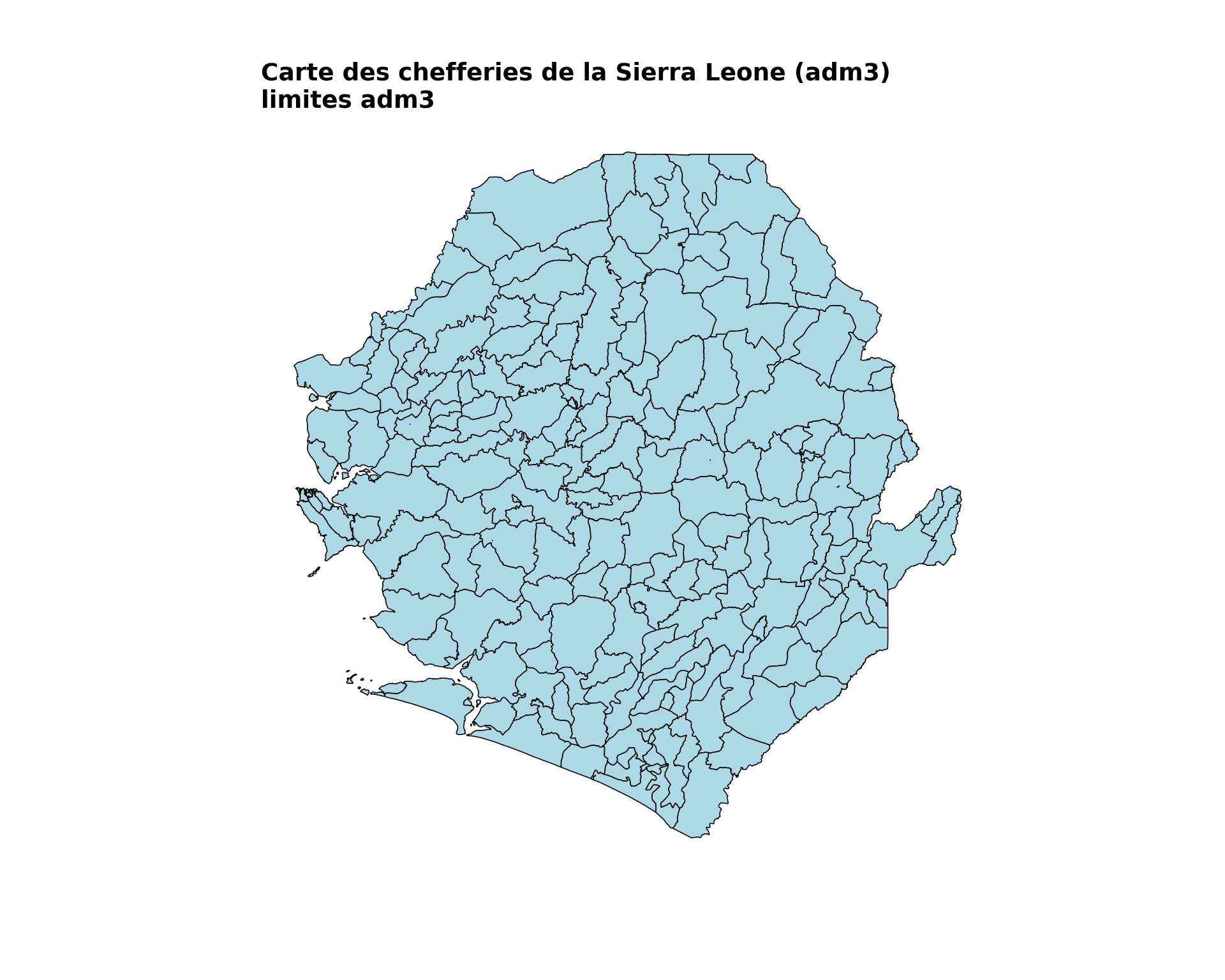
Pour adapter le code :
- Ligne 8 : Ajuster
facecoloretedgecolordans.plot()pour correspondre à vos préférences - Lignes 10–13 : Modifier
titleetsubtitlepour refléter le pays que vous cartographiez - Lignes 17–22 : Ajuster
width,heightetdpidanssave_figure()en fonction de vos besoins de sortie
ImportantValider avec l’équipe SNT
Avant de poursuivre l’analyse, partagez vos cartes shapefile avec l’équipe SNT pour validation. L’équipe aidera à garantir que :
- Les shapefiles représentent avec précision les limites administratives actuelles
- Les limites s’alignent avec les unités opérationnelles pour la prise de décision
- Il n’y a pas de divergences entre les données shapefile et les limites officielles
- Toutes les décisions de cartographie (couleurs, étiquettes, symbologie) sont cohérentes avec les normes du programme
Cette étape de validation est cruciale pour maintenir l’intégrité des données tout au long du processus SNT.
Étape 3.2 : Superposer plusieurs niveaux administratifs
Pour ajouter plus d’informations contextuelles sur la carte précédente, nous superposons les limites et les étiquettes adm2 au-dessus de la carte adm3 existante.
Ce tracé utilise shadowtext::geom_shadowtext pour améliorer la lisibilité des étiquettes adm2.
Afficher le code
# calculer les positions des étiquettes une seule fois pour qu'elles
# restent à l'intérieur de chaque polygone de district
adm2_labels <- adm2_gdf |>
dplyr::mutate(
.lab_xy = sf::st_point_on_surface(geometry),
lon = sf::st_coordinates(.lab_xy)[, 1],
lat = sf::st_coordinates(.lab_xy)[, 2]
) |>
sf::st_drop_geometry()
overlay_map <- ggplot2::ggplot() +
# chefferies adm3 : remplissage doux avec contours discrets mais visibles
ggplot2::geom_sf(
data = gdf,
fill = "#EAF0F4",
color = "#A3B6C2",
linewidth = 0.2
) +
# districts adm2 : pas de remplissage, contour foncé fin pour ancrer
# la superposition
ggplot2::geom_sf(
data = adm2_gdf,
fill = NA,
color = "#1F3A57",
linewidth = 0.45
) +
# étiquettes adm2 avec un halo blanc marqué pour la lisibilité
shadowtext::geom_shadowtext(
data = adm2_labels,
ggplot2::aes(x = lon, y = lat, label = adm2),
color = "#1F3A57",
bg.color = "white",
bg.r = 0.18,
size = 3.6,
fontface = "bold"
) +
ggplot2::labs(
title = "Superposition des limites administratives de la Sierra Leone",
subtitle = "Districts (adm2) et chefferies (adm3)"
) +
snt_map_theme()
# enregistrer le tracé
ggplot2::ggsave(
plot = overlay_map,
filename = here::here("03_output", "3a_figures", "overlay_map.png"),
width = 10,
height = 8,
dpi = 300
)
NoteSortie
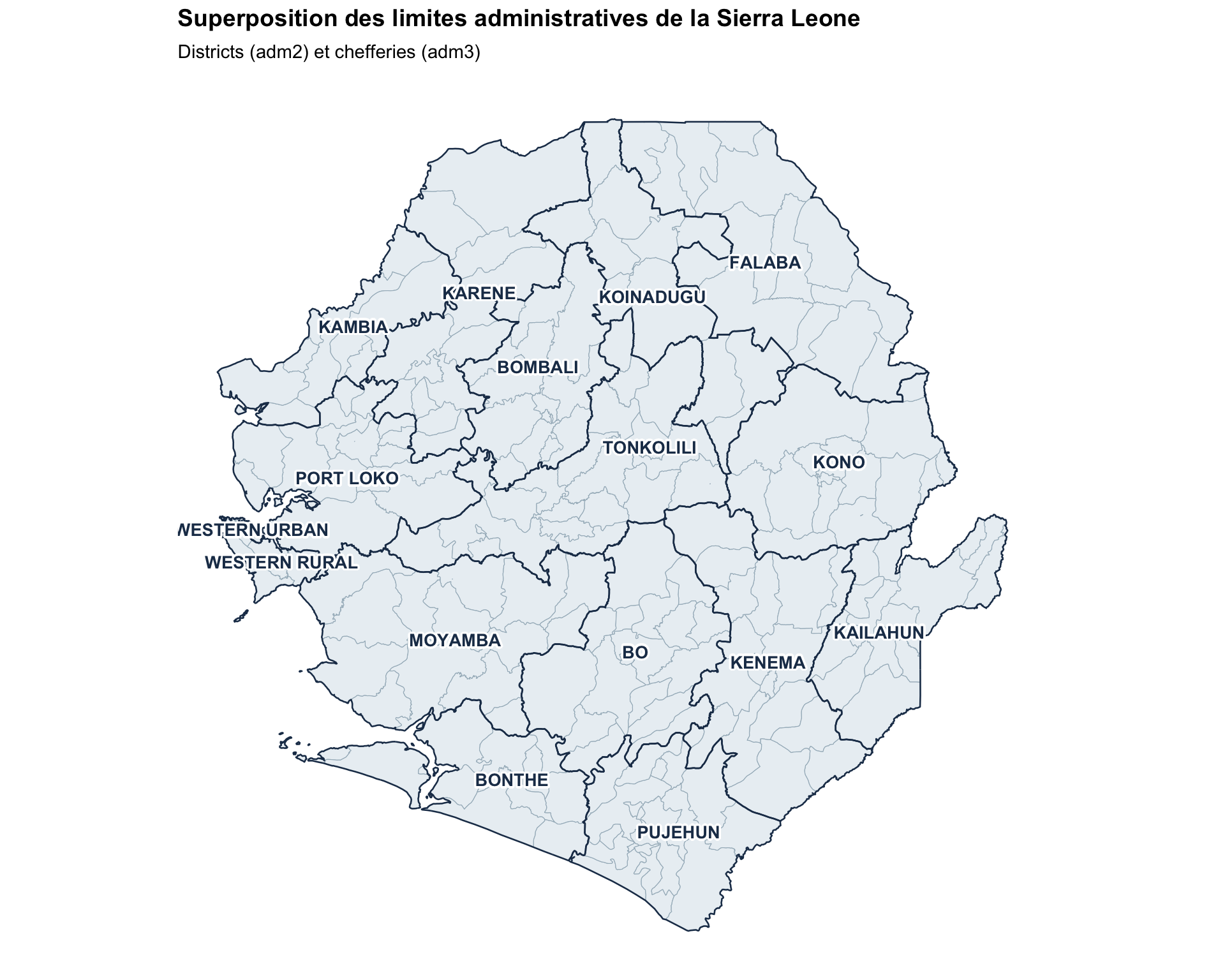
Pour adapter le code :
- Lignes 14–16 : Ajuster
fill,coloretlinewidthpouradm3selon vos préférences - Lignes 22–23 : Ajuster
coloretlinewidthdu contouradm2pour l’accentuation visuelle - Ligne 28 : Mettre à jour l’esthétique
labeldansgeom_shadowtext()pour correspondre à la colonne de vos données contenant les noms d’unités - Lignes 29–33 : Ajuster
color,bg.color,bg.r(rayon du halo) etsizedes étiquettes pour la lisibilité - Lignes 36–37 : Modifier
titleetsubtitledu tracé en fonction des données du pays que vous utilisez - Pour visualiser plus de deux niveaux administratifs, ajoutez des couches
geom_sf()supplémentaires
Ce tracé utilise des points représentatifs et des étiquettes de texte avec halo pour améliorer la lisibilité des étiquettes adm2.
Afficher le code
# calculer les positions des étiquettes une fois pour que les étiquettes restent à l'intérieur de chaque polygone de district
adm2_labels = adm2_gdf.copy()
adm2_points = adm2_labels.geometry.representative_point()
adm2_labels["lon"] = adm2_points.x
adm2_labels["lat"] = adm2_points.y
fig, ax = plt.subplots(figsize=(10, 8))
# chefferies adm3 : remplissage doux avec des contours subtils mais visibles
gdf.plot(ax=ax, facecolor="#EAF0F4", edgecolor="#A3B6C2", linewidth=0.2)
# districts adm2 : pas de remplissage, contour sombre mince pour ancrer la superposition
adm2_gdf.plot(ax=ax, facecolor="none", edgecolor="#1F3A57", linewidth=0.45)
# étiquettes adm2 avec un fort halo blanc pour la lisibilité
label_points(ax, adm2_labels, label_col="adm2", size=8)
finish_map(
ax,
title="Superposition des limites administratives de la Sierra Leone",
subtitle="Districts (adm2) et chefferies (adm3)"
)
# enregistrer le tracé
save_figure(
fig,
here("03_output/3a_figures/overlay_map.png"),
width=10,
height=8,
dpi=300
)
plt.show()
NoteSortie
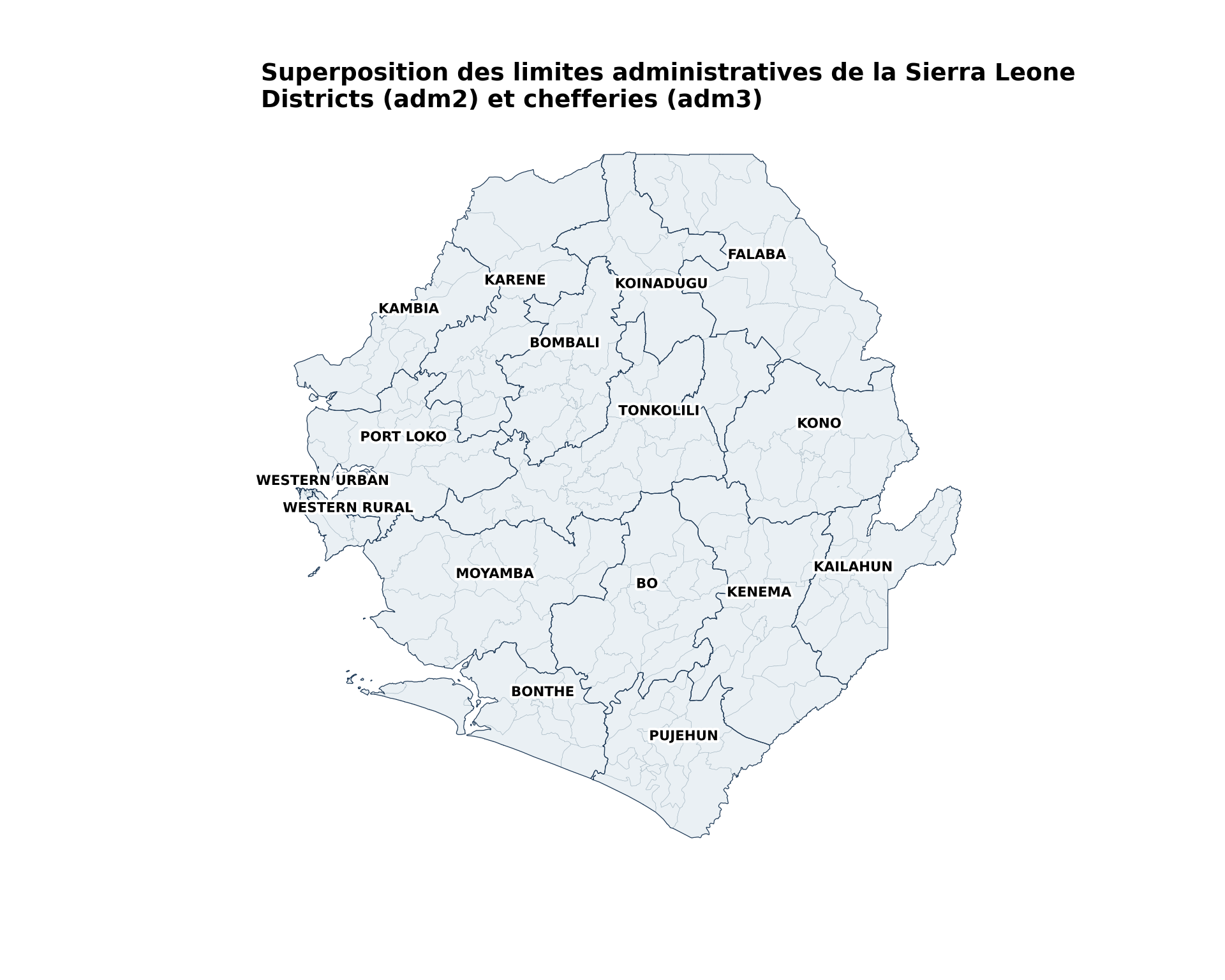
Pour adapter le code :
- Ligne 15 : Ajuster
facecolor,edgecoloretlinewidthdeadm3pour correspondre à vos préférences - Ligne 18 : Ajuster
edgecoloretlinewidthdu contouradm2pour l’emphase visuelle - Ligne 21 : Mettre à jour
label_colpour correspondre à la colonne de vos données contenant les noms d’unités - Lignes 23–27 : Modifier
titleetsubtitledu tracé en fonction des données du pays que vous utilisez - Pour visualiser plus de deux niveaux administratifs, ajoutez des couches
.plot()supplémentaires
Étape 3.3 : Dépannage des problèmes de visualisation
Le tableau ci-dessous présente les problèmes qui peuvent être rencontrés lors d’une tentative de visualisation, leurs causes probables et les corrections recommandées. Veuillez consulter Gestion et personnalisation des shapefiles pour des suggestions supplémentaires sur l’inspection, le dépannage et le nettoyage de votre shapefile.
Problèmes de visualisation courants et solutions| Symptôme | Cause probable | Vérification diagnostique (R / Python) | Solution immédiate (R / Python) |
|---|---|---|---|
| Polygones manquants | Géométries invalides | R : sum(!sf::st_is_valid(gdf)) Python : (~gdf.is_valid).sum() |
R : gdf <- sf::st_make_valid(gdf) Python : gdf["geometry"] = gdf.make_valid() |
| Forme de pays déformée | CRS incorrect | R : sf::st_crs(gdf)$input Python : gdf.crs |
R : sf::st_transform(gdf, 4326) Python : gdf = gdf.to_crs(4326) |
| Carte de sortie vide | Géométries vides | R : sum(sf::st_is_empty(gdf)) Python : gdf.is_empty.sum() |
R : gdf <- gdf[!sf::st_is_empty(gdf), ] Python : gdf = gdf[~gdf.is_empty] |
| Étiquettes mal alignées | Incompatibilité CRS | Comparer R : sf::st_crs() / Python : gdf.crs des couches |
Reprojeter les deux sur le même CRS (R : sf::st_transform() ; Python : gdf.to_crs()) |
| Limites dentelées | Géométries trop simplifiées | R : mapview::npts(gdf) Python : gdf.geometry.apply(lambda g: len(g.exterior.coords) if g.geom_type == "Polygon" else 0).sum() |
Réduire dTolerance (R : sf::st_simplify()) / tolerance (Python : gdf.simplify()) |
WarningBonnes pratiques lors de la modification des shapefiles
Lors du dépannage des shapefiles, assurez-vous de :
- Créer une copie de sauvegarde des données shapefile originales avant de modifier les géométries
- Documenter toutes les modifications apportées au shapefile original
- Vérifier les réparations et le shapefile résultant avec l’équipe SNT avant de procéder à l’analyse
Étape 4 : Utilisation et visualisation avancées des shapefiles
Les techniques avancées pour visualiser les shapefiles transmettent plus d’informations grâce à des éléments de tracé supplémentaires. Pour cet exemple, nous utilisons les données fusionnées shapefile-tabulaires de la Sierra Leone. Voir Fusion de vecteurs spatiaux avec des données tabulaires sur la façon de fusionner des tableaux de données d’unités administratives avec votre shapefile pour préparer la visualisation.
Les exemples d’ensembles de données fusionnées démontrent comment les shapefiles passent de cartes de base à des outils analytiques. Lors de la visualisation de données d’indicateurs :
- Les limites administratives fournissent le cadre spatial
- Les échelles de couleurs représentent les valeurs d’indicateurs
- La hiérarchie est maintenue grâce à un ordre de couches soigneux
Étape 4.1 : Charger et préparer les données fusionnées pour les visualisations avancées
Nous chargeons d’abord les données nécessaires pour créer des visualisations shapefile avancées. Cette étape charge à la fois les données d’intervention catégorielles et les données DHIS2, qui sont ensuite fusionnées avec le shapefile. Les étapes de fusion ont été adaptées de la page Fusion de vecteurs spatiaux avec des données tabulaires de cette bibliothèque.
Nous utilisons dplyr::inner_join qui ne conserve que les enregistrements parfaitement correspondants. Si vous devez conserver toutes les unités shapefile même lorsque des données sont manquantes, envisagez dplyr::left_join et gérez les valeurs NA de manière appropriée.
Afficher le code
# charger les données d'intervention catégorielles
# le fichier Excel contient une colonne `adm3` verbeuse (style "Dea Chiefdom")
# et une colonne `FIRST_CHIE` brute ("DEA"). supprimer la colonne verbeuse
# et utiliser le code brut pour correspondre au champ `adm3` du shapefile
categorical_intervention_data <- readxl::read_excel(
here::here(
"1.2_epidemiology",
"1.2a_routine_surveillance",
"processed",
"scenario_with_irs_no_smc_06_20_2025.xlsx"
)
) |>
dplyr::select(-dplyr::any_of("adm3")) |>
dplyr::rename(
adm2 = FIRST_DNAM,
adm3 = FIRST_CHIE
)
# diagnostiquer la couverture de jointure par noms uniquement à adm2-adm3
shp_names_cat <- gdf |>
sf::st_drop_geometry() |>
dplyr::distinct(adm1, adm2, adm3)
shp_with_cat <- shp_names_cat |>
dplyr::inner_join(
categorical_intervention_data |>
dplyr::distinct(adm2, adm3),
by = c("adm2", "adm3")
)
cli::cli_h2("Diagnostics de jointure d'intervention catégorielle")
cli::cli_alert_success(
"Correspondances exactes entre adm2-adm3: {nrow(shp_with_cat)}"
)
# effectuer maintenant la fusion réelle avec les niveaux administratifs 2-3
gdf_cat_joined <- gdf |>
dplyr::inner_join(
categorical_intervention_data,
by = c("adm2", "adm3")
) |>
sf::st_as_sf()
cli::cli_alert_success(
"Nombre de lignes fusionnées final pour les données d'intervention: {nrow(gdf_cat_joined)}"
)
#==============================================================================#
# charger les données DHIS2 et filtrer à l'année de travail au moment
# de la lecture afin de ne jamais conserver l'ensemble multi-années en mémoire
sle_dhis2_df_coord_spatial_adm3 <- readRDS(
here::here(
"1.2_epidemiology",
"1.2a_routine_surveillance",
"processed",
"sle_dhis2_df_coord_spatial_adm3.rds"
)
) |>
dplyr::filter(year == "2022")
# agréger aux totaux annuels par chefferie pour que chaque chefferie apparaisse une fois
# (plutôt qu'une fois par mois) avant la jointure
sle_dhis2_2022_annual <- sle_dhis2_df_coord_spatial_adm3 |>
dplyr::group_by(adm0, adm1, adm2, adm3) |>
dplyr::summarise(
dplyr::across(
c(conf, test, conf_u5, test_u5,
conf_5_14, test_5_14, conf_ov15, test_ov15),
~ sum(.x, na.rm = TRUE)
),
.groups = "drop"
)
# diagnostiquer la couverture de jointure par noms uniquement à adm1-adm3
dhis2_admins <- sle_dhis2_2022_annual |>
dplyr::distinct(adm1, adm2, adm3)
shp_names <- gdf |>
sf::st_drop_geometry() |>
dplyr::distinct(adm1, adm2, adm3)
shp_with_dhis2 <- shp_names |>
dplyr::inner_join(
dhis2_admins,
by = c("adm1", "adm2", "adm3")
)
cli::cli_h2("Diagnostics de jointure DHIS2")
cli::cli_alert_success(
"Correspondances exactes entre adm1-adm3: {nrow(shp_with_dhis2)}"
)
# effectuer maintenant la fusion réelle avec les niveaux administratifs 1-3
tabshp <- gdf |>
dplyr::inner_join(
sle_dhis2_2022_annual,
by = c("adm0", "adm1", "adm2", "adm3")
) |>
sf::st_as_sf()
cli::cli_alert_success(
"Nombre de lignes fusionnées final: {nrow(tabshp)}"
)Pour adapter le code :
- Mettre à jour les chemins de fichiers et les noms de colonnes en fonction des données que vous fusionnez
- Si votre shapefile utilise des noms d’attributs différents, ajustez l’étape
dplyr::rename()à l’Étape 2
Nous utilisons merge(..., how="inner") qui ne conserve que les enregistrements parfaitement correspondants. Si vous devez conserver toutes les unités shapefile même lorsque des données sont manquantes, envisagez how="left" et gérez les valeurs manquantes de manière appropriée.
Afficher le code
# charger les données d'intervention catégorielles
# le fichier Excel contient une colonne `adm3` verbeuse (style "Dea Chiefdom") et une
# colonne brute `FIRST_CHIE` ("DEA"). supprimer la colonne verbeuse et utiliser le code brut
# pour qu'il corresponde au champ `adm3` du shapefile
categorical_intervention_data = (
pd.read_excel(
here(
"1.2_epidemiology/1.2a_routine_surveillance/processed/"
"scenario_with_irs_no_smc_06_20_2025.xlsx"
)
)
.drop(columns=["adm3"], errors="ignore")
.rename(columns={"FIRST_DNAM": "adm2", "FIRST_CHIE": "adm3"})
)
# diagnostiquer la couverture de jointure par noms uniquement à adm2-adm3
shp_names_cat = gdf[["adm1", "adm2", "adm3"]].drop_duplicates()
shp_with_cat = shp_names_cat.merge(
categorical_intervention_data[["adm2", "adm3"]].drop_duplicates(),
on=["adm2", "adm3"],
how="inner"
)
print("Diagnostics de jointure d'intervention catégorielle")
print(f"SUCCÈS : Correspondances exactes entre adm2-adm3 : {len(shp_with_cat)}")
# effectuer la fusion réelle avec adm2-adm3
gdf_cat_joined = gdf.merge(
categorical_intervention_data,
on=["adm2", "adm3"],
how="inner"
)
gdf_cat_joined = gpd.GeoDataFrame(gdf_cat_joined, geometry="geometry", crs=gdf.crs)
print(f"SUCCÈS : Nombre de lignes fusionnées final pour les données d'intervention : {len(gdf_cat_joined)}")
# ----------------------------------------------------------------------------
# charger les données DHIS2 et filtrer à l'année de travail au moment de la lecture
# pour ne jamais conserver l'ensemble de données multi-années complet en mémoire en aval
sle_dhis2_df_coord_spatial_adm3 = (
read_rds(
here(
"1.2_epidemiology/1.2a_routine_surveillance/processed/"
"sle_dhis2_df_coord_spatial_adm3.rds"
)
)
.loc[lambda x: x["year"].astype(str) == "2022"]
)
# agréger aux totaux annuels par chefferie pour que chaque chefferie apparaisse une fois
# (plutôt qu'une fois par mois) avant la jointure
sum_cols = [
"conf", "test", "conf_u5", "test_u5",
"conf_5_14", "test_5_14", "conf_ov15", "test_ov15"
]
sle_dhis2_2022_annual = (
sle_dhis2_df_coord_spatial_adm3
.groupby(["adm0", "adm1", "adm2", "adm3"], as_index=False)[sum_cols]
.sum()
)
# diagnostiquer la couverture de jointure par noms uniquement à adm1-adm3
dhis2_admins = sle_dhis2_2022_annual[["adm1", "adm2", "adm3"]].drop_duplicates()
shp_names = gdf[["adm1", "adm2", "adm3"]].drop_duplicates()
shp_with_dhis2 = shp_names.merge(dhis2_admins, on=["adm1", "adm2", "adm3"], how="inner")
print("Diagnostics de jointure DHIS2")
print(f"SUCCÈS : Correspondances exactes entre adm1-adm3 : {len(shp_with_dhis2)}")
# effectuer la fusion réelle avec adm1-adm3
tabshp = gdf.merge(
sle_dhis2_2022_annual,
on=["adm0", "adm1", "adm2", "adm3"],
how="inner"
)
tabshp = gpd.GeoDataFrame(tabshp, geometry="geometry", crs=gdf.crs)
print(f"SUCCÈS : Nombre de lignes fusionnées final : {len(tabshp)}")Pour adapter le code :
- Mettre à jour les chemins de fichiers et les noms de colonnes en fonction des données que vous fusionnez
- Si votre shapefile utilise des noms d’attributs différents, ajustez l’étape
.rename()à l’Étape 2
Étape 4.2 : Cartographie catégorielle des couleurs
La cartographie catégorielle est destinée aux données discrètes et non numériques ou aux groupes distincts. Cet exemple utilise la couverture IRS planifiée en Sierra Leone par chefferie pour 2026-2030. La cartographie attribue des couleurs ou des formes distinctes pour différencier les catégories.
Afficher le code
categorical_map <- ggplot2::ggplot() +
ggplot2::geom_sf(
data = gdf_cat_joined,
ggplot2::aes(fill = irs),
color = "white",
size = 0.2
) +
ggplot2::scale_fill_brewer(
# supprimer le titre de la légende et utiliser des étiquettes explicites
name = NULL,
palette = "Accent",
labels = c(
"IRS" = "IRS planifiée",
"No IRS" = "Pas d'IRS planifiée"
),
na.value = "grey90",
na.translate = FALSE
) +
ggplot2::geom_sf(
data = gdf_cat_joined,
fill = NA,
color = "grey30",
linewidth = 0.3
) +
ggplot2::geom_sf(
data = adm2_gdf,
fill = NA,
color = "black",
linewidth = 0.5
) +
ggplot2::labs(
title = "Couverture planifiée de la pulvérisation intradomiciliaire (IRS)",
subtitle = "Par chefferie, 2026-2030"
) +
snt_map_theme() +
ggplot2::theme(
legend.key.size = ggplot2::unit(0.5, "cm")
)
# enregistrer le tracé
ggplot2::ggsave(
plot = categorical_map,
filename = here::here("03_output", "3a_figures", "categorical_map.png"),
width = 10,
height = 8,
dpi = 300
)
NoteSortie
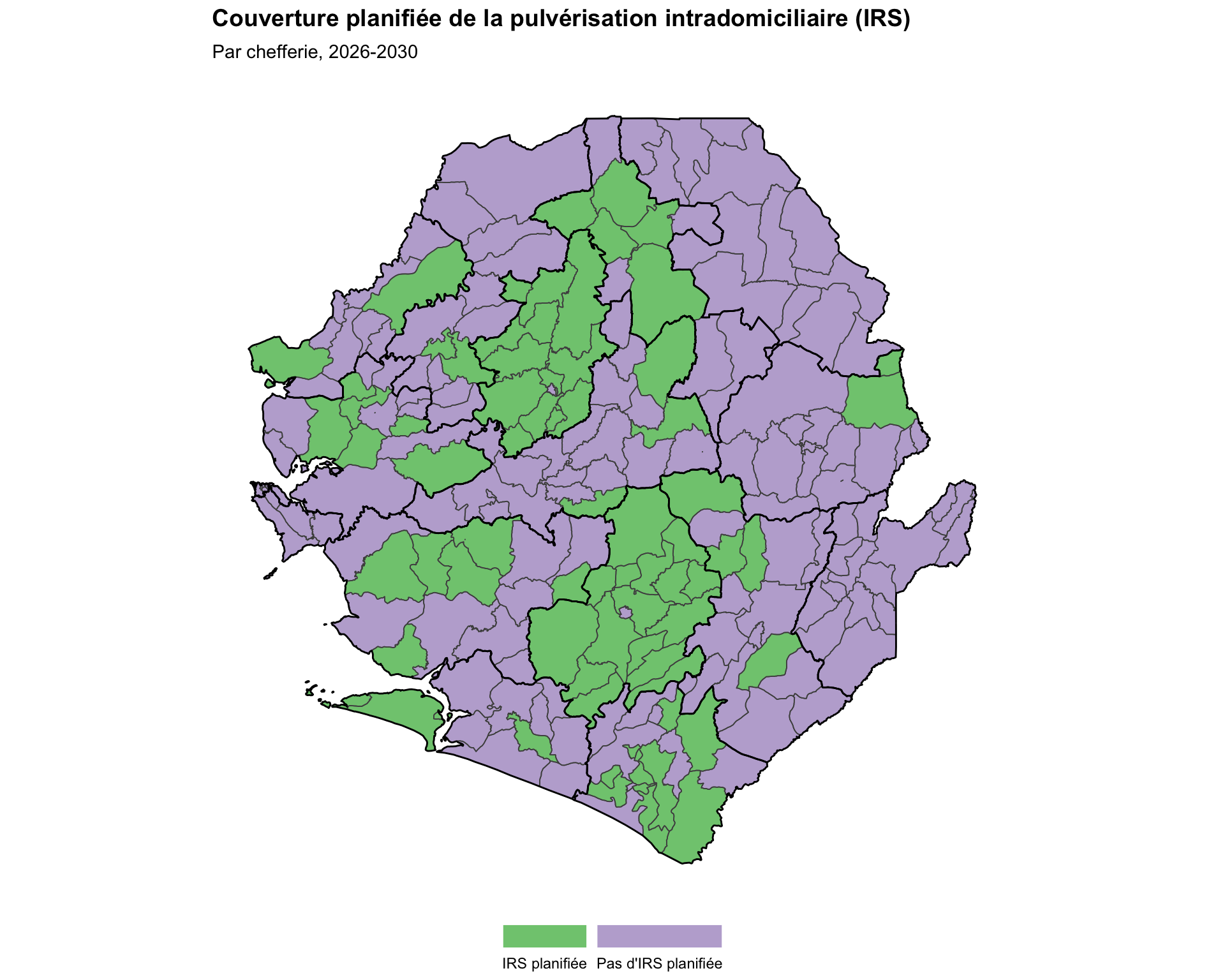
Pour adapter le code :
- Ligne 4 : Remplacer
irspar le nom souhaité de la variable catégorielle que vous souhaitez tracer - Ligne 9 : Modifier le contenu du paramètre
namepour refléter la variable catégorielle que vous tracez - Ligne 27 : Modifier le contenu du paramètre
titleen fonction des données que vous tracez
Afficher le code
irs_palette = {"IRS": "#7fc97f", "No IRS": "#beaed4"}
irs_labels = {"IRS": "IRS planifié", "No IRS": "Pas d'IRS planifié"}
fig, ax = plt.subplots(figsize=(10, 8))
gdf_cat_joined.plot(
ax=ax,
color=gdf_cat_joined["irs"].map(irs_palette).fillna("#E5E5E5"),
edgecolor="white",
linewidth=0.2,
)
gdf_cat_joined.boundary.plot(ax=ax, color="#4D4D4D", linewidth=0.3)
adm2_gdf.boundary.plot(ax=ax, color="black", linewidth=0.5)
finish_map(
ax,
title="Couverture planifiée de pulvérisation intradomiciliaire d'insecticide (IRS)",
subtitle="Par chefferie, 2026-2030"
)
add_bottom_legend(ax, legend_patches(irs_palette, irs_labels), ncol=2)
# enregistrer le tracé
save_figure(
fig,
here("03_output/3a_figures/categorical_map.png"),
width=10,
height=8,
dpi=300
)
plt.show()
NoteSortie
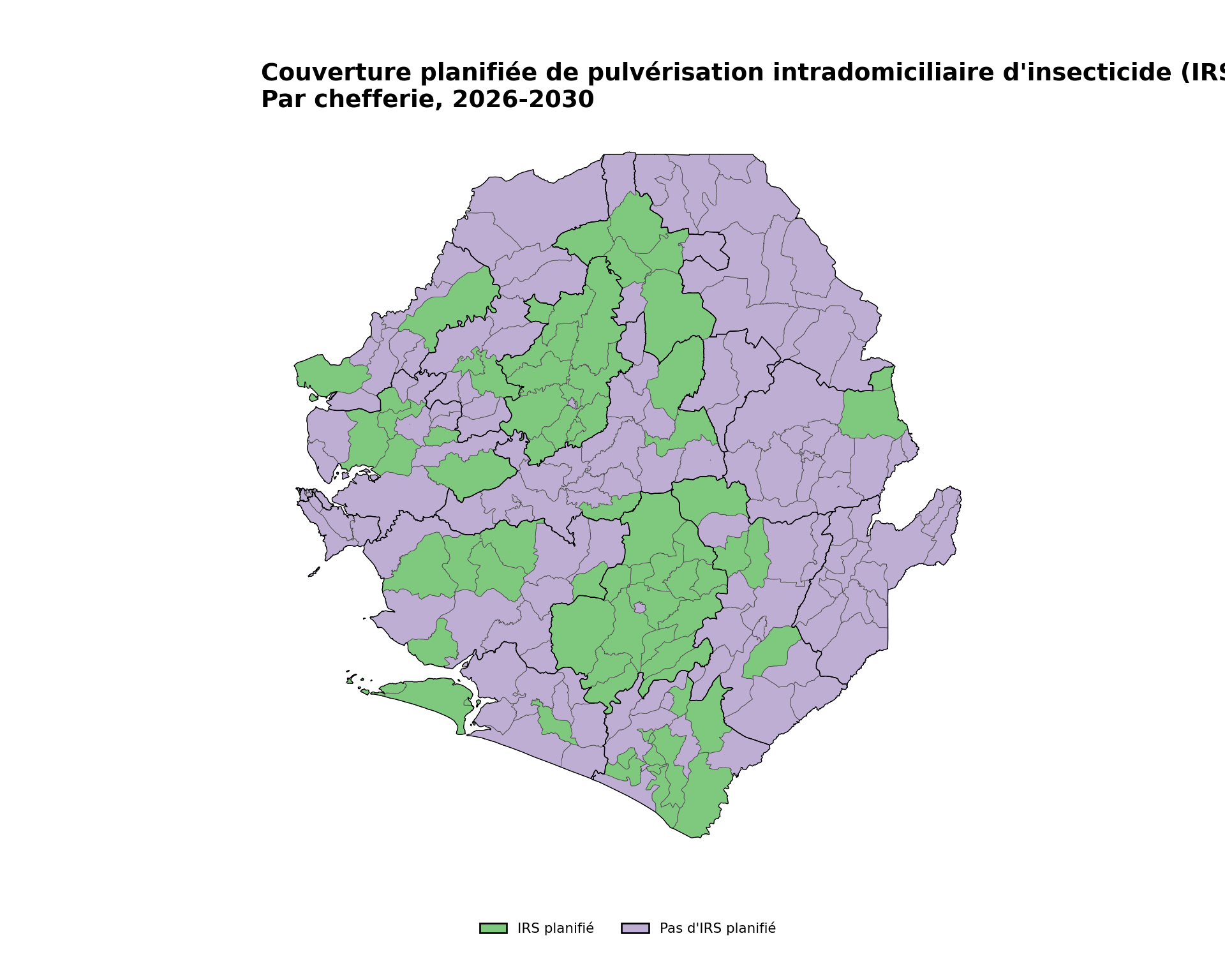
Pour adapter le code :
- Ligne 3 : Remplacer
irspar la variable catégorielle souhaitée dans vos données - Lignes 1–2 : Mettre à jour
irs_paletteetirs_labelspour correspondre aux valeurs de catégorie de vos données et au libellé que vous souhaitez afficher dans la légende - Lignes 18–22 : Modifier
titleetsubtitleen fonction des données que vous tracez
Étape 4.3 : Cartographie des couleurs par intervalles
La cartographie par intervalles fonctionne bien pour les données numériques qui bénéficient d’un regroupement en intervalles, comme les niveaux d’incidence, la proportion de cas suspects testés ou la proportion de personnes utilisant une MII. Cela permet à l’équipe SNT d’identifier immédiatement quelles unités administratives ont atteint un seuil quantitatif significatif et facilite ainsi la prise de décision. Cet exemple crée des intervalles pour la proportion de tests positifs, également connue sous le nom de taux de positivité des tests, par chefferie. Le taux de positivité des tests est d’abord calculé puis tracé.
Afficher le code
# agréger les comptages par chefferie au niveau du district (adm2) pour que
# le choroplèthe remplisse les polygones complets des districts, évitant
# les trous causés par les chefferies manquantes
tabshp_adm2 <- tabshp |>
sf::st_drop_geometry() |>
dplyr::group_by(adm0, adm1, adm2) |>
dplyr::summarise(
dplyr::across(
c(
conf, test,
conf_u5, test_u5,
conf_5_14, test_5_14,
conf_ov15, test_ov15
),
~ sum(.x, na.rm = TRUE)
),
.groups = "drop"
) |>
# restaurer la géométrie des polygones depuis le shapefile adm2
dplyr::left_join(adm2_gdf, by = c("adm0", "adm1", "adm2")) |>
sf::st_as_sf()
# calculer les taux de positivité des tests en pourcentages au niveau adm2
tabshp_with_rates <- tabshp_adm2 |>
dplyr::mutate(
tpr_overall_pct = dplyr::if_else(
test > 0, (conf / test) * 100, NA_real_
),
tpr_u5_pct = dplyr::if_else(
test_u5 > 0, (conf_u5 / test_u5) * 100, NA_real_
),
tpr_5_14_pct = dplyr::if_else(
test_5_14 > 0, (conf_5_14 / test_5_14) * 100, NA_real_
),
tpr_ov15_pct = dplyr::if_else(
test_ov15 > 0, (conf_ov15 / test_ov15) * 100, NA_real_
)
)
# définir les étiquettes ordonnées des intervalles et une palette divergente
# où le bleu va jusqu'à 50-60 et les tons chauds prennent le relais au-delà
tpr_bin_labels <- c(
"0-10", "10-20", "20-30", "30-40", "40-50",
"50-60", "60-70", "70-80", "80-90", "90-100"
)
tpr_bin_palette <- c(
"0-10" = "#1a5276",
"10-20" = "#2980b9",
"20-30" = "#5dade2",
"30-40" = "#85c1e9",
"40-50" = "#aed6f1",
"50-60" = "#d6eaf8",
"60-70" = "#f7dc6f",
"70-80" = "#e67e22",
"80-90" = "#c0392b",
"90-100" = "#7b0d0d"
)
tabshp_with_rates <- tabshp_with_rates |>
dplyr::mutate(
tpr_overall_bin = cut(
tpr_overall_pct,
breaks = c(0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100),
labels = tpr_bin_labels,
include.lowest = TRUE
)
)
binned_map <- ggplot2::ggplot() +
# districts adm2 colorés par intervalle de TPR
ggplot2::geom_sf(
data = tabshp_with_rates,
ggplot2::aes(fill = tpr_overall_bin),
color = "white",
size = 0.2
) +
ggplot2::scale_fill_manual(
name = "Taux de positivité des tests (%)",
values = tpr_bin_palette,
drop = TRUE,
na.value = "grey90",
na.translate = FALSE,
guide = ggplot2::guide_legend(
title.position = "top",
title.hjust = 0.5,
label.position = "bottom",
override.aes = list(
colour = "black",
size = 0.15,
alpha = 1
),
nrow = 1,
byrow = TRUE
)
) +
# régions adm1 : superposition plus épaisse pour lire clairement les limites
ggplot2::geom_sf(
data = adm1_gdf,
fill = NA,
color = "black",
linewidth = 0.5
) +
ggplot2::labs(
title = "Taux de positivité des tests tous âges en Sierra Leone",
subtitle = "Par district (adm2), 2022"
) +
snt_map_theme()
# enregistrer le tracé
ggplot2::ggsave(
plot = binned_map,
filename = here::here("03_output", "3a_figures", "binned_map.png"),
width = 10,
height = 8,
dpi = 300
)
NoteSortie
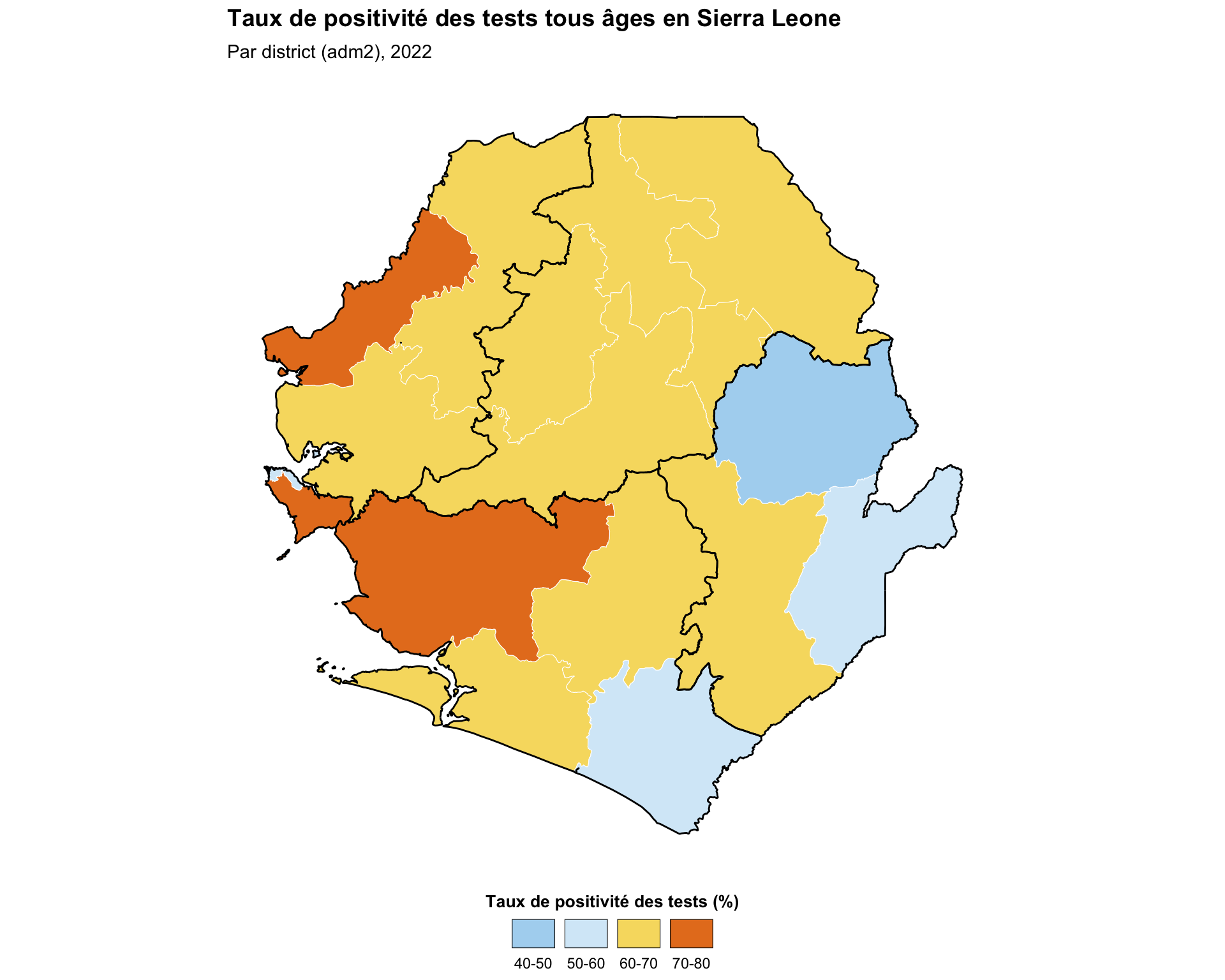
Pour adapter le code :
- Lignes 2–29 : Modifier le calcul de l’indicateur continu en fonction de vos données et tracés souhaités. Si vous tracez une variable continue existante, supprimez entièrement ce bloc.
- Ligne 36 : Remplacer
tpr_overall_pctpar la variable continue que vous souhaitez regrouper et tracer - Ligne 37 : Modifier les
breaksen fonction de la plage et de la distribution de votre variable continue - Ligne 44 : Modifier le contenu du paramètre
nameen fonction de la variable continue que vous tracez - Lignes 47–49 : Modifier les
labelsen fonction des intervalles définis à la ligne 37 - Ligne 66 : Modifier le
titleen fonction de la variable continue que vous tracez
Afficher le code
# agréger les comptages au niveau chefferie jusqu'au district (adm2) pour que la carte choroplèthe
# remplisse les polygones de district complets, en évitant les lacunes causées par les chefferies manquantes
tabshp_adm2 = (
pd.DataFrame(tabshp.drop(columns="geometry"))
.groupby(["adm0", "adm1", "adm2"], as_index=False)[sum_cols]
.sum()
.merge(adm2_gdf, on=["adm0", "adm1", "adm2"], how="left")
)
tabshp_adm2 = gpd.GeoDataFrame(tabshp_adm2, geometry="geometry", crs=adm2_gdf.crs)
# calculer les taux de positivité des tests en pourcentages au niveau adm2
tabshp_with_rates = tabshp_adm2.copy()
tabshp_with_rates["tpr_overall_pct"] = np.where(
tabshp_with_rates["test"] > 0,
(tabshp_with_rates["conf"] / tabshp_with_rates["test"]) * 100,
np.nan
)
tabshp_with_rates["tpr_u5_pct"] = np.where(
tabshp_with_rates["test_u5"] > 0,
(tabshp_with_rates["conf_u5"] / tabshp_with_rates["test_u5"]) * 100,
np.nan
)
tabshp_with_rates["tpr_5_14_pct"] = np.where(
tabshp_with_rates["test_5_14"] > 0,
(tabshp_with_rates["conf_5_14"] / tabshp_with_rates["test_5_14"]) * 100,
np.nan
)
tabshp_with_rates["tpr_ov15_pct"] = np.where(
tabshp_with_rates["test_ov15"] > 0,
(tabshp_with_rates["conf_ov15"] / tabshp_with_rates["test_ov15"]) * 100,
np.nan
)
tabshp_with_rates["tpr_overall_bin"] = pd.cut(
tabshp_with_rates["tpr_overall_pct"],
bins=np.arange(0, 110, 10),
labels=tpr_bin_labels,
include_lowest=True
).astype("string")
fig, ax = plt.subplots(figsize=(10, 8))
plot_binned_map(
ax,
tabshp_with_rates,
fill_col="tpr_overall_bin",
palette=tpr_bin_palette,
title="Taux de positivité des tests tous âges en Sierra Leone",
subtitle="Par district (adm2), 2022",
overlay=adm1_gdf,
)
# enregistrer le tracé
save_figure(
fig,
here("03_output/3a_figures/binned_map.png"),
width=10,
height=8,
dpi=300
)
plt.show()
NoteSortie
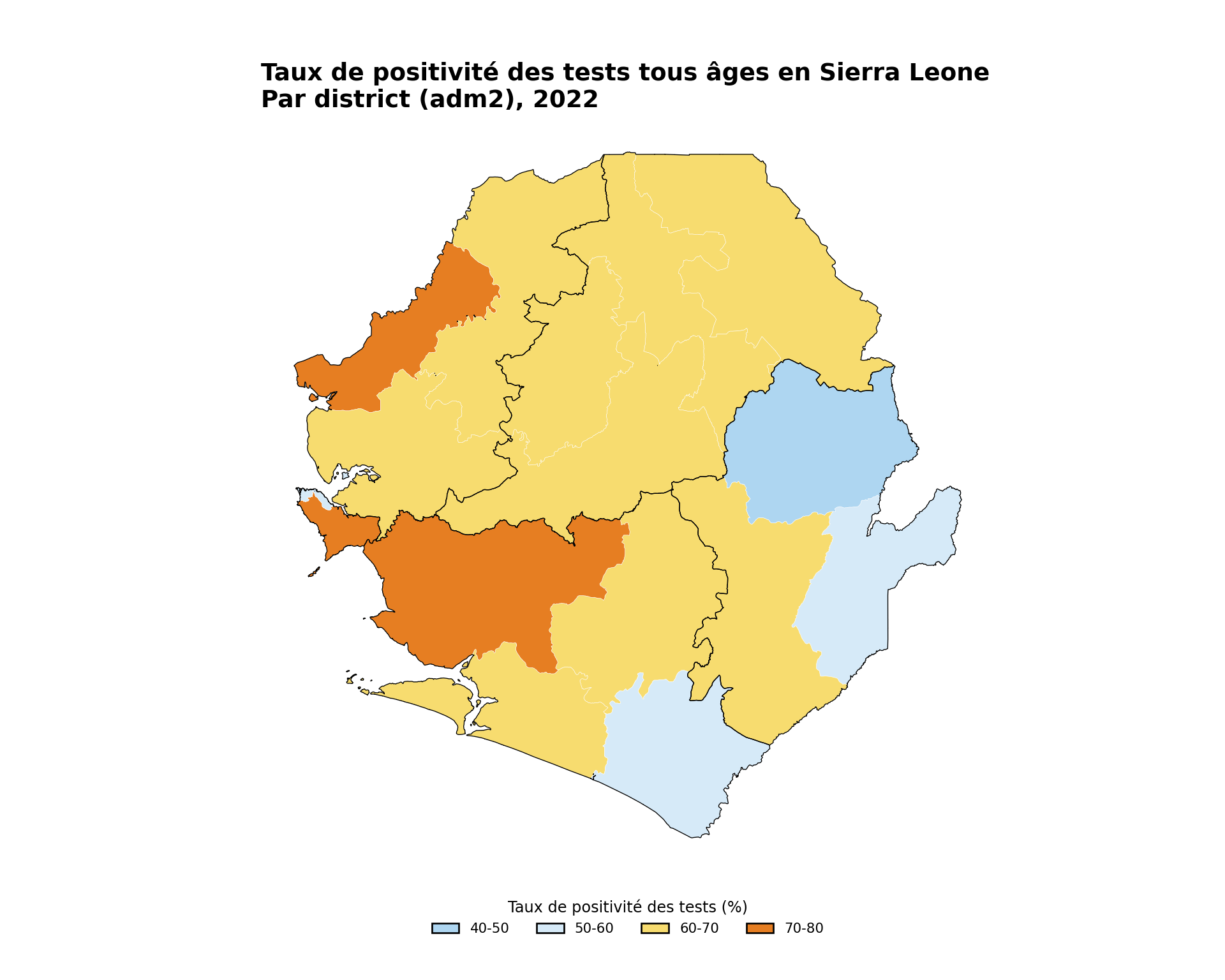
Pour adapter le code :
- Lignes 2–38 : Modifier le calcul de l’indicateur continu en fonction de vos données et des tracés souhaités. Si vous tracez une variable continue existante, supprimez entièrement ce bloc.
- Lignes 40–45 : Modifier
tpr_bin_labels,tpr_bin_paletteetbinspour correspondre aux intervalles et à la rampe de couleurs que vous souhaitez - Lignes 51–53 : Remplacer
tpr_overall_binpar la variable binée que vous souhaitez tracer et ajuster les étiquettes de légende si nécessaire - Lignes 55–56 : Modifier
titleetsubtitleen fonction des données que vous tracez
Étape 4.4 : Cartographie continue des couleurs
La cartographie continue est appropriée pour visualiser des données numériques avec une plage continue et ininterrompue. Cela peut être une première étape utile avant de refaire une version par intervalles de la carte, ou peut être approprié en soi. Dans cet exemple, nous montrons une version continue du même indicateur de positivité des tests de l’étape précédente.
Afficher le code
# palette par défaut du dégradé SNT (valeurs élevées -> rouge foncé,
# valeurs faibles -> bleu foncé)
tpr_gradient_colors <- c(
"#7b0d0d", "#c0392b", "#e67e22", "#f7dc6f",
"#d6eaf8", "#5dade2", "#1a5276"
)
continuous_map <- ggplot2::ggplot() +
ggplot2::geom_sf(
data = tabshp_with_rates,
ggplot2::aes(fill = tpr_overall_pct),
color = "white",
size = 0.2
) +
ggplot2::scale_fill_gradientn(
name = "Taux de positivité des tests (%)",
colors = rev(tpr_gradient_colors),
limits = c(0, 100),
na.value = "grey90",
guide = ggplot2::guide_colorbar(
title.position = "top",
title.hjust = 0.5,
barwidth = grid::unit(15, "lines"),
barheight = grid::unit(0.5, "lines")
)
) +
ggplot2::geom_sf(
data = adm1_gdf,
fill = NA,
color = "black",
linewidth = 0.5
) +
ggplot2::labs(
title = "Taux de positivité des tests tous âges en Sierra Leone",
subtitle = "Par district (adm2), 2022"
) +
snt_map_theme()
# enregistrer le tracé
ggplot2::ggsave(
plot = continuous_map,
filename = here::here("03_output", "3a_figures", "continuous_map.png"),
width = 10,
height = 8,
dpi = 300
)
NoteSortie
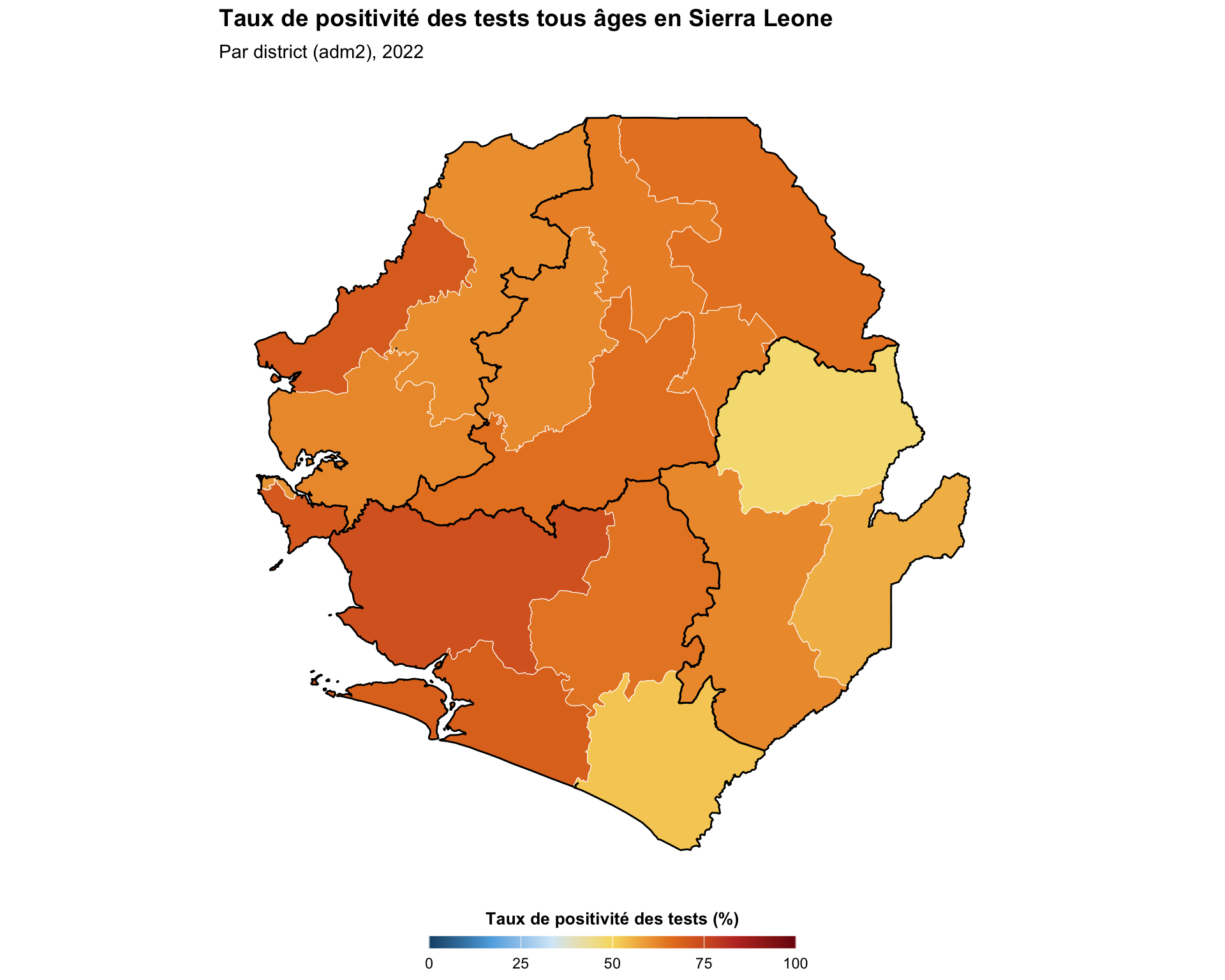
Pour adapter le code :
- Ligne 4 : Remplacer
tpr_overall_pctpar la variable continue que vous souhaitez tracer - Ligne 9 : Modifier le contenu du paramètre
nameen fonction de la variable continue que vous tracez - Ligne 12 : Modifier les
limitsen fonction de la plage de la variable continue que vous tracez - Ligne 29 : Modifier le
titleen fonction des données que vous tracez
Afficher le code
fig, ax = plt.subplots(figsize=(10, 8))
plot_gradient_map(
ax,
tabshp_with_rates,
fill_col="tpr_overall_pct",
colors=tpr_gradient_colors,
title="Taux de positivité des tests tous âges en Sierra Leone",
subtitle="Par district (adm2), 2022",
overlay=adm1_gdf,
legend_label="Taux de positivité des tests (%)",
vmin=0,
vmax=100,
)
# enregistrer le tracé
save_figure(
fig,
here("03_output/3a_figures/continuous_map.png"),
width=10,
height=8,
dpi=300
)
plt.show()
NoteSortie
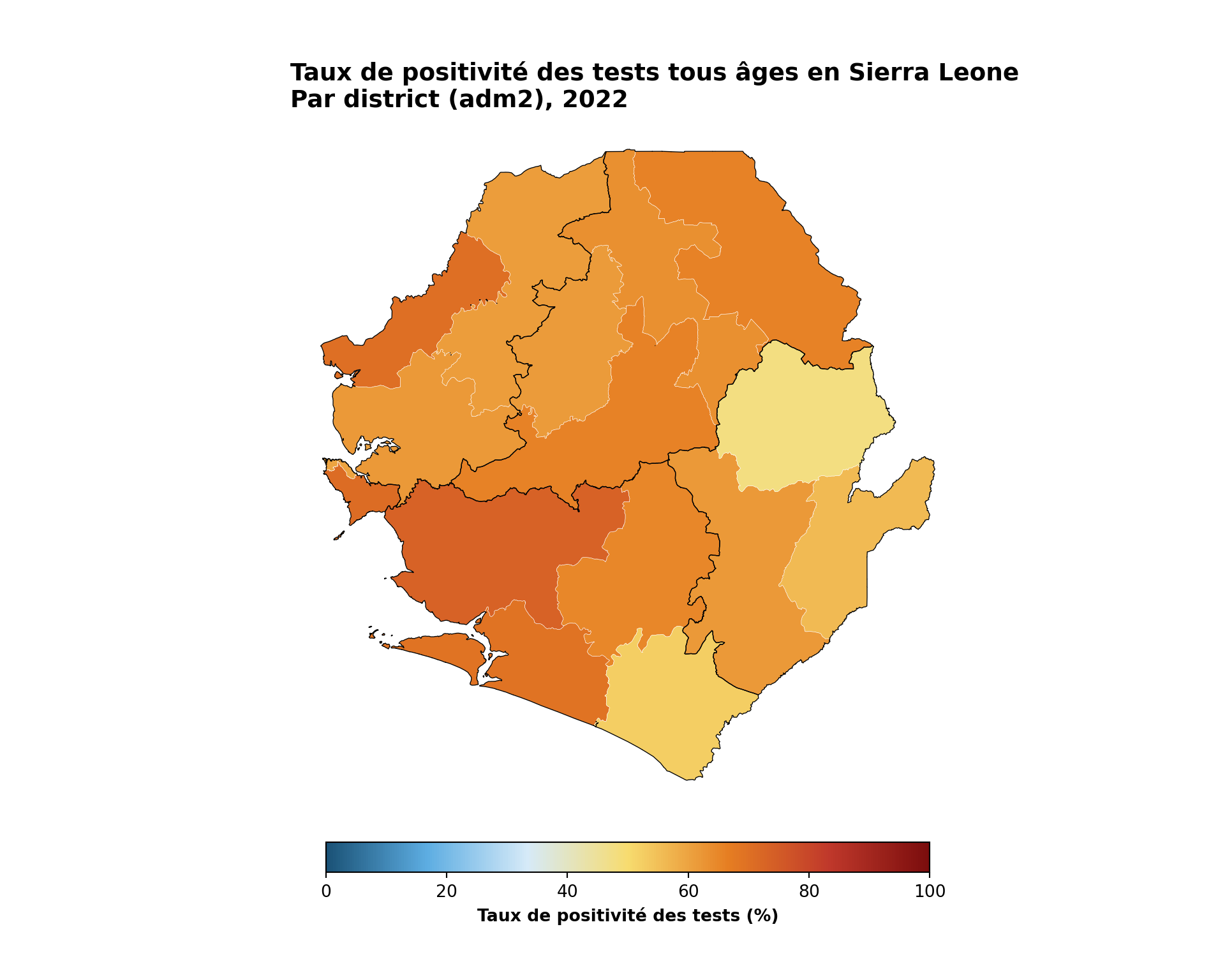
Pour adapter le code :
- Ligne 5 : Modifier
tpr_gradient_colorspour utiliser une rampe de couleurs différente - Ligne 8 : Remplacer
tpr_overall_pctpar la variable continue que vous souhaitez tracer - Ligne 13 : Modifier
legend_labelen fonction de la variable que vous tracez - Lignes 14–15 : Modifier
vminetvmaxen fonction de la plage de la variable continue - Lignes 10–11 : Modifier
titleetsubtitleen fonction des données que vous tracez
Étape 4.5 : Tracer des subdivisions par régions plus grandes
Cet exemple produit une carte qui montre les formes d’un niveau administratif avec la coloration et l’étiquetage d’un autre niveau administratif. Le code trace les formes adm2 et adm3 de la Sierra Leone (limites noires et blanches respectivement) avec des étiquettes et une coloration adm1.
Afficher le code
# étiquettes adm1 avec gestion des erreurs
# (le fichier .rds traité chargé à l'Étape 2 est déjà valide, donc
# aucun nettoyage supplémentaire st_make_valid / st_buffer n'est nécessaire ici)
adm1_labels <- tryCatch(
{
gdf |>
dplyr::group_by(adm1) |>
dplyr::summarise(geometry = sf::st_union(geometry)) |>
sf::st_make_valid() |>
dplyr::mutate(
centroid = sf::st_point_on_surface(geometry),
coords = sf::st_coordinates(centroid),
x = coords[, 1],
y = coords[, 2]
)
},
error = function(e) {
adm2_gdf |>
dplyr::mutate(
centroid = sf::st_point_on_surface(geometry),
coords = sf::st_coordinates(centroid),
x = coords[, 1],
y = coords[, 2]
)
}
)
# palette de couleurs automatique
n_adm1 <- length(unique(gdf$adm1))
adm1_colors <- viridis::plasma(n_adm1)
names(adm1_colors) <- unique(gdf$adm1)
subdivided_plot <- ggplot2::ggplot() +
ggplot2::geom_sf(
data = gdf,
ggplot2::aes(fill = adm1),
color = "white",
linewidth = 0.35
) +
ggplot2::scale_fill_manual(values = adm1_colors) +
ggplot2::geom_sf(
data = adm2_gdf,
fill = NA,
color = "black",
linewidth = 0.8
) +
shadowtext::geom_shadowtext(
data = adm1_labels,
ggplot2::aes(x = x, y = y, label = adm1),
size = 3,
fontface = "bold",
color = "black",
bg.color = "white",
bg.r = 0.25
) +
ggplot2::labs(
title = "Limites Adm1 et Adm2 subdivisées de la Sierra Leone"
) +
snt_map_theme()
# enregistrer le tracé
ggplot2::ggsave(
plot = subdivided_plot,
filename = here::here("03_output", "3a_figures", "subdivided_map.png"),
width = 10,
height = 8,
dpi = 300
)
NoteSortie
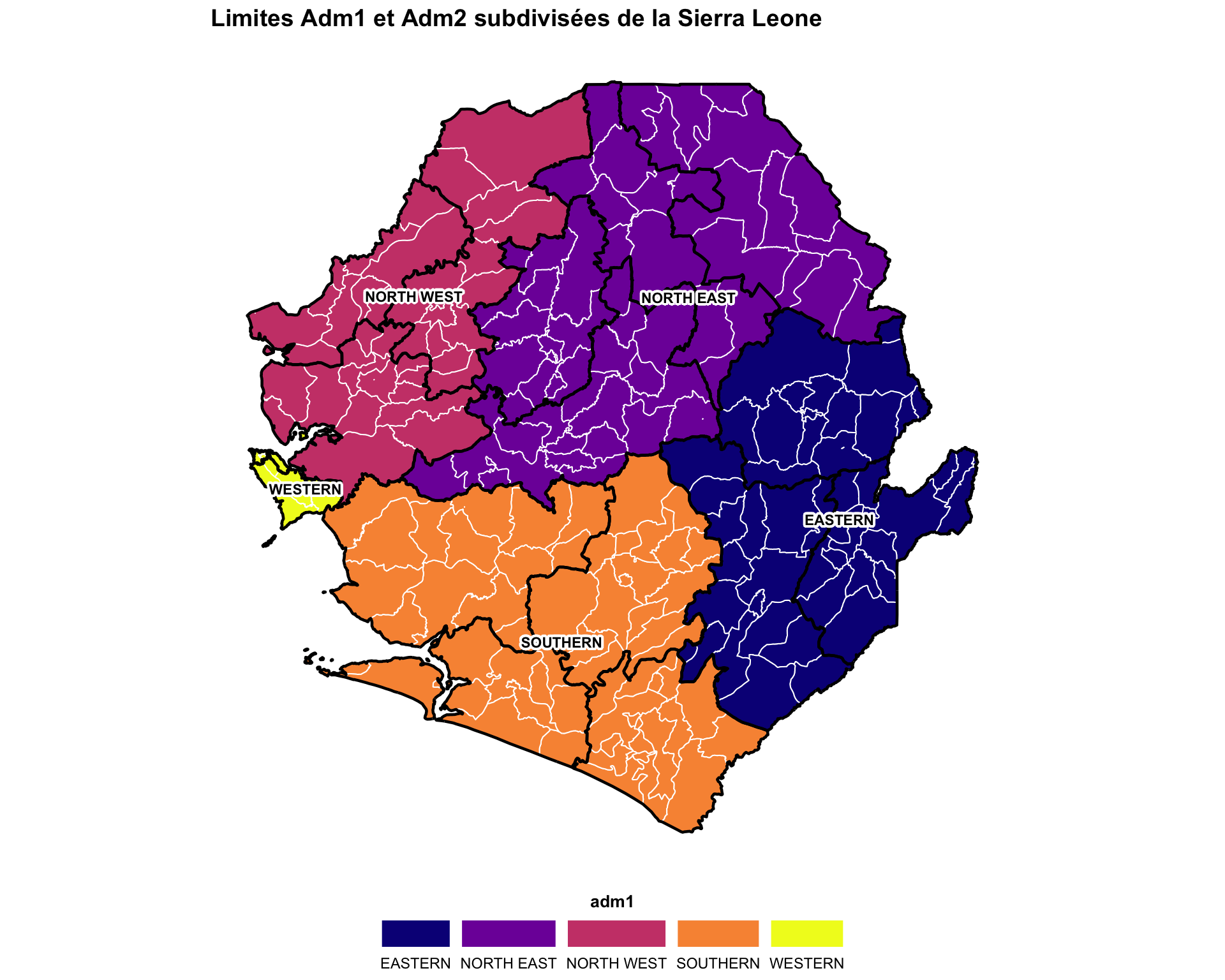
Pour adapter le code :
- Lignes 7, 29, 31, 36, 49 : Remplacer
adm1par la colonne de vos données contenant les noms de région plus large - Ligne 57 : Modifier le
titleen fonction des données que vous tracez
Afficher le code
# étiquettes adm1 avec gestion des erreurs
# (les fichiers traités chargés à l'Étape 2 sont déjà valides, donc aucun
# nettoyage de géométrie supplémentaire n'est nécessaire ici)
try:
adm1_labels = gdf.dissolve(by="adm1", as_index=False)
except Exception:
adm1_labels = adm2_gdf.copy()
adm1_points = adm1_labels.geometry.representative_point()
adm1_labels["lon"] = adm1_points.x
adm1_labels["lat"] = adm1_points.y
# palette de couleurs automatique
adm1_values = list(gdf["adm1"].dropna().unique())
plasma = plt.get_cmap("plasma")
adm1_colors = {
adm1: mcolors.to_hex(plasma(i / max(len(adm1_values) - 1, 1)))
for i, adm1 in enumerate(adm1_values)
}
fig, ax = plt.subplots(figsize=(10, 8))
gdf.plot(
ax=ax,
color=gdf["adm1"].map(adm1_colors),
edgecolor="white",
linewidth=0.35,
)
adm2_gdf.boundary.plot(ax=ax, color="black", linewidth=0.8)
label_points(ax, adm1_labels, label_col="adm1", size=8)
finish_map(ax, title="Limites adm1 et adm2 subdivisées de la Sierra Leone")
add_bottom_legend(ax, legend_patches(adm1_colors), ncol=len(adm1_colors))
# enregistrer le tracé
save_figure(
fig,
here("03_output/3a_figures/subdivided_map.png"),
width=10,
height=8,
dpi=300
)
plt.show()
NoteSortie
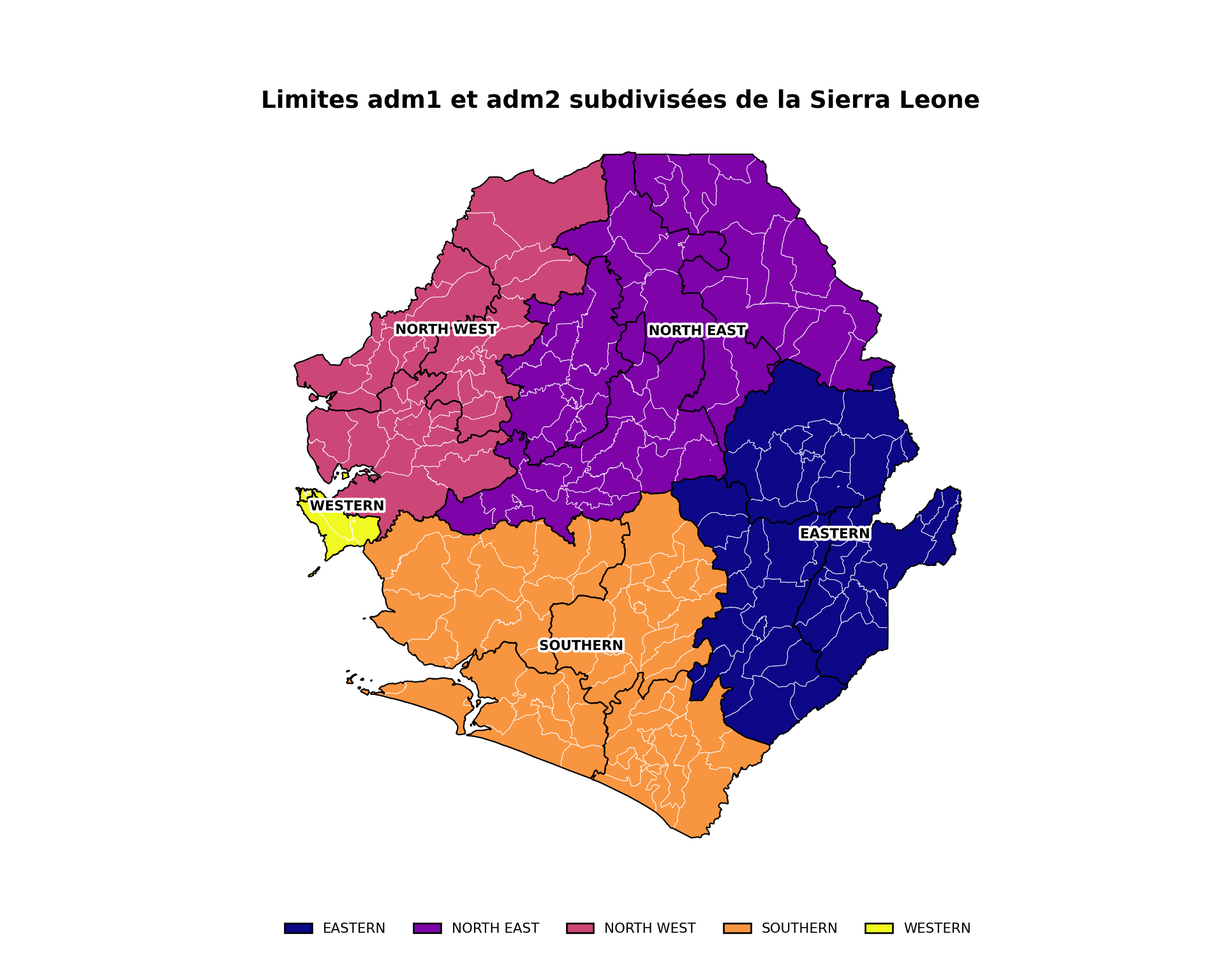
Pour adapter le code :
- Lignes 5, 20, 25, 32 et 36 : Remplacer
adm1par la colonne de vos données contenant les noms de région plus large - Ligne 38 : Modifier
titleen fonction des données que vous tracez
Étape 4.6 : Cartes à facettes
Les tracés à facettes permettent la comparaison entre les unités administratives. Cet exemple démontre des indicateurs continus de positivité des tests et affiche chaque carte dans un panneau séparé avec une géographie identique, applique des couleurs et des légendes cohérentes entre les facettes et maintient des échelles uniformes pour une comparaison directe. Cela nécessite que les données soient remodelées en format long pour simplifier le traçage de plusieurs indicateurs dans des visualisations à facettes.
Afficher le code
# sélectionner les colonnes de pourcentage TPR
tpr_cols <- c(
"tpr_u5_pct",
"tpr_5_14_pct",
"tpr_ov15_pct",
"tpr_overall_pct"
)
# convertir en format long et créer des catégories par intervalles
tpr_long_data <- tabshp_with_rates |>
dplyr::select(geometry, dplyr::all_of(tpr_cols)) |>
tidyr::pivot_longer(
cols = -geometry,
names_to = "age_group",
values_to = "tpr_percentage"
) |>
dplyr::mutate(
age_group = dplyr::recode(
age_group,
"tpr_u5_pct" = "Moins de 5 ans",
"tpr_5_14_pct" = "5-14 ans",
"tpr_ov15_pct" = "Plus de 15 ans",
"tpr_overall_pct" = "Global"
),
age_group = factor(
age_group,
levels = c(
"Moins de 5 ans",
"5-14 ans",
"Plus de 15 ans",
"Global"
),
ordered = TRUE
),
tpr_binned = cut(
tpr_percentage,
breaks = c(0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100),
labels = c(
"0-10", "10-20", "20-30", "30-40", "40-50",
"50-60", "60-70", "70-80", "80-90", "90-100"
),
include.lowest = TRUE
)
)
faceted_tpr_plot <- ggplot2::ggplot(tpr_long_data) +
ggplot2::geom_sf(
ggplot2::aes(fill = tpr_binned),
color = "white",
linewidth = 0.15
) +
ggplot2::facet_wrap(~ age_group, ncol = 2) +
# utiliser la même palette nommée et la même légende à une ligne qu'à
# l'Étape 4.3 pour que la mise en page reste cohérente sur toute la page
ggplot2::scale_fill_manual(
name = "Taux de positivité des tests (%)",
values = tpr_bin_palette,
drop = TRUE,
na.value = "grey90",
na.translate = FALSE,
guide = ggplot2::guide_legend(
title.position = "top",
title.hjust = 0.5,
label.position = "bottom",
override.aes = list(
colour = "black",
size = 0.15,
alpha = 1
),
nrow = 1,
byrow = TRUE
)
) +
# régions adm1 comme superposition de niveau supérieur (source unique
# de vérité pour les limites sur chaque facette)
ggplot2::geom_sf(
data = adm1_gdf,
fill = NA,
color = "black",
linewidth = 0.3
) +
ggplot2::labs(
title = "Taux de positivité des tests par groupe d'âge et district (2022)",
subtitle = "Proportion de tests positifs"
) +
snt_map_theme() +
# ajustements spécifiques aux facettes en plus du thème partagé
ggplot2::theme(
panel.spacing = ggplot2::unit(0.5, "cm"),
strip.text = ggplot2::element_text(face = "bold", size = 11),
legend.key.width = ggplot2::unit(0.9, "cm")
)
# enregistrer le tracé
ggplot2::ggsave(
plot = faceted_tpr_plot,
filename = here::here("03_output", "3a_figures", "faceted_tpr_plot.png"),
width = 10,
height = 8,
dpi = 300
)
NoteSortie
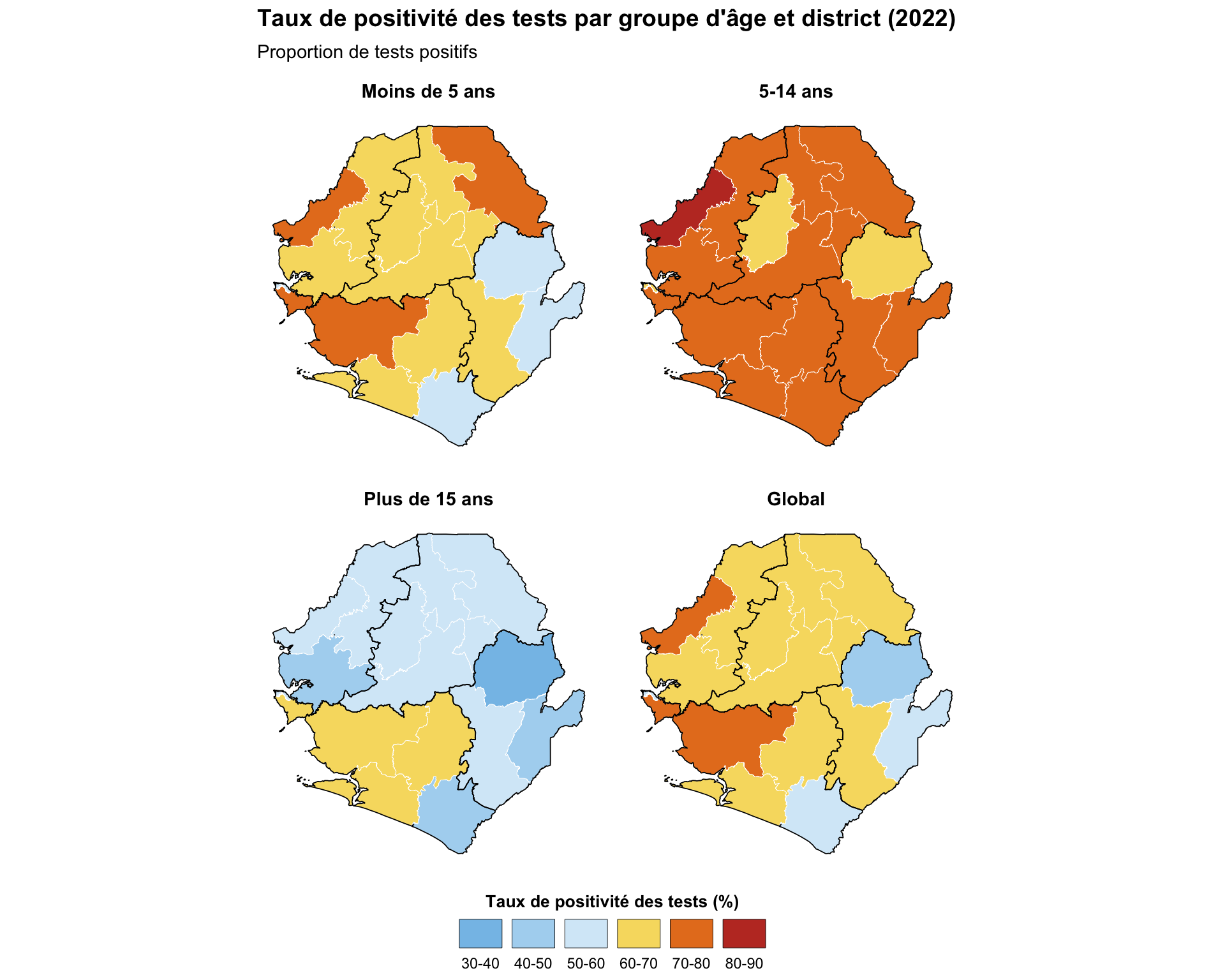
Pour adapter le code :
- Ligne 2 : Définir le vecteur de colonnes correspondant aux facettes du tracé
- Lignes 13–19 : Modifier les groupes d’âge en fonction du nombre et des noms de colonnes sélectionnés pour les facettes du tracé
- Lignes 33–34 : Modifier les
breaksetlabelsde l’échelle en fonction de vos besoins et préférences - Ligne 51 : Modifier le
namede la légende en fonction des données que vous tracez - Lignes 62–63 : Modifier le
titleet lesubtitleen fonction des données que vous tracez - Plus de variables de facettes de tracé peuvent être ajoutées en étendant le vecteur initial avec des noms de colonnes supplémentaires. Ajustez la disposition des facettes en modifiant le paramètre
ncoldansfacet_wrappour accueillir des variables supplémentaires
Afficher le code
# sélectionner les colonnes de pourcentage TPR
tpr_cols = ["tpr_u5_pct", "tpr_5_14_pct", "tpr_ov15_pct", "tpr_overall_pct"]
# convertir les données en format long et créer des catégories par intervalles
age_labels = {
"tpr_u5_pct": "Moins de 5 ans",
"tpr_5_14_pct": "5-14 ans",
"tpr_ov15_pct": "Plus de 15 ans",
"tpr_overall_pct": "Global",
}
age_order = ["Moins de 5 ans", "5-14 ans", "Plus de 15 ans", "Global"]
tpr_long_data = tabshp_with_rates[["geometry"] + tpr_cols].melt(
id_vars="geometry",
value_vars=tpr_cols,
var_name="age_group",
value_name="tpr_percentage"
)
tpr_long_data["age_group"] = pd.Categorical(
tpr_long_data["age_group"].map(age_labels),
categories=age_order,
ordered=True
)
tpr_long_data["tpr_binned"] = pd.cut(
tpr_long_data["tpr_percentage"],
bins=np.arange(0, 110, 10),
labels=tpr_bin_labels,
include_lowest=True
).astype("string")
tpr_long_data = gpd.GeoDataFrame(tpr_long_data, geometry="geometry", crs=tabshp_with_rates.crs)
fig, axes = plt.subplots(2, 2, figsize=(10, 8))
for ax, age_group in zip(axes.flat, age_order):
subset = tpr_long_data.loc[tpr_long_data["age_group"] == age_group]
plot_colors = subset["tpr_binned"].map(tpr_bin_palette).fillna("#E5E5E5")
subset.plot(
ax=ax,
color=plot_colors,
edgecolor="white",
linewidth=0.15,
)
adm1_gdf.boundary.plot(ax=ax, color="black", linewidth=0.3)
finish_map(ax, title=age_group)
fig.suptitle(
"Taux de positivité des tests par groupe d'âge et district (2022)",
fontweight="bold",
x=0.02,
ha="left",
)
handles = legend_patches(tpr_bin_palette)
fig.legend(
handles=handles,
title="Taux de positivité des tests (%)",
loc="lower center",
bbox_to_anchor=(0.5, -0.02),
ncol=len(handles),
frameon=False,
fontsize=8,
title_fontsize=9,
)
fig.tight_layout(rect=[0, 0.07, 1, 0.95])
# enregistrer le tracé
save_figure(
fig,
here("03_output/3a_figures/faceted_tpr_plot.png"),
width=10,
height=8,
dpi=300
)
plt.show()
NoteSortie
Pour adapter le code :
- Ligne 2 : Définir le vecteur de colonnes correspondant aux facettes du tracé
- Lignes 5–12 : Modifier les groupes d’âge en fonction du nombre et des noms de colonnes sélectionnés pour les facettes du tracé
- Lignes 28–34 : Modifier les intervalles d’échelle et les étiquettes en fonction de vos besoins et préférences
- Lignes 49–61 : Modifier le titre et la disposition de la légende en fonction des données que vous tracez
- Des facettes de tracé supplémentaires peuvent être ajoutées en étendant le vecteur initial avec des noms de colonnes supplémentaires. Ajuster la disposition des facettes en modifiant
plt.subplots()
Étape 5 : Personnalisation des cartes pour publication
Les cartes produites à l’Étape 4 sont fonctionnelles, mais quelques personnalisations ciblées les rendent nettement plus faciles à lire et à publier. Chaque sous-section ci-dessous ajoute un élément de finition : choix de couleur, couches supplémentaires, cadrage, composition, interactivité et dimensionnement à l’exportation. Les modèles se généralisent à toute carte de la bibliothèque SNT et sont référencés depuis plusieurs autres pages.
Étape 5.1 : Palettes de couleurs et accessibilité
Environ 5 % des hommes et 0,5 % des femmes présentent une forme de déficience de la vision des couleurs, le plus souvent rouge-vert. La palette divergente utilisée à l’Étape 4 (bleu foncé, bleu clair, jaune, orange, rouge foncé) est robuste sous deutéranopie et protanopie simulées et est la valeur par défaut SNT pour cette raison. Les rampes rouge-vert pures (par exemple RdYlGn) et rainbow() doivent être évitées pour les choroplèthes.
Palettes recommandées par type de données
| Type de données | Palette recommandée | Notes |
|---|---|---|
| Séquentielle (faible à élevée) | blues, ylord, viridis |
Utiliser viridis lorsque l'impression monochromatique est une préoccupation |
| Divergente (faible / moyen / élevé) | rdbu, byor, spectral |
Placer la teinte neutre au point médian significatif de l'indicateur |
| Catégorielle (jusqu'à 8 groupes) | Accent, Set2 (ColorBrewer) |
Éviter les combinaisons rouge-vert ; vérifier dans un simulateur CVD avant publication |
| Catégorielle (binaire) | #1a5276 avec grey80 |
Réserver une teinte saturée pour la catégorie « active », neutre pour l'autre |
Afficher le code
# définir un petit catalogue de palettes couvrant les cas d'utilisation
# séquentiels, divergents et catégoriels. chaque entrée est un vecteur de
# caractères ordonné de codes hex qui peut être passé directement à scale_fill_manual().
snt_palettes <- list(
# séquentielle
blues = c(
"#deebf7", "#c6dbef", "#9ecae1",
"#6baed6", "#4292c6", "#2171b5", "#08519c"
),
ylord = c(
"#ffffcc", "#ffeda0", "#fed976",
"#feb24c", "#fd8d3c", "#fc4e2a", "#bd0026"
),
viridis = c(
"#440154", "#482878", "#3e4a89",
"#31688e", "#26828e", "#1f9e89", "#35b779",
"#6ece58", "#b5de2b", "#fde725"
),
# divergente (valeur par défaut snt pour les indicateurs de type tpr)
byor = c(
"#1a5276", "#2980b9", "#5dade2",
"#85c1e9", "#aed6f1", "#d6eaf8",
"#f7dc6f", "#e67e22", "#c0392b", "#7b0d0d"
),
rdbu = c(
"#b2182b", "#d6604d", "#f4a582",
"#fddbc7", "#d1e5f0", "#92c5de",
"#4393c3", "#2166ac"
),
spectral = c(
"#d53e4f", "#f46d43", "#fdae61",
"#fee08b", "#e6f598", "#abdda4",
"#66c2a5", "#3288bd"
),
# catégorielle
set2 = c(
"#66c2a5", "#fc8d62", "#8da0cb",
"#e78ac3", "#a6d854", "#ffd92f"
),
accent = c(
"#7fc97f", "#beaed4", "#fdc086",
"#ffff99", "#386cb0", "#f0027f"
)
)
# remodeler en un dataframe long pour que chaque couleur soit une tuile
swatches_df <- purrr::imap_dfr(
snt_palettes,
function(cols, name) {
data.frame(
palette = name,
position = seq_along(cols),
colour = cols,
stringsAsFactors = FALSE
)
}
) |>
dplyr::mutate(
palette = factor(
palette,
levels = rev(names(snt_palettes))
)
)
palette_swatches <- ggplot2::ggplot(
swatches_df,
ggplot2::aes(
x = position,
y = palette,
fill = colour
)
) +
ggplot2::geom_tile(
color = "white",
linewidth = 0.4
) +
ggplot2::scale_fill_identity() +
ggplot2::scale_x_continuous(expand = c(0, 0)) +
ggplot2::labs(
title = "Palettes de couleurs SNT recommandées",
subtitle = "Options séquentielles, divergentes et catégorielles",
x = NULL,
y = NULL
) +
ggplot2::theme_minimal(base_size = 11) +
ggplot2::theme(
panel.grid = ggplot2::element_blank(),
axis.text.x = ggplot2::element_blank(),
axis.ticks = ggplot2::element_blank(),
axis.text.y = ggplot2::element_text(
face = "bold",
size = 10
),
plot.title = ggplot2::element_text(
face = "bold",
size = 14,
margin = ggplot2::margin(b = 6)
),
plot.subtitle = ggplot2::element_text(
size = 11,
margin = ggplot2::margin(b = 10)
),
plot.margin = ggplot2::margin(
t = 5, r = 10, b = 5, l = 5
)
)
# enregistrer le tracé
ggplot2::ggsave(
plot = palette_swatches,
filename = here::here(
"03_output", "3a_figures", "palette_swatches.png"
),
width = 10,
height = 6,
dpi = 300
)
NoteSortie
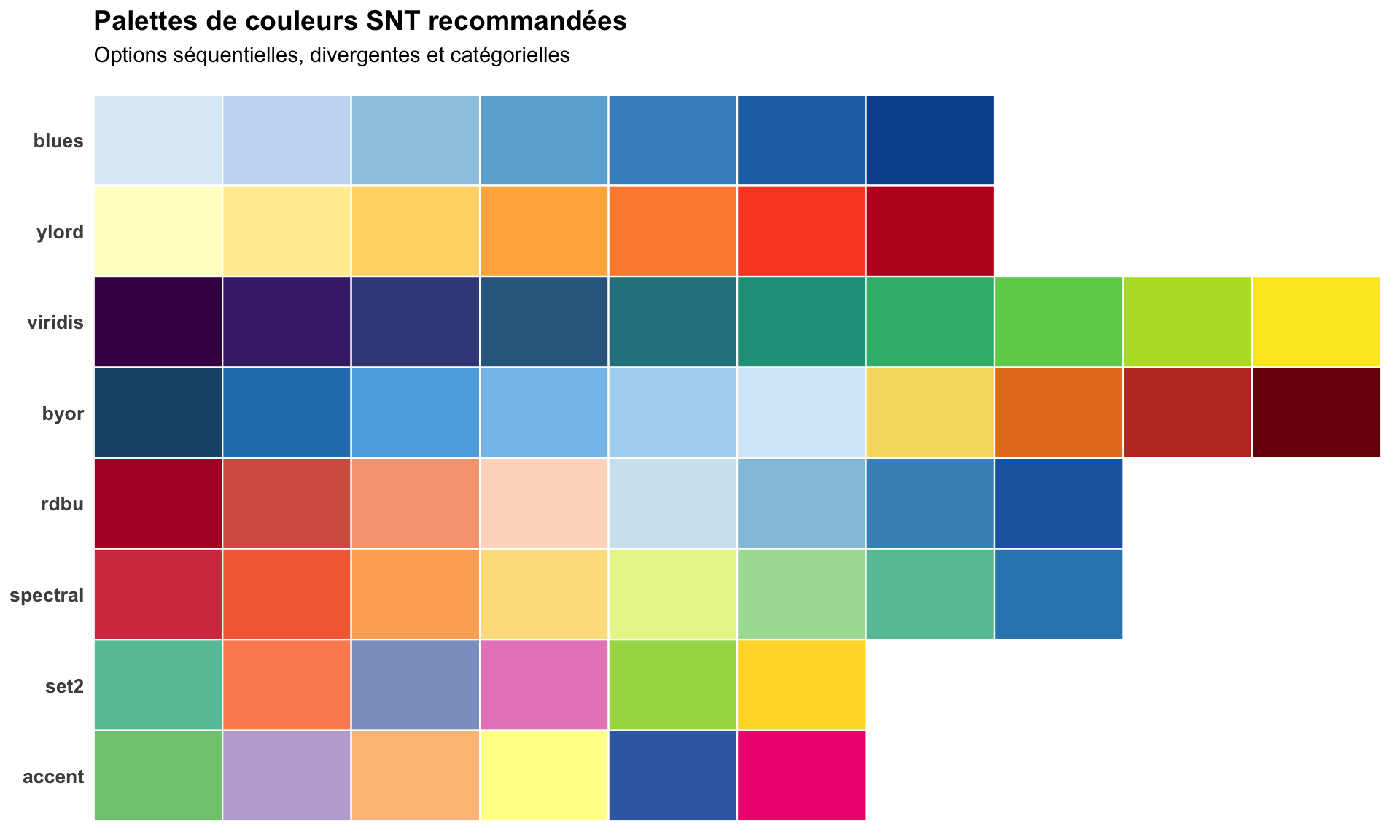
Pour adapter le code :
- Lignes 4–48 : Ajouter, supprimer ou remplacer toute entrée de palette dans
snt_palettes. Chaque entrée est un vecteur hex simple, donc toute palette personnalisée peut être intégrée - Lignes 65–68 : Réordonner les niveaux
factorpour contrôler l’ordre des palettes sur l’axe y (de haut en bas) - Lignes 82–83 : Mettre à jour le
titleet lesubtitlepour décrire l’ensemble de palettes que vous affichez
Afficher le code
# remodeler en un dataframe long pour que chaque couleur soit une tuile
swatches_df = pd.DataFrame(
[
{"palette": name, "position": i + 1, "colour": colour}
for name, colours in snt_palettes.items()
for i, colour in enumerate(colours)
]
)
palette_order = list(reversed(list(snt_palettes.keys())))
fig, ax = plt.subplots(figsize=(10, 6))
for y, palette_name in enumerate(palette_order):
subset = swatches_df.loc[swatches_df["palette"] == palette_name]
for _, row in subset.iterrows():
ax.add_patch(
mpatches.Rectangle(
(row["position"] - 1, y - 0.4),
1,
0.8,
facecolor=row["colour"],
edgecolor="white",
linewidth=0.4,
)
)
ax.set_xlim(0, max(len(cols) for cols in snt_palettes.values()))
ax.set_ylim(-0.5, len(palette_order) - 0.5)
ax.set_yticks(range(len(palette_order)))
ax.set_yticklabels(palette_order, fontweight="bold")
ax.set_xticks([])
ax.set_title(
"Palettes de couleurs SNT recommandées\nOptions séquentielles, divergentes et catégorielles",
loc="left",
fontsize=14,
fontweight="bold",
)
for spine in ax.spines.values():
spine.set_visible(False)
ax.tick_params(left=False, bottom=False)
# enregistrer le tracé
save_figure(
fig,
here("03_output/3a_figures/palette_swatches.png"),
width=10,
height=6,
dpi=300
)
plt.show()
NoteSortie

Pour adapter le code :
- Lignes 3–11 : Ajouter, supprimer ou remplacer toute entrée de palette dans
snt_palettes. Chaque entrée est une liste hex simple, donc toute palette personnalisée peut être intégrée - Ligne 13 : Réordonner
palette_orderpour contrôler l’ordre des palettes sur l’axe y - Lignes 34–39 : Mettre à jour le
titlepour décrire l’ensemble de palettes que vous affichez
Étape 5.2 : Ajouter des superpositions de points
L’ajout de superpositions de points (établissements de santé, capitales de district, centres urbains) au-dessus d’un choroplèthe aide l’équipe SNT à interpréter le contexte spatial d’un indicateur. Le principe consiste à superposer un deuxième geom_sf() pour les points après la couche de polygones, de sorte que les points soient au-dessus.
Afficher le code
# petit ensemble de référence de capitales de district pour l'orientation
# remplacer par votre liste principale d'établissements ou votre ensemble de données de capitales
city_points <- data.frame(
city = c("Freetown", "Bo", "Kenema", "Makeni"),
lon = c(-13.234, -11.738, -11.190, -12.043),
lat = c(8.484, 7.964, 7.875, 8.886)
) |>
sf::st_as_sf(coords = c("lon", "lat"), crs = 4326)
map_with_points <- ggplot2::ggplot() +
ggplot2::geom_sf(
data = tabshp_with_rates,
ggplot2::aes(fill = tpr_overall_bin),
color = "white",
size = 0.2
) +
ggplot2::scale_fill_manual(
name = "Test positivity rate (%)",
values = tpr_bin_palette,
drop = TRUE,
na.value = "grey90",
na.translate = FALSE,
guide = ggplot2::guide_legend(
title.position = "top",
title.hjust = 0.5,
label.position = "bottom",
override.aes = list(
colour = "black",
size = 0.15,
alpha = 1
),
nrow = 1,
byrow = TRUE
)
) +
# régions adm1 comme superposition de niveau supérieur
ggplot2::geom_sf(
data = adm1_gdf,
fill = NA,
color = "black",
linewidth = 0.5
) +
ggplot2::geom_sf(
data = city_points,
shape = 21,
fill = "white",
color = "black",
size = 2.4,
stroke = 0.6
) +
shadowtext::geom_shadowtext(
data = city_points,
ggplot2::aes(
x = sf::st_coordinates(geometry)[, 1],
y = sf::st_coordinates(geometry)[, 2],
label = city
),
color = "black",
bg.color = "white",
bg.r = 0.18,
size = 3.2,
fontface = "bold",
nudge_y = 0.08
) +
ggplot2::labs(
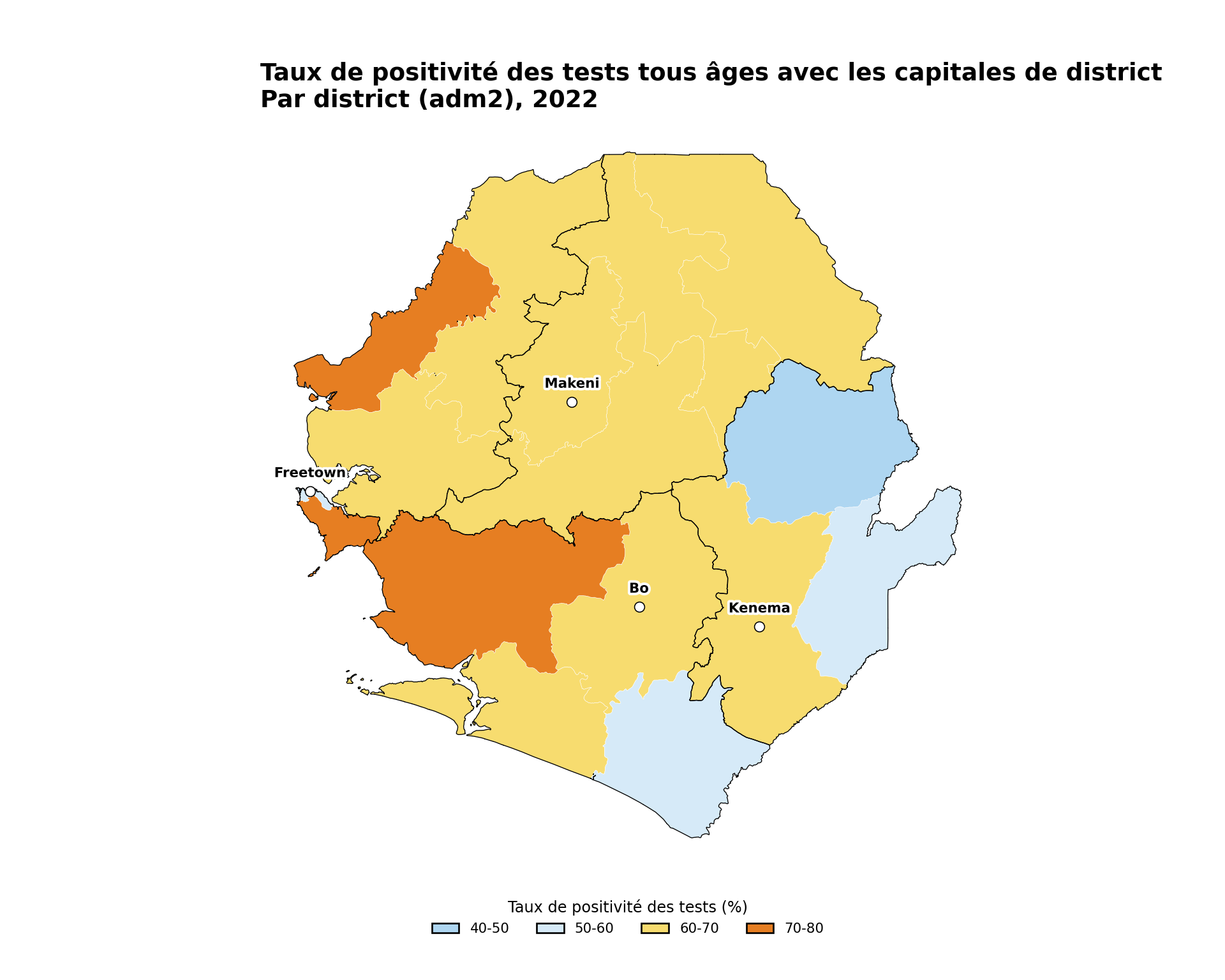
title = "Taux de positivité des tests tous âges avec les capitales de district",
subtitle = "Par district (adm2), 2022"
) +
snt_map_theme()
# sauvegarder le graphique
ggplot2::ggsave(
plot = map_with_points,
filename = here::here("03_output", "3a_figures", "map_with_points.png"),
width = 10,
height = 8,
dpi = 300
)
NoteSortie
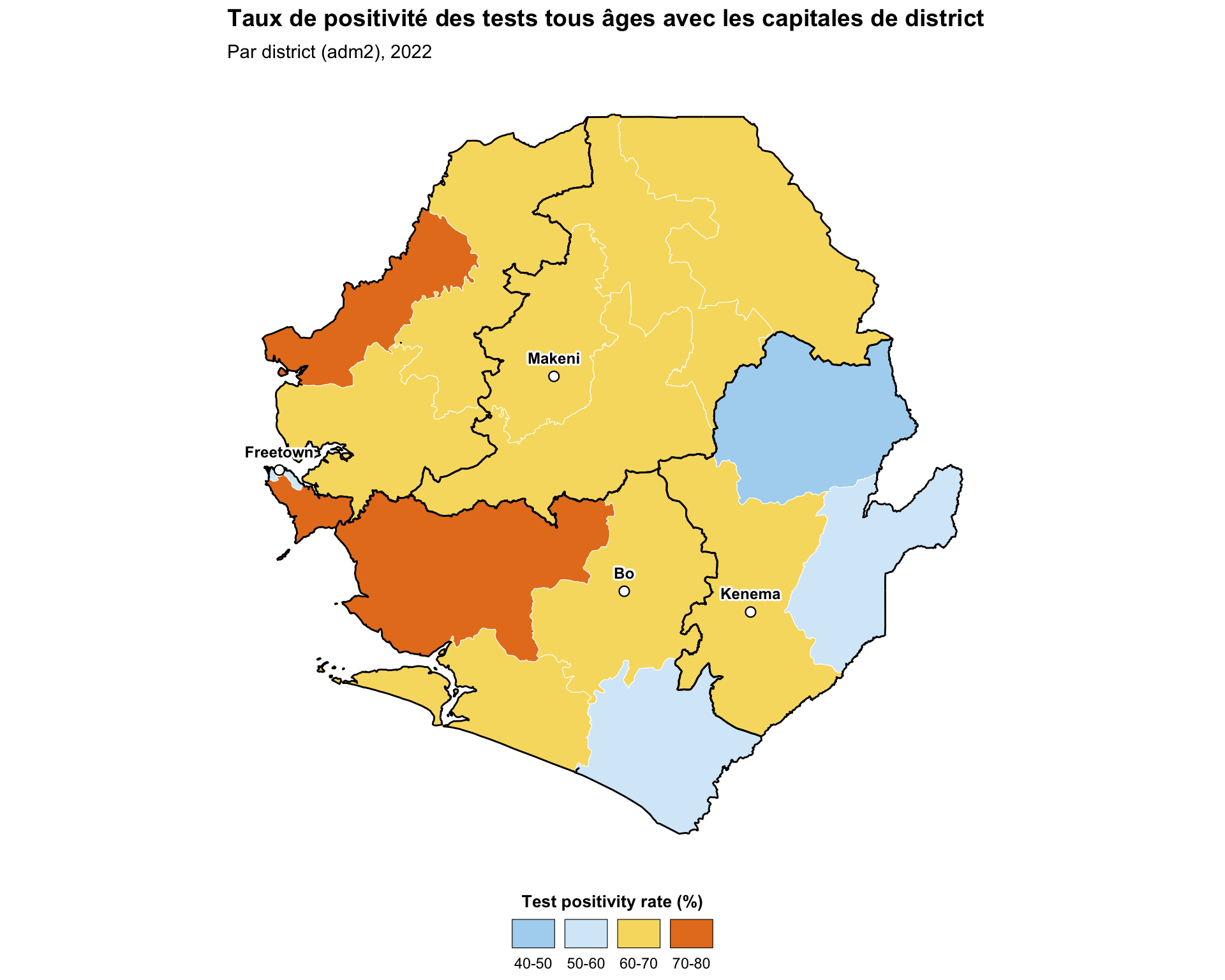
Pour adapter le code :
- Lignes 3–7 : Remplacer
city_pointspar votre propre ensemble de données de points (par exemple une liste principale d’établissements de santé). Tout cadre de données avec des colonnes de longitude et de latitude, ou un objetsfPOINT existant, fonctionne - Lignes 30–36 : Ajuster le marqueur
shape,fill,color,sizeetstrokepour correspondre au style de votre figure - Ligne 48 : Ajuster
nudge_ypour déplacer les étiquettes au-dessus des points si elles se chevauchent
TipPoints d’établissements de santé
Pour de véritables ensembles de données d’établissements de santé, consultez Listes principales d’établissements de santé pour le flux de travail standard de chargement et de nettoyage qui produit un objet sf prêt à être inséré dans le bloc ci-dessus.
Afficher le code
# petit ensemble de référence de capitales de district pour l'orientation
# remplacer par votre liste principale d'établissements ou votre ensemble de données de capitales
city_points = pd.DataFrame({
"city": ["Freetown", "Bo", "Kenema", "Makeni"],
"lon": [-13.234, -11.738, -11.190, -12.043],
"lat": [8.484, 7.964, 7.875, 8.886],
})
city_points = gpd.GeoDataFrame(
city_points,
geometry=gpd.points_from_xy(city_points["lon"], city_points["lat"]),
crs="EPSG:4326",
).to_crs(tabshp_with_rates.crs)
city_points["lon"] = city_points.geometry.x
city_points["lat"] = city_points.geometry.y
fig, ax = plt.subplots(figsize=(10, 8))
plot_binned_map(
ax,
tabshp_with_rates,
fill_col="tpr_overall_bin",
palette=tpr_bin_palette,
title="Taux de positivité des tests tous âges avec les capitales de district",
subtitle="Par district (adm2), 2022",
overlay=adm1_gdf,
)
city_points.plot(
ax=ax,
marker="o",
facecolor="white",
edgecolor="black",
markersize=35,
linewidth=0.6,
)
label_points(ax, city_points, label_col="city", dy=0.08, size=8)
# sauvegarder le graphique
save_figure(
fig,
here("03_output/3a_figures/map_with_points.png"),
width=10,
height=8,
dpi=300
)
plt.show()
NoteSortie
Pour adapter le code :
- Lignes 3–16 : Remplacer
city_pointspar votre propre ensemble de données de points, par exemple une liste principale d’établissements de santé - Lignes 33–40 : Ajuster le marqueur
facecolor,edgecolor,markersizeetlinewidthpour correspondre au style de votre figure - Ligne 42 : Ajuster
dypour déplacer les étiquettes au-dessus des points si elles se chevauchent
Étape 5.3 : Mise en évidence d’unités administratives sélectionnées
Pour soutenir la prise de décision, l’équipe SNT doit souvent attirer l’attention sur un sous-ensemble d’unités administratives, par exemple les districts avec le TPR le plus élevé ou les districts ciblés par une nouvelle intervention. Mettre en évidence en superposant un deuxième geom_sf() avec un remplissage transparent et un contour plus épais et contrastant au-dessus du choroplèthe.
Afficher le code
# sélectionner les trois districts avec le TPR tous âges le plus élevé
top_tpr <- tabshp_with_rates |>
dplyr::slice_max(tpr_overall_pct, n = 3)
highlighted_map <- ggplot2::ggplot() +
ggplot2::geom_sf(
data = tabshp_with_rates,
ggplot2::aes(fill = tpr_overall_bin),
color = "white",
size = 0.2
) +
ggplot2::scale_fill_manual(
name = "Test positivity rate (%)",
values = tpr_bin_palette,
drop = TRUE,
na.value = "grey90",
na.translate = FALSE,
guide = ggplot2::guide_legend(
title.position = "top",
title.hjust = 0.5,
label.position = "bottom",
override.aes = list(
colour = "black",
size = 0.15,
alpha = 1
),
nrow = 1,
byrow = TRUE
)
) +
# régions adm1 comme superposition de niveau supérieur
ggplot2::geom_sf(
data = adm1_gdf,
fill = NA,
color = "grey40",
linewidth = 0.5
) +
# la couche de mise en évidence se trouve au-dessus de tout le reste
ggplot2::geom_sf(
data = top_tpr,
fill = NA,
color = "black",
linewidth = 1.1
) +
ggplot2::labs(
title = "Top 3 des districts par taux de positivité des tests tous âges",
subtitle = "Par district (adm2), 2022"
) +
snt_map_theme()
# sauvegarder le graphique
ggplot2::ggsave(
plot = highlighted_map,
filename = here::here("03_output", "3a_figures", "highlighted_map.png"),
width = 10,
height = 8,
dpi = 300
)
NoteSortie
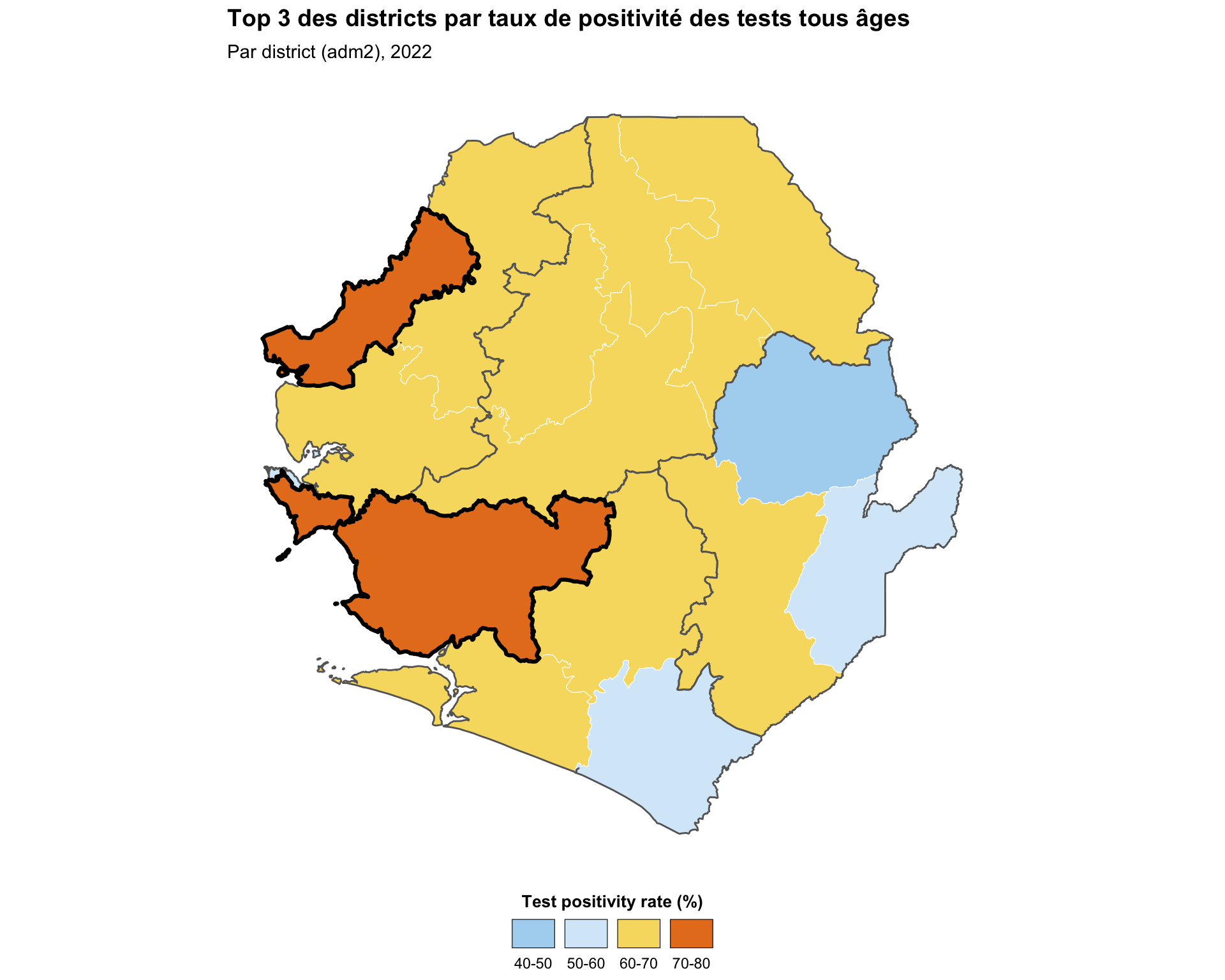
Pour adapter le code :
- Lignes 2–3 : Remplacer
slice_max()par tout filtre qui sélectionne les unités que vous souhaitez mettre en évidence, par exempledplyr::filter(adm2 %in% target_districts) - Lignes 26–30 : Ajuster le contour de mise en évidence
coloretlinewidthpour correspondre à votre figure - Lignes 32–33 : Modifier le
titleet lesubtitleen fonction des unités que vous mettez en évidence
Afficher le code
# sélectionner les trois districts avec le TPR tous âges le plus élevé
top_tpr = tabshp_with_rates.nlargest(3, "tpr_overall_pct")
fig, ax = plt.subplots(figsize=(10, 8))
plot_binned_map(
ax,
tabshp_with_rates,
fill_col="tpr_overall_bin",
palette=tpr_bin_palette,
title="Top 3 des districts par taux de positivité des tests tous âges",
subtitle="Par district (adm2), 2022",
overlay=adm1_gdf,
overlay_color="#666666",
)
# la couche de mise en évidence se trouve au-dessus de tout le reste
top_tpr.boundary.plot(ax=ax, color="black", linewidth=1.1)
# sauvegarder le graphique
save_figure(
fig,
here("03_output/3a_figures/highlighted_map.png"),
width=10,
height=8,
dpi=300
)
plt.show()
NoteSortie
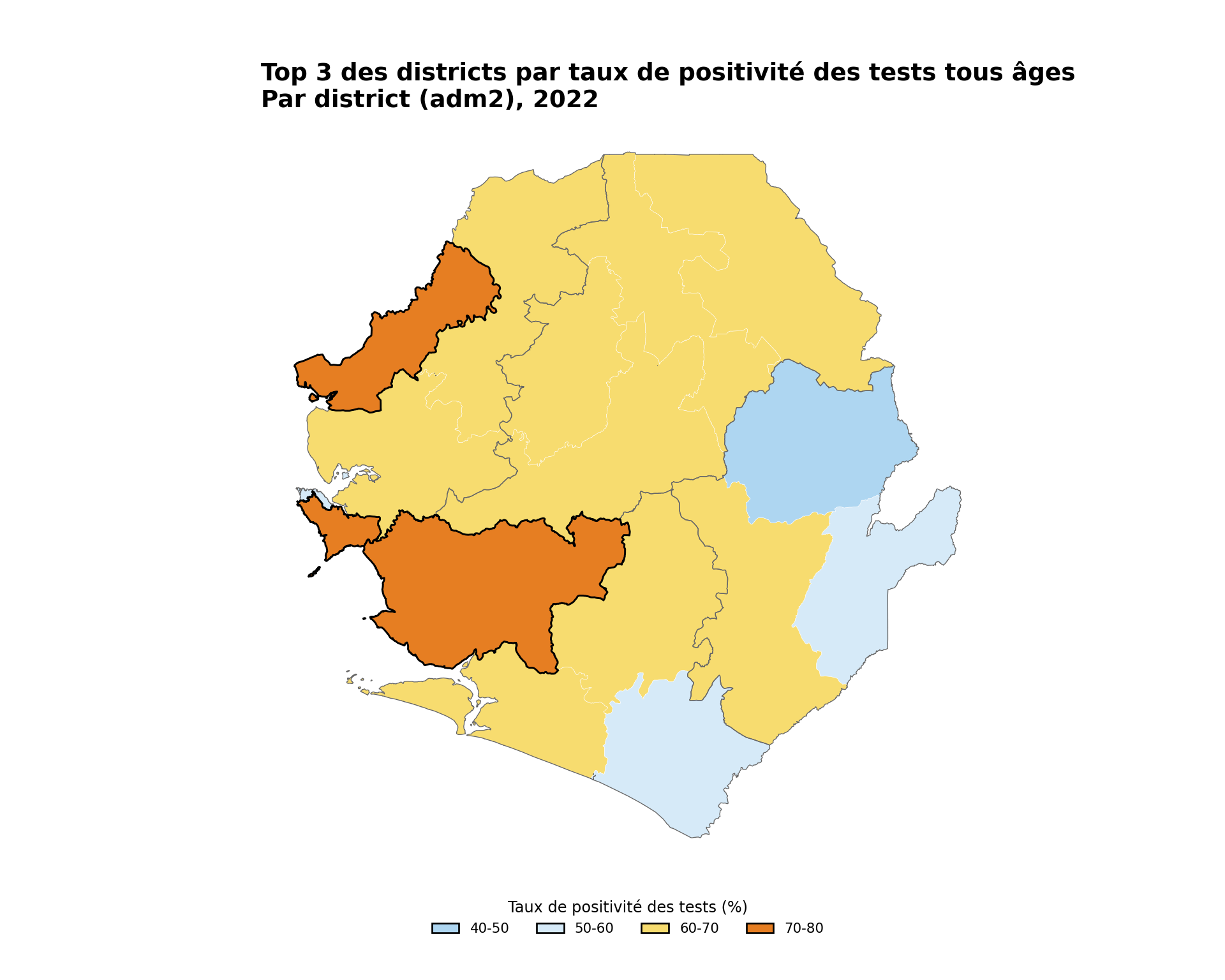
Pour adapter le code :
- Ligne 2 : Remplacer
.nlargest()par tout filtre qui sélectionne les unités que vous souhaitez mettre en évidence, par exempletabshp_with_rates[tabshp_with_rates["adm2"].isin(target_districts)] - Ligne 20 : Ajuster le contour de mise en évidence
coloretlinewidthpour correspondre à votre figure - Lignes 10–11 : Modifier le
titleet lesubtitleen fonction des unités que vous mettez en évidence
Étape 5.4 : Barre d’échelle et flèche du nord
Pour les cartes destinées à la publication ou aux tableaux de bord opérationnels, une barre d’échelle et une flèche du nord donnent aux lecteurs un contexte spatial immédiat. L’outil standard dans l’écosystème R est ggspatial, qui fournit annotation_scale() et annotation_north_arrow() en tant que couches sensibles aux coordonnées du graphique.
Afficher le code
publication_map <- ggplot2::ggplot() +
ggplot2::geom_sf(
data = tabshp_with_rates,
ggplot2::aes(fill = tpr_overall_bin),
color = "white",
size = 0.2
) +
ggplot2::scale_fill_manual(
name = "Test positivity rate (%)",
values = tpr_bin_palette,
drop = TRUE,
na.value = "grey90",
na.translate = FALSE,
guide = ggplot2::guide_legend(
title.position = "top",
title.hjust = 0.5,
label.position = "bottom",
override.aes = list(
colour = "black",
size = 0.15,
alpha = 1
),
nrow = 1,
byrow = TRUE
)
) +
# régions adm1 comme superposition de niveau supérieur
ggplot2::geom_sf(
data = adm1_gdf,
fill = NA,
color = "black",
linewidth = 0.5
) +
ggspatial::annotation_scale(
location = "bl",
width_hint = 0.25,
style = "bar",
line_width = 0.6
) +
ggspatial::annotation_north_arrow(
location = "tr",
which_north = "true",
style = ggspatial::north_arrow_fancy_orienteering(),
height = grid::unit(1.4, "cm"),
width = grid::unit(1.4, "cm")
) +
ggplot2::labs(
title = "Taux de positivité des tests avec barre d'échelle et flèche du nord",
subtitle = "Par district (adm2), 2022"
) +
snt_map_theme()
# sauvegarder le graphique
ggplot2::ggsave(
plot = publication_map,
filename = here::here("03_output", "3a_figures", "publication_map.png"),
width = 10,
height = 8,
dpi = 300
)
NoteSortie
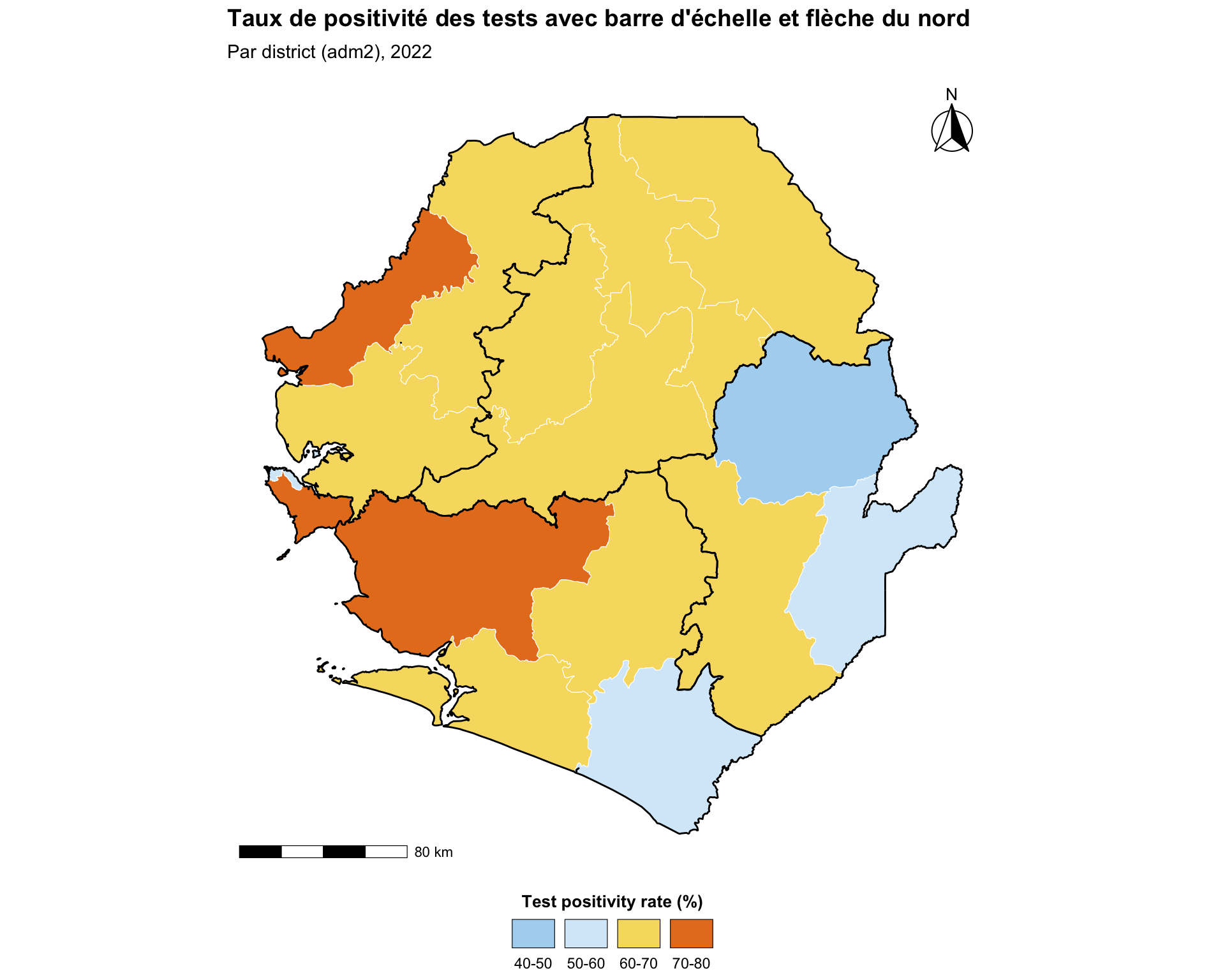
Pour adapter le code :
- Lignes 21–25 : Déplacer la barre d’échelle en changeant
location(l’un de"bl","br","tl","tr") et la redimensionner avecwidth_hint - Lignes 27–32 : Remplacer
north_arrow_fancy_orienteering()parnorth_arrow_minimal()ounorth_arrow_orienteering()pour utiliser un symbole nord plus simple ou différent - Lignes 34–35 : Modifier le
titleet lesubtitleen fonction des données que vous tracez
Python utilise matplotlib-scalebar pour la barre d’échelle et une simple flèche annotée pour le nord.
Afficher le code
# transformer en mètres pour la barre d'échelle
tabshp_with_rates_m = tabshp_with_rates.to_crs(epsg=3857)
adm1_gdf_m = adm1_gdf.to_crs(epsg=3857)
fig, ax = plt.subplots(figsize=(10, 8))
plot_binned_map(
ax,
tabshp_with_rates_m,
fill_col="tpr_overall_bin",
palette=tpr_bin_palette,
title="Taux de positivité des tests avec barre d'échelle et flèche du nord",
subtitle="Par district (adm2), 2022",
overlay=adm1_gdf_m,
)
ax.add_artist(
ScaleBar(
1,
units="m",
dimension="si-length",
location="lower left",
length_fraction=0.25,
box_alpha=0,
)
)
ax.annotate(
"N",
xy=(0.94, 0.93),
xytext=(0.94, 0.80),
xycoords="axes fraction",
textcoords="axes fraction",
ha="center",
va="center",
fontsize=12,
fontweight="bold",
arrowprops={"arrowstyle": "-|>", "facecolor": "black", "edgecolor": "black", "lw": 1.2},
)
# sauvegarder le graphique
save_figure(
fig,
here("03_output/3a_figures/publication_map.png"),
width=10,
height=8,
dpi=300
)
plt.show()
NoteSortie
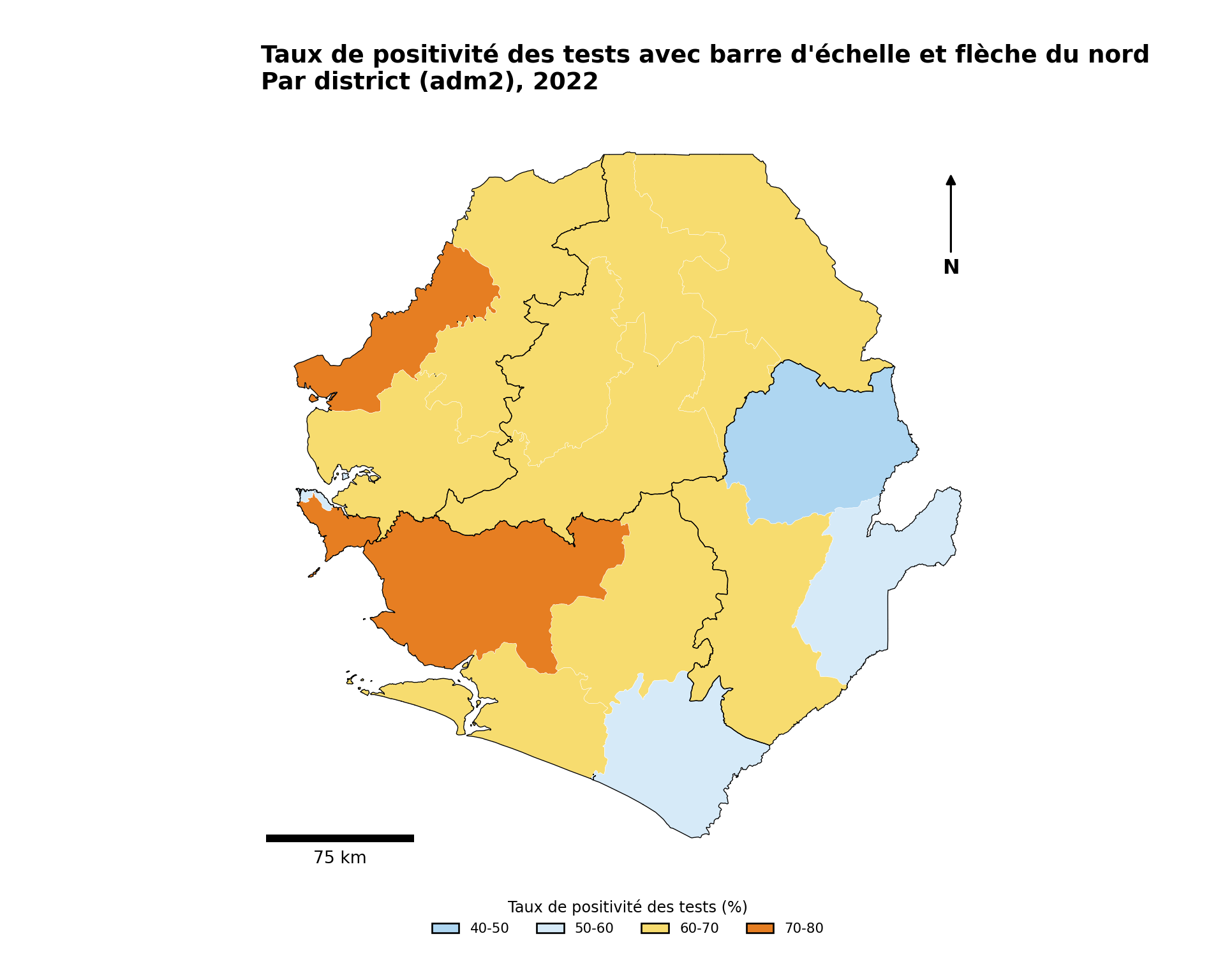
Pour adapter le code :
- Lignes 18–27 : Déplacer la barre d’échelle en changeant
locationet la redimensionner aveclength_fraction - Lignes 29–43 : Déplacer ou redéfinir le style de la flèche du nord en changeant les coordonnées de fraction d’axes et
arrowprops - Lignes 12–13 : Modifier le
titleet lesubtitleen fonction des données que vous tracez
Étape 5.5 : Combiner des cartes avec patchwork
La comparaison côte à côte de deux indicateurs ou de deux groupes d’âge est souvent plus claire avec patchwork qu’avec facet_wrap, car chaque sous-graphique peut avoir sa propre échelle, son titre et sa légende. L’opérateur + compose les graphiques horizontalement, / les empile verticalement et plot_layout(guides = "collect") consolide les légendes.
Afficher le code
# petite fonction d'aide pour que les deux panneaux partagent le même aspect et héritent du
# thème de carte SNT partagé utilisé aux étapes 4.3 - 5.4 (polices, tailles, mise en page
# de la légende, marges) ; seul le sous-titre par panneau est ajusté
make_panel <- function(data, fill_col, panel_title) {
ggplot2::ggplot() +
ggplot2::geom_sf(
data = data,
ggplot2::aes(fill = .data[[fill_col]]),
color = "white",
size = 0.2
) +
ggplot2::scale_fill_gradientn(
name = "TPR (%)",
colors = rev(tpr_gradient_colors),
limits = c(0, 100),
na.value = "grey90",
guide = ggplot2::guide_colorbar(
title.position = "top",
title.hjust = 0.5,
barwidth = grid::unit(8, "lines"),
barheight = grid::unit(0.4, "lines")
)
) +
# régions adm1 comme superposition de niveau supérieur
ggplot2::geom_sf(
data = adm1_gdf,
fill = NA,
color = "black",
linewidth = 0.5
) +
ggplot2::labs(subtitle = panel_title) +
snt_map_theme() +
ggplot2::theme(
plot.subtitle = ggplot2::element_text(
face = "bold",
size = 11,
hjust = 0,
margin = ggplot2::margin(b = 6)
)
)
}
panel_u5 <- make_panel(
tabshp_with_rates, "tpr_u5_pct", "Moins de 5 ans"
)
panel_ov15 <- make_panel(
tabshp_with_rates, "tpr_ov15_pct", "Plus de 15 ans"
)
combined_map <- patchwork::wrap_plots(
panel_u5, panel_ov15, ncol = 2
) +
patchwork::plot_annotation(
title = "Taux de positivité des tests par groupe d'âge, 2022",
theme = ggplot2::theme(
plot.title = ggplot2::element_text(
face = "bold",
size = 14,
hjust = 0,
margin = ggplot2::margin(b = 8)
)
)
) +
patchwork::plot_layout(guides = "collect") &
ggplot2::theme(legend.position = "bottom")
# sauvegarder le graphique
ggplot2::ggsave(
plot = combined_map,
filename = here::here("03_output", "3a_figures", "combined_map.png"),
width = 12,
height = 7,
dpi = 300
)
NoteSortie
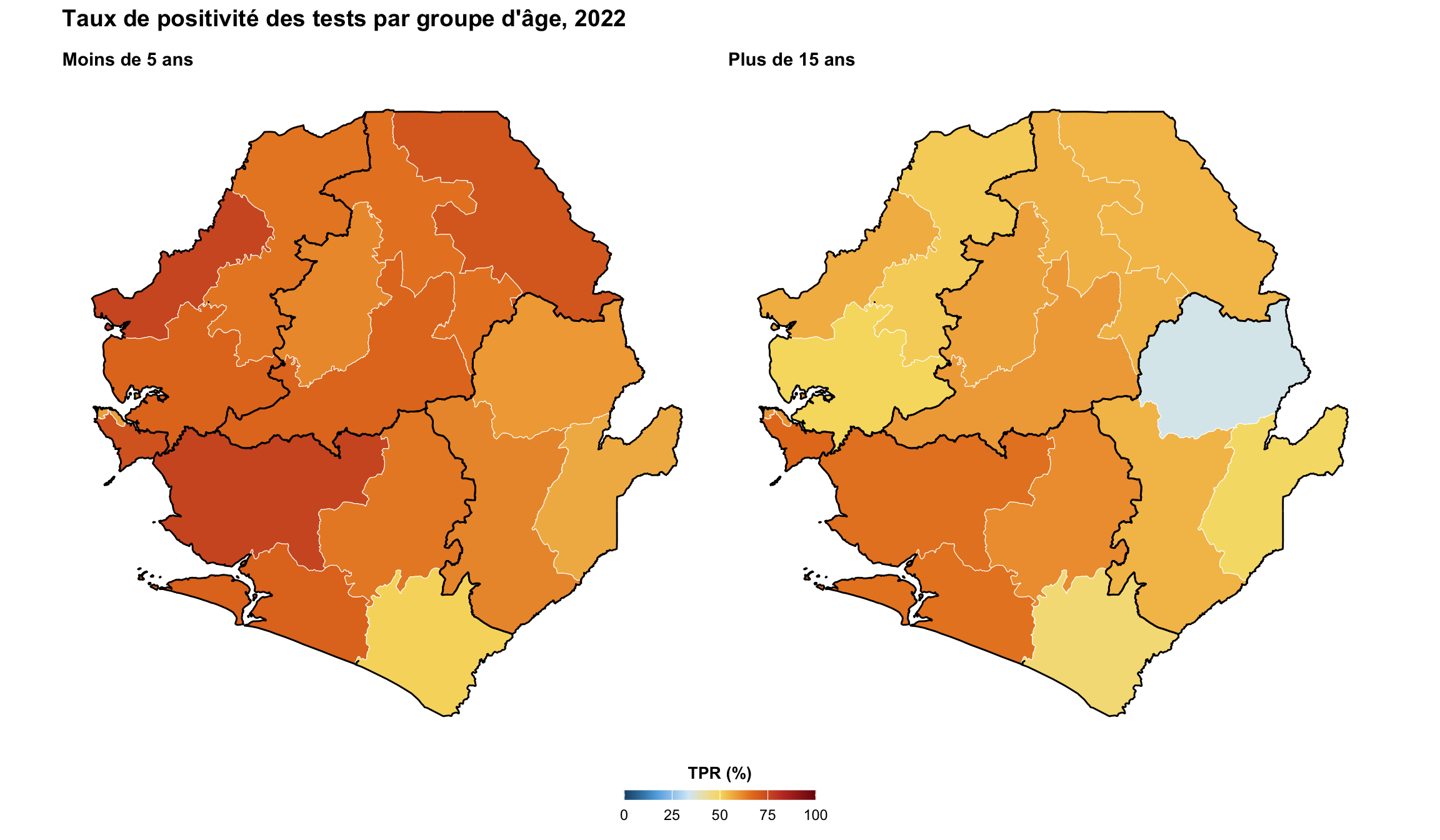
Pour adapter le code :
- Lignes 14–16 : Remplacer
"tpr_u5_pct"/"tpr_ov15_pct"par les colonnes que vous souhaitez comparer côte à côte - Ligne 48 : Remplacer
ncol = 2parncol = 1pour empiler les panneaux verticalement - Ligne 51 : Modifier le
titleglobal en fonction des données que vous tracez
TipCôte à côte vs
facet_wrap
Utilisez facet_wrap (Étape 4.6) lorsque chaque panneau partage la même échelle, légende et titre. Utilisez patchwork lorsque les panneaux doivent différer dans l’un de ces éléments, ou lorsque vous souhaitez combiner des cartes avec des graphiques non cartographiques tels qu’un graphique à barres, un histogramme de l’indicateur ou un localisateur d’encart.
Python utilise les sous-graphiques matplotlib pour la même composition côte à côte.
Afficher le code
def make_panel_py(ax, data, fill_col, panel_title):
cmap = mcolors.LinearSegmentedColormap.from_list("tpr_gradient", tpr_gradient_colors)
data.plot(
ax=ax,
column=fill_col,
cmap=cmap,
vmin=0,
vmax=100,
edgecolor="white",
linewidth=0.2,
missing_kwds={"color": "#E5E5E5"},
)
adm1_gdf.boundary.plot(ax=ax, color="black", linewidth=0.5)
finish_map(ax, title=panel_title)
return cmap
fig, axes = plt.subplots(1, 2, figsize=(12, 7))
cmap = make_panel_py(axes[0], tabshp_with_rates, "tpr_u5_pct", "Moins de 5 ans")
make_panel_py(axes[1], tabshp_with_rates, "tpr_ov15_pct", "Plus de 15 ans")
fig.suptitle(
"Taux de positivité des tests par groupe d'âge, 2022",
fontweight="bold",
x=0.02,
ha="left",
)
sm = ScalarMappable(norm=mcolors.Normalize(vmin=0, vmax=100), cmap=cmap)
sm.set_array([])
cbar = fig.colorbar(sm, ax=axes, orientation="horizontal", fraction=0.04, pad=0.06)
cbar.set_label("TPR (%)", fontweight="bold")
# sauvegarder le graphique
save_figure(
fig,
here("03_output/3a_figures/combined_map.png"),
width=12,
height=7,
dpi=300
)
plt.show()
NoteSortie
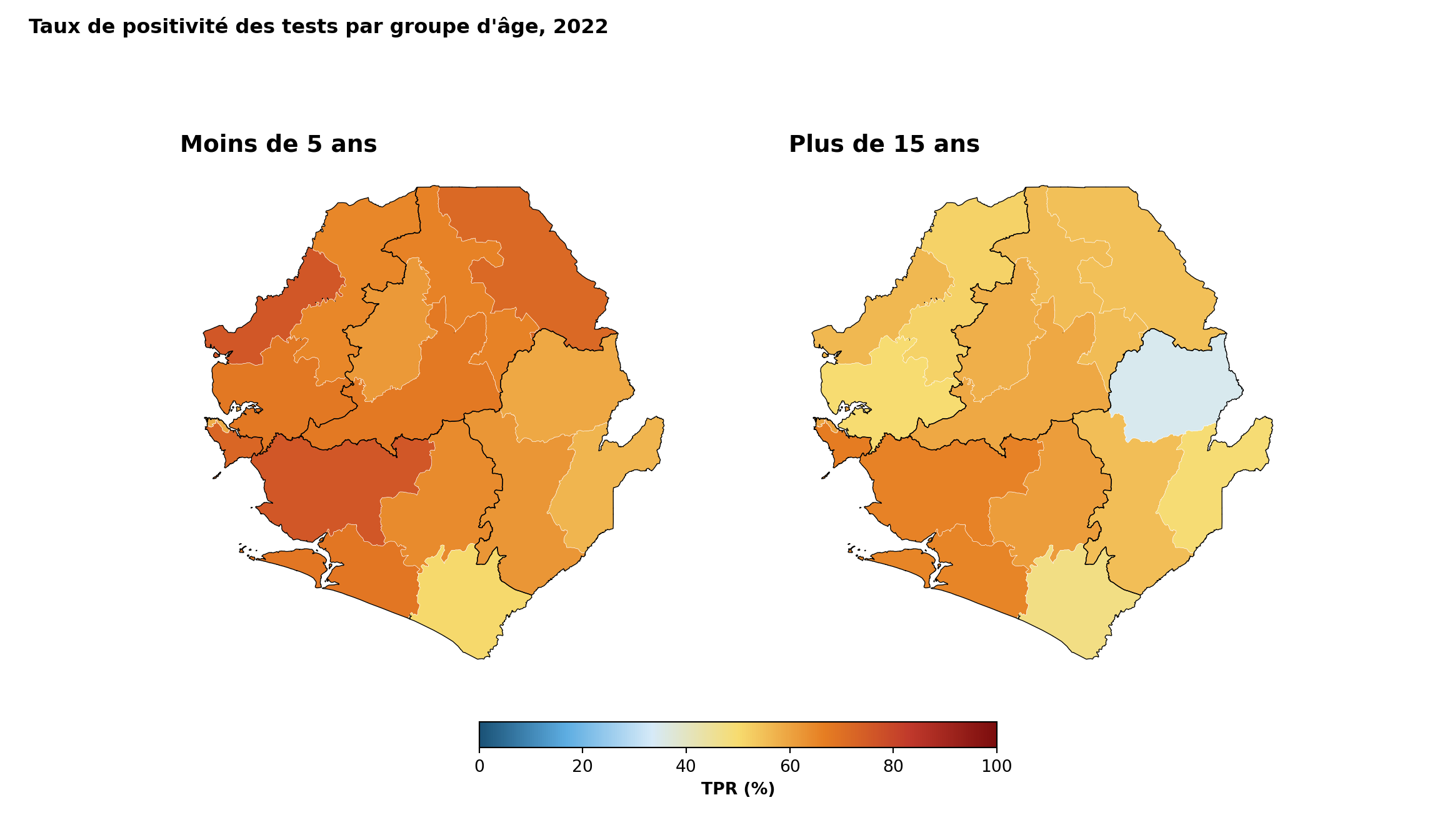
Pour adapter le code :
- Lignes 22–23 : Remplacer
"tpr_u5_pct"/"tpr_ov15_pct"par les colonnes que vous souhaitez comparer côte à côte - Ligne 21 : Remplacer
plt.subplots(1, 2)parplt.subplots(2, 1)pour empiler les panneaux verticalement - Ligne 24 : Modifier le
titleglobal en fonction des données que vous tracez
Étape 5.6 : Cartes interactives pour le contrôle qualité
Une carte statique est ce qui se retrouve dans le rapport, mais pour le contrôle qualité et la révision des parties prenantes, une carte interactive est souvent plus rapide. En R, mapview::mapView() rend tout objet sf comme une carte Leaflet interactive. En Python, l’équivalent est GeoDataFrame.explore() (basé sur folium). Les deux produisent des cartes Leaflet interactives avec des fenêtres contextuelles d’attributs au clic et un fond de carte intégré.
Pour adapter le code :
- Ligne 3 : Remplacer
tabshp_with_ratespar l’objetsfque vous souhaitez inspecter - Ligne 4 : Remplacer
"tpr_overall_pct"par la colonne par laquelle vous souhaitez coloriser - Ligne 6 : Remplacer
tpr_gradient_colorspar toute palette (par exempleget_palette("blues", n = 7))
WarningUtiliser pour le contrôle qualité, pas pour la livraison finale
Les cartes interactives sont excellentes pour inspecter les limites et les valeurs aberrantes, mais ne doivent pas remplacer les cartes statiques dans les sorties SNT formelles. Les réviseurs et les décideurs s’attendent à des figures statiques reproductibles, et les widgets interactifs ne survivent pas à l’exportation PDF ou à la livraison imprimée.
Python utilise .explore() de GeoPandas, qui rend une carte Folium/Leaflet interactive.
Afficher le code
# construire un colormap branca linéaire depuis la palette hex. passer
# un `LinearSegmentedColormap` matplotlib à `.explore(cmap=...)` amène
# geopandas à émettre des tuples rgba flottants (par ex. [0.48, 0.05,
# 0.05, 1.0]) dans le `fillColor` du geojson, ce que leaflet ne peut
# pas analyser - les polygones se rendent alors comme une couleur
# uniforme par défaut. les colormaps branca émettent des chaînes hex
# que leaflet rend correctement.
import branca.colormap as bcm
# adapter automatiquement le colormap à la plage de données réelle pour
# que toute la palette soit utilisée. coder en dur `vmin=0, vmax=100`
# compresserait les données (généralement 50-70 %) au milieu du
# gradient (jaunes), ce que `mapview::mapView()` de r évite en
# choisissant par défaut la plage des données.
_tpr_vals = tabshp_with_rates["tpr_overall_pct"].dropna()
_tpr_vmin = float(_tpr_vals.min())
_tpr_vmax = float(_tpr_vals.max())
tpr_cmap = bcm.LinearColormap(
colors=tpr_gradient_colors,
vmin=_tpr_vmin,
vmax=_tpr_vmax,
caption="TPR (%)",
)
# fonction de style par feature : convertir la valeur en chaîne hex
# via le colormap branca, pour que leaflet reçoive des couleurs css
# valides.
def tpr_style_function(feature):
value = feature["properties"].get("tpr_overall_pct")
fill = tpr_cmap(value) if value is not None else "#cccccc"
return {
"fillColor": fill,
"color": "white",
"weight": 0.5,
"fillOpacity": 0.85,
}
# choroplèthe du TPR tous âges avec fenêtres contextuelles d'attributs
interactive_map = tabshp_with_rates.explore(
tooltip=["adm1", "adm2", "tpr_overall_pct"],
popup=True,
style_kwds={"style_function": tpr_style_function},
legend=False,
)
# attacher la légende branca séparément pour qu'elle soit à côté de la carte
tpr_cmap.add_to(interactive_map)
interactive_mapÉtape 5.7 : Exporter des cartes pour les rapports
La même carte peut sembler soignée dans un jeu de diapositives et pixelisée dans un rapport imprimé si les paramètres d’exportation sont incorrects. Les trois paramètres les plus importants sont :
- Ratio d’aspect (
width/height). Pour une carte, cela devrait correspondre à la boîte englobante du pays, sinon la géographie est écrasée. Pour une figure non cartographique (un graphique à barres classé, un résumé par district, une série temporelle), le ratio d’aspect est déterminé par le nombre de catégories sur l’axe long, et non par la géographie. - DPI. 300 pour l’impression, 150 pour les diapositives, 96-150 pour le web. Le DPI est ignoré pour la sortie vectorielle (
.pdf,.svg). - Support de sortie. Une carte panoramique large et un résumé à barres classées haut ont des profils largeur/hauteur très différents même lorsqu’ils proviennent du même ensemble de données. Enregistrez-les avec les dimensions qui conviennent au support, et non avec les dimensions qui correspondent à l’écran sur lequel vous vous trouvez.
Préréglages d’exportation par support de sortie
| Support | Format | Largeur | DPI | Notes |
|---|---|---|---|---|
| Rapport Word / PDF | PNG ou PDF | 6,5 po (colonne simple) | 300 | Définir height de sorte que le ratio d'aspect corresponde à la boîte englobante du pays |
| Jeu de diapositives (16:9) | PNG | 10 po | 150 | Un DPI plus faible maintient la taille du fichier gérable dans PPT |
| Affiche imprimée | PDF ou SVG | taille physique en pouces | Vectoriel | Utiliser le vectoriel pour éviter la pixelisation à de grandes tailles |
| Web / tableau de bord | PNG ou SVG | 8 po | 96-150 | Définir width en pouces et laisser le DPI gérer les pixels |
Afficher le code
# Profil 1 : carte panoramique large (ratio d'aspect basé sur la bbox)
# calculer le ratio d'aspect à partir de la boîte englobante du shapefile pour que la figure
# exportée corresponde à la forme réelle du pays et ne soit jamais écrasée latéralement
bbox <- sf::st_bbox(adm2_gdf)
aspect_ratio <- (bbox$ymax - bbox$ymin) / (bbox$xmax - bbox$xmin)
map_width <- 10
map_height <- map_width * aspect_ratio
# PNG pour un rapport Word / PDF à 300 dpi
ggplot2::ggsave(
plot = binned_map,
filename = here::here("03_output", "3a_figures", "tpr_binned_map.png"),
width = map_width,
height = map_height,
dpi = 300,
units = "in"
)
# copie vectorielle PDF pour l'impression (le DPI est ignoré pour la sortie vectorielle)
ggplot2::ggsave(
plot = binned_map,
filename = here::here("03_output", "3a_figures", "tpr_binned_map.pdf"),
width = map_width,
height = map_height,
units = "in",
device = grDevices::cairo_pdf
)
# Profil 2 : résumé à barres classées haut (basé sur le nombre de districts, pas la bbox)
# un graphique à barres horizontales classées du TPR par district. Son ratio d'aspect n'a
# rien à voir avec la boîte englobante du pays : la hauteur évolue avec le
# nombre de barres, la largeur est fixée par la colonne du rapport.
tpr_ranking <- tabshp_with_rates |>
sf::st_drop_geometry() |>
dplyr::arrange(dplyr::desc(tpr_overall_pct)) |>
dplyr::mutate(adm2 = forcats::fct_inorder(adm2))
ranked_bars <- ggplot2::ggplot(
tpr_ranking,
ggplot2::aes(x = tpr_overall_pct, y = forcats::fct_rev(adm2))
) +
ggplot2::geom_col(fill = "#1F3A57") +
ggplot2::labs(
title = "Taux de positivité des tests par district, 2022",
x = "TPR (%)",
y = NULL
) +
ggplot2::theme_minimal(base_size = 11)
# la hauteur évolue avec le nombre de districts (~ 0,25 po par barre) pour que chaque
# étiquette reste lisible ; la largeur est fixée à la largeur de colonne simple du rapport
n_districts <- nrow(tpr_ranking)
bar_width <- 6.5
bar_height <- max(4, 0.25 * n_districts + 1.5)
ggplot2::ggsave(
plot = ranked_bars,
filename = here::here("03_output", "3a_figures", "tpr_ranking_bars.png"),
width = bar_width,
height = bar_height,
dpi = 300,
units = "in"
)
# Profil 3 : SVG pour le web / tableaux de bord (vectoriel, largeur conviviale pour l'écran)
ggplot2::ggsave(
plot = binned_map,
filename = here::here("03_output", "3a_figures", "tpr_binned_map.svg"),
width = 8,
height = 8 * aspect_ratio,
units = "in"
)Pour adapter le code :
- Lignes 13–14 : Calculer le ratio d’aspect de la boîte englobante à partir de l’
adm2_gdfde votre pays pour que la carte ne soit pas écrasée - Lignes 16–17 : Modifier
map_widthpour correspondre au support de destination (6,5 po pour un rapport à colonne simple, 10 po pour un jeu de diapositives) - Lignes 47–50 : Remplacer
tpr_overall_pctetadm2par l’indicateur / unité que vous souhaitez classer - Lignes 66–68 : Ajuster le multiplicateur de hauteur (
0.25 * n_districts) si vos étiquettes d’unité sont plus longues ou plus courtes que les noms de district - Lignes 80–81 : Ajuster les dimensions SVG à la largeur de colonne de votre tableau de bord ; SVG ignore
dpi
Afficher le code
# Profil 1 : carte panoramique large (ratio d'aspect basé sur la bbox)
# calculer le ratio d'aspect à partir de la boîte englobante du shapefile pour que la figure
# exportée corresponde à la forme réelle du pays et ne soit jamais écrasée latéralement
xmin, ymin, xmax, ymax = adm2_gdf.total_bounds
aspect_ratio = (ymax - ymin) / (xmax - xmin)
map_width = 10
map_height = map_width * aspect_ratio
fig, ax = plt.subplots(figsize=(map_width, map_height))
plot_binned_map(
ax,
tabshp_with_rates,
fill_col="tpr_overall_bin",
palette=tpr_bin_palette,
title="Taux de positivité des tests tous âges en Sierra Leone",
subtitle="Par district (adm2), 2022",
overlay=adm1_gdf,
)
# PNG pour un rapport Word / PDF à 300 dpi
save_figure(
fig,
here("03_output/3a_figures/tpr_binned_map.png"),
width=map_width,
height=map_height,
dpi=300
)
# copie vectorielle PDF pour l'impression
ensure_output_dir(here("03_output/3a_figures/tpr_binned_map.pdf"))
fig.savefig(
here("03_output/3a_figures/tpr_binned_map.pdf"),
bbox_inches="tight"
)
# Profil 2 : résumé à barres classées haut (basé sur le nombre de districts, pas la bbox)
# un graphique à barres horizontales classées du TPR par district. Son ratio d'aspect n'a
# rien à voir avec la boîte englobante du pays : la hauteur évolue avec le
# nombre de barres, la largeur est fixée par la colonne du rapport.
tpr_ranking = (
pd.DataFrame(tabshp_with_rates.drop(columns="geometry"))
.sort_values("tpr_overall_pct", ascending=False)
)
n_districts = len(tpr_ranking)
bar_width = 6.5
bar_height = max(4, 0.25 * n_districts + 1.5)
fig_bar, ax_bar = plt.subplots(figsize=(bar_width, bar_height))
ax_bar.barh(
tpr_ranking["adm2"],
tpr_ranking["tpr_overall_pct"],
color="#1F3A57"
)
ax_bar.invert_yaxis()
ax_bar.set_title("Taux de positivité des tests par district, 2022", loc="left", fontweight="bold")
ax_bar.set_xlabel("TPR (%)")
ax_bar.set_ylabel("")
ax_bar.spines[["top", "right"]].set_visible(False)
fig_bar.tight_layout()
save_figure(
fig_bar,
here("03_output/3a_figures/tpr_ranking_bars.png"),
width=bar_width,
height=bar_height,
dpi=300
)
# Profil 3 : SVG pour le web / tableaux de bord (vectoriel, largeur conviviale pour l'écran)
ensure_output_dir(here("03_output/3a_figures/tpr_binned_map.svg"))
fig.savefig(
here("03_output/3a_figures/tpr_binned_map.svg"),
bbox_inches="tight"
)
TipCarte large vs graphique haut : choisir le bon profil
Deux figures construites à partir du même ensemble de données partagent rarement la même largeur et hauteur. Utilisez cette règle empirique :
- Carte large. La largeur est définie par la colonne du rapport ou la diapositive. La hauteur est déterminée par la boîte englobante (voir les blocs de code ci-dessous). Ne définissez jamais la hauteur manuellement ; laissez la boîte englobante la déterminer.
- Résumé classé haut. La largeur est définie par la colonne du rapport. La hauteur évolue avec le nombre de catégories sur l’axe long (voir les blocs de code ci-dessous ; environ
0,25 popar barre pour les données au niveau du district, plus si les étiquettes s’enroulent). Ne définissez jamais la largeur pour correspondre à la carte ; les deux figures ont des formes différentes par conception. - Panneau de comparaison carré. Lorsque vous combinez une carte et un graphique non cartographique (R :
patchwork::wrap_plots(); Python :matplotlib.pyplot.subplots()avecgridspec_kwouFigure.subplot_mosaic()), rendez chacun séparément à son ratio d’aspect naturel d’abord, puis laissez la fonction de mise en page les organiser ; ne forcez pas un seulfig-width/fig-heightpartagé.
Formule de hauteur de la carte large dans le code
Formule de hauteur du résumé classé haut dans le code
TipImporter dans PowerPoint sans distorsion
Une fois qu’un PNG est déposé dans une diapositive, PowerPoint vous permet de faire glisser l’une des huit poignées autour de l’image. La plupart d’entre elles déforment la figure :
- Utilisez uniquement les poignées d’angle. Maintenez Shift enfoncé tout en faisant glisser un coin pour verrouiller le ratio d’aspect ; la largeur et la hauteur évoluent alors ensemble et la géographie reste correcte. Les poignées latérales et supérieures / inférieures étirent une seule dimension et écraseront le pays.
- Clic droit → Taille et position → Verrouiller le ratio d’aspect. Cochez ceci une fois par image. À partir de là, saisir une nouvelle largeur dans le volet Taille met à jour la hauteur automatiquement, et vice versa.
- Ré-exporter plutôt que redimensionner au-delà de 100 %. Si un PNG de 10 po se retrouve plus petit que 4 po sur la diapositive, la qualité à l’écran est correcte mais le fichier contient toujours 10 po de pixels. Si vous devez le rendre sensiblement plus grand que la taille exportée, ré-exportez depuis R aux dimensions plus grandes au lieu d’étirer le raster.
- Préférer SVG / EMF pour les diapositives que vous redimensionnerez beaucoup. Les formats vectoriels s’adaptent sans rééchantillonnage ; les PNG raster deviennent flous une fois que vous dépassez 100 % de la taille exportée.
Résumé
Cette page a décrit le processus d’utilisation et de visualisation des données shapefile. Cela commence par l’importation et la validation des données spatiales, en veillant à ce que des systèmes de coordonnées appropriés soient établis pour un alignement géographique précis.
Les techniques de visualisation démontrées peuvent être utilisées à différentes fins. La cartographie de base des limites vérifie le chargement correct des données, tandis que les cartes superposées créent le cadre géographique nécessaire pour l’analyse stratifiée. Ces sorties deviennent la base des applications SNT clés : calcul de la couverture des interventions entre les juridictions, identification des lacunes dans la prestation de services et suivi des performances par rapport aux objectifs géographiques.
Bien que les détails de mise en œuvre varient selon les environnements analytiques, les principes fondamentaux s’appliquent universellement : valider avant l’analyse, maintenir des références spatiales cohérentes et visualiser à plusieurs échelles pour confirmer la pertinence opérationnelle. Les ensembles de données spatiales résultants permettent une prise de décision fondée sur des preuves adaptée aux contextes infranationaux.
Code complet
Trouvez ci-dessous le script de code complet pour visualiser et afficher les données shapefile.
Show full code
################################################################################
###### ~ Utilisation et visualisation de base des shapefiles full code ~ #######
################################################################################
### Step -----------------------------------------------------------------------
# installer `pacman` si ce n'est pas déjà fait
if (!requireNamespace("pacman", quietly = TRUE)) {
install.packages("pacman")
}
# charger les paquets requis en utilisant pacman
pacman::p_load(
readxl, # lire les fichiers Excel
tidyr, # organisation des données
sf, # gérer les données shapefile
dplyr, # manipulation des données
ggplot2, # traçage
viridis, # palettes de couleurs
shadowtext, # étiquettes de tracé
cli, # sortie console stylisée
here, # gestion des chemins de fichiers
stringr # nettoyage des chaînes de caractères
)
# définir le chemin spatial
spat_path <- here::here(
"1.1_foundational",
"1.1a_administrative_boundaries"
)
# charger l'objet spatial chefferie (adm3) traité
gdf <- readRDS(
here::here(spat_path, "processed", "sle_spatial_adm3_2021.rds")
) |>
# garantir que la sortie reste un objet sf valide pour usage en aval
sf::st_as_sf()
# charger l'objet spatial district (adm2) traité
adm2_gdf <- readRDS(
here::here(spat_path, "processed", "sle_spatial_adm2_2021.rds")
) |>
sf::st_as_sf()
# charger l'objet spatial région (adm1) traité, utilisé comme
# superposition de niveau supérieur dans les cartes choroplèthes
# à partir de l'Étape 4
adm1_gdf <- readRDS(
here::here(spat_path, "processed", "sle_spatial_adm1_2021.rds")
) |>
sf::st_as_sf()
# thème de carte partagé réutilisé par chaque carte de cette page
# (theme_void() supprime les axes/la grille par défaut ; le bloc theme
# ci-dessous contrôle les polices, tailles, mise en page de la légende
# et marges, afin que chaque tracé des Étapes 3 à 5 ait la même
# apparence)
snt_map_theme <- function() {
ggplot2::theme_void() +
ggplot2::theme(
legend.position = "bottom",
legend.direction = "horizontal",
# le titre se place au-dessus des cases de la légende, les
# étiquettes des graduations en dessous
legend.title.position = "top",
legend.text.position = "bottom",
legend.title = ggplot2::element_text(
face = "bold",
size = 10,
hjust = 0.5,
margin = ggplot2::margin(b = 6)
),
legend.box.margin = ggplot2::margin(t = 8),
# une largeur de clé étroite garde les légendes sur une seule
# ligne compactes même avec beaucoup de classes ; les Étapes
# 4.3 / 4.6 / 5.2 / 5.3 / 5.4 dépendent toutes de ce défaut
legend.key.width = grid::unit(0.9, "cm"),
strip.text = ggplot2::element_text(
face = "bold",
size = 10,
margin = ggplot2::margin(t = 2, b = 6, l = 4, r = 4)
),
strip.text.y = ggplot2::element_text(angle = -90),
panel.spacing = grid::unit(4, "pt"),
plot.title = ggplot2::element_text(
face = "bold",
size = 14,
margin = ggplot2::margin(b = 8)
),
plot.subtitle = ggplot2::element_text(
size = 11,
margin = ggplot2::margin(b = 10)
),
plot.margin = ggplot2::margin(t = 5, r = 5, b = 5, l = 5)
)
}
# tracer le shapefile de chefferie
basic_map <- ggplot2::ggplot() +
ggplot2::geom_sf(
data = gdf,
fill = "lightblue",
color = "black"
) +
ggplot2::labs(
title = "Carte des chefferies de Sierra Leone (adm3)",
subtitle = "limites adm3"
) +
snt_map_theme()
# enregistrer le tracé
ggplot2::ggsave(
plot = basic_map,
filename = here::here("03_output", "3a_figures", "basic_map.png"),
width = 10,
height = 8,
dpi = 300
)
# calculer les positions des étiquettes une seule fois pour qu'elles
# restent à l'intérieur de chaque polygone de district
adm2_labels <- adm2_gdf |>
dplyr::mutate(
.lab_xy = sf::st_point_on_surface(geometry),
lon = sf::st_coordinates(.lab_xy)[, 1],
lat = sf::st_coordinates(.lab_xy)[, 2]
) |>
sf::st_drop_geometry()
overlay_map <- ggplot2::ggplot() +
# chefferies adm3 : remplissage doux avec contours discrets mais visibles
ggplot2::geom_sf(
data = gdf,
fill = "#EAF0F4",
color = "#A3B6C2",
linewidth = 0.2
) +
# districts adm2 : pas de remplissage, contour foncé fin pour ancrer
# la superposition
ggplot2::geom_sf(
data = adm2_gdf,
fill = NA,
color = "#1F3A57",
linewidth = 0.45
) +
# étiquettes adm2 avec un halo blanc marqué pour la lisibilité
shadowtext::geom_shadowtext(
data = adm2_labels,
ggplot2::aes(x = lon, y = lat, label = adm2),
color = "#1F3A57",
bg.color = "white",
bg.r = 0.18,
size = 3.6,
fontface = "bold"
) +
ggplot2::labs(
title = "Superposition des limites administratives de la Sierra Leone",
subtitle = "Districts (adm2) et chefferies (adm3)"
) +
snt_map_theme()
# enregistrer le tracé
ggplot2::ggsave(
plot = overlay_map,
filename = here::here("03_output", "3a_figures", "overlay_map.png"),
width = 10,
height = 8,
dpi = 300
)
# charger les données d'intervention catégorielles
# le fichier Excel contient une colonne `adm3` verbeuse (style "Dea Chiefdom")
# et une colonne `FIRST_CHIE` brute ("DEA"). supprimer la colonne verbeuse
# et utiliser le code brut pour correspondre au champ `adm3` du shapefile
categorical_intervention_data <- readxl::read_excel(
here::here(
"1.2_epidemiology",
"1.2a_routine_surveillance",
"processed",
"scenario_with_irs_no_smc_06_20_2025.xlsx"
)
) |>
dplyr::select(-dplyr::any_of("adm3")) |>
dplyr::rename(
adm2 = FIRST_DNAM,
adm3 = FIRST_CHIE
)
# diagnostiquer la couverture de jointure par noms uniquement à adm2-adm3
shp_names_cat <- gdf |>
sf::st_drop_geometry() |>
dplyr::distinct(adm1, adm2, adm3)
shp_with_cat <- shp_names_cat |>
dplyr::inner_join(
categorical_intervention_data |>
dplyr::distinct(adm2, adm3),
by = c("adm2", "adm3")
)
cli::cli_h2("Diagnostics de jointure d'intervention catégorielle")
cli::cli_alert_success(
"Correspondances exactes entre adm2-adm3: {nrow(shp_with_cat)}"
)
# effectuer maintenant la fusion réelle avec les niveaux administratifs 2-3
gdf_cat_joined <- gdf |>
dplyr::inner_join(
categorical_intervention_data,
by = c("adm2", "adm3")
) |>
sf::st_as_sf()
cli::cli_alert_success(
"Nombre de lignes fusionnées final pour les données d'intervention: {nrow(gdf_cat_joined)}"
)
#==============================================================================#
# charger les données DHIS2 et filtrer à l'année de travail au moment
# de la lecture afin de ne jamais conserver l'ensemble multi-années en mémoire
sle_dhis2_df_coord_spatial_adm3 <- readRDS(
here::here(
"1.2_epidemiology",
"1.2a_routine_surveillance",
"processed",
"sle_dhis2_df_coord_spatial_adm3.rds"
)
) |>
dplyr::filter(year == "2022")
# agréger aux totaux annuels par chefferie pour que chaque chefferie apparaisse une fois
# (plutôt qu'une fois par mois) avant la jointure
sle_dhis2_2022_annual <- sle_dhis2_df_coord_spatial_adm3 |>
dplyr::group_by(adm0, adm1, adm2, adm3) |>
dplyr::summarise(
dplyr::across(
c(conf, test, conf_u5, test_u5,
conf_5_14, test_5_14, conf_ov15, test_ov15),
~ sum(.x, na.rm = TRUE)
),
.groups = "drop"
)
# diagnostiquer la couverture de jointure par noms uniquement à adm1-adm3
dhis2_admins <- sle_dhis2_2022_annual |>
dplyr::distinct(adm1, adm2, adm3)
shp_names <- gdf |>
sf::st_drop_geometry() |>
dplyr::distinct(adm1, adm2, adm3)
shp_with_dhis2 <- shp_names |>
dplyr::inner_join(
dhis2_admins,
by = c("adm1", "adm2", "adm3")
)
cli::cli_h2("Diagnostics de jointure DHIS2")
cli::cli_alert_success(
"Correspondances exactes entre adm1-adm3: {nrow(shp_with_dhis2)}"
)
# effectuer maintenant la fusion réelle avec les niveaux administratifs 1-3
tabshp <- gdf |>
dplyr::inner_join(
sle_dhis2_2022_annual,
by = c("adm0", "adm1", "adm2", "adm3")
) |>
sf::st_as_sf()
cli::cli_alert_success(
"Nombre de lignes fusionnées final: {nrow(tabshp)}"
)
categorical_map <- ggplot2::ggplot() +
ggplot2::geom_sf(
data = gdf_cat_joined,
ggplot2::aes(fill = irs),
color = "white",
size = 0.2
) +
ggplot2::scale_fill_brewer(
# supprimer le titre de la légende et utiliser des étiquettes explicites
name = NULL,
palette = "Accent",
labels = c(
"IRS" = "IRS planifiée",
"No IRS" = "Pas d'IRS planifiée"
),
na.value = "grey90",
na.translate = FALSE
) +
ggplot2::geom_sf(
data = gdf_cat_joined,
fill = NA,
color = "grey30",
linewidth = 0.3
) +
ggplot2::geom_sf(
data = adm2_gdf,
fill = NA,
color = "black",
linewidth = 0.5
) +
ggplot2::labs(
title = "Couverture planifiée de la pulvérisation intradomiciliaire (IRS)",
subtitle = "Par chefferie, 2026-2030"
) +
snt_map_theme() +
ggplot2::theme(
legend.key.size = ggplot2::unit(0.5, "cm")
)
# enregistrer le tracé
ggplot2::ggsave(
plot = categorical_map,
filename = here::here("03_output", "3a_figures", "categorical_map.png"),
width = 10,
height = 8,
dpi = 300
)
# agréger les comptages par chefferie au niveau du district (adm2) pour que
# le choroplèthe remplisse les polygones complets des districts, évitant
# les trous causés par les chefferies manquantes
tabshp_adm2 <- tabshp |>
sf::st_drop_geometry() |>
dplyr::group_by(adm0, adm1, adm2) |>
dplyr::summarise(
dplyr::across(
c(
conf, test,
conf_u5, test_u5,
conf_5_14, test_5_14,
conf_ov15, test_ov15
),
~ sum(.x, na.rm = TRUE)
),
.groups = "drop"
) |>
# restaurer la géométrie des polygones depuis le shapefile adm2
dplyr::left_join(adm2_gdf, by = c("adm0", "adm1", "adm2")) |>
sf::st_as_sf()
# calculer les taux de positivité des tests en pourcentages au niveau adm2
tabshp_with_rates <- tabshp_adm2 |>
dplyr::mutate(
tpr_overall_pct = dplyr::if_else(
test > 0, (conf / test) * 100, NA_real_
),
tpr_u5_pct = dplyr::if_else(
test_u5 > 0, (conf_u5 / test_u5) * 100, NA_real_
),
tpr_5_14_pct = dplyr::if_else(
test_5_14 > 0, (conf_5_14 / test_5_14) * 100, NA_real_
),
tpr_ov15_pct = dplyr::if_else(
test_ov15 > 0, (conf_ov15 / test_ov15) * 100, NA_real_
)
)
# définir les étiquettes ordonnées des intervalles et une palette divergente
# où le bleu va jusqu'à 50-60 et les tons chauds prennent le relais au-delà
tpr_bin_labels <- c(
"0-10", "10-20", "20-30", "30-40", "40-50",
"50-60", "60-70", "70-80", "80-90", "90-100"
)
tpr_bin_palette <- c(
"0-10" = "#1a5276",
"10-20" = "#2980b9",
"20-30" = "#5dade2",
"30-40" = "#85c1e9",
"40-50" = "#aed6f1",
"50-60" = "#d6eaf8",
"60-70" = "#f7dc6f",
"70-80" = "#e67e22",
"80-90" = "#c0392b",
"90-100" = "#7b0d0d"
)
tabshp_with_rates <- tabshp_with_rates |>
dplyr::mutate(
tpr_overall_bin = cut(
tpr_overall_pct,
breaks = c(0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100),
labels = tpr_bin_labels,
include.lowest = TRUE
)
)
binned_map <- ggplot2::ggplot() +
# districts adm2 colorés par intervalle de TPR
ggplot2::geom_sf(
data = tabshp_with_rates,
ggplot2::aes(fill = tpr_overall_bin),
color = "white",
size = 0.2
) +
ggplot2::scale_fill_manual(
name = "Taux de positivité des tests (%)",
values = tpr_bin_palette,
drop = TRUE,
na.value = "grey90",
na.translate = FALSE,
guide = ggplot2::guide_legend(
title.position = "top",
title.hjust = 0.5,
label.position = "bottom",
override.aes = list(
colour = "black",
size = 0.15,
alpha = 1
),
nrow = 1,
byrow = TRUE
)
) +
# régions adm1 : superposition plus épaisse pour lire clairement les limites
ggplot2::geom_sf(
data = adm1_gdf,
fill = NA,
color = "black",
linewidth = 0.5
) +
ggplot2::labs(
title = "Taux de positivité des tests tous âges en Sierra Leone",
subtitle = "Par district (adm2), 2022"
) +
snt_map_theme()
# enregistrer le tracé
ggplot2::ggsave(
plot = binned_map,
filename = here::here("03_output", "3a_figures", "binned_map.png"),
width = 10,
height = 8,
dpi = 300
)
# palette par défaut du dégradé SNT (valeurs élevées -> rouge foncé,
# valeurs faibles -> bleu foncé)
tpr_gradient_colors <- c(
"#7b0d0d", "#c0392b", "#e67e22", "#f7dc6f",
"#d6eaf8", "#5dade2", "#1a5276"
)
continuous_map <- ggplot2::ggplot() +
ggplot2::geom_sf(
data = tabshp_with_rates,
ggplot2::aes(fill = tpr_overall_pct),
color = "white",
size = 0.2
) +
ggplot2::scale_fill_gradientn(
name = "Taux de positivité des tests (%)",
colors = rev(tpr_gradient_colors),
limits = c(0, 100),
na.value = "grey90",
guide = ggplot2::guide_colorbar(
title.position = "top",
title.hjust = 0.5,
barwidth = grid::unit(15, "lines"),
barheight = grid::unit(0.5, "lines")
)
) +
ggplot2::geom_sf(
data = adm1_gdf,
fill = NA,
color = "black",
linewidth = 0.5
) +
ggplot2::labs(
title = "Taux de positivité des tests tous âges en Sierra Leone",
subtitle = "Par district (adm2), 2022"
) +
snt_map_theme()
# enregistrer le tracé
ggplot2::ggsave(
plot = continuous_map,
filename = here::here("03_output", "3a_figures", "continuous_map.png"),
width = 10,
height = 8,
dpi = 300
)
# étiquettes adm1 avec gestion des erreurs
# (le fichier .rds traité chargé à l'Étape 2 est déjà valide, donc
# aucun nettoyage supplémentaire st_make_valid / st_buffer n'est nécessaire ici)
adm1_labels <- tryCatch(
{
gdf |>
dplyr::group_by(adm1) |>
dplyr::summarise(geometry = sf::st_union(geometry)) |>
sf::st_make_valid() |>
dplyr::mutate(
centroid = sf::st_point_on_surface(geometry),
coords = sf::st_coordinates(centroid),
x = coords[, 1],
y = coords[, 2]
)
},
error = function(e) {
adm2_gdf |>
dplyr::mutate(
centroid = sf::st_point_on_surface(geometry),
coords = sf::st_coordinates(centroid),
x = coords[, 1],
y = coords[, 2]
)
}
)
# palette de couleurs automatique
n_adm1 <- length(unique(gdf$adm1))
adm1_colors <- viridis::plasma(n_adm1)
names(adm1_colors) <- unique(gdf$adm1)
subdivided_plot <- ggplot2::ggplot() +
ggplot2::geom_sf(
data = gdf,
ggplot2::aes(fill = adm1),
color = "white",
linewidth = 0.35
) +
ggplot2::scale_fill_manual(values = adm1_colors) +
ggplot2::geom_sf(
data = adm2_gdf,
fill = NA,
color = "black",
linewidth = 0.8
) +
shadowtext::geom_shadowtext(
data = adm1_labels,
ggplot2::aes(x = x, y = y, label = adm1),
size = 3,
fontface = "bold",
color = "black",
bg.color = "white",
bg.r = 0.25
) +
ggplot2::labs(
title = "Limites Adm1 et Adm2 subdivisées de la Sierra Leone"
) +
snt_map_theme()
# enregistrer le tracé
ggplot2::ggsave(
plot = subdivided_plot,
filename = here::here("03_output", "3a_figures", "subdivided_map.png"),
width = 10,
height = 8,
dpi = 300
)
# sélectionner les colonnes de pourcentage TPR
tpr_cols <- c(
"tpr_u5_pct",
"tpr_5_14_pct",
"tpr_ov15_pct",
"tpr_overall_pct"
)
# convertir en format long et créer des catégories par intervalles
tpr_long_data <- tabshp_with_rates |>
dplyr::select(geometry, dplyr::all_of(tpr_cols)) |>
tidyr::pivot_longer(
cols = -geometry,
names_to = "age_group",
values_to = "tpr_percentage"
) |>
dplyr::mutate(
age_group = dplyr::recode(
age_group,
"tpr_u5_pct" = "Moins de 5 ans",
"tpr_5_14_pct" = "5-14 ans",
"tpr_ov15_pct" = "Plus de 15 ans",
"tpr_overall_pct" = "Global"
),
age_group = factor(
age_group,
levels = c(
"Moins de 5 ans",
"5-14 ans",
"Plus de 15 ans",
"Global"
),
ordered = TRUE
),
tpr_binned = cut(
tpr_percentage,
breaks = c(0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100),
labels = c(
"0-10", "10-20", "20-30", "30-40", "40-50",
"50-60", "60-70", "70-80", "80-90", "90-100"
),
include.lowest = TRUE
)
)
faceted_tpr_plot <- ggplot2::ggplot(tpr_long_data) +
ggplot2::geom_sf(
ggplot2::aes(fill = tpr_binned),
color = "white",
linewidth = 0.15
) +
ggplot2::facet_wrap(~ age_group, ncol = 2) +
# utiliser la même palette nommée et la même légende à une ligne qu'à
# l'Étape 4.3 pour que la mise en page reste cohérente sur toute la page
ggplot2::scale_fill_manual(
name = "Taux de positivité des tests (%)",
values = tpr_bin_palette,
drop = TRUE,
na.value = "grey90",
na.translate = FALSE,
guide = ggplot2::guide_legend(
title.position = "top",
title.hjust = 0.5,
label.position = "bottom",
override.aes = list(
colour = "black",
size = 0.15,
alpha = 1
),
nrow = 1,
byrow = TRUE
)
) +
# régions adm1 comme superposition de niveau supérieur (source unique
# de vérité pour les limites sur chaque facette)
ggplot2::geom_sf(
data = adm1_gdf,
fill = NA,
color = "black",
linewidth = 0.3
) +
ggplot2::labs(
title = "Taux de positivité des tests par groupe d'âge et district (2022)",
subtitle = "Proportion de tests positifs"
) +
snt_map_theme() +
# ajustements spécifiques aux facettes en plus du thème partagé
ggplot2::theme(
panel.spacing = ggplot2::unit(0.5, "cm"),
strip.text = ggplot2::element_text(face = "bold", size = 11),
legend.key.width = ggplot2::unit(0.9, "cm")
)
# enregistrer le tracé
ggplot2::ggsave(
plot = faceted_tpr_plot,
filename = here::here("03_output", "3a_figures", "faceted_tpr_plot.png"),
width = 10,
height = 8,
dpi = 300
)
# définir un petit catalogue de palettes couvrant les cas d'utilisation
# séquentiels, divergents et catégoriels. chaque entrée est un vecteur de
# caractères ordonné de codes hex qui peut être passé directement à scale_fill_manual().
snt_palettes <- list(
# séquentielle
blues = c(
"#deebf7", "#c6dbef", "#9ecae1",
"#6baed6", "#4292c6", "#2171b5", "#08519c"
),
ylord = c(
"#ffffcc", "#ffeda0", "#fed976",
"#feb24c", "#fd8d3c", "#fc4e2a", "#bd0026"
),
viridis = c(
"#440154", "#482878", "#3e4a89",
"#31688e", "#26828e", "#1f9e89", "#35b779",
"#6ece58", "#b5de2b", "#fde725"
),
# divergente (valeur par défaut snt pour les indicateurs de type tpr)
byor = c(
"#1a5276", "#2980b9", "#5dade2",
"#85c1e9", "#aed6f1", "#d6eaf8",
"#f7dc6f", "#e67e22", "#c0392b", "#7b0d0d"
),
rdbu = c(
"#b2182b", "#d6604d", "#f4a582",
"#fddbc7", "#d1e5f0", "#92c5de",
"#4393c3", "#2166ac"
),
spectral = c(
"#d53e4f", "#f46d43", "#fdae61",
"#fee08b", "#e6f598", "#abdda4",
"#66c2a5", "#3288bd"
),
# catégorielle
set2 = c(
"#66c2a5", "#fc8d62", "#8da0cb",
"#e78ac3", "#a6d854", "#ffd92f"
),
accent = c(
"#7fc97f", "#beaed4", "#fdc086",
"#ffff99", "#386cb0", "#f0027f"
)
)
# remodeler en un dataframe long pour que chaque couleur soit une tuile
swatches_df <- purrr::imap_dfr(
snt_palettes,
function(cols, name) {
data.frame(
palette = name,
position = seq_along(cols),
colour = cols,
stringsAsFactors = FALSE
)
}
) |>
dplyr::mutate(
palette = factor(
palette,
levels = rev(names(snt_palettes))
)
)
palette_swatches <- ggplot2::ggplot(
swatches_df,
ggplot2::aes(
x = position,
y = palette,
fill = colour
)
) +
ggplot2::geom_tile(
color = "white",
linewidth = 0.4
) +
ggplot2::scale_fill_identity() +
ggplot2::scale_x_continuous(expand = c(0, 0)) +
ggplot2::labs(
title = "Palettes de couleurs SNT recommandées",
subtitle = "Options séquentielles, divergentes et catégorielles",
x = NULL,
y = NULL
) +
ggplot2::theme_minimal(base_size = 11) +
ggplot2::theme(
panel.grid = ggplot2::element_blank(),
axis.text.x = ggplot2::element_blank(),
axis.ticks = ggplot2::element_blank(),
axis.text.y = ggplot2::element_text(
face = "bold",
size = 10
),
plot.title = ggplot2::element_text(
face = "bold",
size = 14,
margin = ggplot2::margin(b = 6)
),
plot.subtitle = ggplot2::element_text(
size = 11,
margin = ggplot2::margin(b = 10)
),
plot.margin = ggplot2::margin(
t = 5, r = 10, b = 5, l = 5
)
)
# enregistrer le tracé
ggplot2::ggsave(
plot = palette_swatches,
filename = here::here(
"03_output", "3a_figures", "palette_swatches.png"
),
width = 10,
height = 6,
dpi = 300
)
# petit ensemble de référence de capitales de district pour l'orientation
# remplacer par votre liste principale d'établissements ou votre ensemble de données de capitales
city_points <- data.frame(
city = c("Freetown", "Bo", "Kenema", "Makeni"),
lon = c(-13.234, -11.738, -11.190, -12.043),
lat = c(8.484, 7.964, 7.875, 8.886)
) |>
sf::st_as_sf(coords = c("lon", "lat"), crs = 4326)
map_with_points <- ggplot2::ggplot() +
ggplot2::geom_sf(
data = tabshp_with_rates,
ggplot2::aes(fill = tpr_overall_bin),
color = "white",
size = 0.2
) +
ggplot2::scale_fill_manual(
name = "Test positivity rate (%)",
values = tpr_bin_palette,
drop = TRUE,
na.value = "grey90",
na.translate = FALSE,
guide = ggplot2::guide_legend(
title.position = "top",
title.hjust = 0.5,
label.position = "bottom",
override.aes = list(
colour = "black",
size = 0.15,
alpha = 1
),
nrow = 1,
byrow = TRUE
)
) +
# régions adm1 comme superposition de niveau supérieur
ggplot2::geom_sf(
data = adm1_gdf,
fill = NA,
color = "black",
linewidth = 0.5
) +
ggplot2::geom_sf(
data = city_points,
shape = 21,
fill = "white",
color = "black",
size = 2.4,
stroke = 0.6
) +
shadowtext::geom_shadowtext(
data = city_points,
ggplot2::aes(
x = sf::st_coordinates(geometry)[, 1],
y = sf::st_coordinates(geometry)[, 2],
label = city
),
color = "black",
bg.color = "white",
bg.r = 0.18,
size = 3.2,
fontface = "bold",
nudge_y = 0.08
) +
ggplot2::labs(
title = "Taux de positivité des tests tous âges avec les capitales de district",
subtitle = "Par district (adm2), 2022"
) +
snt_map_theme()
# sauvegarder le graphique
ggplot2::ggsave(
plot = map_with_points,
filename = here::here("03_output", "3a_figures", "map_with_points.png"),
width = 10,
height = 8,
dpi = 300
)
# sélectionner les trois districts avec le TPR tous âges le plus élevé
top_tpr <- tabshp_with_rates |>
dplyr::slice_max(tpr_overall_pct, n = 3)
highlighted_map <- ggplot2::ggplot() +
ggplot2::geom_sf(
data = tabshp_with_rates,
ggplot2::aes(fill = tpr_overall_bin),
color = "white",
size = 0.2
) +
ggplot2::scale_fill_manual(
name = "Test positivity rate (%)",
values = tpr_bin_palette,
drop = TRUE,
na.value = "grey90",
na.translate = FALSE,
guide = ggplot2::guide_legend(
title.position = "top",
title.hjust = 0.5,
label.position = "bottom",
override.aes = list(
colour = "black",
size = 0.15,
alpha = 1
),
nrow = 1,
byrow = TRUE
)
) +
# régions adm1 comme superposition de niveau supérieur
ggplot2::geom_sf(
data = adm1_gdf,
fill = NA,
color = "grey40",
linewidth = 0.5
) +
# la couche de mise en évidence se trouve au-dessus de tout le reste
ggplot2::geom_sf(
data = top_tpr,
fill = NA,
color = "black",
linewidth = 1.1
) +
ggplot2::labs(
title = "Top 3 des districts par taux de positivité des tests tous âges",
subtitle = "Par district (adm2), 2022"
) +
snt_map_theme()
# sauvegarder le graphique
ggplot2::ggsave(
plot = highlighted_map,
filename = here::here("03_output", "3a_figures", "highlighted_map.png"),
width = 10,
height = 8,
dpi = 300
)
publication_map <- ggplot2::ggplot() +
ggplot2::geom_sf(
data = tabshp_with_rates,
ggplot2::aes(fill = tpr_overall_bin),
color = "white",
size = 0.2
) +
ggplot2::scale_fill_manual(
name = "Test positivity rate (%)",
values = tpr_bin_palette,
drop = TRUE,
na.value = "grey90",
na.translate = FALSE,
guide = ggplot2::guide_legend(
title.position = "top",
title.hjust = 0.5,
label.position = "bottom",
override.aes = list(
colour = "black",
size = 0.15,
alpha = 1
),
nrow = 1,
byrow = TRUE
)
) +
# régions adm1 comme superposition de niveau supérieur
ggplot2::geom_sf(
data = adm1_gdf,
fill = NA,
color = "black",
linewidth = 0.5
) +
ggspatial::annotation_scale(
location = "bl",
width_hint = 0.25,
style = "bar",
line_width = 0.6
) +
ggspatial::annotation_north_arrow(
location = "tr",
which_north = "true",
style = ggspatial::north_arrow_fancy_orienteering(),
height = grid::unit(1.4, "cm"),
width = grid::unit(1.4, "cm")
) +
ggplot2::labs(
title = "Taux de positivité des tests avec barre d'échelle et flèche du nord",
subtitle = "Par district (adm2), 2022"
) +
snt_map_theme()
# sauvegarder le graphique
ggplot2::ggsave(
plot = publication_map,
filename = here::here("03_output", "3a_figures", "publication_map.png"),
width = 10,
height = 8,
dpi = 300
)
# petite fonction d'aide pour que les deux panneaux partagent le même aspect et héritent du
# thème de carte SNT partagé utilisé aux étapes 4.3 - 5.4 (polices, tailles, mise en page
# de la légende, marges) ; seul le sous-titre par panneau est ajusté
make_panel <- function(data, fill_col, panel_title) {
ggplot2::ggplot() +
ggplot2::geom_sf(
data = data,
ggplot2::aes(fill = .data[[fill_col]]),
color = "white",
size = 0.2
) +
ggplot2::scale_fill_gradientn(
name = "TPR (%)",
colors = rev(tpr_gradient_colors),
limits = c(0, 100),
na.value = "grey90",
guide = ggplot2::guide_colorbar(
title.position = "top",
title.hjust = 0.5,
barwidth = grid::unit(8, "lines"),
barheight = grid::unit(0.4, "lines")
)
) +
# régions adm1 comme superposition de niveau supérieur
ggplot2::geom_sf(
data = adm1_gdf,
fill = NA,
color = "black",
linewidth = 0.5
) +
ggplot2::labs(subtitle = panel_title) +
snt_map_theme() +
ggplot2::theme(
plot.subtitle = ggplot2::element_text(
face = "bold",
size = 11,
hjust = 0,
margin = ggplot2::margin(b = 6)
)
)
}
panel_u5 <- make_panel(
tabshp_with_rates, "tpr_u5_pct", "Moins de 5 ans"
)
panel_ov15 <- make_panel(
tabshp_with_rates, "tpr_ov15_pct", "Plus de 15 ans"
)
combined_map <- patchwork::wrap_plots(
panel_u5, panel_ov15, ncol = 2
) +
patchwork::plot_annotation(
title = "Taux de positivité des tests par groupe d'âge, 2022",
theme = ggplot2::theme(
plot.title = ggplot2::element_text(
face = "bold",
size = 14,
hjust = 0,
margin = ggplot2::margin(b = 8)
)
)
) +
patchwork::plot_layout(guides = "collect") &
ggplot2::theme(legend.position = "bottom")
# sauvegarder le graphique
ggplot2::ggsave(
plot = combined_map,
filename = here::here("03_output", "3a_figures", "combined_map.png"),
width = 12,
height = 7,
dpi = 300
)
# choroplèthe du TPR tous âges avec fenêtres contextuelles d'attributs
mapview::mapView(
tabshp_with_rates,
zcol = "tpr_overall_pct",
layer.name = "TPR (%)",
col.regions = rev(tpr_gradient_colors),
alpha.regions = 0.85,
legend = TRUE
)
# Profil 1 : carte panoramique large (ratio d'aspect basé sur la bbox)
# calculer le ratio d'aspect à partir de la boîte englobante du shapefile pour que la figure
# exportée corresponde à la forme réelle du pays et ne soit jamais écrasée latéralement
bbox <- sf::st_bbox(adm2_gdf)
aspect_ratio <- (bbox$ymax - bbox$ymin) / (bbox$xmax - bbox$xmin)
map_width <- 10
map_height <- map_width * aspect_ratio
# PNG pour un rapport Word / PDF à 300 dpi
ggplot2::ggsave(
plot = binned_map,
filename = here::here("03_output", "3a_figures", "tpr_binned_map.png"),
width = map_width,
height = map_height,
dpi = 300,
units = "in"
)
# copie vectorielle PDF pour l'impression (le DPI est ignoré pour la sortie vectorielle)
ggplot2::ggsave(
plot = binned_map,
filename = here::here("03_output", "3a_figures", "tpr_binned_map.pdf"),
width = map_width,
height = map_height,
units = "in",
device = grDevices::cairo_pdf
)
# Profil 2 : résumé à barres classées haut (basé sur le nombre de districts, pas la bbox)
# un graphique à barres horizontales classées du TPR par district. Son ratio d'aspect n'a
# rien à voir avec la boîte englobante du pays : la hauteur évolue avec le
# nombre de barres, la largeur est fixée par la colonne du rapport.
tpr_ranking <- tabshp_with_rates |>
sf::st_drop_geometry() |>
dplyr::arrange(dplyr::desc(tpr_overall_pct)) |>
dplyr::mutate(adm2 = forcats::fct_inorder(adm2))
ranked_bars <- ggplot2::ggplot(
tpr_ranking,
ggplot2::aes(x = tpr_overall_pct, y = forcats::fct_rev(adm2))
) +
ggplot2::geom_col(fill = "#1F3A57") +
ggplot2::labs(
title = "Taux de positivité des tests par district, 2022",
x = "TPR (%)",
y = NULL
) +
ggplot2::theme_minimal(base_size = 11)
# la hauteur évolue avec le nombre de districts (~ 0,25 po par barre) pour que chaque
# étiquette reste lisible ; la largeur est fixée à la largeur de colonne simple du rapport
n_districts <- nrow(tpr_ranking)
bar_width <- 6.5
bar_height <- max(4, 0.25 * n_districts + 1.5)
ggplot2::ggsave(
plot = ranked_bars,
filename = here::here("03_output", "3a_figures", "tpr_ranking_bars.png"),
width = bar_width,
height = bar_height,
dpi = 300,
units = "in"
)
# Profil 3 : SVG pour le web / tableaux de bord (vectoriel, largeur conviviale pour l'écran)
ggplot2::ggsave(
plot = binned_map,
filename = here::here("03_output", "3a_figures", "tpr_binned_map.svg"),
width = 8,
height = 8 * aspect_ratio,
units = "in"
)Show full code
################################################################################
###### ~ Utilisation et visualisation de base des shapefiles full code ~ #######
################################################################################
### Step -----------------------------------------------------------------------
from pathlib import Path
import geopandas as gpd
import matplotlib.colors as mcolors
import matplotlib.patches as mpatches
import matplotlib.patheffects as path_effects
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pyreadr
from matplotlib.cm import ScalarMappable
from matplotlib_scalebar.scalebar import ScaleBar
from pyprojroot import here
def read_rds(path):
"""lire un fichier RDS à objet unique en tant qu'objet pandas."""
result = pyreadr.read_r(str(path))
return next(iter(result.values()))
def ensure_output_dir(path):
"""créer le répertoire parent avant d'enregistrer des figures ou des données."""
Path(path).parent.mkdir(parents=True, exist_ok=True)
def add_title(ax, title=None, subtitle=None):
"""utiliser un bloc de titre matplotlib pour correspondre à la sortie titre/sous-titre de ggplot."""
if title and subtitle:
ax.set_title(f"{title}\n{subtitle}", loc="left", fontsize=14, fontweight="bold")
elif title:
ax.set_title(title, loc="left", fontsize=14, fontweight="bold")
def finish_map(ax, title=None, subtitle=None):
"""appliquer le style de carte statique partagé utilisé sur cette page."""
add_title(ax, title, subtitle)
ax.set_axis_off()
def save_figure(fig, filename, width, height, dpi=300):
"""enregistrer une figure matplotlib avec des dimensions correspondant aux exemples R."""
ensure_output_dir(filename)
fig.set_size_inches(width, height)
fig.savefig(filename, dpi=dpi, bbox_inches="tight")
def label_points(ax, data, label_col, x_col="lon", y_col="lat", dy=0.08, size=8):
"""ajouter des étiquettes de points avec un halo blanc pour la lisibilité."""
for _, row in data.iterrows():
text = ax.text(
row[x_col],
row[y_col] + dy,
row[label_col],
ha="center",
va="center",
fontsize=size,
fontweight="bold",
color="black",
)
text.set_path_effects([
path_effects.Stroke(linewidth=3, foreground="white"),
path_effects.Normal(),
])
def legend_patches(palette, labels=None):
"""créer des poignées de légende catégorielle à partir d'un dictionnaire de couleurs nommé."""
labels = labels or {}
return [
mpatches.Patch(facecolor=color, edgecolor="black", label=labels.get(key, key))
for key, color in palette.items()
]
def add_bottom_legend(ax, handles, title=None, ncol=None):
"""placer une légende horizontale compacte sous une carte."""
ncol = ncol or len(handles)
ax.legend(
handles=handles,
title=title,
loc="lower center",
bbox_to_anchor=(0.5, -0.10),
ncol=ncol,
frameon=False,
fontsize=8,
title_fontsize=9,
)
def plot_binned_map(ax, data, fill_col, palette, title=None, subtitle=None,
overlay=None, overlay_color="black", overlay_width=0.5):
"""dessiner une carte choroplèthe binée avec une légende en bas et une superposition optionnelle."""
plot_colors = data[fill_col].map(palette).fillna("#E5E5E5")
data.plot(
ax=ax,
color=plot_colors,
edgecolor="white",
linewidth=0.2,
)
if overlay is not None:
overlay.plot(ax=ax, facecolor="none", edgecolor=overlay_color, linewidth=overlay_width)
finish_map(ax, title, subtitle)
present_keys = [key for key in palette if key in set(data[fill_col].dropna().astype(str))]
handles = legend_patches({key: palette[key] for key in present_keys})
add_bottom_legend(ax, handles, title="Taux de positivité des tests (%)", ncol=len(handles))
def plot_gradient_map(ax, data, fill_col, colors, title=None, subtitle=None,
overlay=None, legend_label="Taux de positivité des tests (%)",
vmin=0, vmax=100):
"""dessiner une carte choroplèthe continue avec une barre de couleur horizontale."""
cmap = mcolors.LinearSegmentedColormap.from_list("snt_gradient", colors)
data.plot(
ax=ax,
column=fill_col,
cmap=cmap,
vmin=vmin,
vmax=vmax,
edgecolor="white",
linewidth=0.2,
missing_kwds={"color": "#E5E5E5"},
)
if overlay is not None:
overlay.plot(ax=ax, facecolor="none", edgecolor="black", linewidth=0.5)
finish_map(ax, title, subtitle)
sm = ScalarMappable(norm=mcolors.Normalize(vmin=vmin, vmax=vmax), cmap=cmap)
sm.set_array([])
cbar = ax.figure.colorbar(sm, ax=ax, orientation="horizontal", fraction=0.04, pad=0.04)
cbar.set_label(legend_label, fontweight="bold")
snt_palettes = {
"blues": ["#deebf7", "#c6dbef", "#9ecae1", "#6baed6", "#4292c6", "#2171b5", "#08519c"],
"ylord": ["#ffffcc", "#ffeda0", "#fed976", "#feb24c", "#fd8d3c", "#fc4e2a", "#bd0026"],
"viridis": [
"#440154", "#482878", "#3e4a89", "#31688e", "#26828e",
"#1f9e89", "#35b779", "#6ece58", "#b5de2b", "#fde725"
],
"byor": [
"#1a5276", "#2980b9", "#5dade2", "#85c1e9", "#aed6f1",
"#d6eaf8", "#f7dc6f", "#e67e22", "#c0392b", "#7b0d0d"
],
"rdbu": ["#b2182b", "#d6604d", "#f4a582", "#fddbc7", "#d1e5f0", "#92c5de", "#4393c3", "#2166ac"],
"spectral": ["#d53e4f", "#f46d43", "#fdae61", "#fee08b", "#e6f598", "#abdda4", "#66c2a5", "#3288bd"],
"set2": ["#66c2a5", "#fc8d62", "#8da0cb", "#e78ac3", "#a6d854", "#ffd92f"],
"accent": ["#7fc97f", "#beaed4", "#fdc086", "#ffff99", "#386cb0", "#f0027f"],
}
tpr_bin_labels = [
"0-10", "10-20", "20-30", "30-40", "40-50",
"50-60", "60-70", "70-80", "80-90", "90-100"
]
tpr_bin_palette = dict(zip(tpr_bin_labels, snt_palettes["byor"]))
tpr_gradient_colors = [
"#1a5276", "#5dade2", "#d6eaf8", "#f7dc6f",
"#e67e22", "#c0392b", "#7b0d0d"
]
# définir le chemin spatial
spat_path = here("1.1_foundational/1.1a_administrative_boundaries/processed")
# charger l'objet spatial chiefdom (adm3) traité
gdf = gpd.read_file(Path(spat_path) / "sle_spatial_adm3_2021.geojson")
# charger l'objet spatial district (adm2) traité
adm2_gdf = gpd.read_file(Path(spat_path) / "sle_spatial_adm2_2021.geojson")
# charger l'objet spatial region (adm1) traité, utilisé comme superposition de niveau supérieur
# dans les cartes choroplèthes à partir de l'Étape 4
adm1_gdf = gpd.read_file(Path(spat_path) / "sle_spatial_adm1_2021.geojson")
fig, ax = plt.subplots(figsize=(10, 8))
gdf.plot(ax=ax, facecolor="lightblue", edgecolor="black", linewidth=0.6)
finish_map(
ax,
title="Carte des chefferies de la Sierra Leone (adm3)",
subtitle="limites adm3"
)
# enregistrer le tracé
save_figure(
fig,
here("03_output/3a_figures/basic_map.png"),
width=10,
height=8,
dpi=300
)
plt.show()
# calculer les positions des étiquettes une fois pour que les étiquettes restent à l'intérieur de chaque polygone de district
adm2_labels = adm2_gdf.copy()
adm2_points = adm2_labels.geometry.representative_point()
adm2_labels["lon"] = adm2_points.x
adm2_labels["lat"] = adm2_points.y
fig, ax = plt.subplots(figsize=(10, 8))
# chefferies adm3 : remplissage doux avec des contours subtils mais visibles
gdf.plot(ax=ax, facecolor="#EAF0F4", edgecolor="#A3B6C2", linewidth=0.2)
# districts adm2 : pas de remplissage, contour sombre mince pour ancrer la superposition
adm2_gdf.plot(ax=ax, facecolor="none", edgecolor="#1F3A57", linewidth=0.45)
# étiquettes adm2 avec un fort halo blanc pour la lisibilité
label_points(ax, adm2_labels, label_col="adm2", size=8)
finish_map(
ax,
title="Superposition des limites administratives de la Sierra Leone",
subtitle="Districts (adm2) et chefferies (adm3)"
)
# enregistrer le tracé
save_figure(
fig,
here("03_output/3a_figures/overlay_map.png"),
width=10,
height=8,
dpi=300
)
plt.show()
# charger les données d'intervention catégorielles
# le fichier Excel contient une colonne `adm3` verbeuse (style "Dea Chiefdom") et une
# colonne brute `FIRST_CHIE` ("DEA"). supprimer la colonne verbeuse et utiliser le code brut
# pour qu'il corresponde au champ `adm3` du shapefile
categorical_intervention_data = (
pd.read_excel(
here(
"1.2_epidemiology/1.2a_routine_surveillance/processed/"
"scenario_with_irs_no_smc_06_20_2025.xlsx"
)
)
.drop(columns=["adm3"], errors="ignore")
.rename(columns={"FIRST_DNAM": "adm2", "FIRST_CHIE": "adm3"})
)
# diagnostiquer la couverture de jointure par noms uniquement à adm2-adm3
shp_names_cat = gdf[["adm1", "adm2", "adm3"]].drop_duplicates()
shp_with_cat = shp_names_cat.merge(
categorical_intervention_data[["adm2", "adm3"]].drop_duplicates(),
on=["adm2", "adm3"],
how="inner"
)
print("Diagnostics de jointure d'intervention catégorielle")
print(f"SUCCÈS : Correspondances exactes entre adm2-adm3 : {len(shp_with_cat)}")
# effectuer la fusion réelle avec adm2-adm3
gdf_cat_joined = gdf.merge(
categorical_intervention_data,
on=["adm2", "adm3"],
how="inner"
)
gdf_cat_joined = gpd.GeoDataFrame(gdf_cat_joined, geometry="geometry", crs=gdf.crs)
print(f"SUCCÈS : Nombre de lignes fusionnées final pour les données d'intervention : {len(gdf_cat_joined)}")
# ----------------------------------------------------------------------------
# charger les données DHIS2 et filtrer à l'année de travail au moment de la lecture
# pour ne jamais conserver l'ensemble de données multi-années complet en mémoire en aval
sle_dhis2_df_coord_spatial_adm3 = (
read_rds(
here(
"1.2_epidemiology/1.2a_routine_surveillance/processed/"
"sle_dhis2_df_coord_spatial_adm3.rds"
)
)
.loc[lambda x: x["year"].astype(str) == "2022"]
)
# agréger aux totaux annuels par chefferie pour que chaque chefferie apparaisse une fois
# (plutôt qu'une fois par mois) avant la jointure
sum_cols = [
"conf", "test", "conf_u5", "test_u5",
"conf_5_14", "test_5_14", "conf_ov15", "test_ov15"
]
sle_dhis2_2022_annual = (
sle_dhis2_df_coord_spatial_adm3
.groupby(["adm0", "adm1", "adm2", "adm3"], as_index=False)[sum_cols]
.sum()
)
# diagnostiquer la couverture de jointure par noms uniquement à adm1-adm3
dhis2_admins = sle_dhis2_2022_annual[["adm1", "adm2", "adm3"]].drop_duplicates()
shp_names = gdf[["adm1", "adm2", "adm3"]].drop_duplicates()
shp_with_dhis2 = shp_names.merge(dhis2_admins, on=["adm1", "adm2", "adm3"], how="inner")
print("Diagnostics de jointure DHIS2")
print(f"SUCCÈS : Correspondances exactes entre adm1-adm3 : {len(shp_with_dhis2)}")
# effectuer la fusion réelle avec adm1-adm3
tabshp = gdf.merge(
sle_dhis2_2022_annual,
on=["adm0", "adm1", "adm2", "adm3"],
how="inner"
)
tabshp = gpd.GeoDataFrame(tabshp, geometry="geometry", crs=gdf.crs)
print(f"SUCCÈS : Nombre de lignes fusionnées final : {len(tabshp)}")
irs_palette = {"IRS": "#7fc97f", "No IRS": "#beaed4"}
irs_labels = {"IRS": "IRS planifié", "No IRS": "Pas d'IRS planifié"}
fig, ax = plt.subplots(figsize=(10, 8))
gdf_cat_joined.plot(
ax=ax,
color=gdf_cat_joined["irs"].map(irs_palette).fillna("#E5E5E5"),
edgecolor="white",
linewidth=0.2,
)
gdf_cat_joined.boundary.plot(ax=ax, color="#4D4D4D", linewidth=0.3)
adm2_gdf.boundary.plot(ax=ax, color="black", linewidth=0.5)
finish_map(
ax,
title="Couverture planifiée de pulvérisation intradomiciliaire d'insecticide (IRS)",
subtitle="Par chefferie, 2026-2030"
)
add_bottom_legend(ax, legend_patches(irs_palette, irs_labels), ncol=2)
# enregistrer le tracé
save_figure(
fig,
here("03_output/3a_figures/categorical_map.png"),
width=10,
height=8,
dpi=300
)
plt.show()
# agréger les comptages au niveau chefferie jusqu'au district (adm2) pour que la carte choroplèthe
# remplisse les polygones de district complets, en évitant les lacunes causées par les chefferies manquantes
tabshp_adm2 = (
pd.DataFrame(tabshp.drop(columns="geometry"))
.groupby(["adm0", "adm1", "adm2"], as_index=False)[sum_cols]
.sum()
.merge(adm2_gdf, on=["adm0", "adm1", "adm2"], how="left")
)
tabshp_adm2 = gpd.GeoDataFrame(tabshp_adm2, geometry="geometry", crs=adm2_gdf.crs)
# calculer les taux de positivité des tests en pourcentages au niveau adm2
tabshp_with_rates = tabshp_adm2.copy()
tabshp_with_rates["tpr_overall_pct"] = np.where(
tabshp_with_rates["test"] > 0,
(tabshp_with_rates["conf"] / tabshp_with_rates["test"]) * 100,
np.nan
)
tabshp_with_rates["tpr_u5_pct"] = np.where(
tabshp_with_rates["test_u5"] > 0,
(tabshp_with_rates["conf_u5"] / tabshp_with_rates["test_u5"]) * 100,
np.nan
)
tabshp_with_rates["tpr_5_14_pct"] = np.where(
tabshp_with_rates["test_5_14"] > 0,
(tabshp_with_rates["conf_5_14"] / tabshp_with_rates["test_5_14"]) * 100,
np.nan
)
tabshp_with_rates["tpr_ov15_pct"] = np.where(
tabshp_with_rates["test_ov15"] > 0,
(tabshp_with_rates["conf_ov15"] / tabshp_with_rates["test_ov15"]) * 100,
np.nan
)
tabshp_with_rates["tpr_overall_bin"] = pd.cut(
tabshp_with_rates["tpr_overall_pct"],
bins=np.arange(0, 110, 10),
labels=tpr_bin_labels,
include_lowest=True
).astype("string")
fig, ax = plt.subplots(figsize=(10, 8))
plot_binned_map(
ax,
tabshp_with_rates,
fill_col="tpr_overall_bin",
palette=tpr_bin_palette,
title="Taux de positivité des tests tous âges en Sierra Leone",
subtitle="Par district (adm2), 2022",
overlay=adm1_gdf,
)
# enregistrer le tracé
save_figure(
fig,
here("03_output/3a_figures/binned_map.png"),
width=10,
height=8,
dpi=300
)
plt.show()
fig, ax = plt.subplots(figsize=(10, 8))
plot_gradient_map(
ax,
tabshp_with_rates,
fill_col="tpr_overall_pct",
colors=tpr_gradient_colors,
title="Taux de positivité des tests tous âges en Sierra Leone",
subtitle="Par district (adm2), 2022",
overlay=adm1_gdf,
legend_label="Taux de positivité des tests (%)",
vmin=0,
vmax=100,
)
# enregistrer le tracé
save_figure(
fig,
here("03_output/3a_figures/continuous_map.png"),
width=10,
height=8,
dpi=300
)
plt.show()
# étiquettes adm1 avec gestion des erreurs
# (les fichiers traités chargés à l'Étape 2 sont déjà valides, donc aucun
# nettoyage de géométrie supplémentaire n'est nécessaire ici)
try:
adm1_labels = gdf.dissolve(by="adm1", as_index=False)
except Exception:
adm1_labels = adm2_gdf.copy()
adm1_points = adm1_labels.geometry.representative_point()
adm1_labels["lon"] = adm1_points.x
adm1_labels["lat"] = adm1_points.y
# palette de couleurs automatique
adm1_values = list(gdf["adm1"].dropna().unique())
plasma = plt.get_cmap("plasma")
adm1_colors = {
adm1: mcolors.to_hex(plasma(i / max(len(adm1_values) - 1, 1)))
for i, adm1 in enumerate(adm1_values)
}
fig, ax = plt.subplots(figsize=(10, 8))
gdf.plot(
ax=ax,
color=gdf["adm1"].map(adm1_colors),
edgecolor="white",
linewidth=0.35,
)
adm2_gdf.boundary.plot(ax=ax, color="black", linewidth=0.8)
label_points(ax, adm1_labels, label_col="adm1", size=8)
finish_map(ax, title="Limites adm1 et adm2 subdivisées de la Sierra Leone")
add_bottom_legend(ax, legend_patches(adm1_colors), ncol=len(adm1_colors))
# enregistrer le tracé
save_figure(
fig,
here("03_output/3a_figures/subdivided_map.png"),
width=10,
height=8,
dpi=300
)
plt.show()
# sélectionner les colonnes de pourcentage TPR
tpr_cols = ["tpr_u5_pct", "tpr_5_14_pct", "tpr_ov15_pct", "tpr_overall_pct"]
# convertir les données en format long et créer des catégories par intervalles
age_labels = {
"tpr_u5_pct": "Moins de 5 ans",
"tpr_5_14_pct": "5-14 ans",
"tpr_ov15_pct": "Plus de 15 ans",
"tpr_overall_pct": "Global",
}
age_order = ["Moins de 5 ans", "5-14 ans", "Plus de 15 ans", "Global"]
tpr_long_data = tabshp_with_rates[["geometry"] + tpr_cols].melt(
id_vars="geometry",
value_vars=tpr_cols,
var_name="age_group",
value_name="tpr_percentage"
)
tpr_long_data["age_group"] = pd.Categorical(
tpr_long_data["age_group"].map(age_labels),
categories=age_order,
ordered=True
)
tpr_long_data["tpr_binned"] = pd.cut(
tpr_long_data["tpr_percentage"],
bins=np.arange(0, 110, 10),
labels=tpr_bin_labels,
include_lowest=True
).astype("string")
tpr_long_data = gpd.GeoDataFrame(tpr_long_data, geometry="geometry", crs=tabshp_with_rates.crs)
fig, axes = plt.subplots(2, 2, figsize=(10, 8))
for ax, age_group in zip(axes.flat, age_order):
subset = tpr_long_data.loc[tpr_long_data["age_group"] == age_group]
plot_colors = subset["tpr_binned"].map(tpr_bin_palette).fillna("#E5E5E5")
subset.plot(
ax=ax,
color=plot_colors,
edgecolor="white",
linewidth=0.15,
)
adm1_gdf.boundary.plot(ax=ax, color="black", linewidth=0.3)
finish_map(ax, title=age_group)
fig.suptitle(
"Taux de positivité des tests par groupe d'âge et district (2022)",
fontweight="bold",
x=0.02,
ha="left",
)
handles = legend_patches(tpr_bin_palette)
fig.legend(
handles=handles,
title="Taux de positivité des tests (%)",
loc="lower center",
bbox_to_anchor=(0.5, -0.02),
ncol=len(handles),
frameon=False,
fontsize=8,
title_fontsize=9,
)
fig.tight_layout(rect=[0, 0.07, 1, 0.95])
# enregistrer le tracé
save_figure(
fig,
here("03_output/3a_figures/faceted_tpr_plot.png"),
width=10,
height=8,
dpi=300
)
plt.show()
# remodeler en un dataframe long pour que chaque couleur soit une tuile
swatches_df = pd.DataFrame(
[
{"palette": name, "position": i + 1, "colour": colour}
for name, colours in snt_palettes.items()
for i, colour in enumerate(colours)
]
)
palette_order = list(reversed(list(snt_palettes.keys())))
fig, ax = plt.subplots(figsize=(10, 6))
for y, palette_name in enumerate(palette_order):
subset = swatches_df.loc[swatches_df["palette"] == palette_name]
for _, row in subset.iterrows():
ax.add_patch(
mpatches.Rectangle(
(row["position"] - 1, y - 0.4),
1,
0.8,
facecolor=row["colour"],
edgecolor="white",
linewidth=0.4,
)
)
ax.set_xlim(0, max(len(cols) for cols in snt_palettes.values()))
ax.set_ylim(-0.5, len(palette_order) - 0.5)
ax.set_yticks(range(len(palette_order)))
ax.set_yticklabels(palette_order, fontweight="bold")
ax.set_xticks([])
ax.set_title(
"Palettes de couleurs SNT recommandées\nOptions séquentielles, divergentes et catégorielles",
loc="left",
fontsize=14,
fontweight="bold",
)
for spine in ax.spines.values():
spine.set_visible(False)
ax.tick_params(left=False, bottom=False)
# enregistrer le tracé
save_figure(
fig,
here("03_output/3a_figures/palette_swatches.png"),
width=10,
height=6,
dpi=300
)
plt.show()
# petit ensemble de référence de capitales de district pour l'orientation
# remplacer par votre liste principale d'établissements ou votre ensemble de données de capitales
city_points = pd.DataFrame({
"city": ["Freetown", "Bo", "Kenema", "Makeni"],
"lon": [-13.234, -11.738, -11.190, -12.043],
"lat": [8.484, 7.964, 7.875, 8.886],
})
city_points = gpd.GeoDataFrame(
city_points,
geometry=gpd.points_from_xy(city_points["lon"], city_points["lat"]),
crs="EPSG:4326",
).to_crs(tabshp_with_rates.crs)
city_points["lon"] = city_points.geometry.x
city_points["lat"] = city_points.geometry.y
fig, ax = plt.subplots(figsize=(10, 8))
plot_binned_map(
ax,
tabshp_with_rates,
fill_col="tpr_overall_bin",
palette=tpr_bin_palette,
title="Taux de positivité des tests tous âges avec les capitales de district",
subtitle="Par district (adm2), 2022",
overlay=adm1_gdf,
)
city_points.plot(
ax=ax,
marker="o",
facecolor="white",
edgecolor="black",
markersize=35,
linewidth=0.6,
)
label_points(ax, city_points, label_col="city", dy=0.08, size=8)
# sauvegarder le graphique
save_figure(
fig,
here("03_output/3a_figures/map_with_points.png"),
width=10,
height=8,
dpi=300
)
plt.show()
# sélectionner les trois districts avec le TPR tous âges le plus élevé
top_tpr = tabshp_with_rates.nlargest(3, "tpr_overall_pct")
fig, ax = plt.subplots(figsize=(10, 8))
plot_binned_map(
ax,
tabshp_with_rates,
fill_col="tpr_overall_bin",
palette=tpr_bin_palette,
title="Top 3 des districts par taux de positivité des tests tous âges",
subtitle="Par district (adm2), 2022",
overlay=adm1_gdf,
overlay_color="#666666",
)
# la couche de mise en évidence se trouve au-dessus de tout le reste
top_tpr.boundary.plot(ax=ax, color="black", linewidth=1.1)
# sauvegarder le graphique
save_figure(
fig,
here("03_output/3a_figures/highlighted_map.png"),
width=10,
height=8,
dpi=300
)
plt.show()
# transformer en mètres pour la barre d'échelle
tabshp_with_rates_m = tabshp_with_rates.to_crs(epsg=3857)
adm1_gdf_m = adm1_gdf.to_crs(epsg=3857)
fig, ax = plt.subplots(figsize=(10, 8))
plot_binned_map(
ax,
tabshp_with_rates_m,
fill_col="tpr_overall_bin",
palette=tpr_bin_palette,
title="Taux de positivité des tests avec barre d'échelle et flèche du nord",
subtitle="Par district (adm2), 2022",
overlay=adm1_gdf_m,
)
ax.add_artist(
ScaleBar(
1,
units="m",
dimension="si-length",
location="lower left",
length_fraction=0.25,
box_alpha=0,
)
)
ax.annotate(
"N",
xy=(0.94, 0.93),
xytext=(0.94, 0.80),
xycoords="axes fraction",
textcoords="axes fraction",
ha="center",
va="center",
fontsize=12,
fontweight="bold",
arrowprops={"arrowstyle": "-|>", "facecolor": "black", "edgecolor": "black", "lw": 1.2},
)
# sauvegarder le graphique
save_figure(
fig,
here("03_output/3a_figures/publication_map.png"),
width=10,
height=8,
dpi=300
)
plt.show()
def make_panel_py(ax, data, fill_col, panel_title):
cmap = mcolors.LinearSegmentedColormap.from_list("tpr_gradient", tpr_gradient_colors)
data.plot(
ax=ax,
column=fill_col,
cmap=cmap,
vmin=0,
vmax=100,
edgecolor="white",
linewidth=0.2,
missing_kwds={"color": "#E5E5E5"},
)
adm1_gdf.boundary.plot(ax=ax, color="black", linewidth=0.5)
finish_map(ax, title=panel_title)
return cmap
fig, axes = plt.subplots(1, 2, figsize=(12, 7))
cmap = make_panel_py(axes[0], tabshp_with_rates, "tpr_u5_pct", "Moins de 5 ans")
make_panel_py(axes[1], tabshp_with_rates, "tpr_ov15_pct", "Plus de 15 ans")
fig.suptitle(
"Taux de positivité des tests par groupe d'âge, 2022",
fontweight="bold",
x=0.02,
ha="left",
)
sm = ScalarMappable(norm=mcolors.Normalize(vmin=0, vmax=100), cmap=cmap)
sm.set_array([])
cbar = fig.colorbar(sm, ax=axes, orientation="horizontal", fraction=0.04, pad=0.06)
cbar.set_label("TPR (%)", fontweight="bold")
# sauvegarder le graphique
save_figure(
fig,
here("03_output/3a_figures/combined_map.png"),
width=12,
height=7,
dpi=300
)
plt.show()
# construire un colormap branca linéaire depuis la palette hex. passer
# un `LinearSegmentedColormap` matplotlib à `.explore(cmap=...)` amène
# geopandas à émettre des tuples rgba flottants (par ex. [0.48, 0.05,
# 0.05, 1.0]) dans le `fillColor` du geojson, ce que leaflet ne peut
# pas analyser - les polygones se rendent alors comme une couleur
# uniforme par défaut. les colormaps branca émettent des chaînes hex
# que leaflet rend correctement.
import branca.colormap as bcm
# adapter automatiquement le colormap à la plage de données réelle pour
# que toute la palette soit utilisée. coder en dur `vmin=0, vmax=100`
# compresserait les données (généralement 50-70 %) au milieu du
# gradient (jaunes), ce que `mapview::mapView()` de r évite en
# choisissant par défaut la plage des données.
_tpr_vals = tabshp_with_rates["tpr_overall_pct"].dropna()
_tpr_vmin = float(_tpr_vals.min())
_tpr_vmax = float(_tpr_vals.max())
tpr_cmap = bcm.LinearColormap(
colors=tpr_gradient_colors,
vmin=_tpr_vmin,
vmax=_tpr_vmax,
caption="TPR (%)",
)
# fonction de style par feature : convertir la valeur en chaîne hex
# via le colormap branca, pour que leaflet reçoive des couleurs css
# valides.
def tpr_style_function(feature):
value = feature["properties"].get("tpr_overall_pct")
fill = tpr_cmap(value) if value is not None else "#cccccc"
return {
"fillColor": fill,
"color": "white",
"weight": 0.5,
"fillOpacity": 0.85,
}
# choroplèthe du TPR tous âges avec fenêtres contextuelles d'attributs
interactive_map = tabshp_with_rates.explore(
tooltip=["adm1", "adm2", "tpr_overall_pct"],
popup=True,
style_kwds={"style_function": tpr_style_function},
legend=False,
)
# attacher la légende branca séparément pour qu'elle soit à côté de la carte
tpr_cmap.add_to(interactive_map)
interactive_map
# Profil 1 : carte panoramique large (ratio d'aspect basé sur la bbox)
# calculer le ratio d'aspect à partir de la boîte englobante du shapefile pour que la figure
# exportée corresponde à la forme réelle du pays et ne soit jamais écrasée latéralement
xmin, ymin, xmax, ymax = adm2_gdf.total_bounds
aspect_ratio = (ymax - ymin) / (xmax - xmin)
map_width = 10
map_height = map_width * aspect_ratio
fig, ax = plt.subplots(figsize=(map_width, map_height))
plot_binned_map(
ax,
tabshp_with_rates,
fill_col="tpr_overall_bin",
palette=tpr_bin_palette,
title="Taux de positivité des tests tous âges en Sierra Leone",
subtitle="Par district (adm2), 2022",
overlay=adm1_gdf,
)
# PNG pour un rapport Word / PDF à 300 dpi
save_figure(
fig,
here("03_output/3a_figures/tpr_binned_map.png"),
width=map_width,
height=map_height,
dpi=300
)
# copie vectorielle PDF pour l'impression
ensure_output_dir(here("03_output/3a_figures/tpr_binned_map.pdf"))
fig.savefig(
here("03_output/3a_figures/tpr_binned_map.pdf"),
bbox_inches="tight"
)
# Profil 2 : résumé à barres classées haut (basé sur le nombre de districts, pas la bbox)
# un graphique à barres horizontales classées du TPR par district. Son ratio d'aspect n'a
# rien à voir avec la boîte englobante du pays : la hauteur évolue avec le
# nombre de barres, la largeur est fixée par la colonne du rapport.
tpr_ranking = (
pd.DataFrame(tabshp_with_rates.drop(columns="geometry"))
.sort_values("tpr_overall_pct", ascending=False)
)
n_districts = len(tpr_ranking)
bar_width = 6.5
bar_height = max(4, 0.25 * n_districts + 1.5)
fig_bar, ax_bar = plt.subplots(figsize=(bar_width, bar_height))
ax_bar.barh(
tpr_ranking["adm2"],
tpr_ranking["tpr_overall_pct"],
color="#1F3A57"
)
ax_bar.invert_yaxis()
ax_bar.set_title("Taux de positivité des tests par district, 2022", loc="left", fontweight="bold")
ax_bar.set_xlabel("TPR (%)")
ax_bar.set_ylabel("")
ax_bar.spines[["top", "right"]].set_visible(False)
fig_bar.tight_layout()
save_figure(
fig_bar,
here("03_output/3a_figures/tpr_ranking_bars.png"),
width=bar_width,
height=bar_height,
dpi=300
)
# Profil 3 : SVG pour le web / tableaux de bord (vectoriel, largeur conviviale pour l'écran)
ensure_output_dir(here("03_output/3a_figures/tpr_binned_map.svg"))
fig.savefig(
here("03_output/3a_figures/tpr_binned_map.svg"),
bbox_inches="tight"
)